




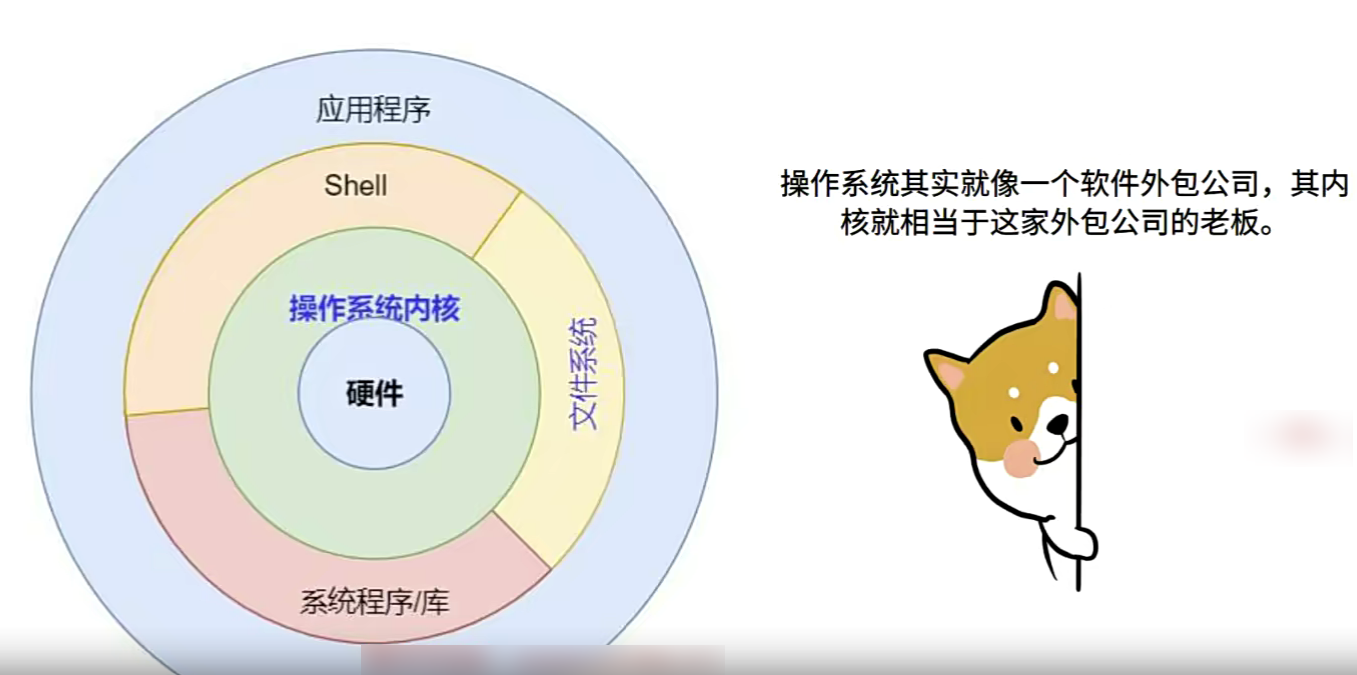
Linux环境编程基础
Linux操作系统概述与安装
虚拟机安装
见gitee地址:
S02-09-05-虚拟机安装讲解/02-虚拟机安装.md · 槐月初叁/23-S1-BigData_PP_Sprints_Learning
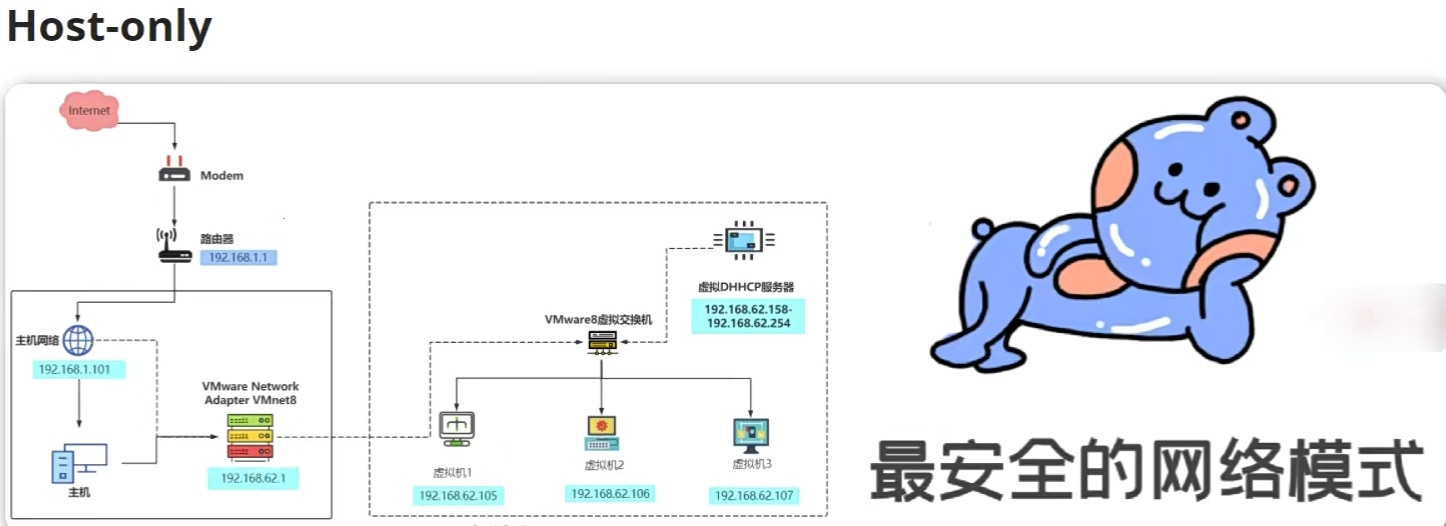
Liunx三种网络配置

桥接模式
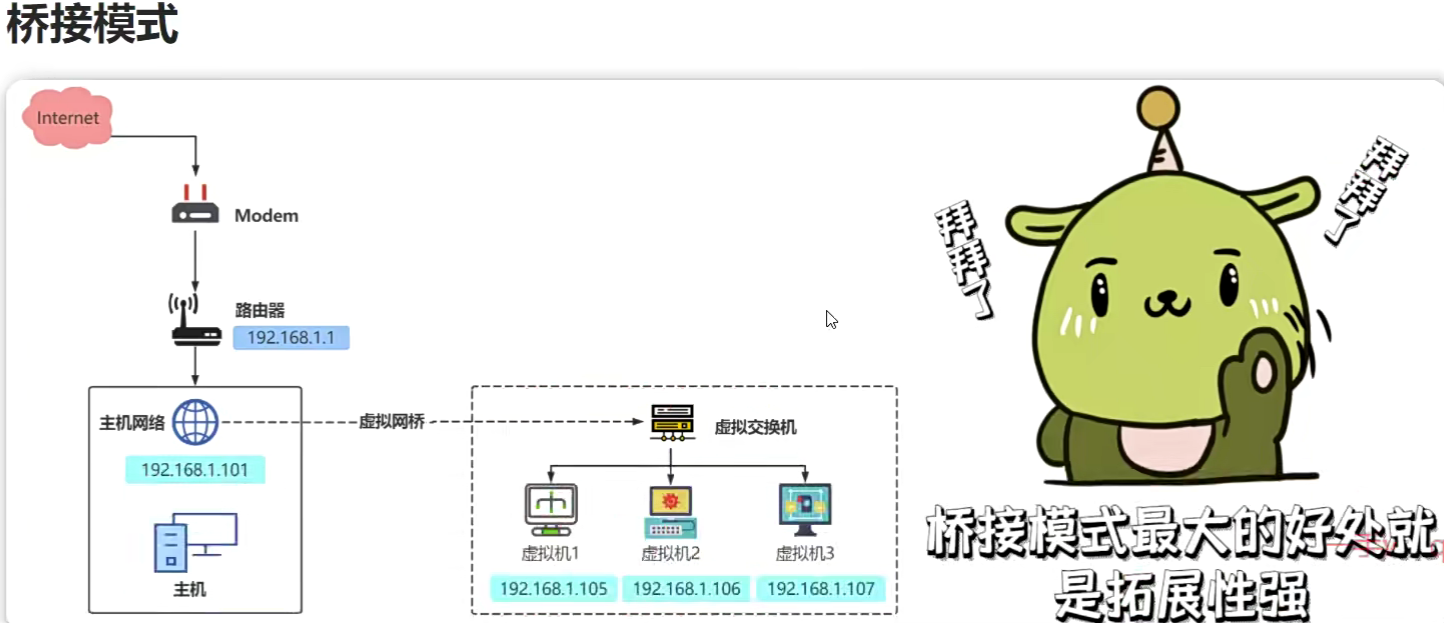
NAT模式

Host-only模式(主机模式)
Linux远程登录
修改当前虚拟机ip地址
1.查看IP地址
1)基本语法
ip addr (功能描述:显示所有网络接口的配置信息)
2)案例实操
[root@node0 ~]# ip addr
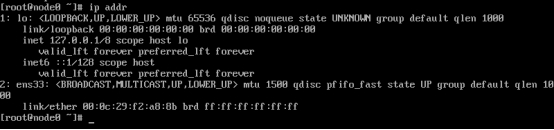
当前网络不可用,需要进行修改。
2.修改当前虚拟机ip地址
1)修改IP地址
[root@node0 ~]#vi /etc/sysconfig/network-scripts/ifcfg-ens33
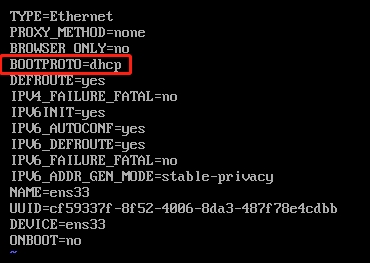
以下标红的项必须修改,有值的按照下面的值修改,没有该项的要增加,另外删除UUID这行配置。
#IP的配置方法[none|static|bootp|dhcp](引导时不使用协议|静态分配IP|BOOTP协议|动态分配IP协议)
UUID=xxxx #删除这一行 esc ->dd
BOOTPROTO=static
ONBOOT=yes
#IP地址
IPADDR=192.168.20.100
#子网掩码
NETMASK=255.255.255.0
#网关
GATEWAY=192.168.20.2
#域名解析器
DNS1=114.114.114.114
DNS2=8.8.8.8
修改后,如下图所示
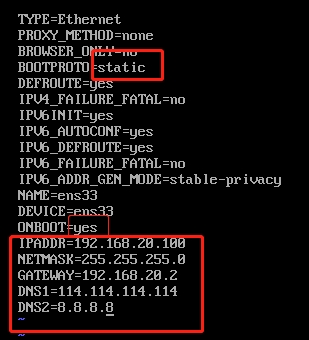
:wq 保存退出
2)执行systemctl restart network
3)如果报错,reboot,重启虚拟机
3.ping 测试主机之间网络连通性
1)基本语法
ping 目的主机 (功能描述:测试当前服务器是否可以连接目的主机)
2)案例实操
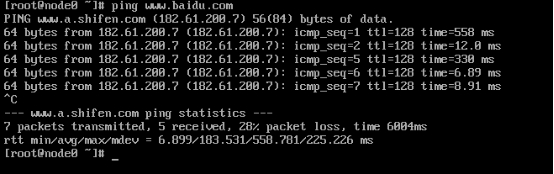
#测试当前服务器是否可以连接百度
[root@node0 ~]# ping www.baidu.com
安装Xshell7和Xftp7
使用Xshell即可进行远程登录Linux
(安装MobaXterm也可以进行远程登录)
Linux系统目录结构

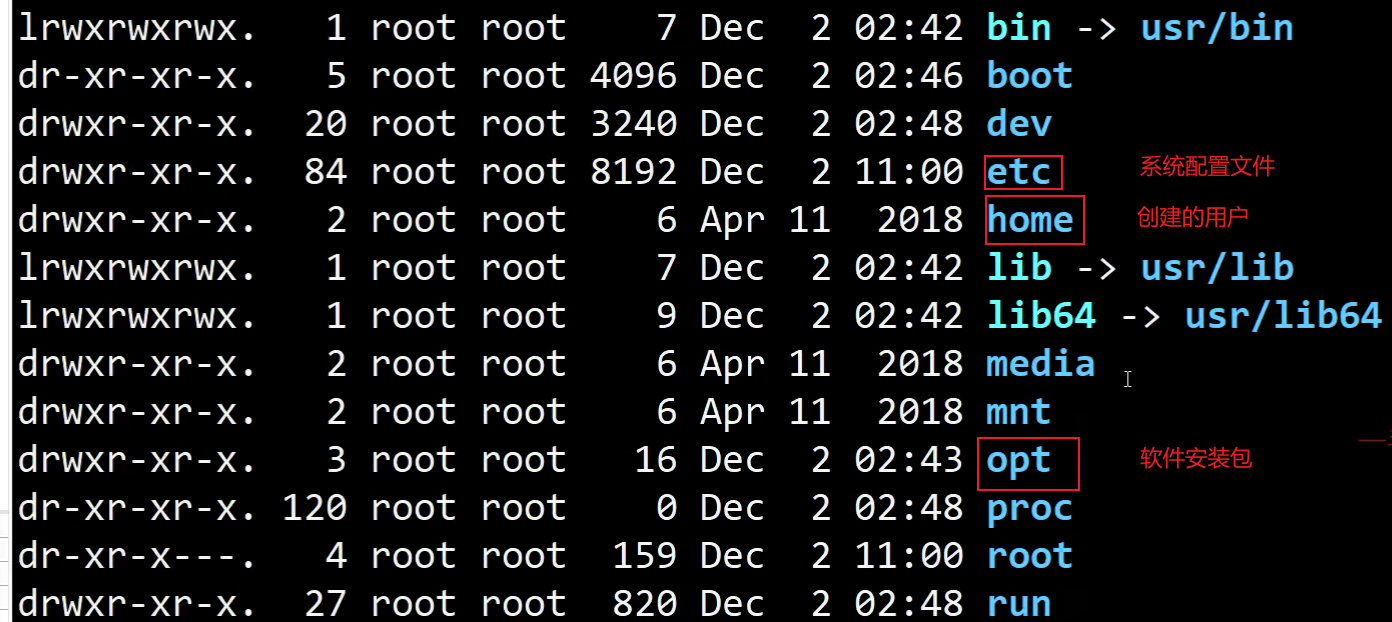
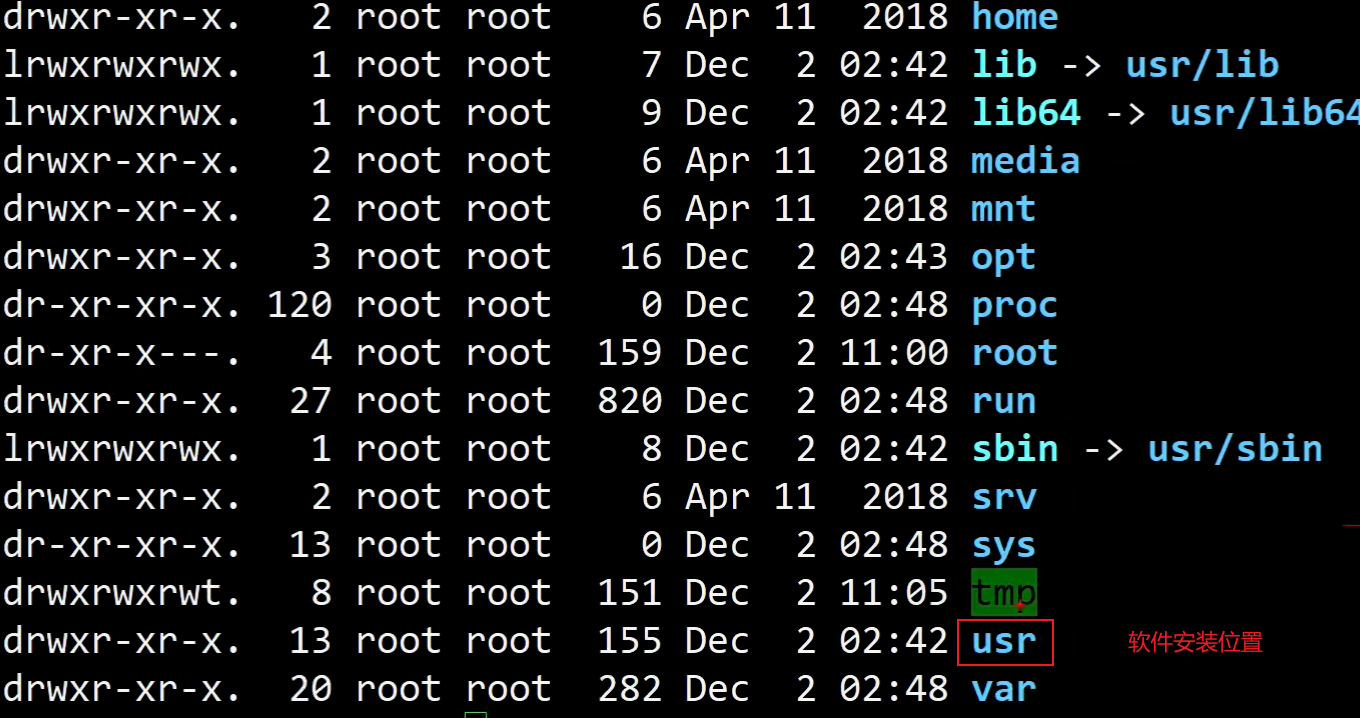
Linux路径
路径,顾名思议,是指从树形目录中的某个目录层次到某个文件的一条道路。Liux系统中是从/开始的。
绝对路径
绝对路径是指从“根"开始的路径。例如/usr/local,/etc/hosts,如果一个路径是从/开始它一定是绝对路径。
注意:
绝对路径必须以
/开头,它表示根目录。
相对路径
相对路径是以.或者..开始的。.表示用户操作所处的位置,..表示上级目录。
注意:
- 相对路径不能以
/开头。- 每个目录中都有
..目录文件。
在路径一些特殊符号的说明
.:当前用户所在目录..:表示上一级目录~:表示当前用户自己家目录~ USER:表示用户名为USER的家目录。这里的USER是在/etc/passwd中存在的用户。
Linux用户权限
Linux用户和用户组

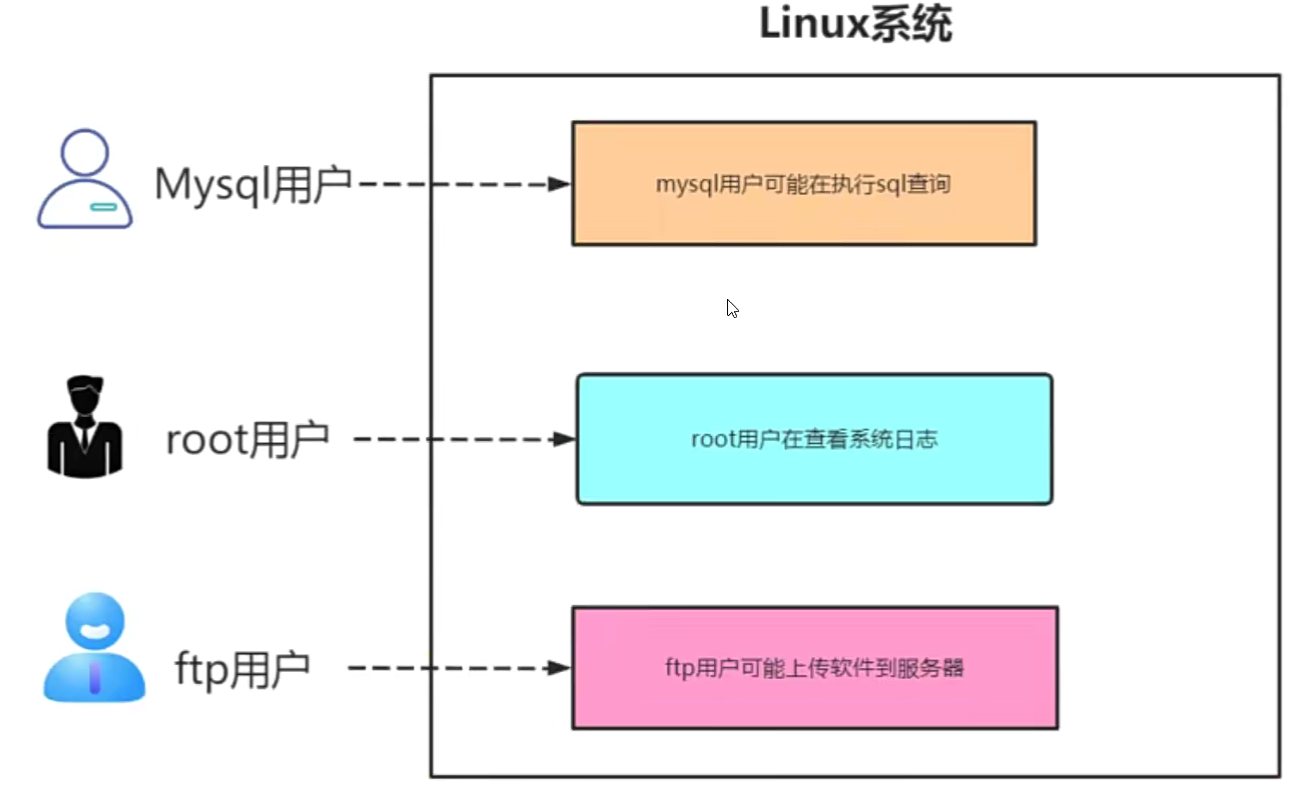
用户概念
通过前面对Linux多用户的理解,我们明白Linux是真正意义上的多用户操作系统,所以我们能在Linux系统中建若干用户(user)
用户组概念
用户组(group)就是具有相同特征的用户(user)的集合体;比如有时我们要让多个用户具有相同的权限,比如查看、修改某一文件或执行某个命令,这时我们需要用户组,我们把用户都定义到同一用户组,我们通过修改文件或目录的权限,让用户组具有一定的操作权限,这样用户组下的用户对该文件或目录都具有相同的权限,这是我们通过定义组和修改文件的权限来实现的,
Linux用户和组的关系
用户和用户组的对应关系有以下4种:
- 一对一:一个用户可以存在一个组中,是组中的唯一成员;
- 一对多:一个用户可以存在多个用户组中,此用户具有这多个组的共同权限;
- 多对一:多个用户可以存在一个组中,这些用户具有和组相同的权限;
- 多对多:多个用户可以存在多个组中,也就是以上3种关系的扩展。
Linux用户管理

Liux系统的管理员之所以是root,是因为该用户的身份号码即UID的数值为0,UID就相当于我们的身份证号码一样具有唯一性,因此可通过用户的UID值来判断用户身份。
- 管理员UID为0:系统的管理员用户。
- 系统用户UID为1 ~ 999:Liux系统为了避免因某个服务程序出现漏洞而被黑客提权至整台服务器,默认服务程序会有独立的系统用户负责运行,进而有效控制被破坏范围。
- 普通用户UID从1000开始:是由管理员创建的用于日常工作的用户。需要注意的是,UID是不能冲突的,而且管理员创建的普通用户的UID默认是从1000开始的(即使前面有闲置的号码)
添加用户
useradd [选项] 参数
选项说明:
- -d 指定用户的家目录(默认为/home/username)
- -e 账户的到期时间,格式为YYYY-MM-DD.
- -u 指定该用户的默认UID
- -g 指定一个初始的用户基本组(必须已存在)
- -G 指定一个或多个扩展用户组
- -N 不创建与用户同名的基本用户组
- -s 指定该用户的默认Shell解释器
参数:
用户名: 要创建的用户名。
案例实战
实例1:下面我们创建一个普通用户并指定家目录的路径、用户的UID以及Shll解释器。在下面的命令中,请注意/sbin/nologin,它是终端解释器中的一员,与Bash解释器有着天壤之别。一旦用户的解释器被设置为nologin,则代表该用户不能登录到系统中:
[root@node1 ~]# useradd -d /home/linux -u 8888 -s /sbin/nologin linuxprobe
[root@node1 ~]# id linuxprobe
uid=8888(linuxprobe) gid=8888(linuxprobe) groups=8888(linuxprobe)
修改帐号
修改用户账号就是根据实际情况更改用户的有关属性,如用户号、主目录、用户组、登录Shell等。
修改已有用户的信息使用usermod命令,其格式如下:
usermod [选项] 用户名
选项:
- -c<备注>:修改用户帐号的备注文字;
- -d<登入目录>:修改用户登入时的目录;
- -e<有效期那限>:修改帐号的有效期限;
- -f<缓冲天数>:修改在密码过期后多少天即关闭该帐号:
- -g<群组>:修改用户所属的群组;
- -G<群组>;修改用户所属的附加群组;
- -l<帐号名称>:修改用户帐号名称;
- -L:锁定用户密码,使密码无效;
- -s:修改用户登入后所使用的shell;
- -u:修改用户D;
- -U:解除密码锁定
常用的选项包括-c, -d, -m, -g, -G, -s, -u以及-o等,这些选项的意义与useradd命令中的选项一样,可以为用户指定新的资源值。
这个选项指定一个新的账号,即将原来的用户名改为新的用户名。
案例实战:
实例1:将用户jinxf的登录Shell修改为bash,主目录改为/home/z,用户组改为root。
[root@node1 ~]# cat /etc/passwd|grep gem
gm:x:1003:1000::/home/gm:/bin/sh
[root@node1 ~]# id gem
uid=1003(gem) gid=1000(gtjin) 组=1000(gtjin),0(root),4(adm)
[root@node1 ~]# usermod -s /bin/bash –g root gem
[root@node1 ~]# usermod -d /home/z -m gem
[root@node1 ~]# cat /etc/passwd|grep gem
gem:x:1003:0::/home/z:/bin/bash
删除帐号
如果一个用户的账号不再使用,可以从系统中删除。删除用户账号就是要将/etc/passwd等系统文件中的该用户记录删除,必要时还删除用户的主目录。
删除一个已有的用户账号使用userdel命令,其格式如下:
userdel [选项] 用户名
选项:
-f:强制删除用户
-r:同时删除用户及用户家目录
这个命令的目的删除用户,与它相关的文件有:
①/etc/passwd
②/etc/shadow
③/home/username
常用的选项是-r,它的作用是把用户的主目录一起删除。
[root@node1 ~]# userdel jinxf
此命令删除用户jinxf在系统文件中(主要是/etc/passwd, /etc/shadow, /etc/group等)的记录,同时删除用户的主目录。
用户口令的管理
用户管理的一项重要内容是用户口令的管理。用户账号刚创建时没有口令,但是被系统锁定,无法使用,必须为其指定口令后才可以使用,即使是指定空口令。
指定和修改用户口令的Shell命令是passwd。超级用户可以为自己和其他用户指定口令,普通用户只能用它修改自己的口令。命令的格式为:
passwd [选项] 用户名
可使用的选项:
- -d:删除密码,仅有系统管理者才能使用;
- -f:强制执行;
- -k:设置只有在密码过期失效后,方能更新;
- -l:锁住密码;
- -s:列出密码的相关信息,仅有系统管理者才能使用;
- -u:解开已上锁的帐号。
如果默认用户名,则修改当前用户的口令。
例如,假设当前用户是jinxf,则下面的命令修改该用户自己的口令:
[root@node1 ~]# passwd
Old password:
New password:*
Re-enter new password:*
如果是超级用户,可以用下列形式指定任何用户的口令:
[root@node1 ~]# passwd jinxf
New password:*
Re-enter new password:*
普通用户修改自己的口令时,passwd命令会先询问原口令,验证后再要求用户输入两遍新口令,如果两次输入的口令一致,则将这个口令指定给用户;而超级用户为用户指定口令时,就不需要知道原口令。
为了系统安全起见,用户应该选择比较复杂的口令,例如最好使用8位长的口令,口令中包含有大写、小写字母和数字,并且应该与姓名、生日等不相同。
为用户指定空口令时,执行下列形式的命令:
[root@node1 ~]# passwd -d jinxf
此命令将用户jinxf的口令删除,这样用户jinxf下一次登录时,系统就不再询问口令。
passwd命令还可以用-l(lock)选项锁定某一用户,使其不能登录,例如:
[root@node1 ~]# passwd -l jinxf
用户组管理
每个用户都有一个用户组,系统可以对一个用户组中的所有用户进行集中管理。不同Linux 系统对用户组的规定有所不同,如Linux下的用户属于与它同名的用户组,这个用户组在创建用户时同时创建。
用户组的管理涉及用户组的添加、删除和修改。组的增加、删除和修改实际上就是对/etc/group文件的更新。
添加新组groupadd
语法:
groupadd [选项] 用户组
选项:
- -g:指定新建工作组的id;
- -r:创建系统工作组,系统工作组的组ID小于500;
- -K:覆盖配置文件"/ect/login.defs";
- -o:允许添加组D号不唯一的工作组。
实例1:添加用户组group1
[root@node1 ~]# groupadd group1
此命令向系统中增加了一个新组group1,新组的组标识号是在当前已有的最大组标识号的基础上加1。
实例2:向系统中增加了一个新组group2,同时指定新组的组标识号是101
[root@node1 ~]# groupadd -g 101 group2
此命令向系统中增加了一个新组group2,同时指定新组的组标识号是101。
删除用户组groupdel
语法:
groupdel 用户组
实例1:从系统中删除组group1
[root@node1 ~]# groupdel group1
修改群组groupmod
语法:
groupmod [选项] 用户组
常用的选项有:
- -g<群组识别码>:设置欲使用的群组识别码;
- -o:重复使用群组识别码;
- -n<新群组名称>:设置欲使用的群组名称。
实例1:将组group2的标识号改为10000,组名修改为group3
[root@node1 ~]# groupmod –g 10000 -n group3 group2
用户切换组
如果一个用户同时属于多个用户组,那么用户可以在用户组之间切换,以便具有其他用户组的权限。
用户可以在登录后,使用命令newgrp切换到其他用户组,这个命令的参数就是目的用户组。例如:
[root@node1 ~]# newgrp root
这条命令将当前用户切换到root用户组,前提条件是root用户组确实是该用户的主组或附加组。类似于用户账号的管理,用户组的管理也可以通过集成的系统管理工具来完成。
Linuxi超级用户与伪用户
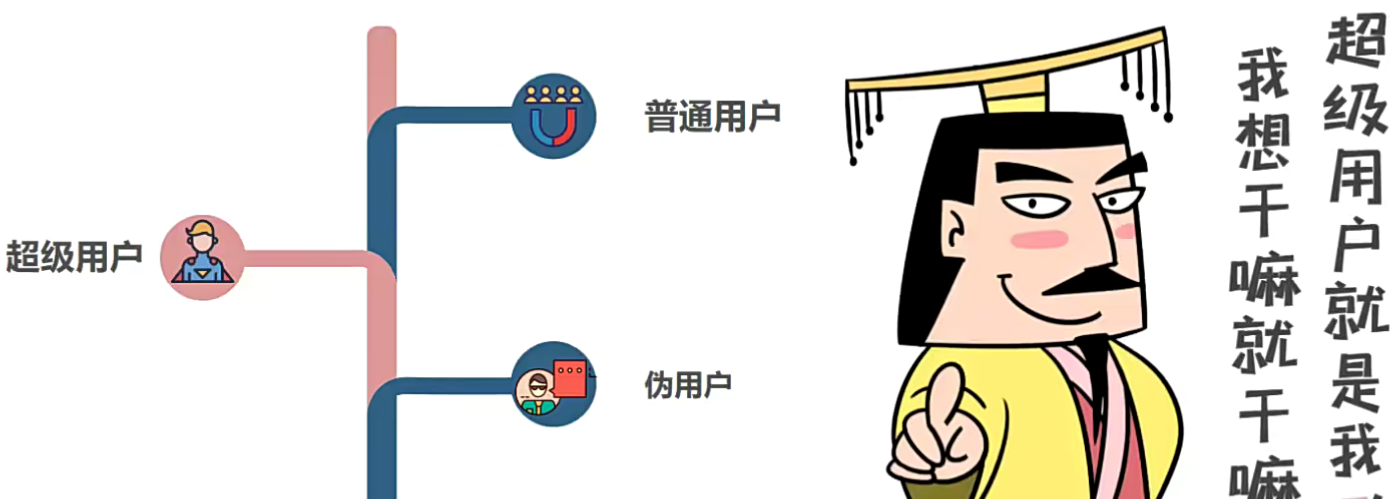
Liux下用户分为三类:超级用户、普通用户、伪用户
- 超级用户:用户名为root,具有一切管理权限,UID为0,可以创建多个管理员。
- 普通用户:在默认情况下,普通用户UID是介于500~6000;
- 伪用户:这些用户的存在是为了方便系统管理,满足相应的系统进程对文件属主的要求。伪用户不能够登录,他的UID值介于1 ~ 499。
用户身份切换
由于超级权限在系统管理中的不可缺少的重要作用,为了完成系统管理任务,必须用到超级权限。
su
su命令就是切换用户的工具。
语法
su [-fmp] [-c command] [-s shell] [--help] [--version] [-] [USER [ARG]]
参数说明:
- -c command或-command=command变更为帐号为USER的使用者并执丸行指令(command)后再变回原来使用者
- –i或–login这个参数加了之后,就好像是重新login为该使用者一样,大部份环境变数(HOME SHELL USER等等)都是以该使用者(USER)为主,并且工作目录也会改变,如果没有指定USER,内定是root
sudo
sudo的全称为:super user do。
顾名思义:干超级用户才能干的事!所以Sudo最常用的功能就是提升一个命名的执行权限。
语法:
sudo [参数] 命令名称
参数:
- -h:列出帮助信息
- -l:列出当前用户可执行的命令
- -u:用户名或UD值以指定的用户身份执行命令
- -k:清空密码的有效时间,下次执行sudo时需要再次进行密码验证
- -b:在后台执行指定的命令
- -p:更改询问密码的提示语
总结
sudo命令具有如下功能:
- 限制用户执行指定的命令:
- 记录用户执行的每一条命令;
- 配置文件(/etc/sudoers)提供集中的用户管理、权限与主机等参数;
- 验证密码的后5分钟内(默认值)无须再让用户再次验证密码。
**编辑配置文件命令:visudo**来配置用户权限。
按照下面的格式将第99行(大约)填写上指定的信息:
谁可以使用 允许使用的主机 =(以谁的身份)可执行命令的列表
niit ALL=(ALL) ALL
⚠️注意:
编辑sudo的配置文件/etc/sudoers,是一般不要直接使用vi(vi/etc/sudoers)去编辑,因为sudoers配置有一定的语法,直接用vi编辑保存系统不会检查语法,如有错也保存了可能导致无法使用sudo工具,最好使用visudo命令去配置。虽然visudo也是调用vi去编辑,但是保存时会进行语法检查,有错会有提示。
sudo免密配置:
visudo
niit ALL=NOPASSWD: ALL
Linux文件基本属性
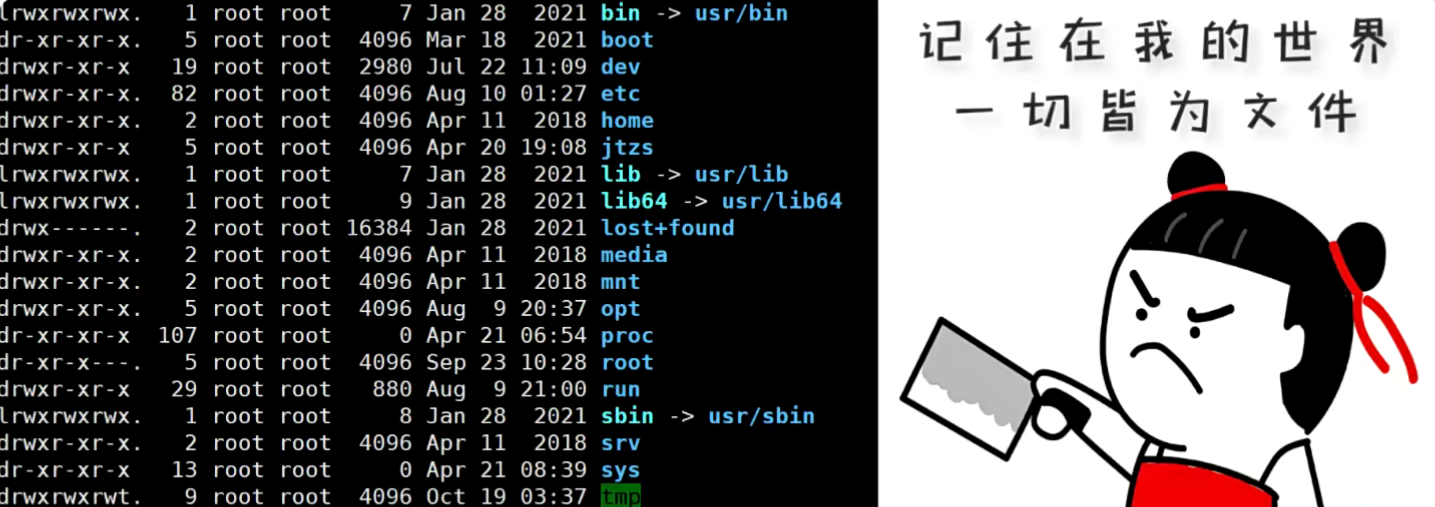
显示文件属性
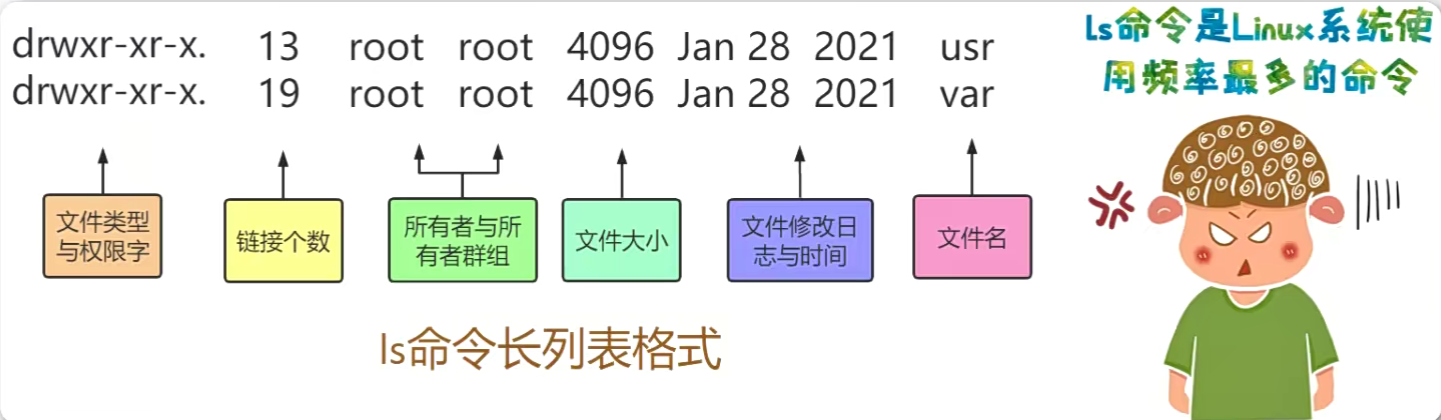
ls命令
Linux ls(英文全拼:list files)命令用于显示指定工作目录下之内容(列出目前工作目录所含之文件及子目录)。
语法:
ls [参数]
参数:
- -a 显示所有文件及目录(以 . 开头的隐藏文件也会列出)
- -l 除文件名称外,亦将文件型态、权限、拥有者、文件大小等资讯详细列出
- ls -l 的缩写 ll
Linux文件类型
Linux可以支持长达256个字符的文件名称,且文件名是区分大小写的,“abc”与"ABC"所代表的是不同文件。
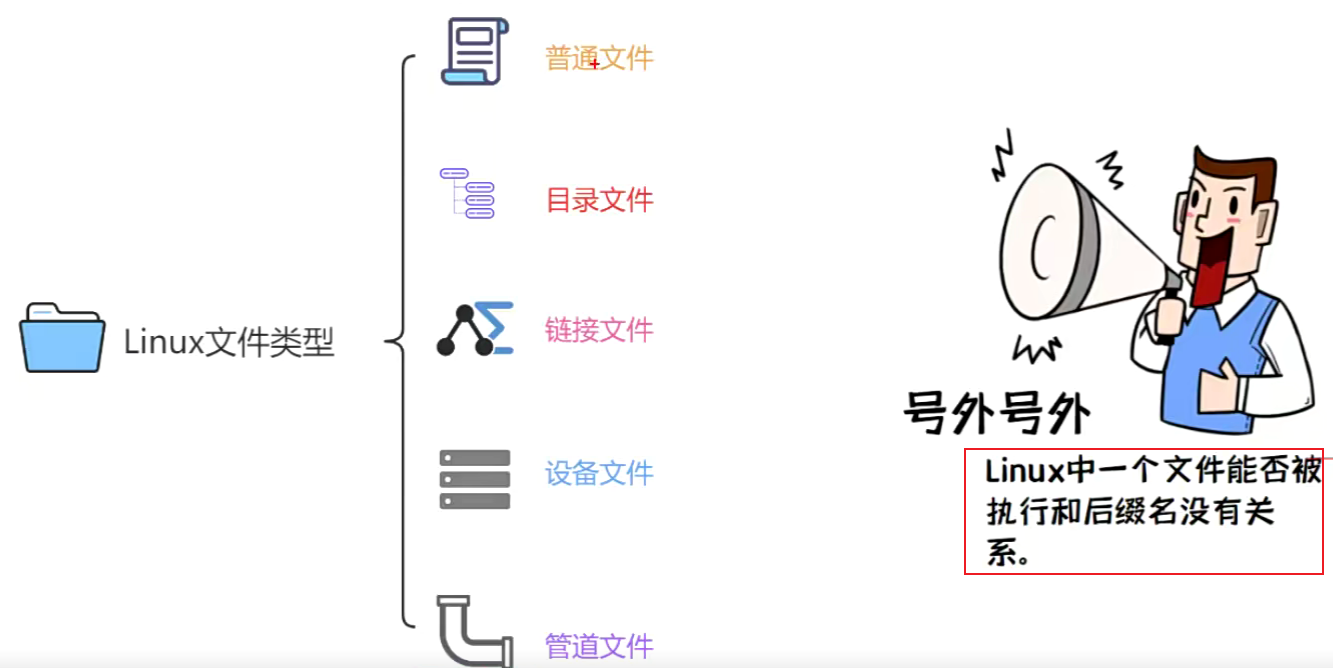
Linux文件类型
- 普通文件(-):存放数据,程序等信息的文件,一般为文本文件和二进制文件。
- 目录文件(d):文件系统中一个目录所包含的目录文件,包括文件名和子目录名
- 链接文件(l):可以在不同的文件系统之间建立链接关系来实现对文件的访问。
- 设备文件©:把IO设备映射为一个设备文件。
- 管道文件§:主要用于在进程间传递数据。
文件权限
所谓的文件权限,是指对文件访问权限,包括对文件的读、写、删除、执行操作。Linux是一个多用户操作系统,它运行多个用户同时登陆和工作,因此Linux将一个文件或者目录与一个用户和组联系起来。
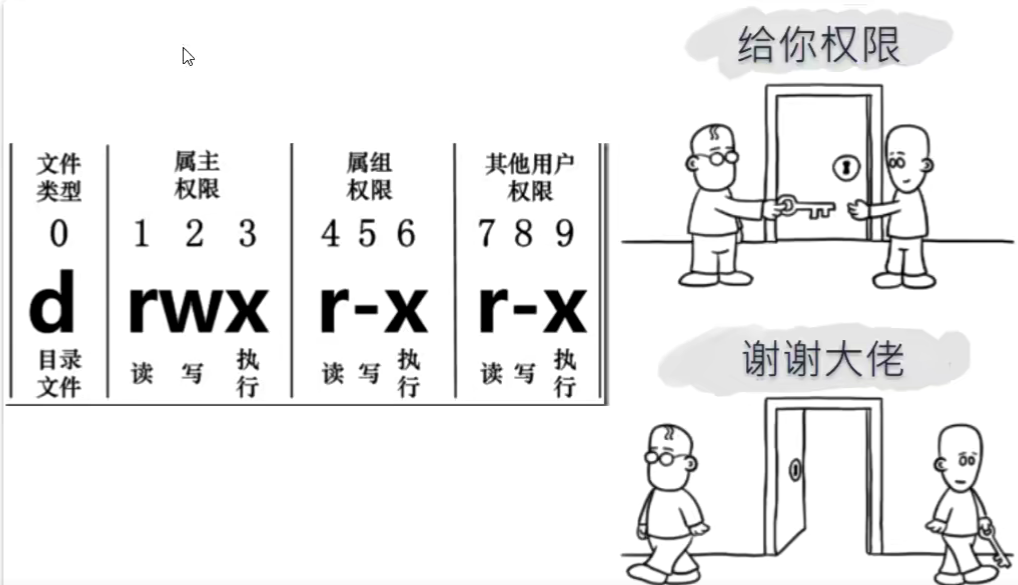
r(read):可读取此文件的实际内容,如读取文本文件的文字内容等;
w(write):可以编辑、新增或者是修改该文件的内容
x(execute):该文件具有可以被系统执行的权限。
⚠️**注意:**在Linux中,文件是否能被执行是由是否具有
x这个权限来决定,与拓展名无关。
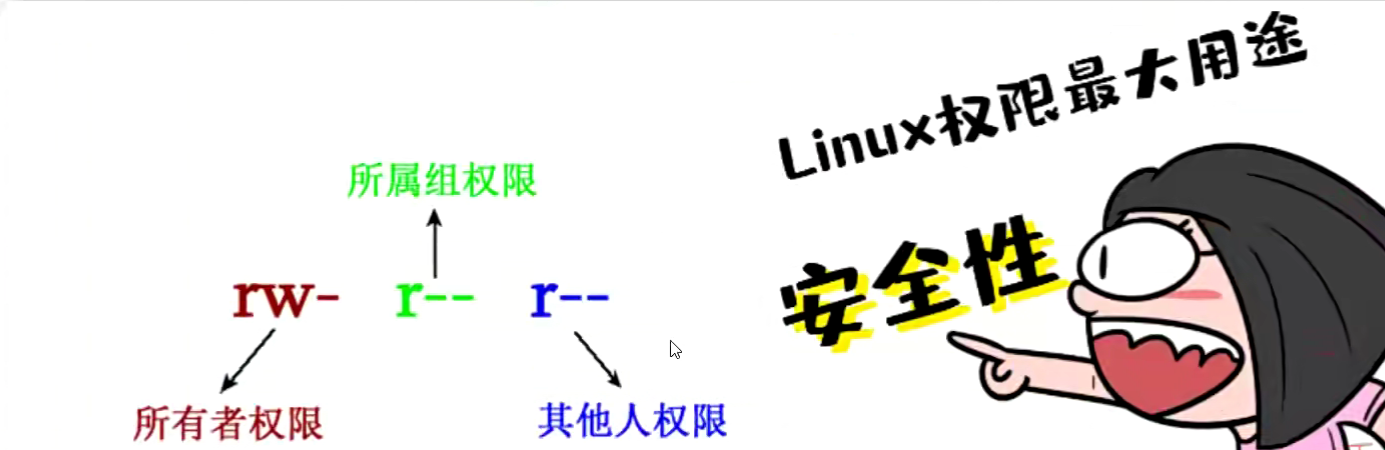
Linux权限字和权限操作

- chgrp:改变文件所属群组;
- chown:改变文件所有人;
- chmod:改变文件的属性;
改变所属群组chgrp
改变一个文件的群组很简单,直接用chgrp命令,这个命令是change group的缩写。
语法:
chgrp [-R] 属组名 文件名
参数选项
- -R:递归更改文件属组,就是在更改某个目录文件的属组时,如果加上-R的参数那么该目录下的所有文件的属组都会更改。
改变文件属性chmod
Liux文件属性有两种设置方法,一种是数字,一种是符号。
Linux文件的基本权限就有九个,分别是owner/group/others(拥有者/组/其他)三种身份各有自己的read/write/execute权限。
文字设定法
基本上就九个权限分别是:
- user:用户
- group:组
- others:其他
那么我们就可以使用u,g,o来代表三种身份的权限。
此外,a则代表all,即全部的身份。读写的权限可以写成r,w,x,也就是可以使用下表的方式来看:
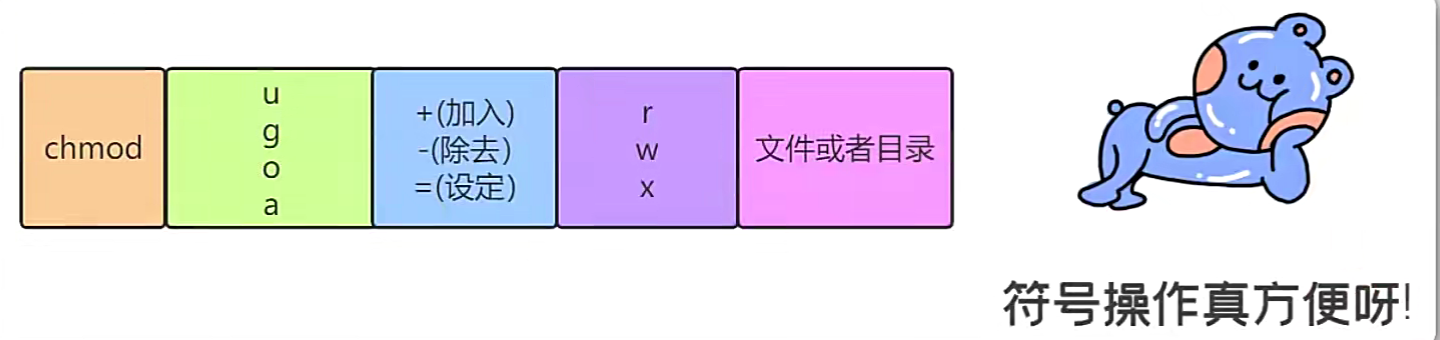
语法:
chmod [who] [+ | - | =] [mode]
chmod niit+w a.txt
数字设定法
我们必须首先了解用数字表示的属性的含义:0表示没有权限,1表示可执行权限,2表示可写权限,4表示可读权限,然后将其相加。所以数字属性的格式应为3个从0到7的八进制数,其顺序是(u) (g) (o)。
例如,如果想让某个文件的属主有“读/写”二种权限,需要把 4(可读)+ 2(可写)= 6(读写)。
先复习一下刚刚上面提到的数据:文件的权限字符为:-rwxrwxrwx,这九个权限是三个三个一组的!其中,我们可以使用数字来代表各个权限,各权限的分数对照表如下:
- r:4
- w:2
- x:1
改变文件拥有者chown
更改文件属主,也可以同时更改文件属组
语法:
chown [-R] 属主名 文件名
chown [-R] 属主名:属组名 文件名
Linux常用命令
更多详细内容见:
[OnlineEducationProject/Sprint0-环境搭建/NIIT-BD-PP-05-Linux Review-V1.1.md · 槐月初叁/23-S1-BigData_PP_Sprints_Learning ](https://gitee.com/huaiyuechusan/23-S1-BigData_PP_Sprints_Learning/blob/master/OnlineEducationProject/Sprint0-环境搭建/NIIT-BD-PP-05-Linux Review-V1.1.md#linux-常用终端快捷键)
Linux文件编辑工具vi/vim
vi/vim的使用
vi或vim是Linuxi最常用的文本编辑器工具,vi或vim没有图形界面编辑器那样单机鼠标的简单操作,但编辑器在系统管理、服务器管理中,永远是图形界面的编辑器所不能比的。
基本上vi/vim共分为三种模式:
- 命令模式(Cornmand mode)
- 输入模式(Insert mode)
- 底线命令模式(Last line mode)
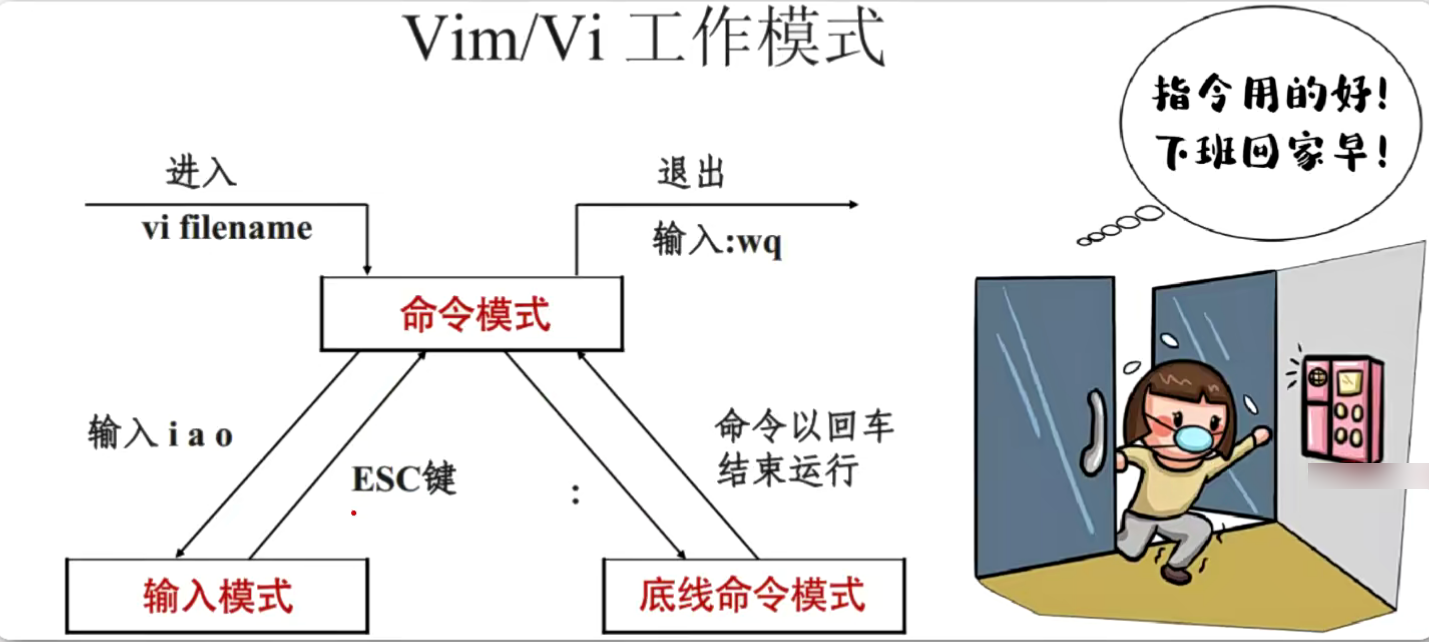
命令模式
用户刚刚启动vi/vim,便进入了命令模式。
此状态下敲击键盘动作会被识别为命令,而非输入字符。比如我们此时按下i,并不会输入一个字符,被当作了一个命令。
输入模式
在命令模式下按下i、o、a就进入了输入模式。
在输入模式中,可以使用以下按键:
- 字符按键以及Shift组合:输入字符
- ENTER:回车键,换行
- BACK SPACE:退格键,删除光标前一个字符
- DEL:删除键,删除光标后一个字符
- 方向键:在文本中移动光标
- HOME/END:移动光标到行首/行尾
- Page Up/Page Down:上/下翻页
- Insert:切换光标为输入/替换模式,光标将变成竖线下划线
- ESC:退出输入模式,切换到命令模式
底线命令模式
主要保存或者退出文件,以及设置Vim编辑器的工作环境,还可以让用户执行外部的Linux命令或跳转所编写文档的特定行数。
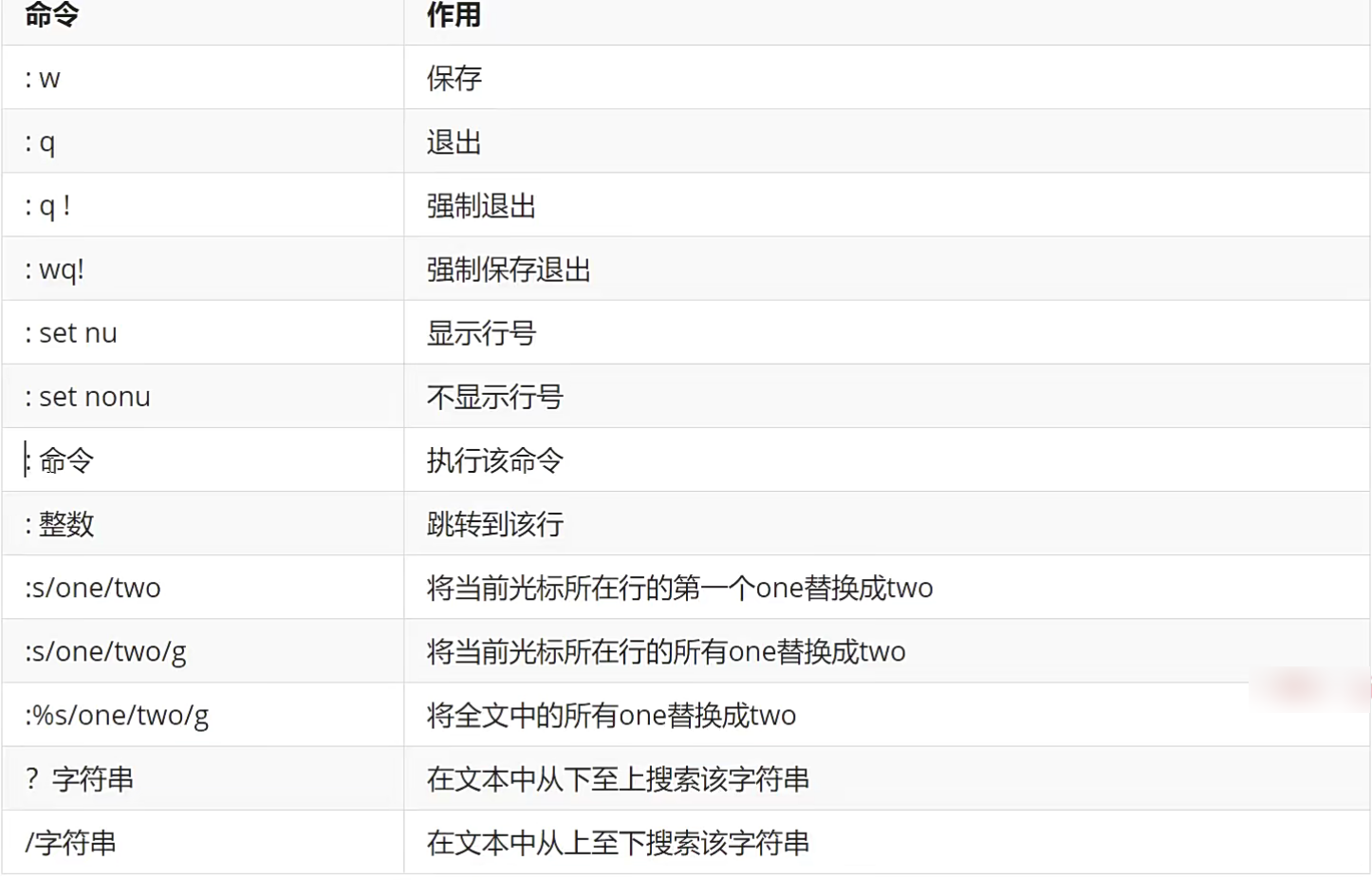
shift + zz 也可以保存退出
Linux处理文件目录的常用命令

pwd(显示目前所在目录)
pwd是Print Working Directory的缩写,也就是显示目前所在目录的命令。
[root@www ~] pwd [-P]
选项与参数:
-P:显示出确实的路径,而非使用连结(ink)路径。
mkdir(创建新目录)
如果想要创建新的目录的话,那么就使用mkdir(make directory)吧。
语法:mkdir [-mp] 目录名称
选项与参数:
- -m:配置文件的权限喔!直接配置,不需要看默认权限(umask)的脸色~
- -p:帮助你直接将所需要的目录(包含上一级目录)递归创建起来!
rmdir(删除空的目录)
语法:rmdir [-p] 目录名称
选项与参数:
-p:从该目录起,一次删除多级空目录
删除runoob目录
cp(复制文件或目录)
cp即拷贝文件和目录。copy的意思。
语法:cp [-adfilprsu] 来源档 目标档
选项与参数:
-r:递归持续复制,用于目录的复制行为
rm(删除文件或者目录)
语法:rm [-fir] 文件或目录
选项与参数:
- -f:就是force的意思,忽略不存在的文件,不会出现警告信息;
- -r:递归删除啊!最常用在目录的删除了!这是非常危险的选项!!!
mv(移动文件与目录,或修改名称)
语法:
mv [-fiu] source destination
mv [options] source1 source2 source3 ... directory
选项与参数:
- -f:force强制的意思,如果目标文件已经存在,不会询问而直接覆盖:
- -i:若目标文件(destination)已经存在时,就会询问是否覆盖!
- -u:若目标文件已经存在,且source比较新,才会升级(update)
Linux文件内容查看命令
cat(显示文件内容)
由第一行开始显示文件内容
语法:cat [-AbEnTv]
选项与参数:
- -A:相当于-vET的整合选项,可列出一些特殊字符而不是空白而已;
- -b:列出行号,仅针对非空白行做行号显示,空白行不标行号!
- -E:将结尾的断行字节$显示出来;
- -n:列印出行号,连同空白行也会有行号,与-b的选项不同;
- -T:将[tab]按键以N显示出来;
- -v:列出一些看不出来的特殊字符
tac(倒着显示文件内容)
tac与cat命令刚好相反,文件内容从最后一行开始显示,可以看出tac是cat的倒着写!
如:tac /etc/issue
nl(显示行号)
语法:n1 [-bnw] 文件
选项与参数:
-b:指定行号指定的方式,主要有两种:
-b a:表示不论是否为空行,也同样列出行号(类似cat -n);
-b t:如果有空行,空的那一行不要列出行号(默认值);
-n:列出行号表示的方法,主要有三种:
-n ln:行号在荧幕的最左方显示;
-n rn:行号在自己栏位的最右方显示,且不加0;
-n rz:行号在自己栏位的最右方显示,且加0;
-W:行号栏位的占用的位数
more(一页一页的显示文件内容)
一页一页翻动
在more这个程序的运行过程中,你有几个按键可以按的:
- 空白键(space):代表向下翻一页;
- Enter:代表向下翻『一行」;
/字串:代表在这个显示的内容当中,向下搜寻『字串』这个关键字;- :f:立刻显示出档名以及目前显示的行数:
- q:代表立刻离开more,不再显示该文件内容。
- b或[ctrl]-b:代表往回翻页,不过这动作只对文件有用,对管线无用。
Iess(往前翻页)
一页一页翻动,以下实例输出/etc/man.config文件的内容:
Iess运行时可以输入的命令有:
- 空白键:向下翻动一页;
- [pagedown]:向下翻动一页;
- [pageup]:向上翻动一页;
- /字串:向下搜寻『字串』的功能;
- ?字串:向上搜寻『字串』的功能;
- n:重复前一个搜寻(与/或?有关!)
- N:反向的重复前一个搜寻(与/或?有关!)
- q:离开less这个程序;
head(只看头几行)
取出文件前面几行
语法:head [-n number] 文件
选项与参数:
- -n:后面接数字,代表显示几行的意思
tail(只看尾几行)
取出文件后面几行
语法:tail [-n number] 文件
选项与参数:
- -n:后面接数字,代表显示几行的意思
- -f:表示持续侦测后面所接的档名,要等到按下[ctrl]-c才会结束tail的侦测
Linux打包压缩命令
tar命令
语法:tar [选项] [文件]
选项:
- -c:产生.tar打包文件
- -v:显示详细信息
- -f:指定压缩后的文件名
- -z:打包同时压缩Gzip
- -x:解包.tar文件
# 打包多个文件
tar -zcvf test.tar.gz a.txt b.txt c.txt
# 解压文件
tar -zxvf test.tar.gz
# 解压文件到指定目录
tar -zxvf test.tar.gz -C /opt
gzip/gunzip压缩
语法:
gzip+文件 (功能描述:压缩文件,只能将文件压缩为*.gz文件)
gunzip+文件.gz (功能描述:解压缩文件命令)
Linux搜索命令
grep命令
grep命令用于在文本中执行关键词搜索,并显示匹配的结果。
语法:
grep [参数 查找内容 源文件]
选项:
- -b:将可执行文件(binary)当作文本文件(text)来搜索
- -c:仅显示找到的行数
- -i:忽略大小写
- -n:显示行号
- -v:反向选择一仅列出没有"关键词"的行
- -E:开启扩展(Extend)的正则表达式
grep -n "a" a.txt
find命令
find命令用于按照指定条件来查找文件。
语法:
find [查找路径] 寻找条件 操作
选项:
- -name:匹配名称
- -perm:匹配权限(mode为完全匹配,-mode为包含即可)
- -user:匹配所有者
- -group:匹配所有组
- -mtime -n +n:匹配修改的间(-n指n天以内,+n指n天以前)
- atime -n +n:匹配访问文件的时间(-n指n天以内,+n指n天以前)
- -ctime -n +n:匹配修改文件权限的时间(-n指n天以内,+n指n天以前)
- -nouser:匹配无所有者的文件
- -nogroup:匹配无所有组的文件
- -newer f1 !f2:匹配比文件f1新但比f2I旧的文件i
- –type b/d/c/p/l/f:匹配文件类型
(后面的字幕参数依次表示块设备、目录、字符设备、管道、链接文件、文本文件)- -size:匹配文件的大小(+50KB为查找超过50KB的文件,而-50KB为查找小于50K的文件)
- -prune:忽略某个目录-exec…{}\;后面可跟用于进一步处理搜索结果的命令
Linux常用系统工作命令
reboot命令
reboot命令用于重启系统,其格式为reboot。
由于重启计算机这种操作会涉及硬件资源的管理权限,因此默认只能使用root管理员来重启,其命令如下:
[root@linuxprobe ~]# reboot
poweroff命令
poweroff命令用于关闭系统,其格式为poweroff。
该命令与reboot命令相同,都会涉及硬件资源的管理权限,因此默认只有root管理员才可以关闭电脑,其命令如下:
[root@linuxprobe ~]# poweroff
wget命令
wget命令用于在终端中下载网络文件。
语法:
wget [参数] 下载地址
参数:
- -b:后台下载模式
- -P:下载到指定目录
- -t:最大尝试次数
- -c:断点续传
- -p:下载页面内所有资源,包括图片、视频等
- -r:递归下载
Linux重定向、管道符、通配符和环境变量

输入输出重定向
把多个Linux命令适当地组合到一起,使其协同工作,以便我们更加高效地处理数据。
- 标准输入重定向(STDN,文件描述符为0):默认从键盘输入,也可从其他文件或命令中输入。
- 标准输出重定向(STDOUT,文件描述符为1):默认输出到屏幕。
- 错误输出重定向(STDERR,文件描述符为2):默认输出到屏幕。
输入重定向作用表

输出重定向作用表

管道命令符
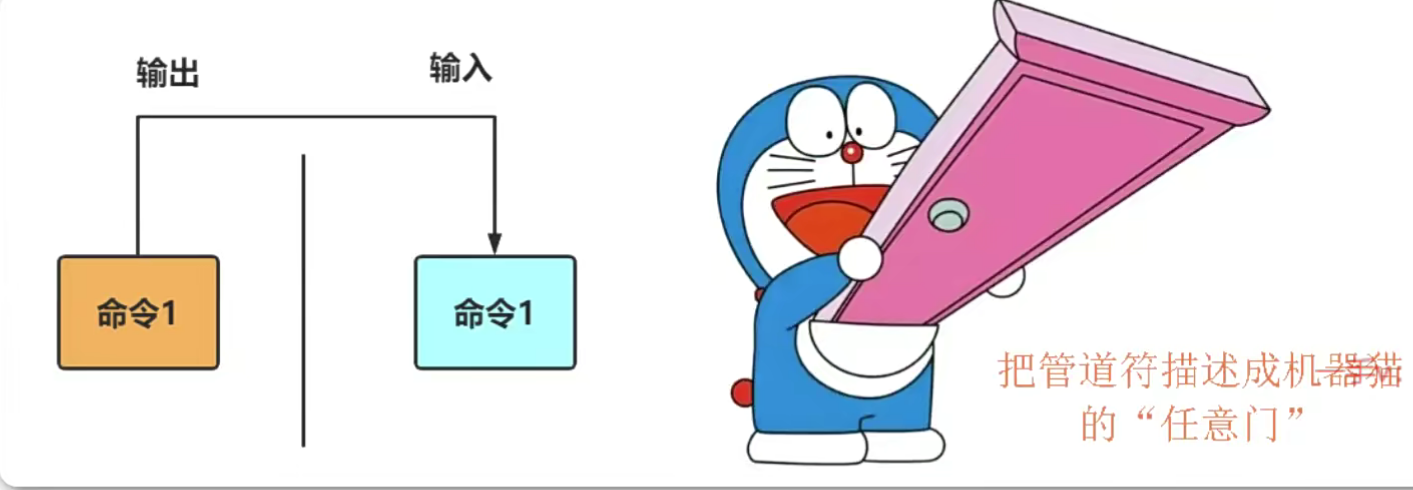
管道命令符的执行格式:命令A | 命令B
命令符的作用:把前一个命令原本要输出到屏幕的数据当作是后一个命令的标准输入
实例1:
找出被限制登录用户的命令是 grep "/sbin/nologin" /etc/passwd
统计文本行数的命令则是 wc -l
现在要做的就是把搜索命令的输出值传递给统计命令,即把原本要输出到屏幂的用户信息列表再交给wc命令作进一步的加工,因此只需要把管道符放到两条命令之间即可,具体如下。这简直是太方便了!
grep "/sbin/nologin" /etc/passwd | wc -l
实例2:
这个管道符就像一个法宝,我们可以将它套用到其他不同的命令上,比如用翻页的形式查看/etc目录中的文件列表及属性信息(这些内容默认会一股脑儿地显示到屏幕上,根本看不清楚)
ls -l /etc/ | more
实例3:
在修改用户密码时,通常都需要输入两次密码以进行确认,这在编写自动化脚本时将成为一个非常致命的缺陷。通过把管道符和passwd命令的-stdin参数相结合,我们可以用一条命令来完成密码重置操作:
echo "linuxprobe" | passwd --stdin root
可以连续使用管道符
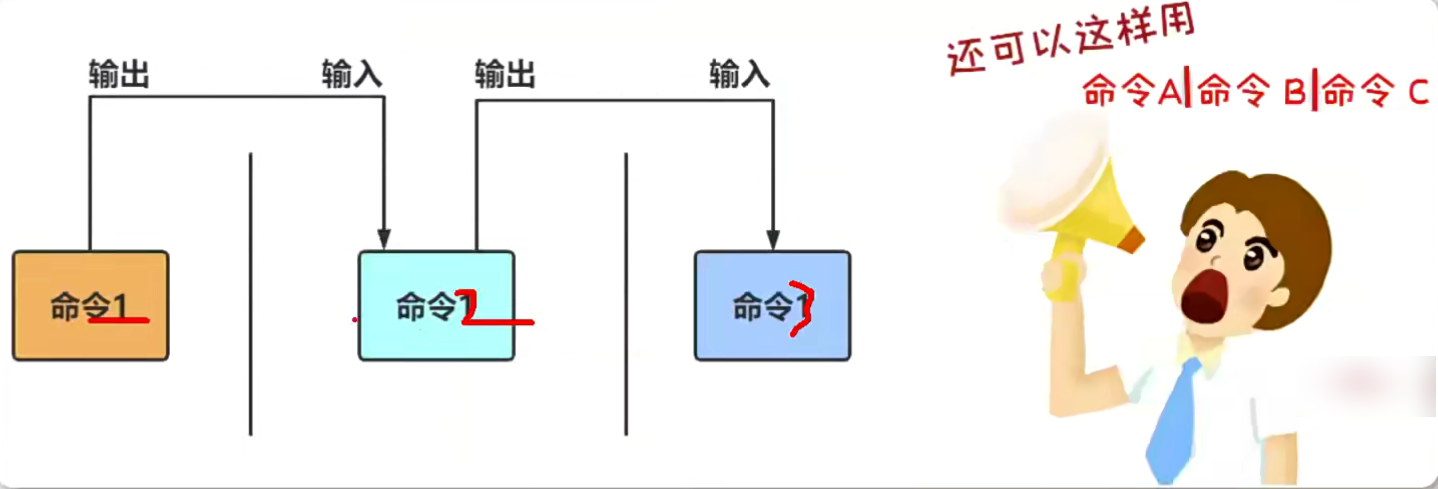
命令行的通配符
通配符就是通用的匹配信息的符号。
星号*代表匹配零个或多个字符,
问号?代表匹配单个字符,
中括号内加上数字[0-9]代表匹配0~9之间的单个数字的字符,
中括号内加上字母[abc]侧是代表匹配a、b、c三个字符中的任意一个字符。
重要的环境变量
在Liux系统中,环境变量按照其作用范围不同大致可以分为系统级环境变量和用户级环境变量。
- 系统级环境变量:每一个登录到系统的用户都能够读取到系统级的环境变量
- 用户级环境变量:每一个登录到系统的用户只能够读取属于自己的用户级的环境变量
自然而然地,环境变量的配置文件也相应的被分成了系统级和用户级两种。
系统级
/etc/profile
在系统启动后第一个用户登录时运行,并从/etc/profile.d目录的配置文件中搜集shell的设置,使用该文件配置的环境变量将应用于登录到系统的每一个用户。
提示:
在Liux系统中,使用以下命令可以使配置文件立刻生效。
source /etc/profile
echo $PATH
用户级
~/.profile(推荐首选)
当用户登录时执行,每个用户都可以使用该文件来配置专属于自己使用的shell信息。
实例1:配置tomcat环境变量
vim /etc/profile
export TOMCAT_HOME=
export PATH=$PATH:$TOMCAT_HOME/bin
Linux磁盘管理
fdisk
查看分区
语法:
fdisk [必要参数] [选择参数]
必要参数:
- -m:查看全部可用的参数
- -n:添加新的分区
- -d:删除某个分区信息
- -l:列出所有可用的分区类型
- -t:改变某个分区的类型
- -p:查看分区信息
- -w:保存并退出
- -q:不保存直接退出
磁盘计算公式
一个磁盘的大小=一个柱面大小柱面的总数=磁头数量每个磁道上的扇区数一个扇区大小柱面总数
df
用于显示Liux系统中各文件系统的硬盘使用情况,包括文件系统所在硬盘分区的总容量、已使用的容量、剩余容量等。
语法:
df [选项] [目录或文件名]
选项:
- -a:显示所有文件系统信息,包括系统特有的/proc、/sysfs等文件系统;
- -m:以MB为单位显示容量:
- -k:以KB为单位显示容量,默认以KB为单位;
- -h:使用人们习惯的KB、MB或GB等单位自行显示容量;
- -T:显示该分区的文件系统名称;
- -i:不用硬盘容量显示,面是以盒有Qd日的数量来显示。
软硬方式链接
Linux系统中的“快捷方式”了。
在Linuⅸ系统中存在硬链接和软链接两种文件。
硬链接:可以将它理解为一个“指向原始文件inode的指针”,系统不为它分配独立的inode和文件。所以,硬链接文件与原始文件其实是同一个文件,只是名字不同。我们每添加一个硬链接,该文件的inode连接数就会增加1;而且只有当该文件的inode连接数为0时,才算彻底将它删除。换言之,由于硬链接实际上是指向原文件inode的指针,因此即便原始文件被删除,依然可以通过硬链接文件来访问。需要注意的是,由于技术的局限性我们不能跨分区对目录文件进行链接。
软链接:仅仅包含所链接文件的路径名,因此能链接目录文件,也可以跨越文件系统进行链接。但是,当原始文件被删除后,链接文件也将失效,从这一点上来说与Windows系统中的“快捷方式”具有一样的性质。
In命令
In命令用于创建链接文件。
语法:
ln [选项] 目标
参数:
- -s:创建“符号链接”(如果不带-s参数,则默认创建硬链接)
- -f:强制创建文件或目录的链接
- -i:覆盖前先询问
- -v:显示创建链接的过程
Linux系统状态检测命令
ip addr(ifconfig)命令
命令用于获取网卡配置与网络状态等信息。
uname命令
uname命令用于查看系统内核与系统版本等信息。
uname -a
Linux zk33.10.0-1160.e17.x8664#1 SMP Mon0ct1916:18:59 UTC 2020 x86_64 x86_64 x86_64 GMU/Linux
注意:
在使用uname命令时,一般会固定搭配上-a参数来完整地查看当前系统的内核名称,主机名、内核发行版本、节点名、系统时间、硬件名称、硬件平台、处理器类型以及操作系统名称等信息。
查看系统版本 cat /etc/redhat-release
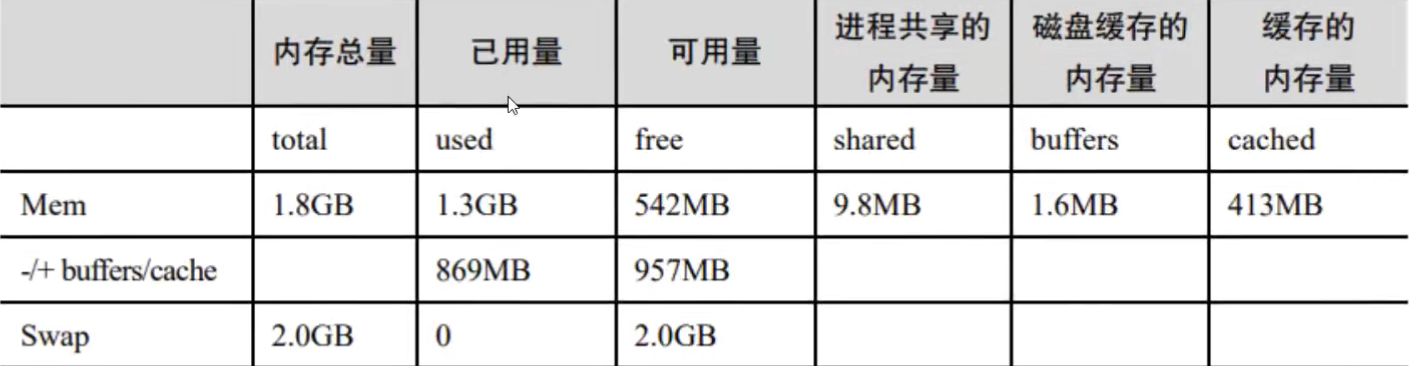
free命令
free用于显示当前系统中内存的使用量信息。
free -h
last命令
last命令用于查看所有系统的登录记录。
语法:
last [参数]
注意:
使用Iast命令可以查看本机的登录记录。但是,由于这些信息都是以日志文件的形式保存在系统中,因此黑客可以很容易地对内容进行篡改。干万不要单纯以该命令的输出信息而判断系统有无被恶意入侵!
history命令
history命令用于显示历史执行过的命令。
语法:
history [-c]
注意:
执行history命令能显示出当前用户在本地计算机中执行过的最近1000条命令记录。如果觉得1000不够用,还可以自定义/etc/profile文件中的HISTSIZE变量值。在使用history命令时,如果使用-c参数则会清空所有的命令历史记录。
uptime命令
uptime用于查看系统的负载信息,格式为uptime。
[root@niit opt]# uptime
17:56:03up7:14,2 users,1 oad average:0.02,0.02,0.05
注意:
uptime命令真的很棒,它可以显示当前系统时间、系统已运行时间、启用终端数量以及平均负载值等信息。平均负载值指的是系统在最近1分钟、5分钟、15分钟内的压力情况;负载值越低越好,尽量不要长期超过1,在生产环境中不要超过5。
Linux下软件安装的命令
源码安装
以源代码安装软件,每次都需要配置操作系统、配置编译参数、实际编译,最后还要依据个人喜好的方式来安装软件。这个过程很麻烦很累人。
rpm软件包管理
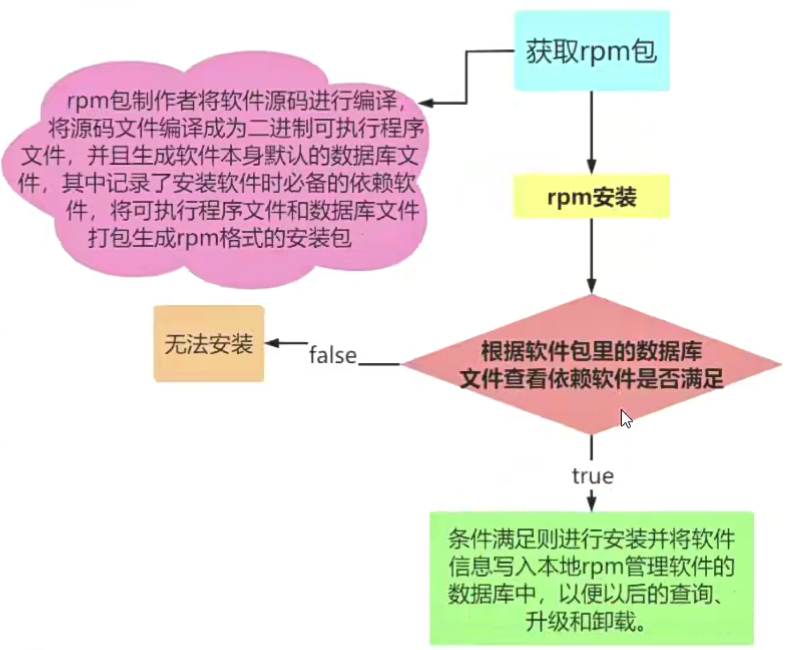
rpm安装软件的默认路径
注意:
- /etc配置文件放置目录
- /usr/bin一些可执行文件
- /usr/lib一些程序使用的动态链接库
- /usr/share/doc一些基本的软件使用手册与说明文件
- /usr/share/man一些man page档案
常用的rpm软件包命令
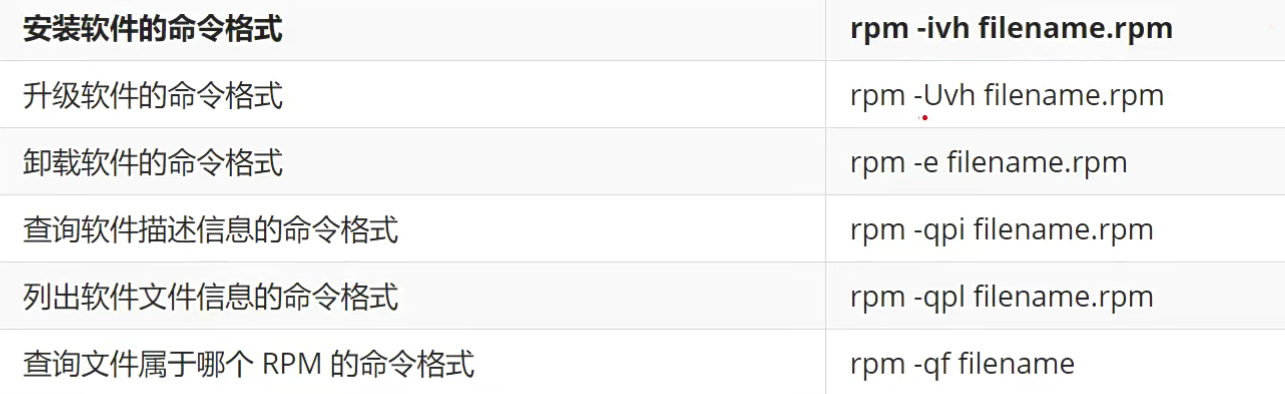
参数说明:
- -i:install的意思,安装
- -v:查看更详细的安装信息画面
- -h:以安装信息栏显示安装进度
软件安装
如你需要安装一个jdk,首先要到网上下载一个jdk的rpm包,如jdk-8u171–linux-x64.rpm。安装并显示安装的进度,命令如下:
rpm -ivh package-name
卸载软件
使用rpm的卸载过程一定要由最上层往下卸载,以rp-pppoe为例,这个软件主要是依据ppp这个软件来安装的,所以当你要卸载ppp的时候,就必须先卸载rp-pppoe才行!
删除的命令非常简单,通过-e参数就可以完成。不过,经常生软件属性依赖导致无法删除某些软件的问题。
rpm -e package-name
直接强制删除
rpm -e --nodeps package-name
yum
yum可以看作是CS架构的软件,yum的存在很好的解决了rpm的属性依赖问题。
yum通过依赖rpm软件包管理器,实现了rpm软件包管理器在功能上的扩展,因此yum是不能脱离rpm而独立运行的。
注意:
yum是一个在线软件管理工具,所以使用yum进行的操作大都是需要在联网的条件下才能正常使用。
YUM的配置文件
容器说明
虽然yum是你在联网后就能直接使用,不过,由于你系统的站点镜像没选择好,会导致连接速度非常慢!所以,这时候就需要我们去手动修改yum的设置文档了。
容器查询
首先,可以先查询一下目录yum server所使用的容器有哪些。
使用命令:yum repolist all,查询结果如下:
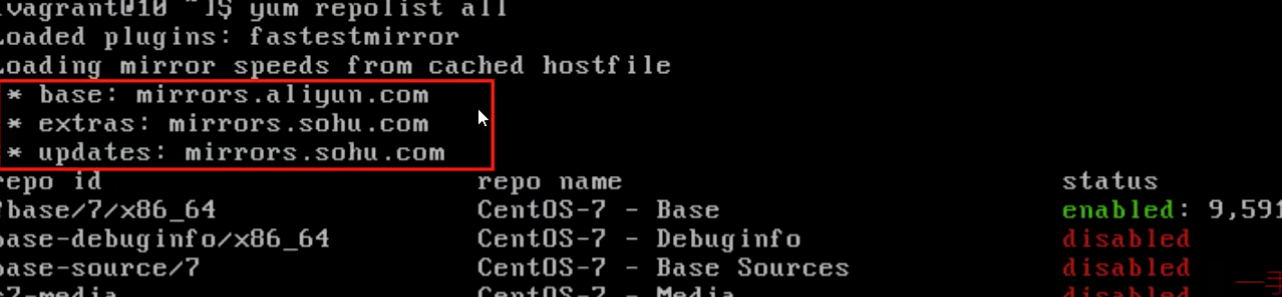
如上图,只有当最右边的status为enabled该容器才算激活
/etc/yum.repos.d/里面会有多个配置文件(文件名以.repo结尾),yum会从里面逐查找,所以里面的容器名称不能有重复。
配置文件修改
打开配置文件:vim /etc/yum.repos.d/CenOS-Base.repo
实例1:配置阿里yum源
1:安装wget (如果已经安装了则省略)
yum install -y wget
2:备份 /etc/yum.repos.d/Centos-Base.repo文件
cd /etc/yum.repos.d/
mv Centos-Base.repo Centos-Base.repo.back
3:下载阿里云的Centos-7.repo文件
wget -0 Centos-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
4:重新加载yum
yum clean all
yum makecache
5:检查配置的源是否是阿里的
cat /etc/yum.repos.d/Centos-Base.repo
yum使用手册
小技巧:
使用参数-y,当遇到需要等待用户输入时,这个选项会提供yes的响应,如上面的例子可以写成:
yum install -y emacs
Linux下常用软件安装_MySql安装
安装MySQL
下载YUM库
wget http://dev.mysql.com/get/mysql57-community-release-el7-10.noarch.rpm
安装YUM库
rpm -ivh mysql57-community-release-el7-10.noarch.rpm
安装数据库
yum -y install mysql-community-server
报错

解决办法:不对gpg进行验证
ny install mysql-community-server --nogpgcheck
完成安装,重启mysql
systemctl restart mysqld
此时MySQL已经开始正常运行,不过要想进入MySQL还得先找出此时root用户的密码,通过如下命令可以在日志文件中找出密码:
grep "password" /var/log/mysqld.log
[root@hadoop8 ~]# grep "password"/var/log/mysqld.log
2018-10-13T08:33:27.994868Z 1 [Note]A temporary password is generated for root@localhost:yjov.Ow*ywPk
复制粘贴上边的密码进入数据库
mysql -uroot -p
输入初始密码,此时不能做任何事情,因为MySQL默认必须修改密码之后才能操作数据库
修改密码命令:
mysql> ALTER USER 'root'@'localhost'IDENTIFIED BY '123456';
Your password does not satisfy the current policy requirements
解决报错如下
修改密码策略
因为当前的密码太复杂不方便后期做实验,所以使用命令修改密码策略两种方式
mysql> set global validate_password_policy=0;
Query OK,0 rows affected (0.00 sec)
mysql> set global validate_password_policy=LoW;
Query OK,0 rows affected (0.00 sec)
mysql>SET GLOBAL validate_password_length=6;
Query OK,0 rows affected (0.00 sec)
注:执行完初始化命令后需要输入数据库root用户密码
注:密码策略分四种
1、OFF(关闭) 2、LOw(低) 3、MEDIUM(中) 4、STRONG(强)
修改密码
mysql> ALTER USER 'root'@'localhost'IDENTIFIED BY '123456';
开启MySQL远程连接
mysql> select User,Host,Password from user;
mysql> update user set host ="%" where user "root";
# 刷新信息
mysq1> flush privileges;
Linux下常用软件安装_MySql卸载
检查是否安装了MySQL组件
[root@localhost ~]rpm -qa grep -i mysql
mysq157-community-release-el7-10.noarch
mysq1-community-libs-5.7.36-1.el7.x86_64
mysq1-community-server-5.7.36-1.el7.x86_64
mysql-community-common-5.7.36-1.el7.x86_64
mysq1-community-client-5.7.36-1.el7.x86_64
mysq1-community-libs-compat-5.7.36-1.el7.x86_6
卸载前关闭MySQL服务
systemctl stop mysqld
systemctl status mysqld
收集MySQL对应的文件夹信息
whereis mysql
mysql:/usr/bin/mysql /usr/1ib64/mysql /usr/share/mysql /usr/share/man/man1/mysql.1.gz
卸载删除MySQL各类组件
rpm -ev --nodeps mysq157-community-release-el7-10.noarch
rpm -ev --nodeps mysq1-community-libs-5.7.36-1.el7.x86_64
rpm -ev --nodeps mysql-community-server-5.7.36-1.e17.x86_64
rpm -ev --nodeps mysq1-community-common-5.7.36-1.el7.x86_64
rpm -ev --nodeps mysq1-community-client-5.7.36-1.el7.x86_64
rpm -ev --nodeps mysql-community-libs-compat-5.7.36-1.e17.x86_64
删除MySQL对应的文件夹
[root@DB-Server init.d]# whereis mysql
mysql:
[root@DB-Server init.d]# find /-name mysql
/var/lib/mysql
/var/1ib/mysql/mysql
/usr/lib64/mysql
[root@DB-Server init.d]# rm -rf /var/lib/mysql
[root@DB-server init.d]# rm -rf /var/lib/mysq1/mysql
[root@DB-Server init.d]# rm -rf /usr/lib64/mysql
删除mysql用户及用户组
[root@DB-Server init.d]# rpm -qa | grep -i mysql
Linux进程管理
ps
查看系统中所有进程
语法:
ps [options] [--help]
参数:
- -a:显示所有进程(包括其他用户的进程)
- -u:用户以及其他详细信息
- -x:显示没有控制终端的进程
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
USER:行程拥有者
PID:pid
%CPU:占用的CPU使用率
%MEM:占用的记忆体使用率
VSZ:占用的虚拟记忆体大小
RSS:占用的记忆体大小
TTY:终端的次要装置号码(minor device number of tty)
STAT:该行程的状态:
D:无法中断的休眠状态(通常IO的进程)
R:正在执行中
S:静止状态
T:暂停执行
Z:不存在但暂时无法消除
W:没有足够的记忆体分页可分配
<:高优先序的行程
N:低优先序的行程
L:有记忆体分页分配并锁在记忆体内(实时系统或捱A/O)
START:行程开始时间
TIME:执行的时间
COMMAND:所执行的指令

实例1:找出和cron与syslog这两个服务有关的PID号码。
[root@zk3 home]# ps -aux | egrep '(cron syslog)'
root 714 0.0 0.1 126388 1680? Ss Oct17 0:01 /usr/sbin/crond -n
root 1069 0.0 0.4 222780 4552? ssl Oct17 0:49 /usr/sbin/rsyslogd -n
root 15844 0.0 0.0 112808 988 pts/0 R+ 10:39 0:00 grep -E --color=auto (cron|syslog)
温馨提示:
egrep是grep的扩展和grep -e是一样的
grep中的匹配字符,全部当作字符串来处理,但是不支持正则表达式的特殊元字符
egrep可以支特元字符
^:指匹配的字符串在行首,
$:指匹配的字符串在行尾,
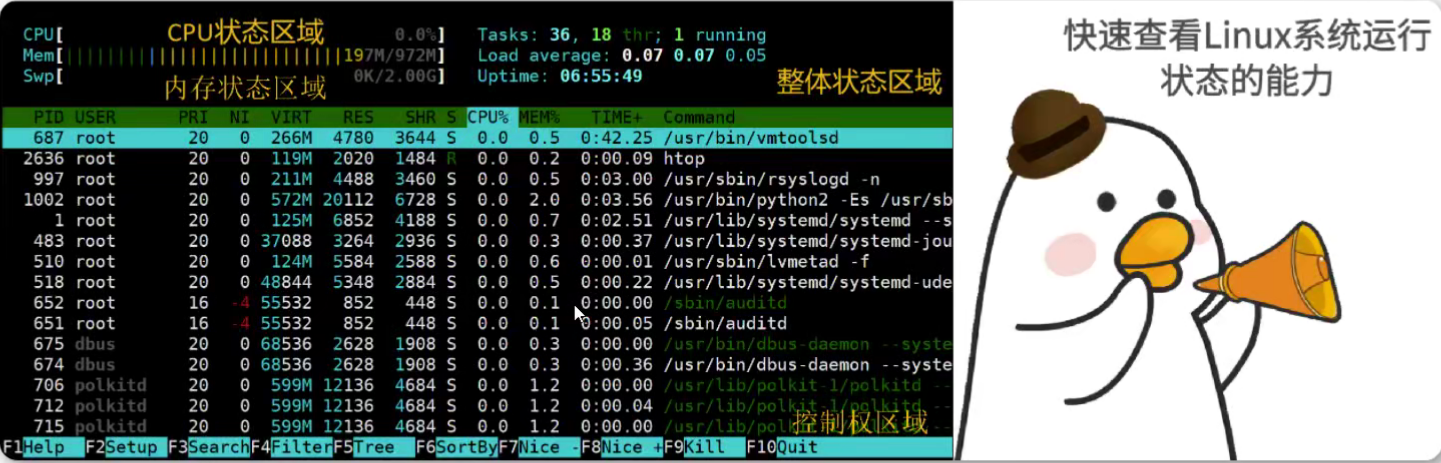
top
查看系统健康状态,windows加强版任务管理器
语法:
top [-d] | top [-bnp]
选项
- -d:屏幕刷新间隔时间;
- -p<进程号>:指定进程;
实例1:每2s更新一次top,观察整体信息。
top -d 2
top是一个不错的进程观察工具,但不同于ps是静态的结果输出。top这个进程可以持续地监测整个系统的进程的工作状态。
htop
htop的介绍
htop是Linux系统中的一个互动的进程查看器,与Linux传统的top比较的话,htop更人性化并且还支持鼠标操作!
htop的安装
# 安装epel源
yum install epel-release -y
# 安装htop
yum install -y htop
# 安装完毕后命令行输入
htop
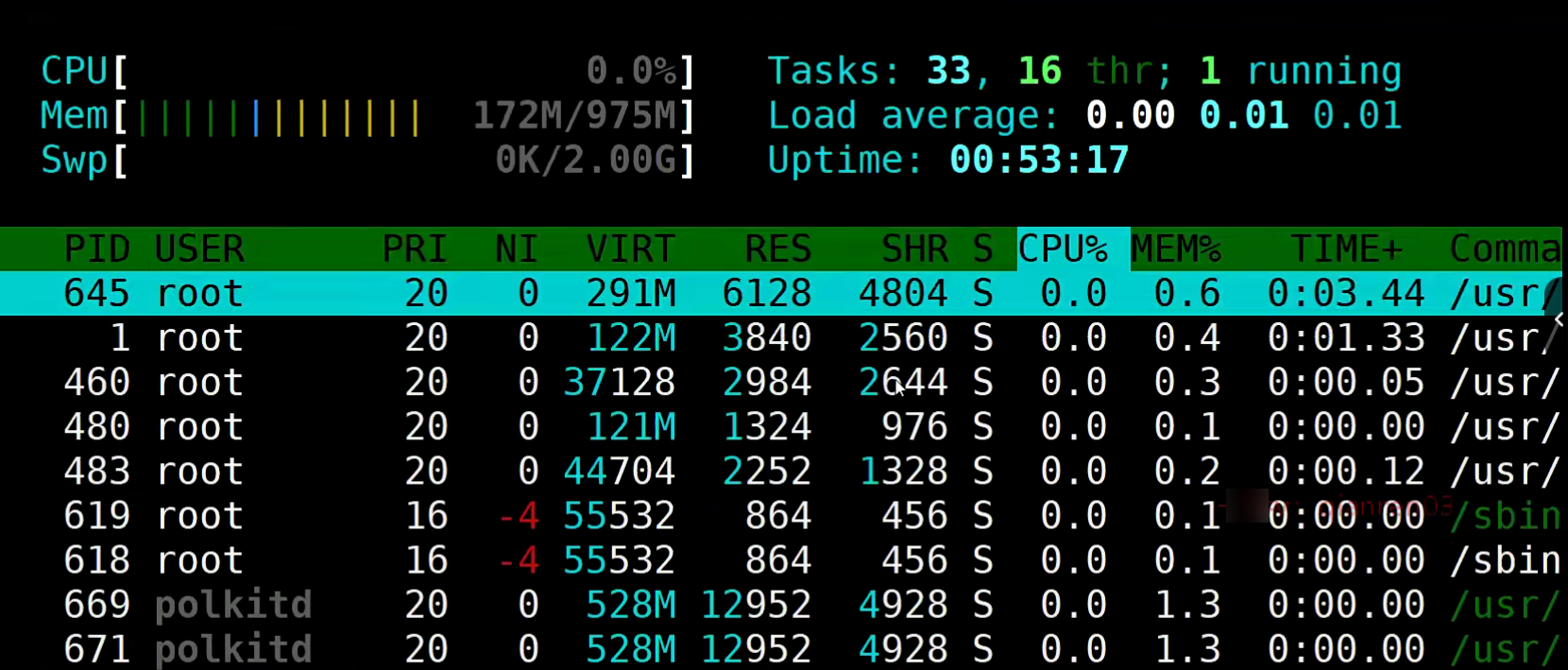
kill
终止进程,kill的应用是和ps或者grep命名结合在一起使用的。
语法:
kill [信号量] 进程ID
注:信号代码可以省略,常用的信号代码是-9,表示强制终止
实例1:终止所有的httpd进程。
ps auxf | grep httpd
kill -9 4158
netstat
netstat命令是一个监控TCP/IP网络的非常有用的工具,它可以显示路由表、实际的网络连以及每一个网络接口设备的状态信息。
语法:
netstat [选项]
实例1:列出所有端口
netstat -a # 列出所有端口
netstat -at # 列出所有TCP端口
netstat -au # 列出所有UDP端口
netstat -ax # 列出所有unix端口
netstat -atnlp # 直接使用ip地址列出所有处理监听状态的TCP端口,且加上程序名
实例2:显示每个协议的统计信息
netstat -s # 显示所有端口的统计信息
netstat -st # 显示所有TCP的统计信息
netstat -su # 显示所有UDP的统计信息
实例3:显示核心路由信息
netstat -r # 显示所有端口的统计信息
netstat -rn # 显示所有TCP的统计信息
Linux系统服务

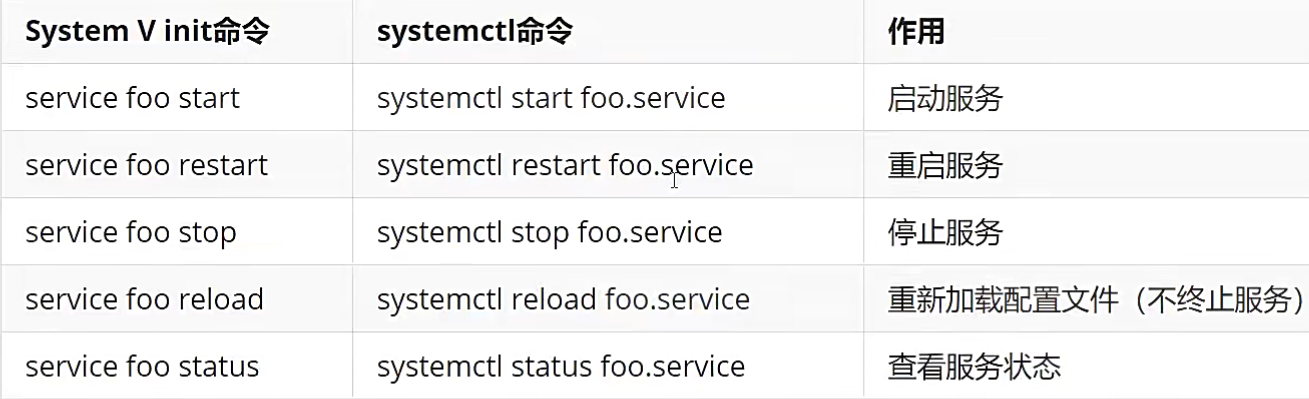
Service命令
服务(service)本质就是进程,但是是运行在后台的,通常都会监听某个端口,等待其它程序的请求,比如(mysql,sshd防火墙等),因此我们又称为守护进程。
语法:
service 服务名 [start | stop | restart | reload | status]
注意:
service命令其实是去/etc/init.d目录下,去执行相关程序
实例1: 查看当前防火墙的状况,关闭防火墙和重启防火墙。
[root@zk3 ~]# service iptables status
Systemd命令
Linux的启动一直采用init进程。
sudo /etc/init.d/apache2 start
# 或者
service apache2 start
service两个缺点:
- 一是启动时间长。init进程是串行启动只有前一个进程启动完,才会启动下一个进程。
- 二是启动脚本复杂。init进程只是执行启动脚本,不管其他事情。脚本需要自己处理各种情况,这往往使得脚本变得很长。
Systemd并不是一个命令,而是一组命令,涉及到系统管理的方方面面。
systemctl
systemctl是Systemd的主命令,用于管理系统。
systemd-analyze
systemd-analyze命令用于查看启动耗时。
# 查看启动耗时
$ systemd-analyze
# 查看每个服务的启动耗时
$ systemd-analyze blame
# 显示瀑布状的启动过程流
$ systemd-analyze critical-chain
# 显示指定服务的启动流
$ systemd-analyze critical-chain atd.service
hostnamectl
hostnamectl命令用于查看当前主机的信息。
# 显示当前主机的信息
hostnamectl
# 设置主机名。
sudo hostnamect]set-hostname rhel7
timedatectl
timedatectl命令用于查看当前时区设置。
# 查看当前时区设置
timedatectl
# 显示所有可用的时区
$ timedatect list-timezones
# 设置当前时区
$ sudo timedatectl set-timezone America/New_York
$ sudo timedatectl set-time YYYY-MM-DD
$ sudo timedatectl set-time HH:MM:SS
Systemd并不是一个命令,而是一组命令,涉及到系统管理的方方面面。
- systemctl 是Systemd的主命令管理系统
- systemd-analyze 命令用于查看启动耗时。
- hostnamectl 命令用于查看当前主机的信息。
- localectl 命令用于查看本地化设置。
- timedatectl 命令用于查看当前时区设置。
chkconfig
chkconfig命令用来更新、查询、改动不同执行级上的系统服务。比方安装了httpd服务,而且把启动的脚本放在了/etc/rc.d/init.d文件夹下,有时候须要开机自己主动启动它,而有时候则不须要,因此,就能够使chkconfig命令来进行控制。
选项:
- –add:将相应的服务加入chkconfig管理
- –del:将相应的服务从chkconfig管理中删除
- –level:查看相应服的运级别
实例1:
列出chkconfig所知道的所有命令。
chkconfig --list
开启服务。
chkconfig telnet on # 开启Telnet服务
chkconfig --list # 列出chkconfig所知道的所有的服务的情况
关闭服务
chkconfig telnet off # 关闭Telnet服务
chkconfig --list # 列出chkconfig所知道的所有的服务的情况
systemctl置服务开机启动、不启动、查看各级别下服务启动状态等常用命令
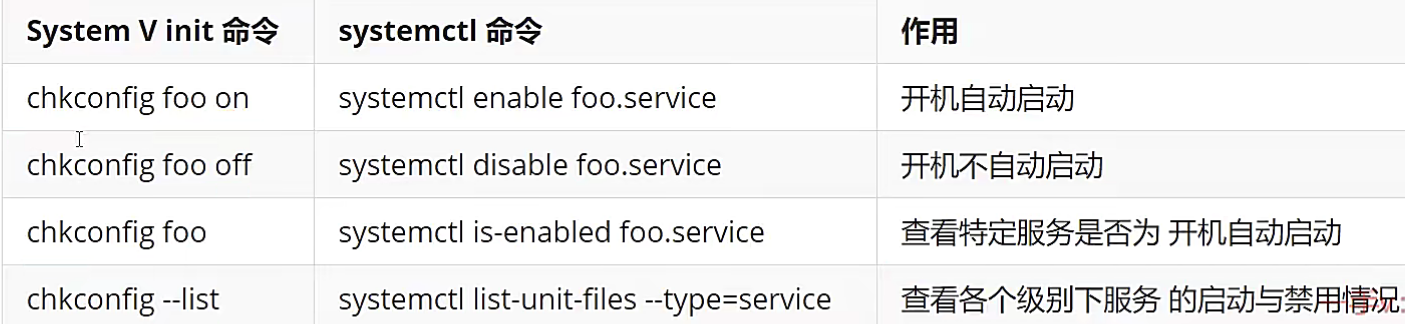
经常使用服务介绍
amd: # 自己主动安装网络文件系统守侯进程
apmd: # 高级电源管理
Arpwatch: # 记录日志并构建一个在LAN接口上看到的以太网地址和IP地址对数据库
Autofs: # 自己主动安装管理进程automount。与NFS相关,依赖于NIS
Bootparamd: # 引导參数server。为LAN上的无盘工作站提供引导所需的相关信息
crond: # 计划任务
Dhcpd: # 启动一个动态IP地址分配server
Gated: # 网关路由守候进程,使用动态的OSPF路由选择协议
Httpd: # WEBserver
Inetd: # 支持多种网络服务的核心守候程序
Innd: # Usenet新闻server
Linuxconf: # 同意使用本地WEBserver作为用户接口来配置机器
Lpd: # 打印server
Mars-nwe: # mars-nwe文件和用于Nove1T的打印server
Mcserv:# Midnight命令文件server
named: # DNSserver
netfs: # 安装NFS、Samba和NetWare网络文件系统
network: # 激活己配置网络接口的脚本程序
nfs: # 打开NFS服务
nscd: # nscdserver,用于NTS一个支持服务,它快速缓存用户口令和组成成员关系
portmap: # RPC portmap管理器,与inetd相似,它管理基于RPc服务的连接
postgresq1: # 一种SQL数据库server。
routed: # 路由守候进程,使用动态RIP路由选择协议
rstatd: # 一个为LAN上的其他机器收集和提供系统信息的守候程序
ruserd: # 这是一个基于RPC的服务。它提供关于当前记录到LAN上一个机器日志中的用户信息
rwalld: # 这是一项基于RPC的服务。同意用户给每一个注冊到LAN机器的其他终端写消息
rwhod: # 激活rwhod.服务进程。它支持LAN的rwho和ruptime服务
sendmail: # 邮件serversendmail
smb: # Samba文件共享/打印服务
snmpd: # 本地简单网络管理候进程
squid: # 激活代理serversquid
syslog: # 一个让系统引导时起动sys1og和k1ogd系统日志守候进程的脚本
xfs: # X Window字型server,为本地和远程Xserver提供字型集
xntpd: # 网络时间server
ypbind: # 为NIS(网络信息系统)客户机激活ypbind服务进程
yppasswdd: # NIS口令server
ypserv: # NIS主server
gpm: # 管鼠标的服务
identd: # AUTH服务。在提供用户信息方面与finger相似
Linux系统定时任务
什么是定时任务
定时任务命令是cond,crond就是计划任务,类似于我们平时生活中的闹钟,定点执行。
为什么要用crond
计划任务主要是做一些周期性的任务,比如凌晨3点定时备份数据、晚上23点开启网站抢购接口、凌晨0点关闭抢占接口等。
计划任务主要分为以下两种使用情况:
系统级别的定时任务
临时文件清理、系统信息采集、日志文件切割
用户级别的定时任务
定时向互联网同步时间、定时备份系统配置文件、定时备份数据库的数据。
crontab配置文件
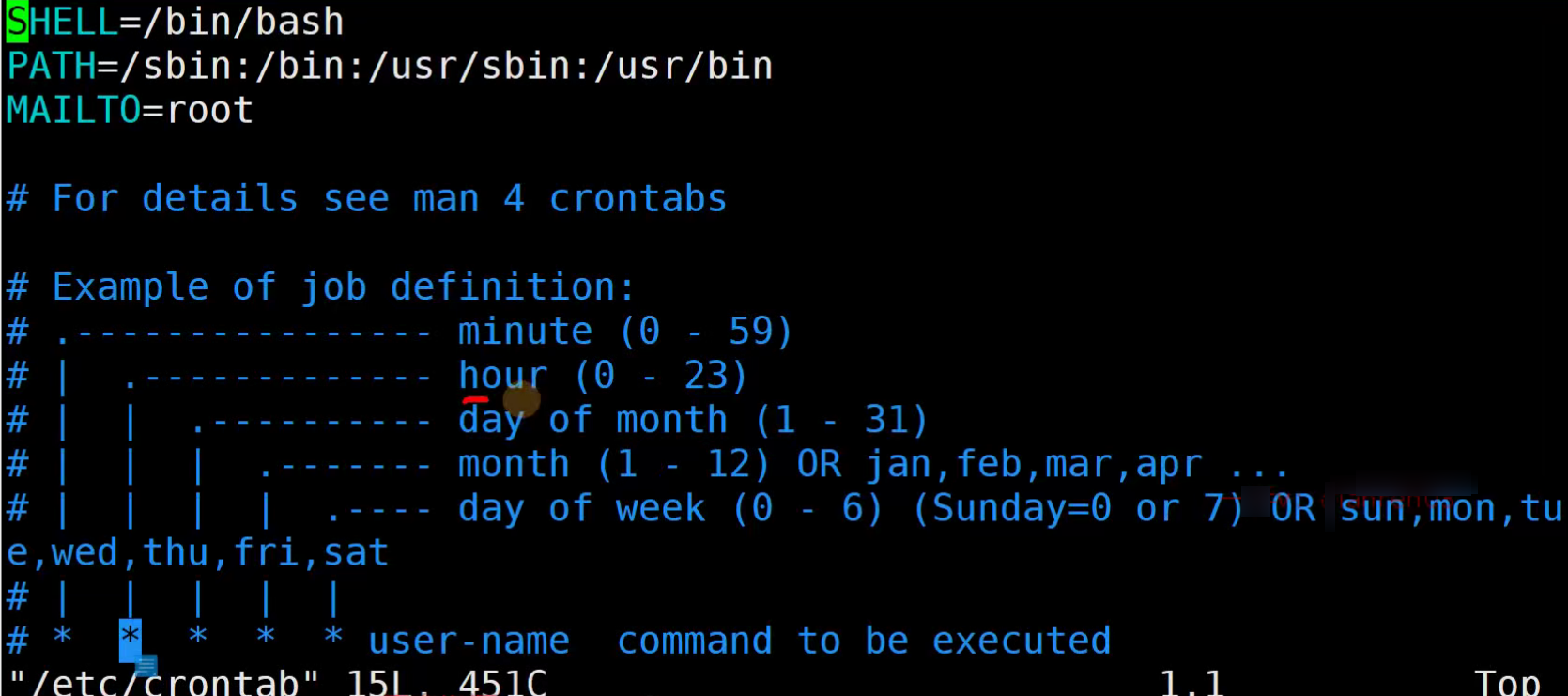
crontab的时间编写规范
00 02 * * * ls # 每天的凌晨2点整执行
00 02 1 * * ls # 每月的1日的凌晨2点整执行
00 02 14 2 * ls # 每年的2月14日凌晨2点执行
00 02 * * 7 ls # 每周天的凌晨2点整执行
00 02 * 6 5 ls # 每年的6月周五凌晨2点执行
00 02 14 * 7 ls # 每月14日或每周日的凌晨2点都执行
00 02 14 2 7 ls # 每年2月14日或每年2月的周天的凌晨2点执行

crontab命令选项
-e # 编辑定时任务
-l # 查看定时任务
-r # 删除定时任务
-u # 指定其他用户
计划任务实践示例
假设在每周一、三、五的凌晨3点25分,都需要使用tr命令把某个网站的数据目录进行打包处理,使其作为一个备份文件。
25 3 * * 1,3,5 /usr/bin/tar -zcvf backup.tar.gz /opt/wwwroot
Linux网络防火墙
防火墙管理工具
firewalld概述
Centos系统中集成了多款防火墙管理工具,其中firewalld服务是默认的防火墙配置管理工具,它拥有基于CLI(命令行界面)和基于GUI(图形用户界面)的两种管理方式:
firewalld中常用的区域名称及测了规则
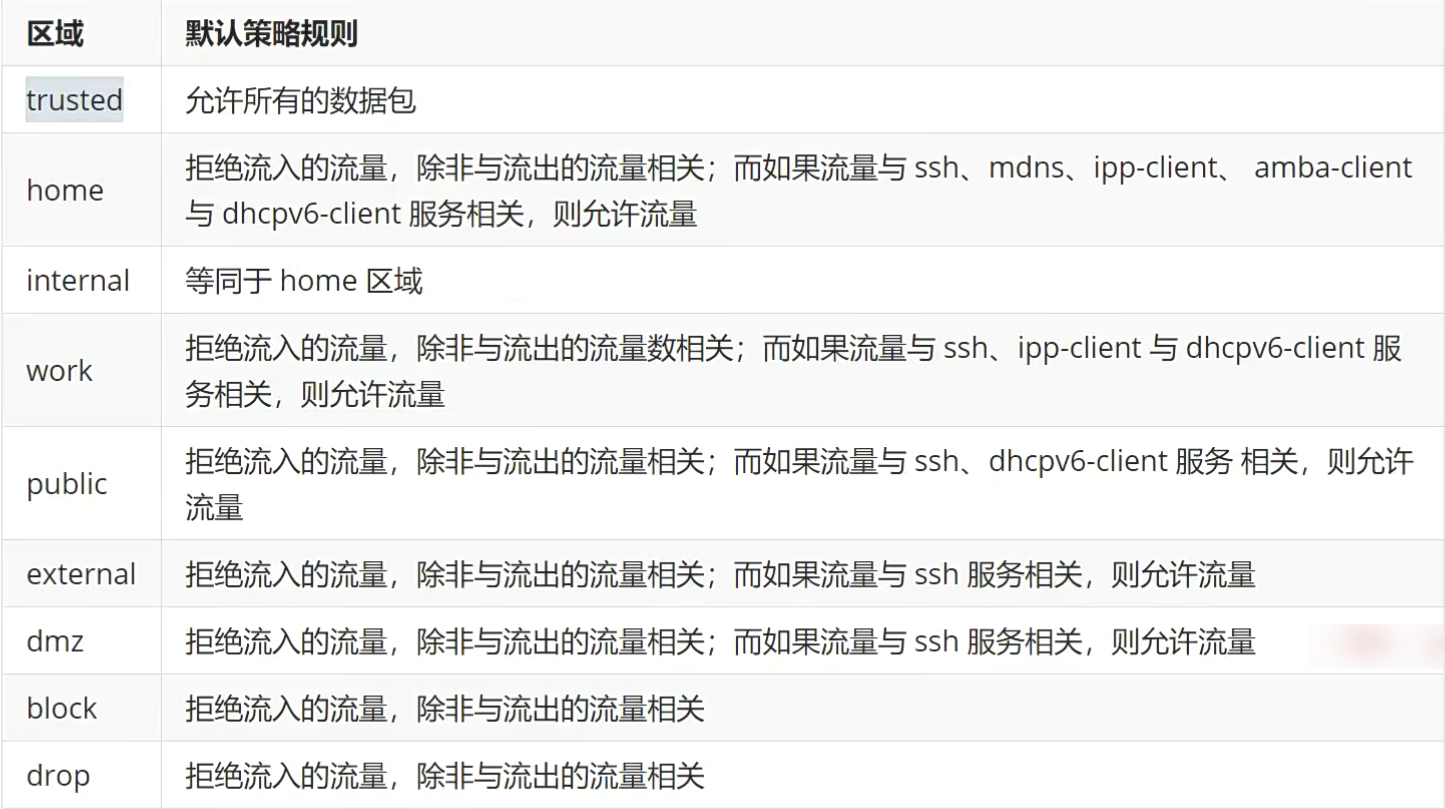
firewalld防火墙的配置
使用firewall–cmd命令行工具。
使用firewall-config图形工具。
编写/etc/firewalld/中的配置文件
启动:systemctl start firewalld
关闭:systemct1 stop firewalld
查看状态:
systemctl status firewalld
firewall-cmd --state
开机禁用:systemctl disable firewalld
开机启用:systemct1 enable firewalld
终端管理工具
Liux命令时曾经听到,命令行终端是一种极富效率的工作方式,frewalld-cmd是firewalld防火墙配置管理工具的CLI(命令行界面)版本。
firewalld-cmd命令的参数以及作用
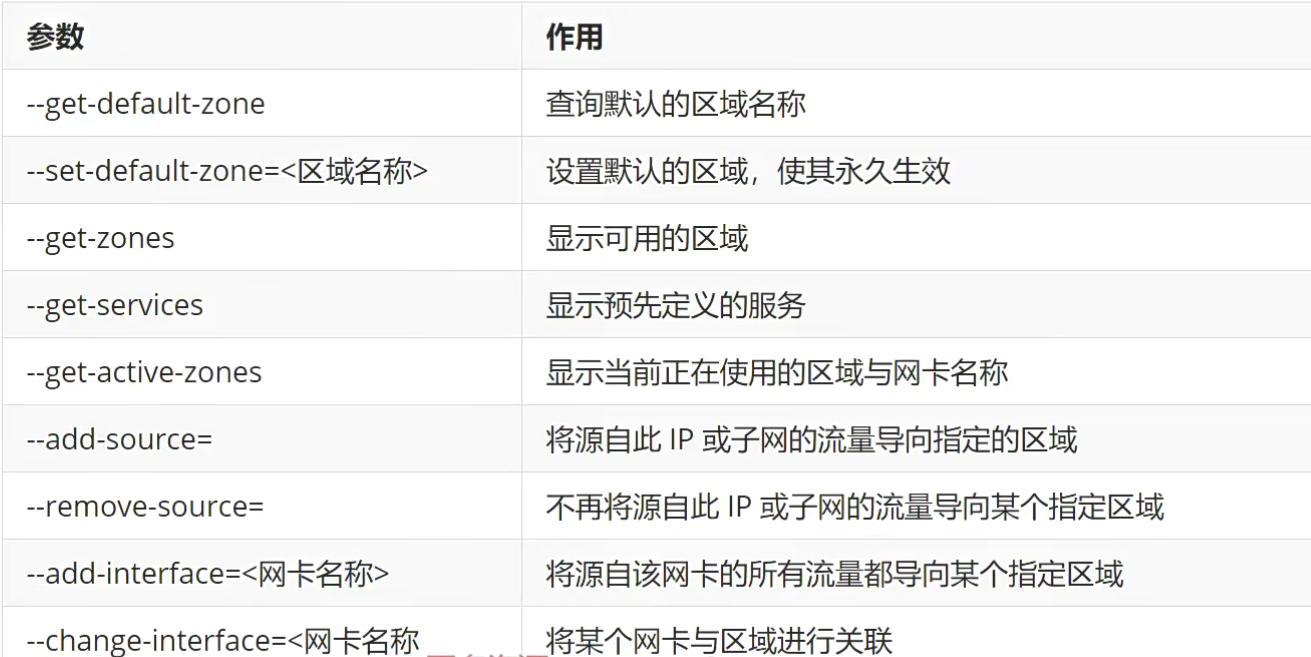
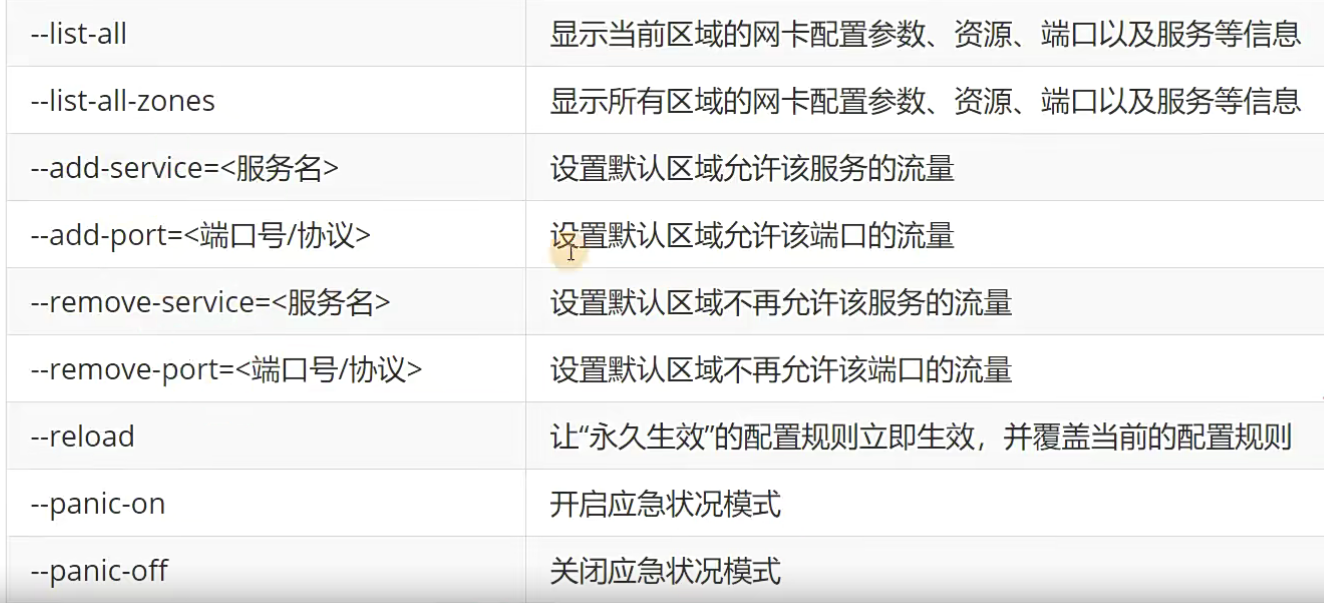
⚠️注意:
使用firewalld配置的防火墙策略默认为运行时(Runtime)模式,又称为当前生效模式,而且随着系统的重启会失效。如果想让配置策略一直存在,就需要使用永久(Permanent)模式了,方法就是在用firewall-cmd命令正常设置防火墙策略时添加-permanent参数,这样配置的防火墙策略就可以永久生效了。
但是,永久生效模式有一个“不近人情“的特点,就是使用它设置的策略只有在系统重启之后才能自动生效:
区域管理示例
显示当前系统中的默认区域
firewall-cmd --get-default-zone
显示默认区域的所有规则
firewall-cmd --list-all
显示当前正在使用的区域及其对应的网卡接口
firewall-cmd --get-active-zones
设置默认区域
firewall-cmd --set-default-zone=home
端口管理示例
查看开启的端口列表
[root@localhost local]# firewall-cmd --zone=public --list-ports
开启某端口
[root@localhost local]# firewall-cmd --zone=public --add-port=8080/tcp
success
关闭某端口
[root@localhost local]# firewall-cmd --zone=public --remove-port=8080/tcp
success
SELinux
安全增强型Linux(Security-Enhanced Linux)简称SELinux,它是一个Linux内核模块,也是Linux的一个安全子系统。
SELinux主要由美国国家安全局开发。2.6及以上版本的Linux内核都已经集成了SELinux模块。
说明:
当您全神贯注地使用它给照片进行美颜的时候,它却在后台默默监听着浏览器中输入的密码信息,而这显然不应该是它应做的事情,SELinux安全子系统就是为了杜绝此类情况而设计的,它能够从多方面监控违法行为。
- 对服务程序的功能进行限制(确保程序干不了出格的事情)
- 对文件资源的访问资源限制(SELinux安全上下文确保文件资源只能被其他所属的服务程序进行访问)
SELinux服务有三种配置模式:
- enforcing:强制启用安全策略模式,将拦截服务的不合法请求。
- permissive:遇到服务越权访问时,只发出警告而不强制拦截。
- disabled:对于越权的行为不警告也不拦截。
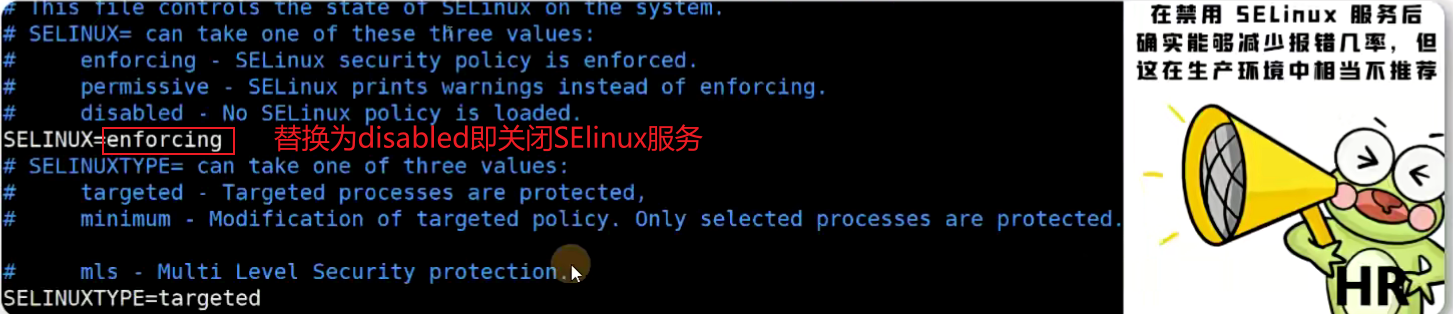
SELinux服务的主配置文件中,定义的是SELinux的默认运行状态,可以将其理解为系统重启后的状态,因此它不会在更改后立即生效。可以使用getenforce命令获得当前SELinux服务的运行模式:
[root@linuxprobe ~]# getenforce
Enforcing
注意:
修改SELinux当前的运行模式(0为禁用,1为启用)。这种修改只是临时的,在系统重启后就会失效:
setenforce 0 getenforce
Linux内核机制
Linux内核都有啥
漫画赏析:Linux 内核到底长啥样https://linux.cn/article-8290-1.html
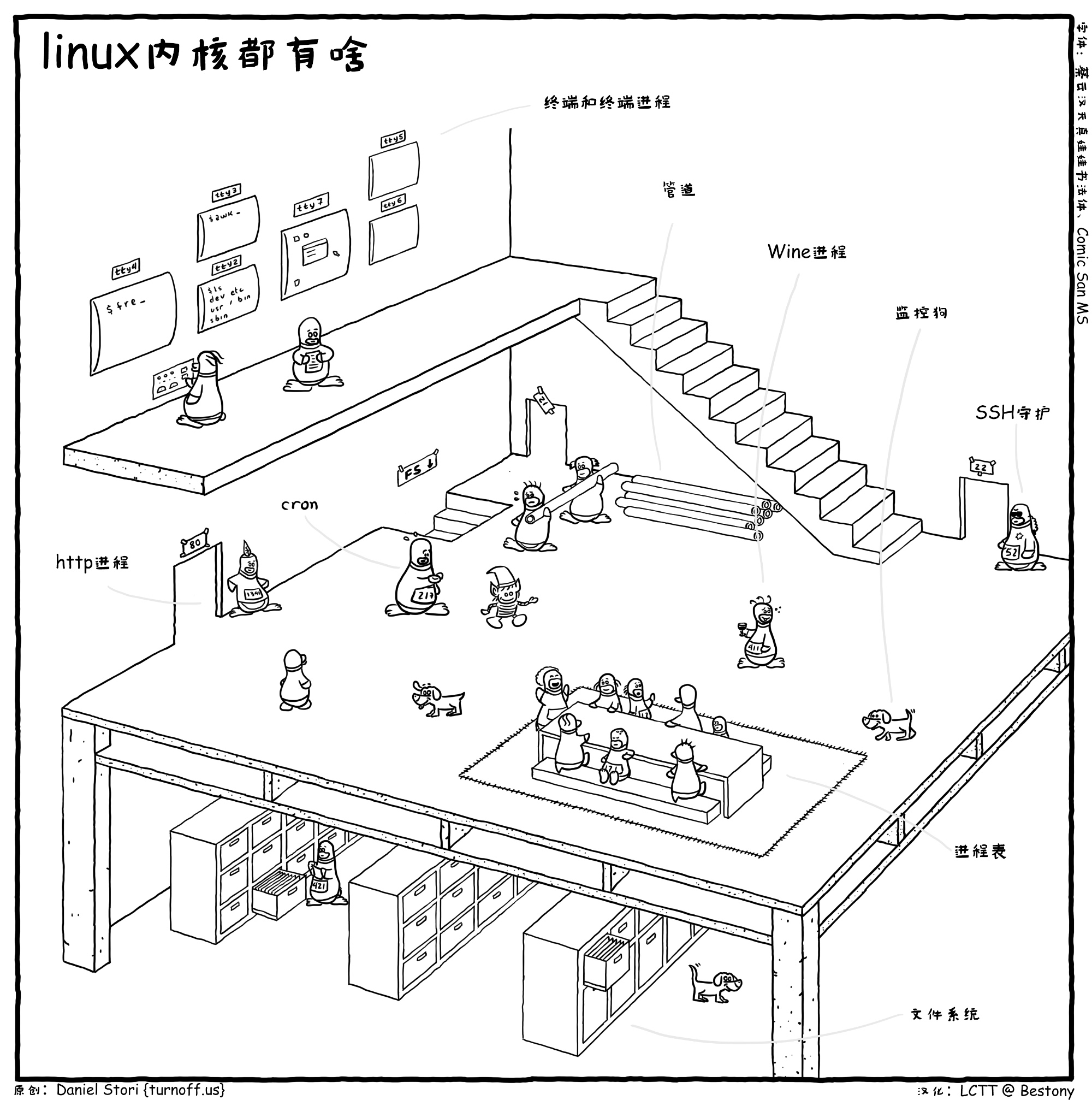
这幅漫画是以一个房子的侧方刨面图来绘画的。使用这样的一个房子来代表 Linux 内核。
地基
作为一个房子,最重要的莫过于其地基,在这个图片里,我们也从最下面的地基开始看起:
地基(底层)由一排排的文件柜组成,井然有序,文件柜里放置着“文件”——电脑中的文件。左上角,有一只胸前挂着 421 号牌的小企鹅,它表示着 PID(进程 ID Process ID) 为 421 的进程,它正在查看文件柜中的文件,这代表系统中正有一个进程在访问文件系统。在右下角有一只小狗,它是看门狗watchdog ,这代表对文件系统的监控。
一层(地面层)
在这一层,最引人瞩目的莫过于中间的一块垫子,众多小企鹅在围着着桌子坐着。这个垫子的区域代表进程表。
左上角有一个小企鹅,站着,仿佛在说些什么这显然是一位家长式的人物,不过看起来周围坐的那些小企鹅不是很听话——你看有好多走神、自顾自聊天的——“喂喂,说你呢,哇塞娃(171),转过身来”。它代表着 Linux 内核中的初始化(init)进程,也就是我们常说的 PID 为 1 的进程。桌子上坐的小企鹅都在等待状态wait中,等待工作任务。
瞧瞧,垫子(进程表)两旁有两只小狗,它会监控小企鹅的状态(监控进程),当小企鹅们不听话时,它就会汪汪地叫喊起来。
在这层的左侧,有一只号牌为 1341 的小企鹅,守在门口,门上写着 80,说明这个 PID 为 1341 的小企鹅负责接待 80 端口,也就是我们常说的 HTTP (网站)的端口。小企鹅头上有一片羽毛,这片羽毛大有来历,它是著名的 HTTP 服务器 Apache 的 Logo。喏,就是这只:

向右看,我们可以看到这里仍有一扇门,门上写着 21,但是,看起来这扇门似乎年久失修,上面的门牌号都歪了,门口也没人守着。看起来这个 21 端口的 FTP 协议有点老旧了,目前用的人也比以前少了,以至于这里都没人接待了。
而在最右侧的一个门牌号 22 的们的待遇就大为不同,居然有一只带着墨镜的小企鹅在守着,看起来好酷啊,它是黑衣人叔叔吗?为什么要这么酷的一个企鹅呢,因为 22 端口是 SSH 端口,是一个非常重要的远程连接端口,通常通过这个端口进行远程管理,所以对这个端口进来的人要仔细审查。
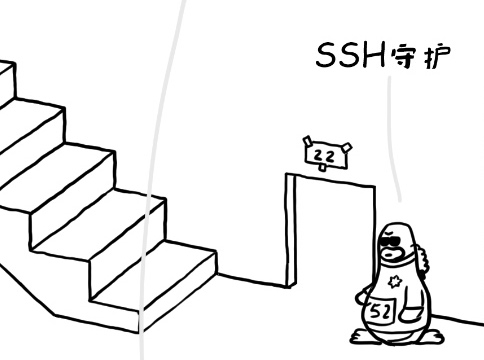
它的身上写着 52,说明它是第 52 个小企鹅。
在图片的左上角,有一个向下台阶。这个台阶是底层(地基)的文件系统中的,进程们可以通过这个台阶,到文件系统中去读取文件,进行操作。

在这一层中,有一个身上写着 217 的小企鹅,他正满头大汗地看着自己的手表。这只小企鹅就是定时任务(Crontab),他会时刻关注时间,查看是否要去做某个工作。
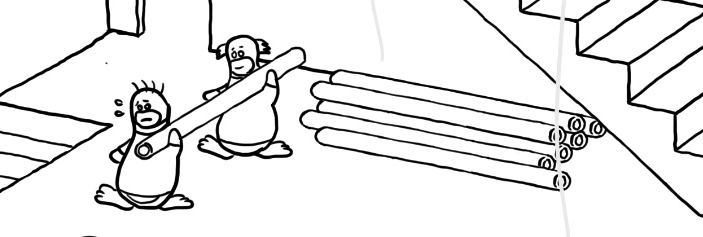
在图片的中部,有两个小企鹅扛着管道(PipeLine)在行走,一只小企鹅可以把自己手上的东西通过这个管道,传递给后面的小企鹅。不过怎么看起来前面这种(男?)企鹅累得满头大汗,而后面那只(女?)企鹅似乎游刃有余——喂喂,前面那个,裤子快掉了~

在这一层还有另外的一个小企鹅,它手上拿着一杯红酒,身上写着 411,看起来有点不胜酒力。它就是红酒(Wine)小企鹅,它可以干(执行)一些来自 Windows 的任务。
跃层
在一层之上,还有一个跃层,这里有很多不同的屏幕,每个屏幕上写着 TTY(这就是对外的终端)。比如说最左边 tty4 上输入了“fre”——这是想输入“freshmeat…”么 :d ;它旁边的 tty2 和 tty3 就正常多了,看起来是比较正常的命令;tty7 显示的图形界面嗳,对,图形界面(X Window)一般就在 7 号终端;tty5 和 tty6 是空的,这表示这两个终端没人用。等等,tty1 呢?
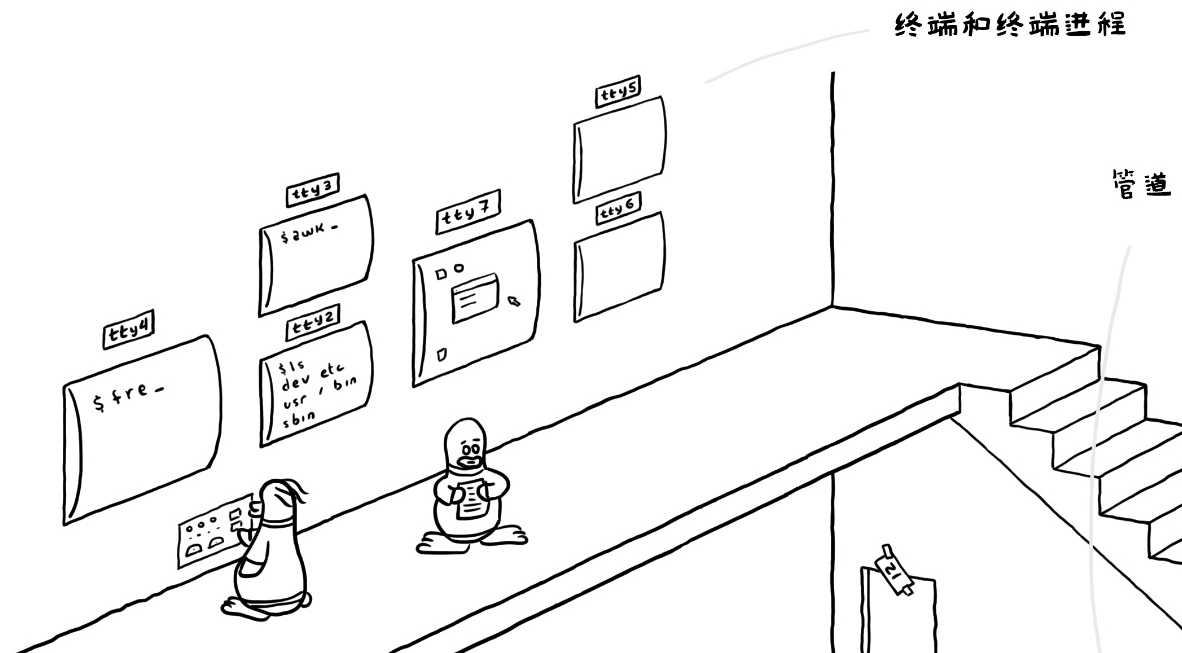
tty(终端)是对外沟通的渠道之一,但是,不是每一个进程都需要 tty,某些进程可以直接通过其他途径(比如端口)来和外部进行通信,对外提供服务的,所以,这一层不是完整的一层,只是个跃层。
好了,我们有落下什么吗?

这小丑是谁啊?
啊哈,我也不知道,或许是病毒?你说呢?
ShellScript脚本编程
Shell脚本入门
Shell是什么
Shell英文是"壳”,Shell是一块包裹着系统核心的壳,处于操作系统的最外层。
Shell是一个用C语言编写的程序,它是用户使用Linux的桥梁。通过编写Shell命令发送给linuⅸ内核去执行,操作就是计算机硬件,所以Shell命令是用户操作计算机硬件的桥梁,Shell是命令,类似于Windows系统中的Dos命令。
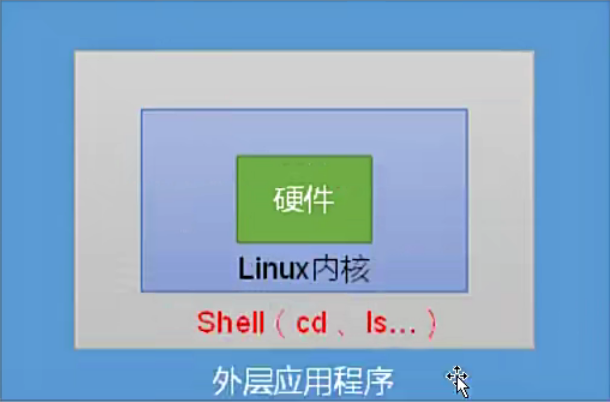
同时它可以作为命令语言,它交互式解释和执行用户输入的命令或者自动地解释和执行预先设定好的一连串的命令;作为程序设计语言,它定义了各种变量和参数,并提供了许多在高级语言中才具有的控制结构,包括循环和分支。
为什么学习Shell脚本?
Shell脚本语言的好处是简单、易学、易用,适合处理文件和目录之类的对象,以简单的方式快速完成某些复杂的事情。通过Shell命令编程语言来提高Linux系统的管理工作效率。
Shell的运行过程

当用户下达指令给该操作系统的时候,时间上是把指令告诉shell,经过shell解释,处理后让内核做出相应的动作。系统的回应和输出的信息也由shl处理,然后显示在用户的屏幕上。
Shell解析器
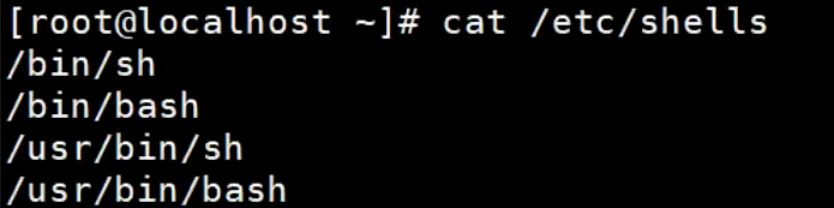
查看linux系统centos支持的shell解析器
cat /etc/shells
打印输出当前centos默认的解析器是bash语法:
echo $SHELL
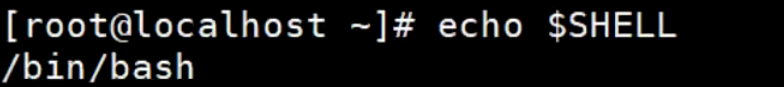
其中:
- echo:用于打印输出数据到终端
- $SHELL:是全局共享的读取解析器类型环境变量,所有的Shell程序都可以读取的变量
Shell编写格式与执行方式
脚本格式
-
脚本文件后缀名规范
Shell脚本文件就是一个文本文件,后缀名建议使用.sh结尾。
-
首行格式规范
#!/bin/bash设置当前Shell脚本文件采用bash解析器运行脚本代码
-
注释格式
单行注释
# 注释内容多行注释
:<<! # 注释内容1 # 注释内容2 !
脚本文件执行的三种方式
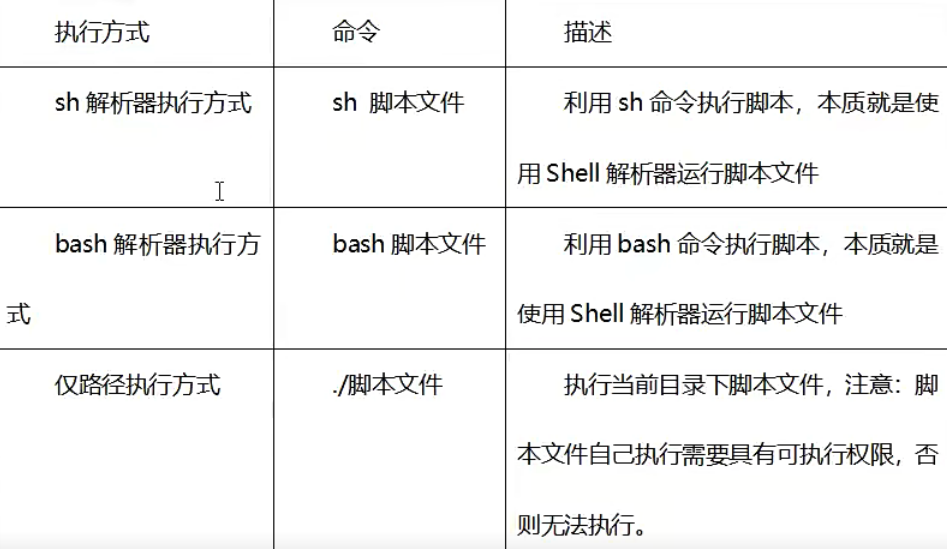
添加权限:chmod a+x helloworld.sh
三种方式的区别:sh或bash执行脚本文件方式是直接使用Shell解析器运行脚本文件,不需要可执行权限,仅路径方式是执行脚本文件自己,需要可执行权限。
解释执行多个命令
案例:执行test.sh脚本,实现在/root/bjsxt/目录下创建一个onetest…txt,在onetest.txt文件中增加内容"hello onetest shell"
实现步骤:
-
使用
mkdir创建/root/bjsxt目录
-
创建脚本文件

-
编写脚本文件
#!/bin/bash # 在/root/bjsxt/目录下创建onetest.txt文件 touch /root/bjsxt/onetest.txt # 在onetest.txt文件中写入内容 echo "Hello Shell" >> /root/bjsxt/onetest.txt -
执行脚本文件使用cat命令查看文件内容

Shell变量
变量用于存储管理运行在内存中的数据。
变量的类型
- 系统环境变量
- 自定义变量
- 特殊符号变量
系统环境变量
系统环境变量是系统提供的共享变量,是linux系统加载Shell的配置文件中定义的变量共享给所有的Shell程序使用。
Shell的配置文件分类
-
全局配置文件
/etc/profile /etc/profile.d/*.sh /etc/bashrc -
个人配置文件
当前用户/.bash_profile 当前用户/.bashrc一般情况下,我们都是直接针对全局配置进行操作。
环境变量的分类
在Liux系统中,环境变量按照其作用范围不同大致可以分为系统级环境变量和用户级环境变量。
系统级环境变量:Shell环境加载全局配置文件中的变量共享给所有用户所有Shell程序使用,全局共享。
用户级环境变量:Shell环境加载个人配置文件中的变共享当前用户的Shell程序使用,登录用户使用。
查看当前Shell系统环境变量
查看当前Shell系统环境变量,命令: env
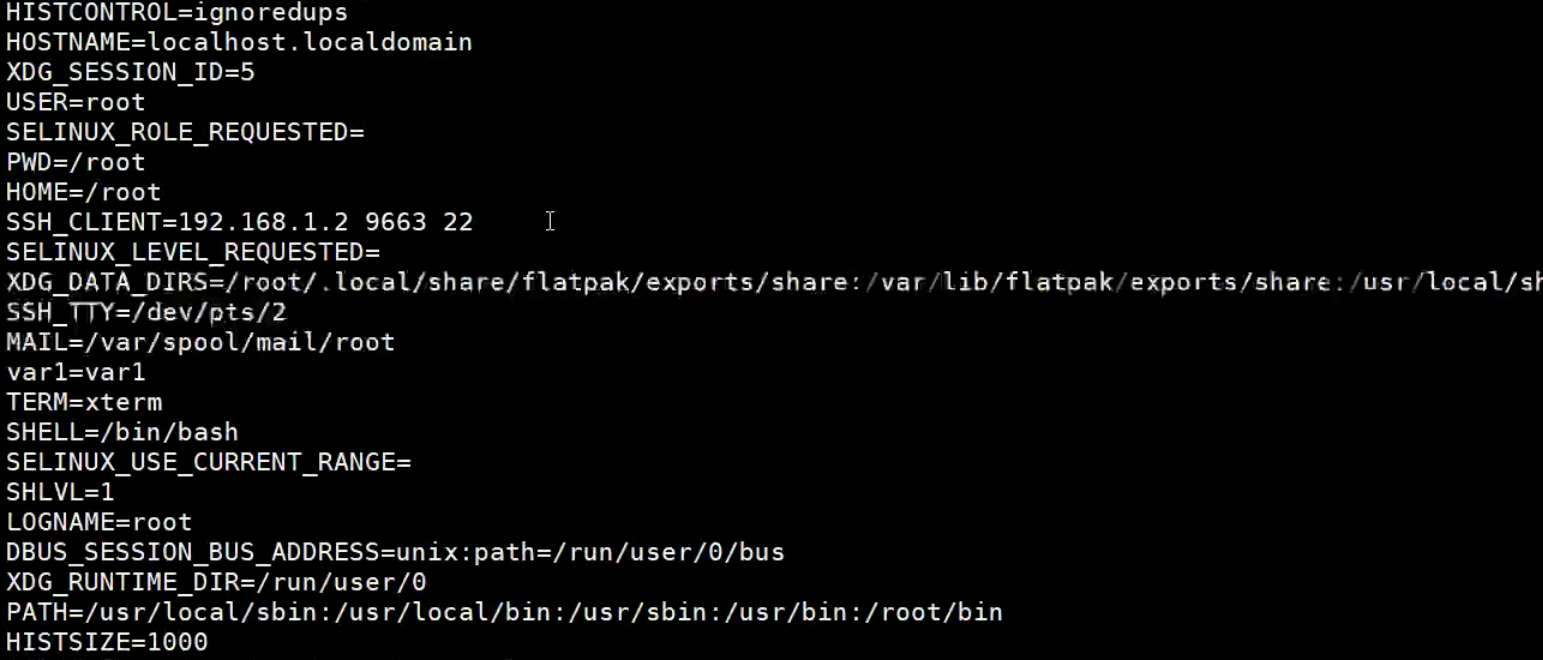
查看所有变量
命令:set
常用系统环境变量
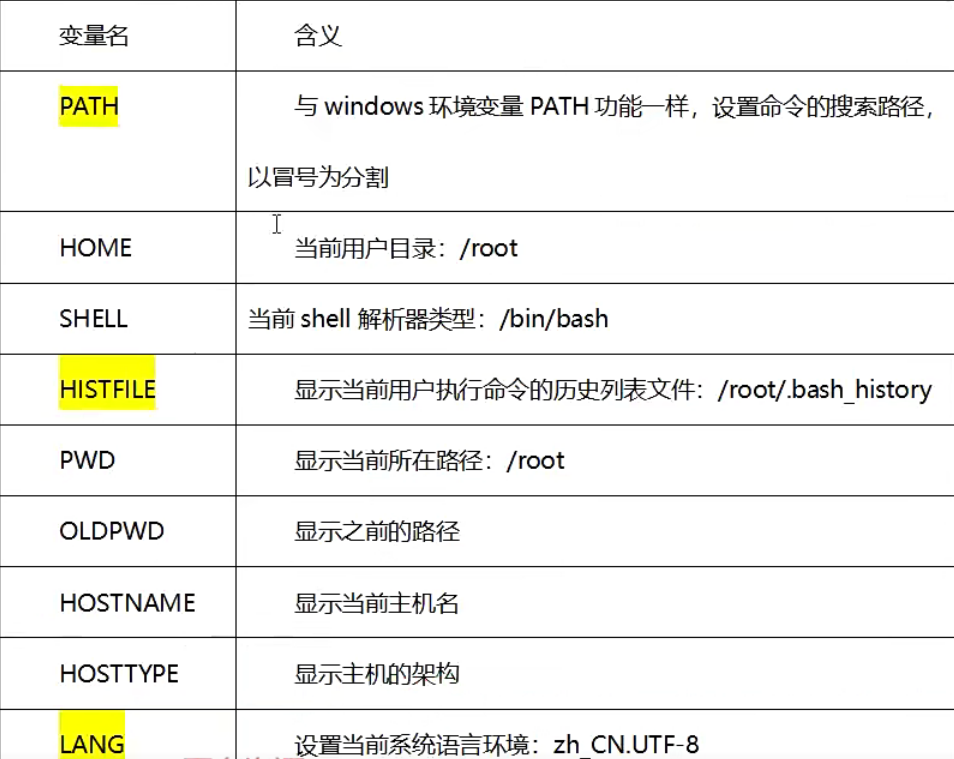
【示例】查看PATH环境变量

自定义变量
自定义变量分类
- 自定义局部变量
- 自定义常量
- 自定义全局变量
自定义局部变量
就是在脚本或命令中定义,仅在当前shell实例中有效,其他shell启动的程序不能访问局部变量。
变量定义规则
- 命名只能使用英文字母,数字和下划线,首个字符不能以数字开头。
- 中间不能有空格,可以使用下划线(_)。
- 不能使用Shell中的关键字作为变量名称。
- 在bash环境中,变量的默认类型都是字符串类型,无法直接进行数值运算。
- 变量的值如果有空格,必须使用双引号括起来。
定义变量语法
变量名=变量值
注意:等号两边不能有空格
【示例】定义局部变量
#!/bin/bash
# 定义变量
a=10
your_name=jack
查看变量
查看变量的值方式:
# 语法1:直接使用变量名查询
$var_name
# 语法2:使用花括号
${var_name}
# 区别:花括号方式适合拼接字符串
删除变量
使用unset命令可以删除变量。语法:
unset variable_name
变量被删除后不能再次使用。unset命令不能删除只读变量。
自定义全局变量
父子Shell环境介绍
例如:有2个Shell脚本文件A.sh和B.sh
如果在A.sh脚本文件中执行了B.sh脚本文件,那么A.sh就是父Shell环境,B.sh就是子Shell环境。
自定义全局变量
就是在当前脚本文件中定义全局变量,这个全局变量可以在当前Shell环境与子Shell环境中都可以使用
语法:
export var_namel var_name2
测试全局变量在子Shell中是否用,在父Shel中是否可用
实现步骤:
-
创建2个脚本文件test1.sh和test2.sh

-
编辑test1.sh
#!/bin/bash # 定义全局变量 export a=100 # 执行test2.sh脚本文件 sh test2.sh -
编辑test2.sh
#!/bin/bash # 输出全局变量 echo "全局变量a的值:$a"
自定义系统环境变量
/etc/profile定义存储自定义系统级环境变量数据,当前用户进入Shell环境初始化的时候会加载全局配置文件/etc/profile里面的环境变量,供给所有Shell程序使用,以后只要是所有Shel‖程序或命令使用的变量,就可以定义在这个文件中。
创建环境变量步骤:
-
编辑/etc/profile全局配置文件
# 增加命令:定义变量 VAR1=VAR1,并导出为环境变量**注意:**直接打开全局配置文件是在配置文件的最顶端,使用G可以快速到文件底部,gg重新回到文件的顶端。
-
重新加载置文件/etc/profile,因为配置文件修改后要立刻功加载里面的数据就需要重新加载,语法:
source /etc/profile -
在Shell环境中读取系统级环境变量var1
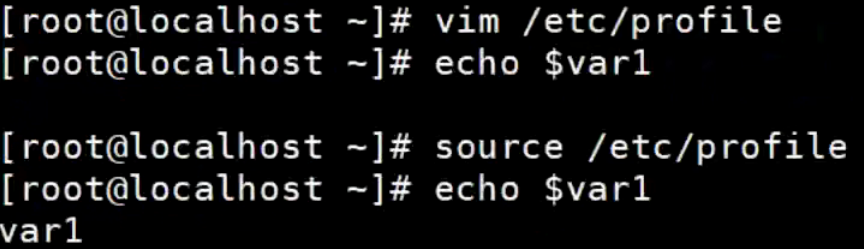
特殊符号变量

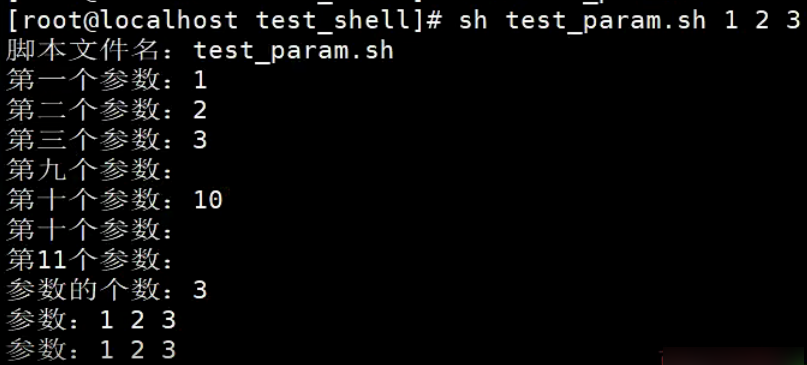
特殊符号变量:$n
$n:用于接收脚本文件执行时传入的参数,
$0用于获取当前脚本文件名称。
$1~$9代表获取第1个输入参数到第9个输入参数。
第10个以上参数获取参数的格式:${数字},否则无法获取。
#!/bin/bash
# 测试特殊符号变量 $n
echo "脚本文件名: $0"
echo "第一个参数: $1"
echo "第二个参数: $2"
echo "第三个参数: $3"
echo "第九个参数: $9"
echo "第十个参数: $10" # 参数有问题
echo "第十个参数: ${10}"
echo "第11个参数: ${11}"
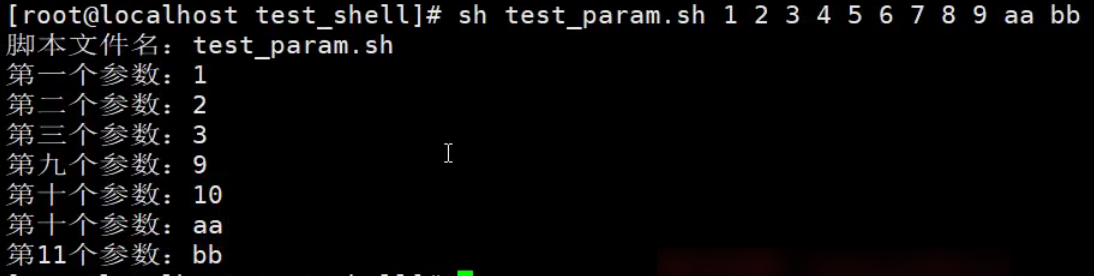
特殊符号变量:$#和$*
$#是获取所有输入参数如的个数
$*(或$@):传递的参数作为一个字符串显示
【示例】$#和$*的使用
#!/bin/bash
# 测试特殊符号变量 $n
echo "脚本文件名: $0"
echo "第一个参数: $1"
echo "第二个参数: $2"
echo "第三个参数: $3"
echo "第九个参数: $9"
echo "第十个参数: $10" # 参数有问题
echo "第十个参数: ${10}"
echo "第11个参数: ${11}"
echo "参数的个数: $#"
echo "参数:$*"
echo "参数:$@"
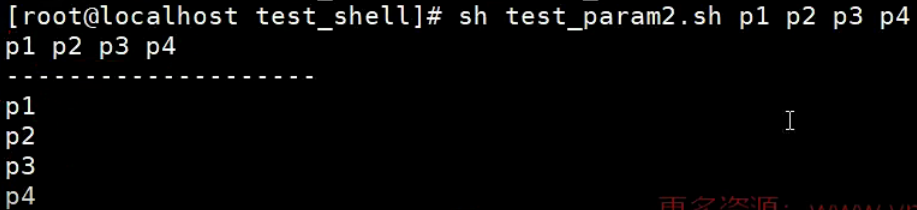
$*与$@区别:
相同点:都是引用所有参数。
不同点:只有在双引号中体现出来。
$*获取的所有参数拼接为一个字符串,格式为:"$1 $2...$n"
$@获取一组参数列表对像,格式为:"$1" "$2"..."$n"
假设在脚本运行时写了三个参数1、2、3,则$*等价于"123"(传递了一个参数),而$@等价于"1" "2" "3"(传递了三个参数)。
#!/bin/bash
# 测试$*与$@的区别
for i in "$*"
do
echo $i
done
echo "---------------"
for i in "$@"
do
echo $i
done
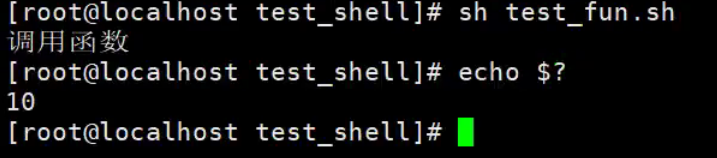
特殊符号变量$?
$?用于获取上一个Shell命令的退出码,或者是函数的返回值。
每个Shell命令的执行都有一个返回值,这个返回值用于说明命令执行是否成功。一般来说,返回0代表命令代表执行成功,非0代表执行失败。
#!/bin/bash
function test_add(){
echo "调用函数"
return 10
}
test_add
特殊符号$$
$$:用于获取当前Shell环境的进程ID号。

字符串变量
字符串创建
字符串是shell编程中最常用最有用的数据类型(除了数字和字符串,也没啥其它类型好用了),字符串可以用单引号,也可以用双引号,也可以不用引号。
【示例】
#!/bin/bash
# 创建字符串使用单引号
a='aaaa'
echo $a
echo ${a}
# 创建字符串使用双引号
b="bbb"
echo $b
# 创建字符串不使用引号
c=ccc
echo $c
#d=aa bb
#echo $d
# 注意如果变量的值中间有空格,需要使用引号创建
d="aa bb"
echo $d
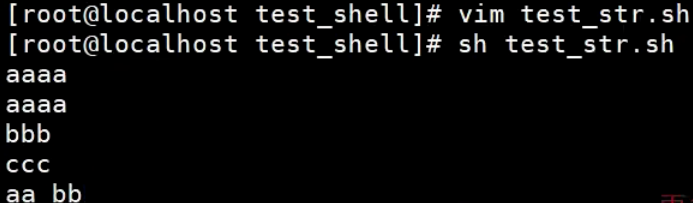
三者区别:
单引号里的任何字符都会原样输出,单引号字符串中的变量是无效的;双引号里可以有变量
字符串中还可以出现双引号的子字符串,但是需要转义
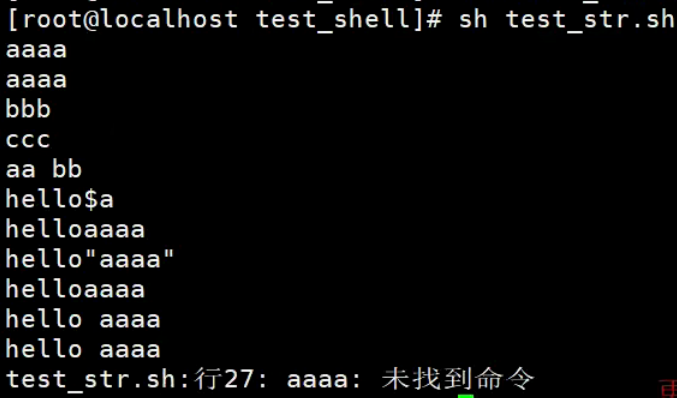
不被引号包围的字符串中出现变量时也会被解析,这一点和双引号""包围的字符串一样。字符串中不能出现空格,否则空格后边的字符串会作为其他命令解析(直接输出没有问题,但不能赋值给其它变量)
#!/bin/bash
a='aaaa'
# 输出字符串变量
echo 'hellosa'
echo "hello$a"
echo "hello\"$a\""
echo hello$a
echo "hello $a"
echo hello $a
# 赋值给其他变量
str1="hello$a"
#str1=hello $a # 不允许
获取字符串的长度
获取字符串长度语法:
${#字符串变量名}
#!/bin/bash
# 获取字符串长度
a="abc"
b="123456"
echo "字符串变量a的值:$a, 长度:${#a}"
echo "字符串变量b的值:${b}, 长度:${#b}"

字符串的拼接
#!/bin/bash
name="jack"
age=22
# 无符号拼接
str=$name$age
echo $str
# 双引号拼接
str="$name$age"
echo $str
# 混合拼接
str=$name','$age
echo $str
# 字符串拼接中间有空格需要使用双号
str="$name $age"
echo $str
# 不支持,需要使用引号
#str=$name $age
# echo输出字符串中间可以有空格
echo $name $age
截取字符串
| 格式 | 说明 |
|---|---|
| ${变量名:start:length} | 从string字符串的左边第start个字符开始,向右截取length个字符。 start从0开始 |
| ${变量名:start} | 从string字符串的左边第start个字符开始截取,直到最后 |
| ${变量名:0-start:length} | 从string字符串的右边第start个字符开始,向右截 取length个字符,stat从1开始,代表右侧第一个字符 |
| ${变量名:0-start} | 从string字符串的右边第start个字符开始截取,直到最后 |
| ${变量名#*chars} | 从string字符串左边第一次出现*chars的位置开始,截取 *chars右边的所有字符 |
| ${变量名##*chars} | 从string字符串左边最后一次出现*chars的位置开始,截取 *chars右边的所有字符 |
| # ${变量名%chars*} | 从string字符串右边第一次出现chars*的位置开始,截取 chars*左边的所有字符 |
| # ${变量名%%chars*} | 从string字符串右边最后一次出现chars*的位置开始,截取 chars*左边的所有字符 |
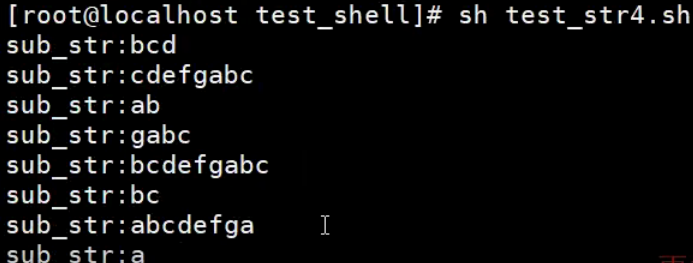
#!/bin/bash
# 截取字符串 ${变量名:start:length}
str="abcdefgabc"
sub_str=${str:1:3}
echo "sub_str:$sub_str"
# ${变量名:start}
sub_str=${str:2}
echo "sub_str:$sub_str"
# ${变量名:0-start:length}
sub_str=${str:0-3:5}
echo "sub_str:$sub_str"
# ${变量名:0-start}
sub_str=${str:0-4}
echo "sub_str:$sub_str"
# ${变量名#*chars} 不包括第一次出现的chars
sub_str=${str#*a}
echo "sub_str:$sub_str"
# ${变量名##*chars} 不包括最后一次出现的chars
sub_str=${str##*a}
echo "sub_str:$sub_str"
# ${变量名%chars*} 不包括第一次出现的chars
sub_str=${str%b*}
echo "sub_str:$sub_str"
# ${变量名%%chars*} 不包括最后一次出现的chars
sub_str=${str%%b*}
echo "sub_str:$sub_str"
数组变量
bash支持一维数组(不支持多维数组),并且没有限定数组的大小。
类似于C语言,数组元素的下标由0开始编号。获取数组中的元素要利用下标,下标可以是整数或算术表达式,其值应大于或等于0。
定义数组
在Shell中,用括号来表示数组,数组元素用"空格"符号分开。定义数组的一般形式为:
array_name=(value0 value1 value2 value3)
数组的值类型任意,个数不限
可以不使用连续的下标,而且下标的范围没有限制。
array_name=([0]=value0 [3]=value3 [5]=value5)
读取数组
读取数组元素值的一般格式是:
${数组名[下标]}
@或*获取数组中的所有元素
$(array_name[@])
$(array_name[*])
获取数组的长度或个数
$(#array_name[@])
$(#array_name[*]
获取数组指定元素的字符长度
${#array_name[索引]}
#!/bin/bash
# 定义数组
arr1=(21 33 "abc" '123')
arr2=(1 2 3 4)
arr3=([0]=10 [1]=20 [3]=30 [4]=40 [6]=60)
# 根据下标获取数组元素的值
echo "获取arr1数组第1个元素的值:${arr1[0]}"
echo "获取arr3数组第7个元素的值:${arr3[6]}"
# 获取数组中的所有元素
echo "获取arr1数组中的所有元素:${arr1[@]}"
echo "获取arr2数组中的所有元素:${arr2[*]}"
# 获取数组的长度
echo "获取arr1数组的长度:${#arr1[@]}"
echo "获取arr2数组的长度:${#arr2[*]}"
# 获取数组指定元素的字符长度
echo "获取arr1数组中第4个元素的长度:${#arr1[3]}"
数组拼接
所谓的数组拼接就是将两个数组连接成一个数组。
语法:使用@和*获取数组所有元素之后进行拼接。
new_array=(${array1[@]} ${array2[@]} ...)
new_array=(${array1[*])} ${array2[*]} ...)
#!/bin/bash
# 定义数组
arr1=(1 2 3 4 5 6)
arr2=(a b c d e f g)
echo "输出数组中所有元素:"
echo "arr1数组中的所有元素:${arr1[@]}"
echo "arr2数组中的所有元素:${arr2[*]}"
echo "数组的拼接:"
new_arr=(${arr1[@]} ${arr2[*]})
echo "拼接后数组:${new_arr[*]}"
数组删除
删除数组可以删哪除数组中指定元素,也可以删除整个数组。
删除数组中指定元素语法格式:
unset array_name[index]
删除整个数组
unset array_name
#!/bin/bash
# 定义数组
arr1=(1 2 3 4 5 6)
arr2=(a b c d e f g)
echo "输出数组中所有元素:"
echo "arr1数组中的所有元素:${arr1[@]}"
echo "arr2数组中的所有元素:${arr2[*]}"
echo "数组元素的删除:"
unset arr1[0]
echo "删除后输出arr1中的所有元素:${arr1[@]}"
echo "数组的删除:"
unset arr2
echo "删除arr2数组后:${arr2[*]}"
Shell内置命令
内置命令介绍
Shell内置命令,就是由Bash Shell自身提供的命令,而不是文件系统的可执行脚本文件。
使用type来确定一个命令是否是内置命令:
type 命令

由此可见,cd是一个Shell内建命令,而ifconfig是一个外部文件,它的位置是/sbin/ifconfig。
通常来说,内置命令会比外部命令执行得更快,执行外部命令时不但会触发磁盘I/O还需要开启一个单独的进程来执行,执行完成后再退出。而执行内置命令相当于调用当前Shell进程的一个函数,还是在当前Shell环境进程内,减少了上下文切换。
Bash Shell中常用的内建命令
alias:给命令创建别名
alisa用来给命令创建一个别名。若直接输入该命令且不带任何参数,则列出当前Shell进程中使用了哪些别名。
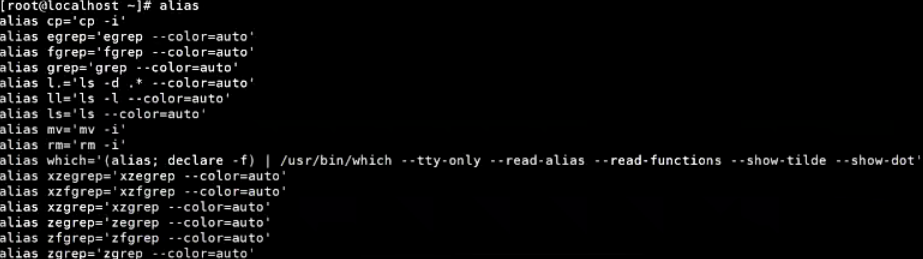
使用alias命令自定义别名
使用alias命令自定义别名的语法格式为:
alias 别名='命令'
设置查看进程的别名
alias pslist='ps -aux'
# 这样使用pslist和输入ps-aux可以达到同样的效果
删除别名
unalias pslist
echo命令:输出字符串
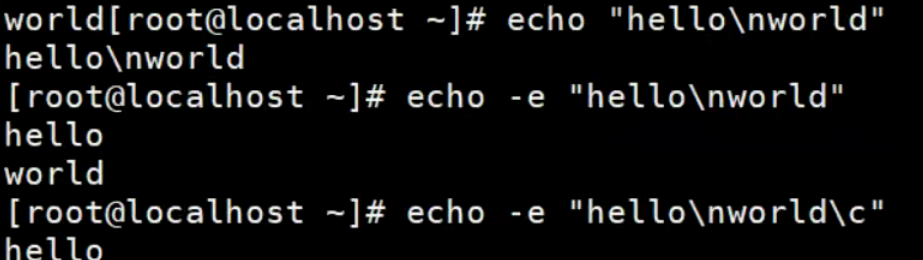
echo是一个Shell内建命令,用来在终端输出字符串,并在最后默认加上换行符。
echo不换行输出
echo命令输出结束后默认会换行,如果不希望换行,可以加上-n参数。
#!/bin/bash
echo -n "echo不换行输出测试"
-e参数
默认情况下,echo不会解析以反斜杠开头的转义字符。比如,\n表示换行,echo默认会将它作为普通字符对待。
read命令:读取从键盘输入的数据
read是Shell内置命令,用来从标准输入中读取数据并赋值给变量。如果没有进行重定向,默认就是从键盘读取用户输入的数据;如果进行了重定向,那么可以从文件中读取数据。
read命令的用法为:
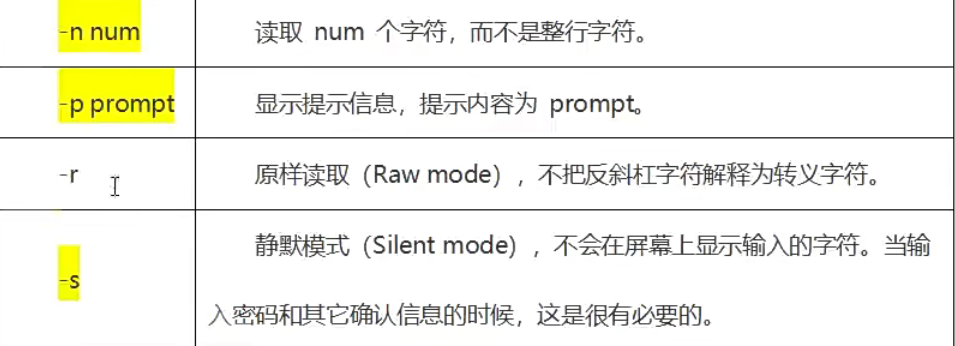
read [-options] [variables]
options表示选项,如下表所示;variables表示用来存储数据的变量,可以有一个,也可以有多个。
options和variables都是可选的,如果没有提供变量名,那么读取的数据将存放到环境变量REPLY。
#!/bin/bash
# 测试read内置命令的使用
# 不指定选项及变量
read
echo "没有指定变量获取值:$REPLY"
read a
echo "指定变量获取值:$a"
# 添加选项 -p
read -p "请输入姓名:" name
read -p "请输入年龄:" age
echo "姓名:$name, 年龄:$age"
# read 参数 -n num
# 获取两个字符
read -n 2 -p "获取输入字符串" str
echo "读取输入内容:$str"
# read 参数 -s
read -sp "请输入密码:" password
read -sp "请输入确认密码:" repassword
echo "密码:$password, 确认密码:$repassword"
if [ $password == $repassword ]
then
echo "密码和确认密码一致"
else
echo "密码和确认密码不一致"
fi
# read 参数 -t
read -t 5 -p "输入有时间限制,请在5秒内输入:" str
echo "输入内容:$str"
read命令支持的选项及options支持的参数

exit命令
exit是一个Shell内置命令,用来退出当前Shell进程,并返回一个退出状态;使用$?可以接收这个退出状态。
exit命令可以接受一个整数值作为参数,代表退出状态。如果不指定,默认状态值是0。
exit退出状态只能是一个介于0~255之间的整数,其中只有0表示成功,其它值都表示失败。
【示例】Shell脚本文件中使用exit退出
#!/bin/bash
echo "exit命令示例"
exit 3
echo "hello exit命令"
declare命令
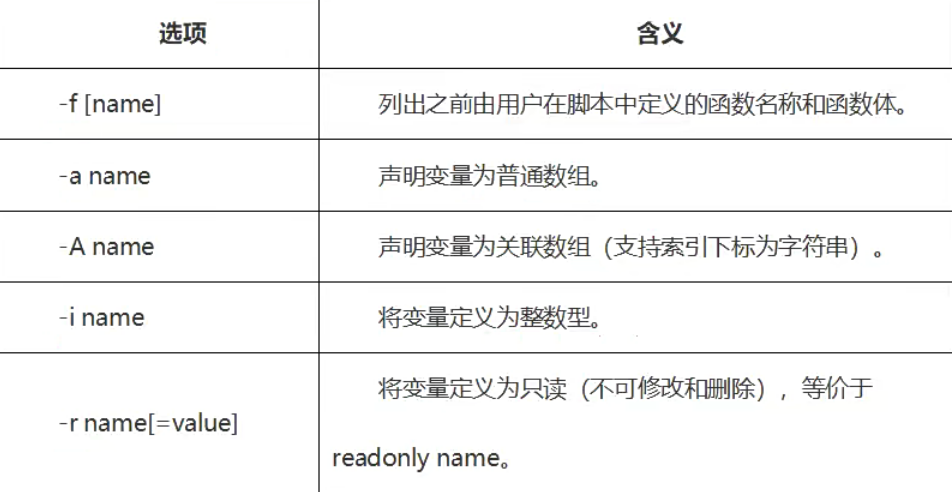
declare命令的用法如下所示:
declare [+/-] [aAirfx] [变量名=变量值]
其中,-表示设置属性,+表示取消属性,aAifⅸ都是具体的选项,它们的含义如下表所示:
#!/bin/bash
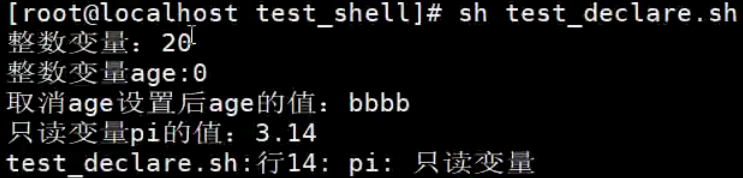
# 测试 + -
# 设置一个整数变量
declare -i age=20
echo "整数变量:$age"
age=aaa
echo "整数变量age: $age"
# 取消变量设置
declare +i age
age=bbbb
echo "取消age设置后age的值: $age"
设置只读变量
declare -r pi=3.14
echo "只读变量pi的值:$pi"
p1=3.3333
echo "只读变量pi的值:$pi"
实现key-value关联数组变量语法
关联数组也称为"键值对(key-value)"数组,键(key)也即字符串形式的数组下标,值(value)也即元素值。
declare -A 关联数组变量名=([字符串key1]=值1 [字符串key2]=值2 ...)
declare也可以用于定义普通索引数组,-a参数创建普通或索数组 -A创建关联数组。
declare -a 普通数组变量名=(值1 值2 ...)
declare -a 普通数组变量名=([0]=值1 [1]=值2 ...)
获取指定key的值
${关联数组变量名[key]}
获取所有值
${关联数组变量名[*]}
${关联数组变量名[@]}
#!/bin/bash
# 创建普通数组
declare -a arr1=(10 20 30 "abc")
declare -a arr2=([0]="baizhan" [2]=a [3]=10 [7]=70)
# 获取数组元素
echo "数组arr1中第2个元素:${arr1[1]}"
echo "数组arr2中第8个元素:${arr2[7]}"
# 获取数组中所有元素
echo "数组arr1中所有的元素:${arr1[*]}"
echo "数组arr2中所有的元素:${arr2[@]}"
# 创建关联数组
declare -A arr1=(["aa"]=10 ["bb"]=20 ["cc"]=30)
# 获取关联数组的值
echo "获取关联数组的值;${arr1["aa"]}"
echo "获取关联数组的值:${arr1["cc"]}"
# 获取关联数组的所有元素
echo "数组中所有元素的值:${arr1[*]}"
# 获取数组的长度
echo "数组的长度:${#arr1[*]}"
Shell运算符
Shell和其他编程语言一样,支持多种运算符,包括:
- 算数运算符
- 关系运算符
- 逻辑运算符
- 文件测试运算符
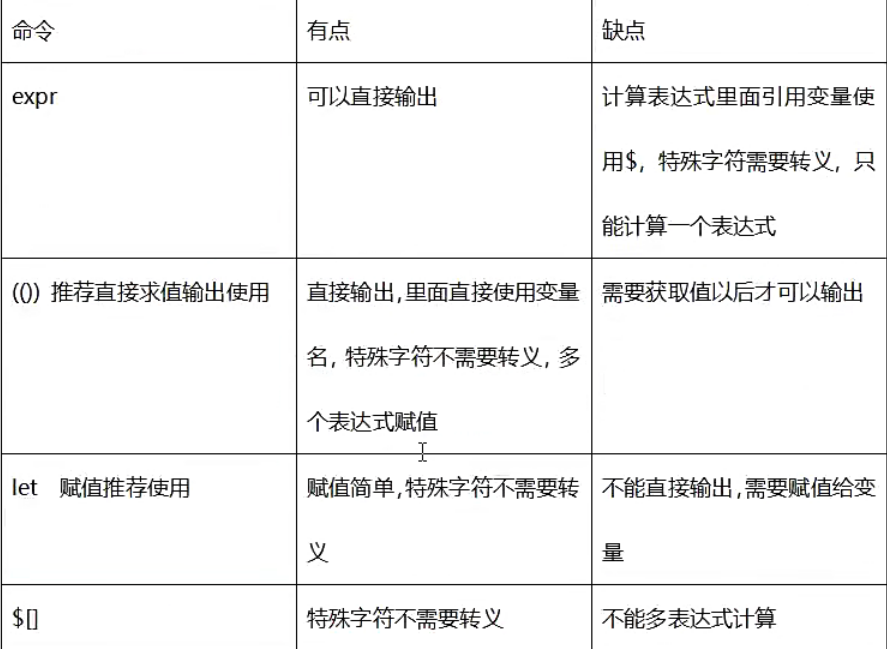
原生bash不支持简单的数学运算,需要通过其他命令来实现,如eXpr。
expr是evaluate expressions的缩写,译为"求值表达式”。Shell expr是一个功能强大,并且比较复杂的命令,它除了可以实现整数计算,还可以结合一些选对字符串进行处理,例如计算字符串长度、字符串比较、字符串匹配、字符串提取等。
expr语法:
expr 算术运算符表达式
获取计算结果赋值给新变量语法:
result=`expr 算术运算符表达式`
注意:这里不是单引号是反引号。运算表达式运算符两边必须要有空格。运算不能是小数远算必须是整数运算。
expr 10 + 10
算数运算符


注意:条件表达式要放在方括号之间,并且要有空格,例如:[$a==$b]是错误的,必须写成[ $a == $b ]。
#!/bin/bash
# 测试算术运算符
# 输入两个整数
read -p "请输入第一个数:" a
read -p "请输入第二个数:" b
# 输出输入的值
echo "a:$a, b:$b"
result=`expr $a + $b`
echo "加法的结果:$result"
result=`expr $a - $b`
echo "减法的结果:$result"
result=`expr $a \* $b`
echo "乘法的结果:$result"
result=`expr $a / $b`
echo "除法的结果:$result"
result=`expr $a % $b`
echo "取余的结果:$result"
比较运算符
整数处比较运算符
假定变量a为10,变量b为20:
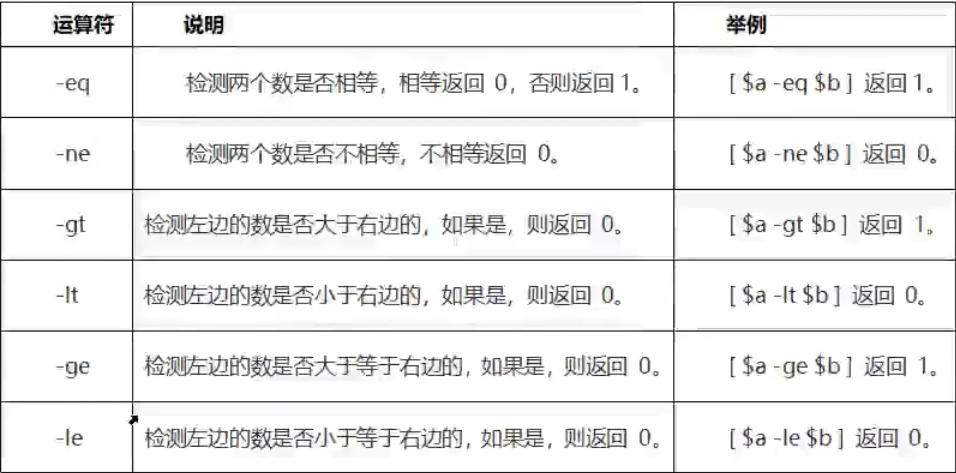
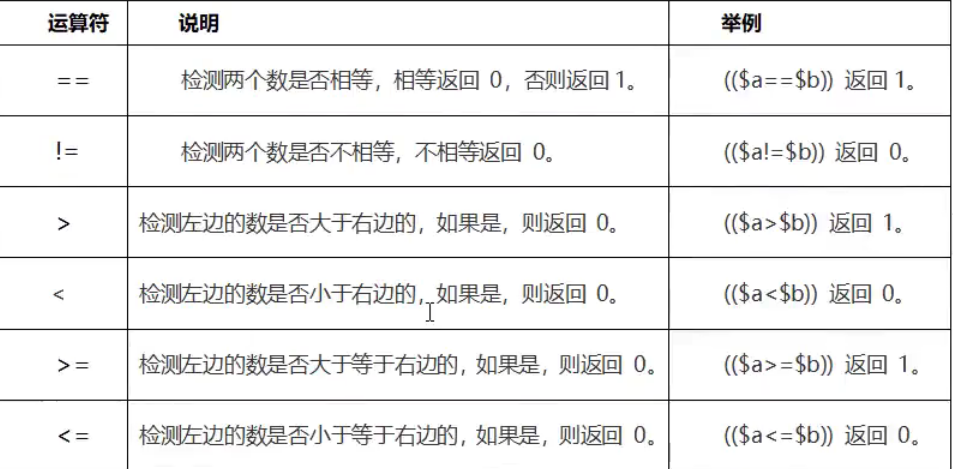
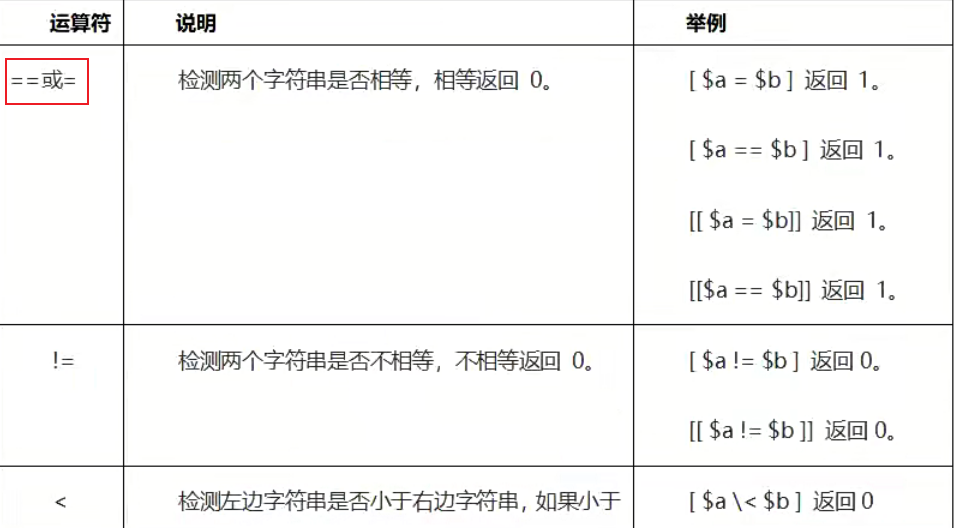
字符串比较运算符
字符串比较运算符可以比较2个变量,变量的类型可以为数字(整数,小数)与字符串。
下表列出了常用的字符串运算符,假定变量a为"abc",变量b为"efg"。
字符串比较可以使用[[]]和[]2种方式。
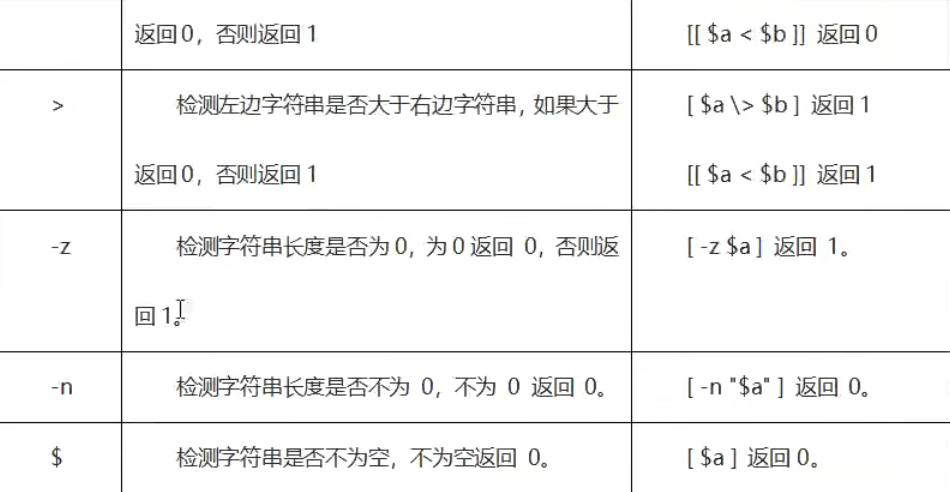
字符串比较没有<=可以通过[[ "a" < "b" || "a" == "b"]]
[[]]和[]的区别
由于(())只能比较整数,不能比较小数和字符串所以不建议使用。
区别1:[]会产生单词分隔现象,[[]]不会产生单词分隔
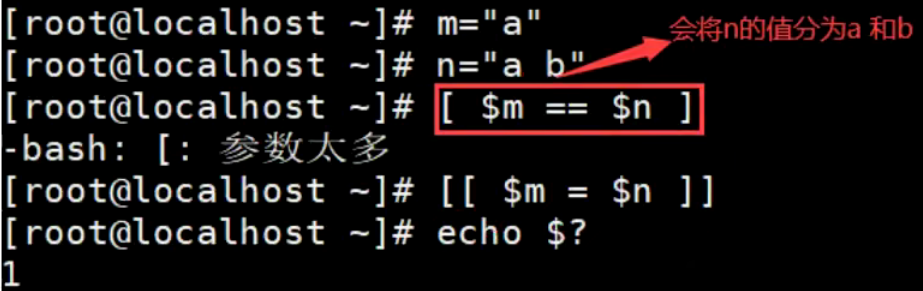
区别2:[]需要对>和<进行转义

布尔运算符
下表列出了常用的布尔运算符,假定变量a为10,变量b为20:


⚠️注意:布尔运算符必须放在[]或与test命令配合使用才有效
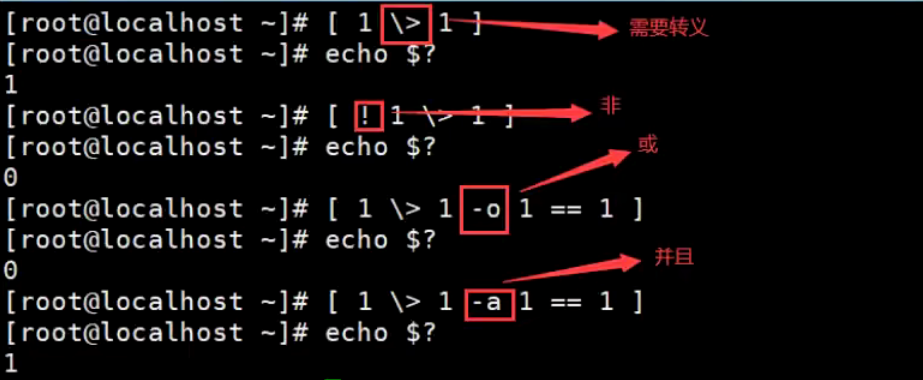
#!/bin/bash
a=10
b=20
# 布尔运算符使用到if条件中
if [ ! $a \> $b ]
then
echo "a变量的值小于等于b"
else
echo "a变量的值大于b"
fi
str="abc"
if [ $str -o 1 == 2 ]
then
echo "条件成立"
else
echo "条件不成立"
fi
if [ $str -a 1 == 2 ]
then
echo "条件成立"
else
echo "条件不成立"
fi
逻辑运算符
假定变量a为10,变量b为20:

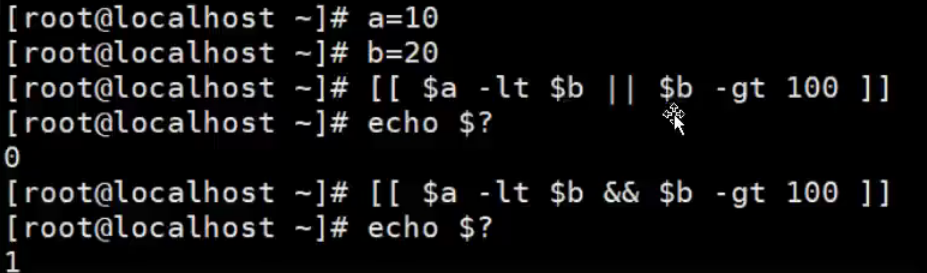
#!/bin/bash
a=100
b=200
# 布尔运算符 [] !-o -a
if [ $a \< $b -o 10 == 100 ]
then
echo"布尔运算符:条件成立”
else
echo"布尔运算符:条件不成立"
fi
# 逻辑运算符[[]]
if [[ $a -lt $b || 10 == 100 ]]
then
echo"逻辑运算符条件成立"
else
echo"逻辑运算符条件不成立"
fi
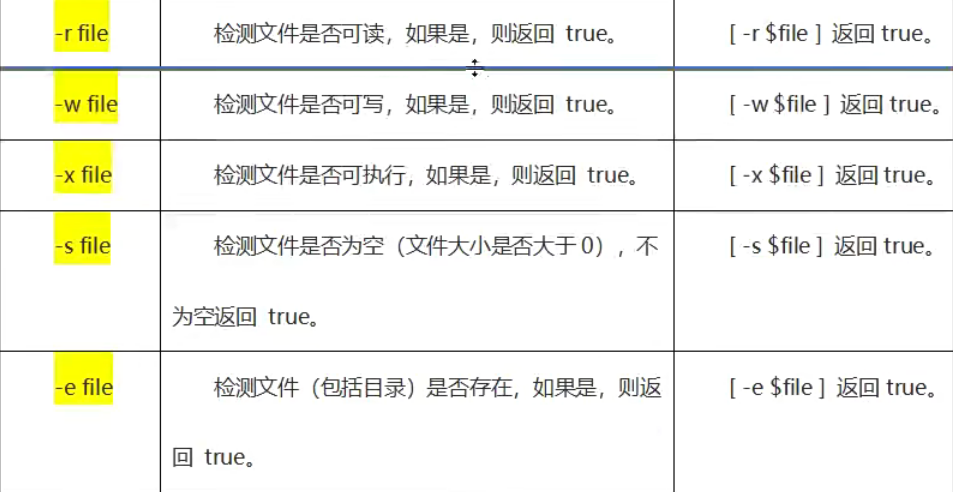
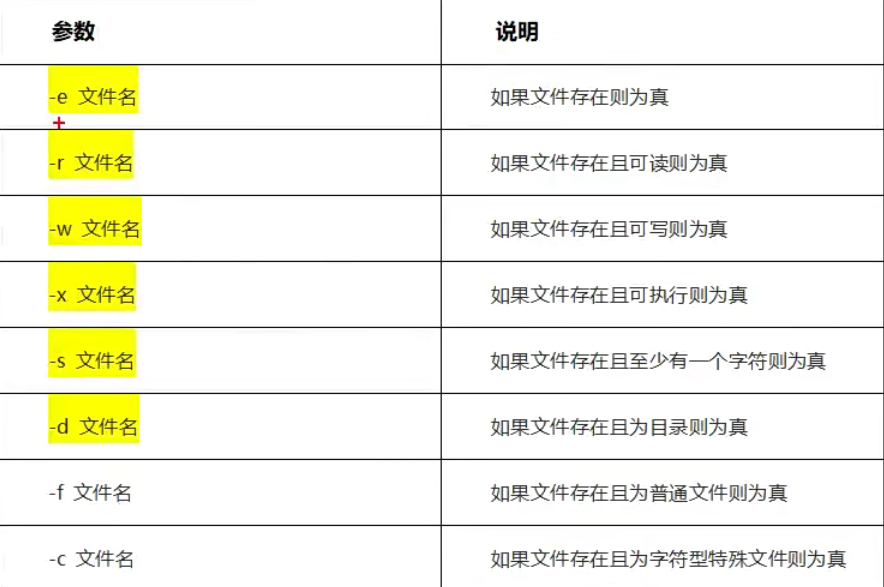
文件测试运算符
文件测试运算符用于检查文件,如检查文件是否存在、是否可读、是否可执行、是否为空、是否可写、是否是目录、是否是普通文件。
属性检测描述如下:

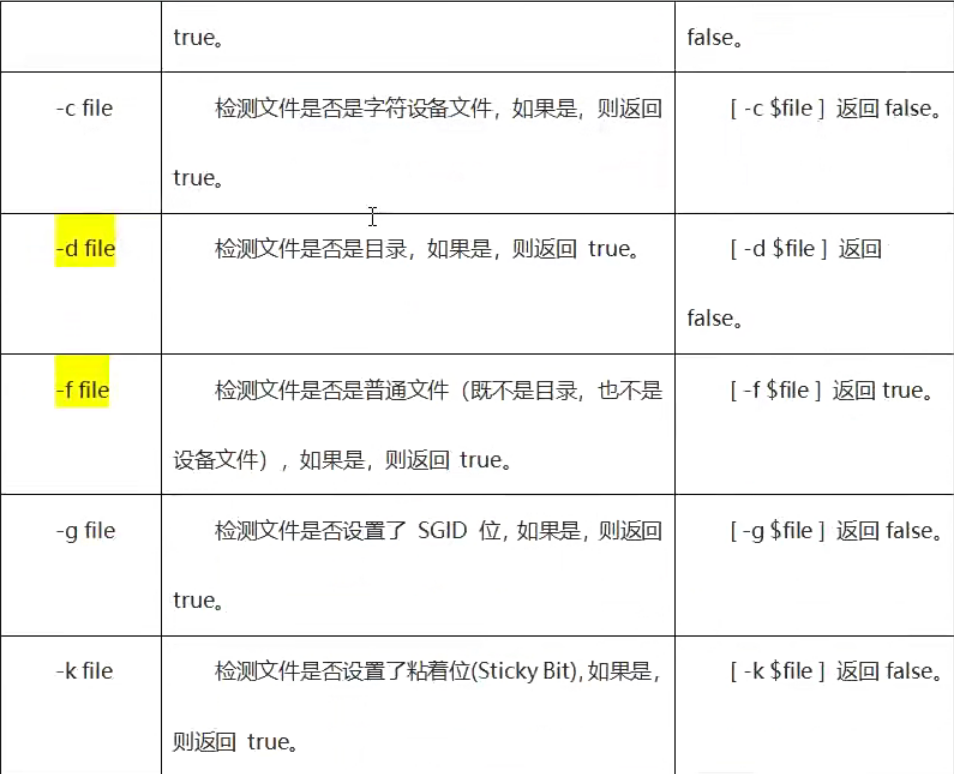
#!/bin/bash
# 文件测试运算符
file=/root/test_shell/test_suanshu.sh
if [ -e $file ]
then
echo "文件存在"
else
echo "文件不存在"
fi
# 判断文件是普通文件吗
if [ -f $file ]
then
echo "文件是普通文件"
else
echo "文件不是普通文件"
fi
# 判断文件是目录吗
if [ -d $file ]
then
echo "文件是目录"
else
echo "文件不是目录"
fi
# 判断文件是否为空
if [ -s $file ]
then
echo "文件不为空"
else
echo "文件为空"
fi
# 判断文件是否可读 可写 可执行
if [-r $file ]
then
echo "文件可读"
else
echo "文件不可读”
fi
if [ -w $file ]
then
echo "文件可写"
else
echo "文件不可写"
fi
if [ -x $file ]
then
echo "文件可执行"
else
echo "文件不可执行"
fi
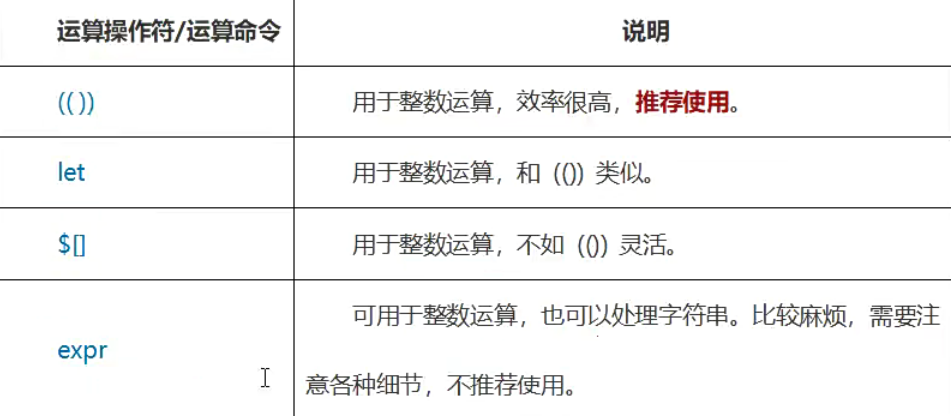
计算命令
要想让数学计算发挥作用,必须使用数学计算命令,shell中常用的数学计算命令如下表所示。
expr命令
expr用于求表达式的值
语法:
expr 算术运算符表达式
【示例】expr求表达式的值

【示例】expr表达式的值赋给变量

expr在字符串中的使用
计算字符串的长度
expr length 字符串
【示例】计算字符串的长度

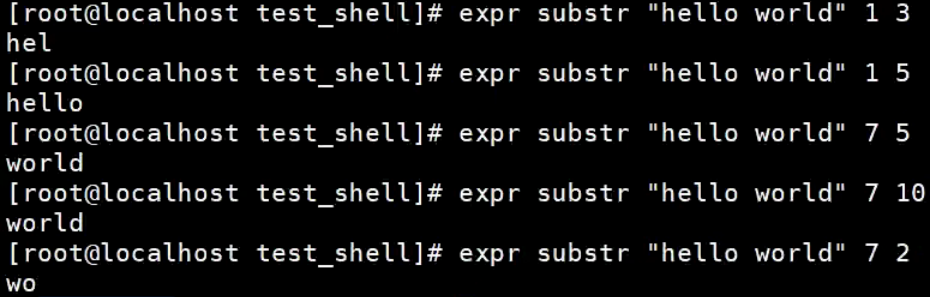
截取字符串
expr substr 字符串 start len
start:截取字符串的起始位置,从1开始
len:截取字符串的个数
获取第一个字符在字符串中出现的位置
expr index 被查找字符串 需要查找的字符
【示例】获取第一个字符在字符串中出现的位置

正则表达式匹配语法1
expr match 字符串 正则表达式
返回值为符合匹配字符串的长度,否则返回为0
【示例】正则表达式匹配语法1

正则表达式匹配语法2
expr 字符串 : 正则表达式
返回值为符合匹配字符串的长度,否则返回为0
【示例】正则表达式匹配语法2

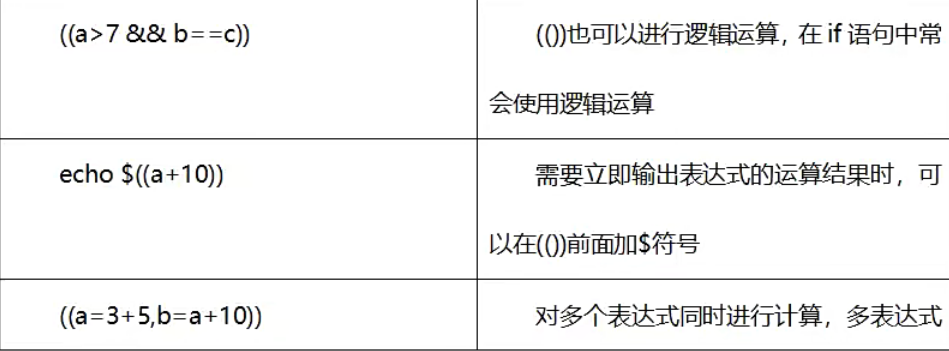
(())命令
能够使用(())进行整数的数学运算。将数学运算表达式放到((和))之间,可以使用$获取(())表达式命令的结果,这和使用$获得变量值是一样的。
语法:
((表达式))
用法:


#!/bin/bash
# (())命令的使用
((a=10+20))
((b=a-10))
((c=a+b))I
echo "a=$a,b=$b,c=$c"
a=$((10+20))
b=$((a-10))
c=$((a+b))
echo "a=$a,b=$b,c=$c"
if ((a>10 && a==c))
then
echo "a>10 && a==c"
else
echo "不成立"
fi
echo $((100+100))
((a=10+20,b=a-10,c=a+b))
echo "a=$a,b=$b,c=$c"
注意:符号之间有无空格都可以,((a = 1 + 2))等价于((a=1+2))
let命令
能够使用let进行整数的数学运算赋值。let命令和双小括(())在数字计算方面功能一样,但是没有(())功能强大,let只能用于赋值计算,不能直接输出,不可以条件判断。
语法:
let 赋值表达式
多个表达式赋值语法:
let 变量名1=值1 变量名2=值2 …
#!/bin/bash
# let命令的使用
let a=10+20
let b=a-10
let c=a+b
echo "a=$a,b=$b,c=$c"
echo"a=${a},b=${b},c=${c}"
# let命令用于多个赋值表达式
let a=10+20 b=a-10 c=a+b
echo "a=$a,b=$b,c=$c"
$[]命令
和(())和Iet命令类似,$[]也只能进行整数运算,但是只能对单个表达式的计算求值与输出。
语法:
$[表达式]
$[]会对表达式进行计算,并取得计算结果- 表达式内部不可以赋值给变量
#!/bin/bash
a=$[10+20]
b=$[a-10]
c=$[a+b]
echo "a=$a,b=$b,c=$c"
执行整数表达式命令总结:
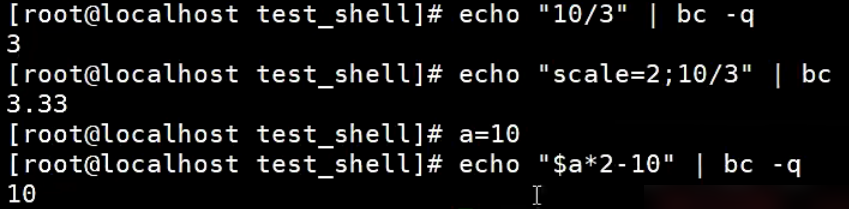
bc命令
Bash shell内置了对整数运算的支持,但是并不支持浮点运算,而linux bc命令可以很方便的进行浮点运算。bc命令是Liux简单的计算器,能进行进制转换与计算。能转换的进制包括十六进制、十进制、八进制、二进制等。可以使用的运算符号包括(+)加法、(-)减法、(*)乘法、(/)除法、(^)指数、(%)余数等。
语法:
bc [options] [参数]
options选项
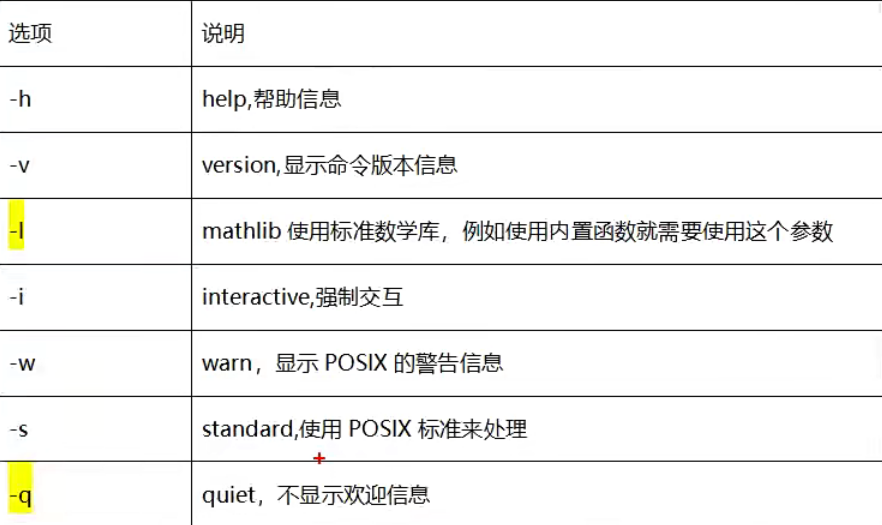
默认使用bc命令后回车会有很多欢迎信息,可以使用bc -q回车后不会有欢迎信息。

基本使用

【示例】bc命令执行计算任务的文件
创建一个文件test task.txt
108*67+123456
58+2008*11
3.14*43+187.23
执行任务文件计算每行表达式的值
bc -q test_task.txt
内置变量的使用
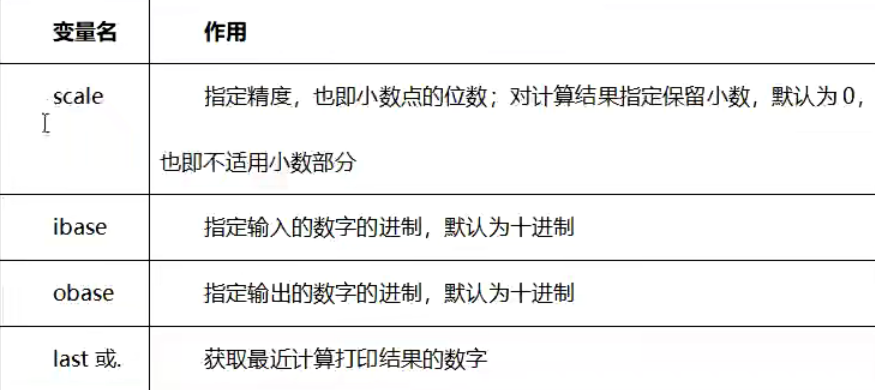
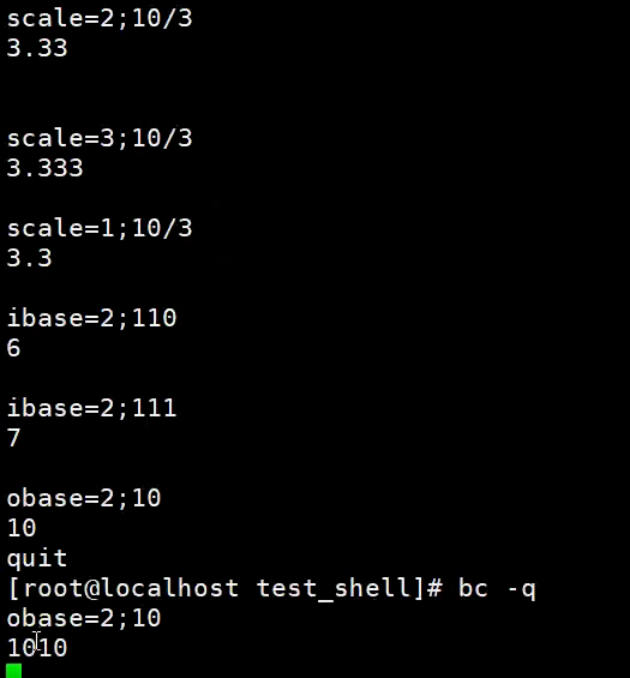
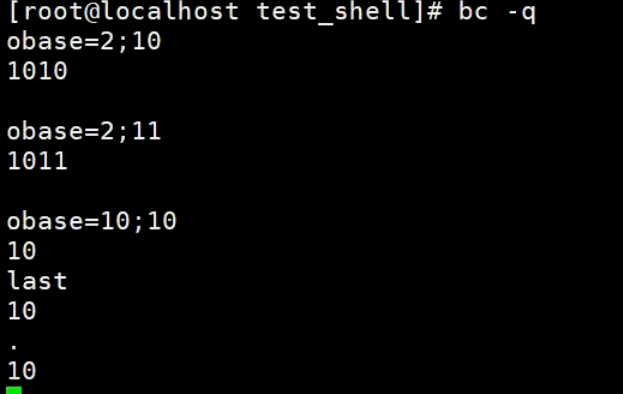
内置数学函数的使用
内置数学函数
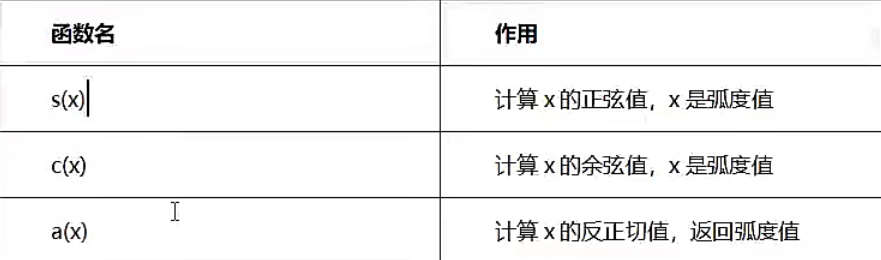
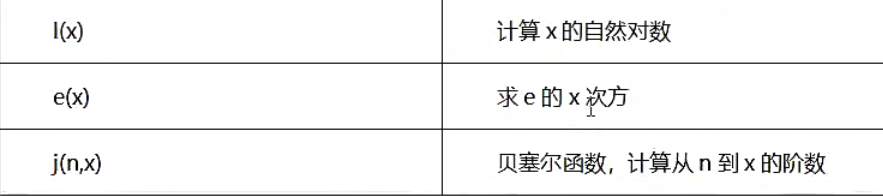
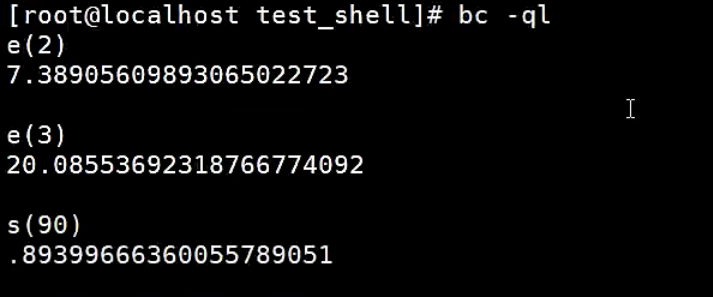
【示例】bc中内置的数学函数的使用
使用内置函数时必须使用bc -ql
非互动式的运算
直接进行bc的表达式计算输出
echo "expression" | bc [options]
expression:表达式必须符合bc命令要求的公式
表达式里面可以引用shell变量
例如:shell变量a=2在表达式里面引用的语法:$a
【示例】bc中非互动式的运算
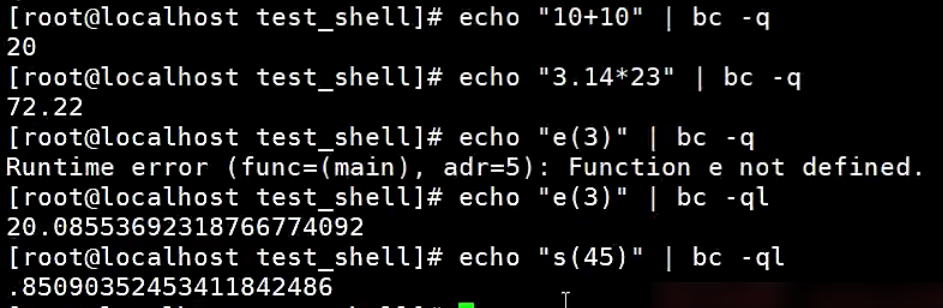
将bc计算的结果赋值给shell变量
语法格式:
#第一种方式
var name=`echo "expression" | bc [options]`
#第二种方式
var name=$(echo "expression" | bc [options])
$()与``功能一样,都是执行里面的命令
区别:
``是所有linux系统支持的方式,兼容性较好,但是容易与引号产生混淆。
$()不是所有linux系统都支持的方式。兼容性较差,但是不容易产生混淆。
【示例】将bc计算的结果赋值给shell变量
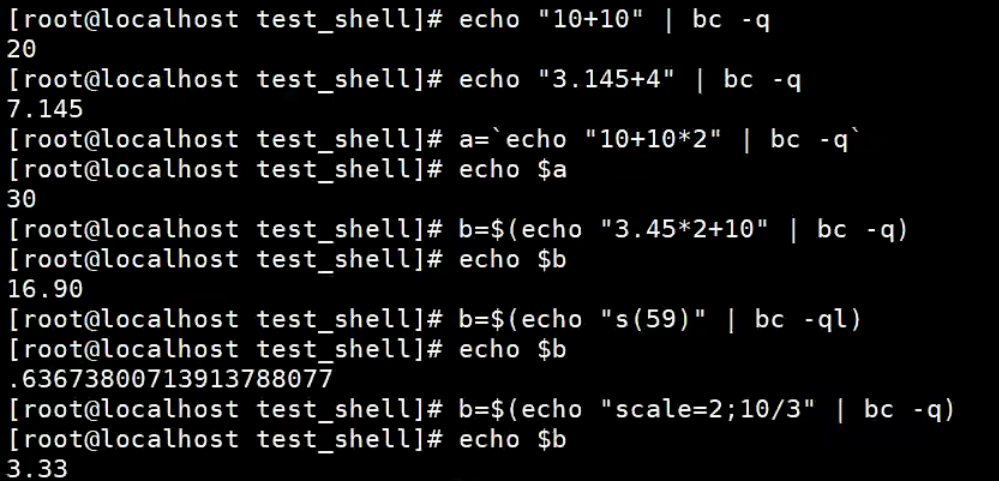
非互动式的输入重定向运算
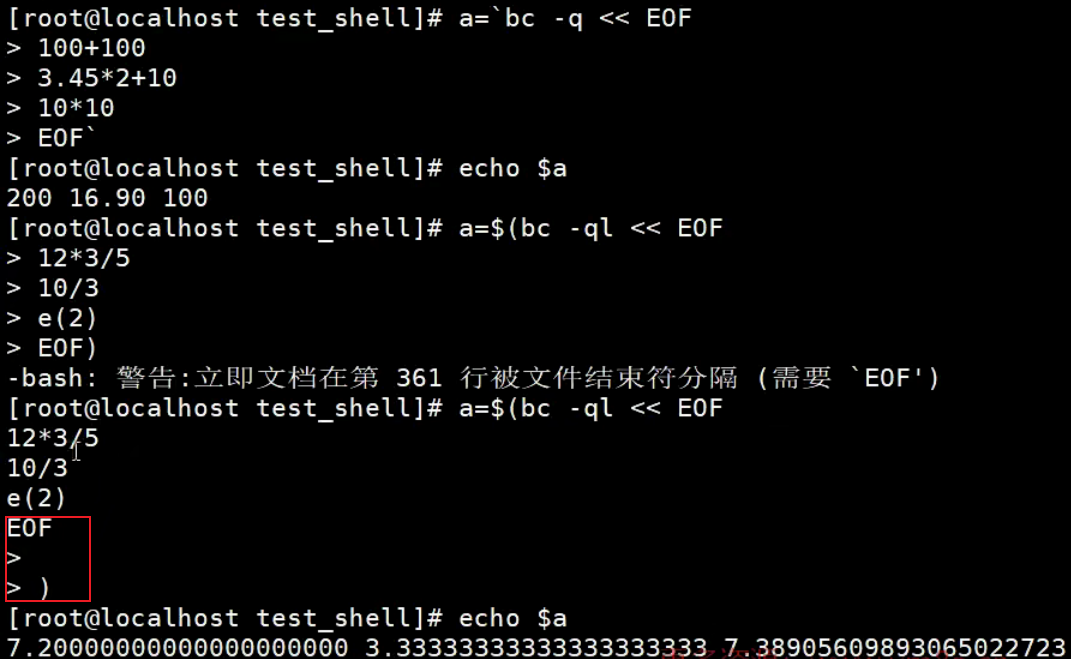
将计算表达式输出给bc去执行,特点类似于文件中输入,可以输入多行表达式。更加清晰。
语法:
#第一种方式
var name=`bc [options] <<EOF
第一行表达式
第二行表达式
...
EOF
`
#第二种方式
var name=$(bc [options] <<EOF
第一行表达式
第二行表达式
...
EOF
)
var name这里Shell变量的名字
bc执行bc的命令
EOF…EOF输入流的多行表达式
含义:将EOF中间多行表达式输入给到bc去执行,将bc执行的结果赋值shel变量
【示例】Shell中非互动式的输入重定向运算
流程控制语句
条件if语句
if语句语法格式
if condition
then
command1
command2
...
commandN
fi
写成一行(适用于终端命令提示符):
if 条件;then 命令;fi
【示例】判断num的值是否是10
#!/bin/bash
# 测试if单分支
# 键盘输入一个数num
read -p "请输入一个数:" num
if ((num==10))
then
echo"您输入的数是10"
fi
if else语句语法格式
if condition
then
commadd1
command2
...
commandN
else
command
fi
写成一行(适用于终端命令提示符):
if 条件;then 命令;else 命令;fi
【示例】输入年龄判断是否成人
#!/bin/bash
# 测试if else
read -p"请输入年龄:"age
if ((age>=18))
then
echo "成年"
else
echo "未成年"
fi
if else-if else语法格式
if condition1
then
command1
elif codition2
then
command2
else
commandN
fi
【示例】输入成绩判断成绩等级
#!/bin/bash
# 测试if elif else 多分支结构
read -p "请输入成绩:" score
if ((score>=90))
then
echo "成绩等级为A"
elif ((score>=80))
then
echo "成绩等级为B"
elif ((score>=70))
then
echo "成绩等级为C”
elif ((score>=60))
then
echo "成绩及格"
else
echo "成绩不及格"
fi
【示例】根据输入的值判断是周几。如输入1输出”周一“
#!/bin/bash
read -p"请输入一个数(1-7):" num
if [[ $num == 1 ]]
then
echo "周一"
elif [[ $num == 2 ]]
then
echo "周二"
fi
选择嵌套
语法格式
if [ condition1 ];then
command1
if [ condition2 ];then
command2
fi
else
if [ condition3 ];then
command3
elif [ condition4 ];then
command4
else
command5
fi
fi
【示例】输入成绩输出成绩的等级
#!/bin/bash
# if条件语句嵌套
read -p "请输入成绩:" score
if ((score>0 && score<=100))
then
echo "输入的成绩是正确的"
if ((score>=90))
then
echo "成绩的等级为A"
elif ((score>=80))
then
echo "成绩的等级为B"
elif ((score>=70)】
then
echo "成绩的等级为C"
elif ((score>=60)】
then
echo "及格"
else
echo "不及格"
fi
else
echo "偷入的成绩不正确”
fi
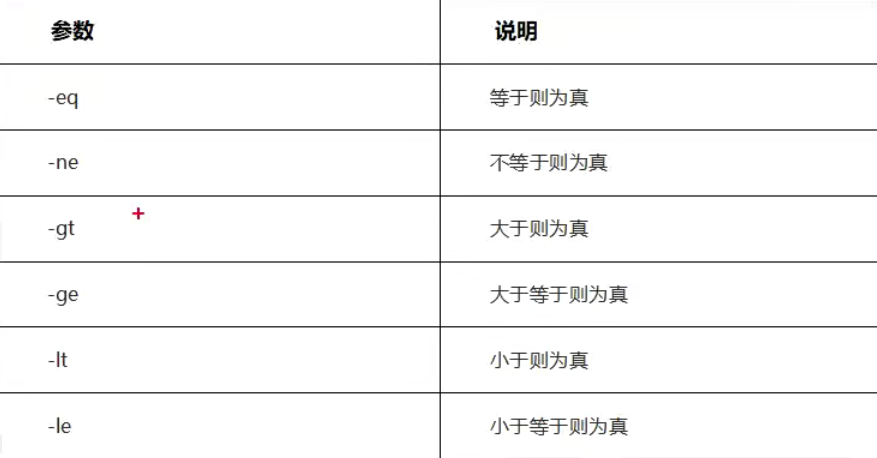
内置命令test
Shell中test命令用于检查某个条件是否成立,它可以进行数值、字符串和文件三个方面的测试。功能和一样。
整数比较测试
整数比较语法
if test 数字1 options 数字2
then
fi
options具体如下:
#!/bin/bash
# test命令检查整数
num1=100
num2=200
if test $numl -lt $num2
then
echo "num1小于num2"
else
echo "num1不小于num2"
fi
num3=200
if test $num2 -eq $num3
then
echo "num2和num3相等"
fi
# -a -o
if test $num1 -lt $num2 -a $num2 -eq $num3
then
echo "两个条件成立"
else
echo "两个条件不成立"
fi
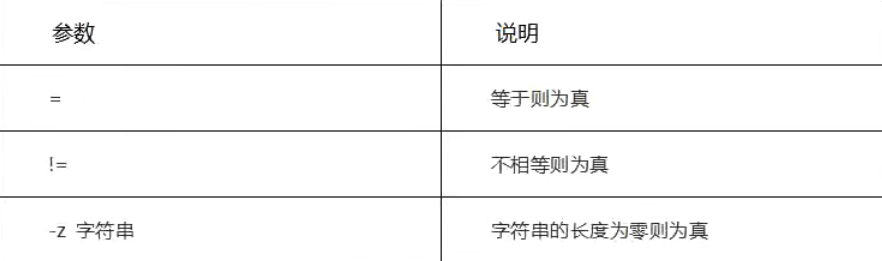
字符串比较测试

#!/bin/bash
# test命令检查字符串
str1="hello"
if test -z $str1
then
echo "str1为空"
else
echo "str1不为空"
fi
if test $str1
then
echo "str1不为空"
else
echo "str1为空"
fi
str2="world"
if test $strl = $str2
then
echo "str1和str2相等"
else
echo "不相等"
fi
# 多条件
if test $strl -o 1 -eq 1
then
echo "条件成立"
fi
if test $strl -a 10 -eq 1
then
echo "条件成立"
else
echo "条件不成立"
fi
文件测试
#!/bin/bash
# test检查文件
file="/root/test_shell/test_test1.sh"
if test -e $file
then
echo "文件存在"
else
echo "文件不存在”
fi
if test -r $file
then
echo "文件可读”
fi
if test -w $file
then
echo "文件可写"
fi
if test -s $file
then
echo "文件不为空"
fi
if test -d $sfile
then
echo "文件是目录"
else
echo "文件不是目录"
fi
test命令经常与-a和-o一起使用,&&和||只能使用到[]中
【示例】if中有多条件时候,必须都满足才会执行
根据提示输入文件全名和输入写入的数据。判断文件是否有可写权限和输入的数据长度不为0,满足以上2个条件将用户的数据写入到指定的文件中去。
#!/bin/bash
read -p "请输入文件名:" filename
read -p "请输入写入的内容:" data
echo "文件名:$filename,内容:$data"
if test -w $filename -a -n $data
then
echo $data > $filename
echo "写入内容成功"
else
echo "写入内容失败"
fi
case语句
case...esac为多选择语句,与其他语言中的switch…case语句类似,是一种多分枝选择结构,每个case分支用右圆括号)开始,用两个分;;表示执行结束,跳出整个case…esac语句,esac(就是case反过来)作为结束标记。
可以用case语句匹配一个值与一个模式,如果匹配成功,执行相匹配的命令。
case...esac语法格式如下:
case 值 in
模式1)
command1
command2
...
commandN
;;
模式2)
command1
command2
...
commandN
;;
esac
case工作方式如上所示,取值后面必须为单词in,每一模式必须以右括号结束。取值可以为变量或常数,匹配发现取值符合某一模式后,其间所有命令开始执行直至;;。
取值将检测匹配的每一个模式。一旦模式匹配,则执行完匹配模式相应命令后不再继续其他模式。如果无一匹配模式,使用星号*捕获该值,再执行后面的命令。
case、in和esac都是Shell关键字,esac就是case的反写在这里代表结束case。
匹配模式:可以是一个数字、一个字符串,甚至是一个简单正则表达式。
简单正则表达式支持如下通配符:

#!/bin/bash
# case多分支选择结构
read -p "请输入一个(0-7)之间的数:" num
case $num in
1)
echo "周一"
;;
2)
echo "周二"
;;
3)
echo "周三"
;;
4)
echo "周四"
;;
5)
echo "周五"
;;
6)
echo "周六"
;;
0|7)
echo "周日"
;;
*)
echo "输入有误"
;;
esac
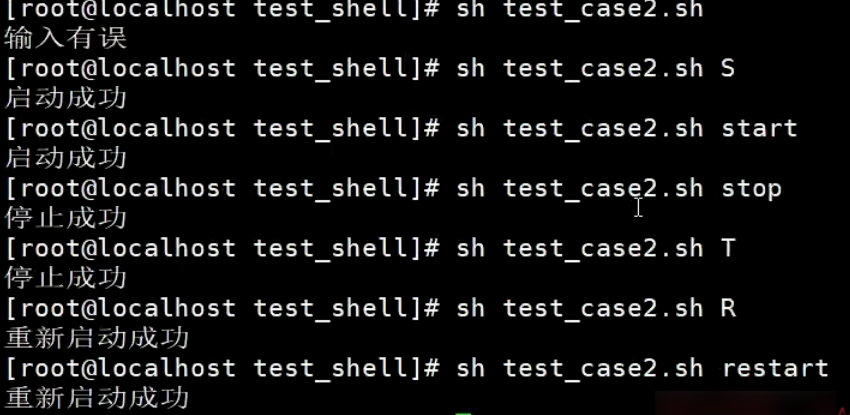
#!/bin/bash
# case多分支结构
case $1 in
start | S)
echo "启动成功"
;;
stop | T)
echo "停止成功"
;;
restart | R)
echo "重新启动成功"
;;
*)
echo "输入有误"
;;
esac
while语句
while循环
while循环用于不断执行一系列命令,也用于从输入文件中读取数据。其语法格式为:
while condition
do
command
done
#!/bin/bash
# while循环
# 键盘输入一个数
read -p "请输入一个整数:" num
i=1
while ((i<=num))
do
echo"当前i的值:$i"
let i++
done
#!/bin/bash
#使用whi1e循环求1-100的和
i=1
sum=0
while ((i<=100))
do
sum=$((sum+i))
#sum=`expr $sum + $i`
#sum=$(($sum+$i))
let i++
done
echo "sum: $sum"
无限循环
无限循环语法格式:
while:
do
command
done
或
while true
do
command
done


跳出循环
在循环过程中,有时候需要在未达到循环结束条件时强制跳出循环,Shell使用两个命令来实现该功能:break和continue
break命令
break命令允许跳出当前整个循环。
【示例】break命令退出当前循环,脚本进入死循环直至用户输入数字大于5。要跳出这个循环
#!/bin/bash
# 退出循环break的使用
while true
do
read -p "请输入一个整数:" num
case $num in
1|2|3|4|5)
echo "您输入的数:$num"
;;
*)
echo "您输入的数不是1 2 3 4 5,退出循环"
break
;;
esac
done
continue命令
continue命令允许跳出本次循环。
#!/bin/bash
# 测试退出循坏continue
while
do
read -p "请输入一个数:" num
if ((num==1 || num==2 || num==3 || num==4 || num==5))
then
echo "您输入的数是:$num"
else
echo "您输入的数不是1 2 3 4 5"
continue
echo"continue退出本次循环"
fi
done
until语句
until循环执行一系列命令直至条件为true时停止。until循环与while循环在处理方式上刚好相反。
一般while循环优于until循环,但在某些时候一也只是极少数情况下,until循环更加有用。
until语法格式:
until condition
do
command
done
condition一般为条件表达式,如果返回值为false,则继续执行循环体内的语句,否则跳出循环。
【示例】使用until命令来输出0~9的数字
#!/bin/bash
# 测试until循坏
# 输出0-9的数
i=0
# until [[ ! $i -le 9 ]]
until ((i>9))
do
echo "当前i的值:$i"
let i++
done
#计算1-100之间的和
i=1
sum=0
until ((i>100))
do
sum=$((i+sum))
let i++
done
echo "1-100的和:$sum"
for语句
循环第一种方式
与其他编程语言类似,Shell支持for循环。
for循环一般格式为:
for var in item1 item2 ... itemN
do
command1
command2
commandN
done
写成一行:
for var in item1 item2 ... itemN;do command1;command2... done;
【示例】for循环顺序输出当前列表中的数字
#!/bin/bash
# for循环 for in
for i in 1 2 3 10 20 30
do
echo "当前变量的值:$i"
done
for v in hello bai d com baizhai
do
echo "当前变量的值:$v"
done
循环第二种方式
语法:
for var in {start..end}
do
命令
done
start:循环范围的起始值必须为整数
end:循环范围的结束值,必须为整数
#!/bin/bash
#输出1-10的整数
for i in {1..10}
do
echo "当前整数:$i"
done
sum=0
for i in {1..100}
do
sum=$((sum+i))
done
echo "1-100的和:$sum"
循环第三种方式
语法:
for((i=start;i<=end;i++))
do
命令
done
一行写法:
for(i=start;i<=end;i++);do 命令;done
#!/bin/bash
#使用for循环输出10-20之间的数
for((i=10;i<=20;i++))
do
echo "当前i的值:$i"
done
for循环的无限循环
for循环的无限循环语法:
for((;;));do 命令;done
#!/bin/bash
# for无限循环
i=1
for((;;))
do
if((i==5))
then
echo "i等于5退出循环"
break
else
echo "当前i的值:$i"
let i++
fi
done
select语句
select in循环用于增强交互性,它可以显示出带编号的菜单,用于输入不同的编号就可以选择不同的菜单,并执行不同的功能,select in是Shell独有的一种循环,非常适合终端这样的交互场景,其它语言没有。
语法格式如下:
select var in 菜单1 菜单2 ...
do
命令
done
注意:select是无限循环(死循环),输入空值,或者输入的值无效,都不会结束循环,只有遇到break语句,或者按下Ctrl+D组合键才能结束循环。
执行命令中终端输出#?代表可以输入选择的菜单编号
【示例】select in的使用
#!/bin/bash
# 测试select语句的使用
echo "一年四个季节,您最喜欢哪个季节?"
select d in "春大" "夏天" "秋大" "冬天"
do
echo "您最喜欢的季节是:$d"
break
done

#!/bin/bash
# select语句与case一起使用
echo "您最喜欢的老师是哪位?"
select t in 张老师 李老师 王老师 赵老师
do
case $t in
"张老师")
echo "您最喜欢的老师是张老师"
break
;;
"李老师")
echo "您最喜欢的老师是李老师"
break
;;
"赵老师")I
echo "您最喜欢的老师是赵老师"
break
;;
"王老师")
echo "您最喜欢的老师是王老师"
break
;;
esac
done

Shell函数
Shell函数和其他编程语言一样,函数是由若干条Shell命令组成的语句块,实现Shell脚本代码重用和模块化编程。
系统函数
basename
basename返回完整路径最后/的部分,常用于获取文件名,基本语法如下:
basename [pathname] [suffix]
suffix为后缀,如果suffix被指定了,basename会将pathname或string中的suffix去掉。
【示例】basename的使用

【示例】basename的使用(写入到脚本文件)
#!/bin/bash
# 系统函数basename
filename1=`basename /root/test_shell/test_while.sh`
filename2=$(basename /root/test_shell/test_while.sh .sh)
echo "filenamel:$filename1"
echo "filename2:$filename2"
dirname
dirname返回完整路径最后V的前面的部分,常用于返回路径部分。
dirname文件绝对路径(功能描述:从给定的包含绝对路径的文件名中去除文件名(非目录的部分),然后返回剩下的路径(目录的部分))
【示例】dirname的使用

【示例】dirname的使用(写到脚本中)
#!/bin/bash
# dirname系统函数
filename=`basename /root/test_shell/test_while.sh`
mydire=$(dirname /root/test_shell/test_while.sh)
echo "文件名:$filename"
echo "文件路径:$mydire"
自定义函数
函数定义
shell中函数的定义格式如下:
[ function ] funname [()]
{
action;
[return int;]
}
说明:
- 可以带function fun()定义,也可以直接fun()定义,不带任何参数。
- 参数返回,可以显示加:return返回,如果不加,将以最后一条命令运行结果,作为返回值。return后跟数值n(0-255)
#!/bin/bash
# 自定义函数
function test_fun1(){
echo "自定义函数fun1"
}
# 调用函数之前必须先定义好函数
# test fun2
test fun2(){
echo "自定义函数fun2"
}
# 调用函数
test_fun1
test_fun2
【示例】函数示例(有返回值)
#!/bin/bash
# 定义函数,有返回值
test_add(){
# 键盘输入两个整数
read -p "请输入第一个整数:" num1
read -p "请输入第二个整数:" num2
return $((num1+num2))
# 调用函数
test_add
# 获取函数的返回值
echo "函数的返回值:$?"
函数返回值在调用该函数后通过$?来获得。
注意:所有函数在使用前必须定义。这意味着必须将函数放在脚本开始部分,直至shell解释器首次发现它时,才可以使用。调用函数仅使用其函数名即可。
函数参数
在Shell中,调用函数时可以向其传递参数。在函数体内部,通过$n的形式来获取参数的值,例如,$1表示第一个参数,$2表示第二个参数…
注意,$10不能获取第十个参数,获取第十个参数需要${10}。当n>=10时,需要使用${n}来获取参数。
【示例】函数参数的使用
#!/bin/bash
#定义函数传递函数参数
test_param(){
echo "第一个参数:$1"
echo "第二个参数:$2"
echo "第三个参数:$3"
echo "第10个参数:${10}"
echo "第11个参数:${11}"
# 调用函数
test_param 1 2 3 4 5 6 7 8 9 100 101 102
【示例】定义函数绘制图像
#!/bin/bash
#定义函数及for循环综合练习
#输出一个矩形
echo "输出一个矩形"
test_fun1(){
for i in {1..5}
do
echo "***"
done
}
test_fun1
echo '输出一个矩形2'
test_fun2(){
for((i=1;i<=6;i++))
do
for((j=1;j<=4;j++))
do
echo -n "*"
done
echo # 输出换行
done
}
test_fun2
echo "输出直角三角形”
test_fun3(){
for((i=1;i<=5;i++))
do
for((j=1;j<=$i;j++))
do
echo -n "*"
done
echo
done
}
test_fun3

Shell程序与函数的区别
函数和Shell程序比较相似,区别在于:
Shell程序(内置命令和外部脚本文件),外部脚本文件是在子Shell中运行,会开启独立的进程运行。
Shell函数在当前Shell的进程中运行。
【示例】Shel程序与函数的区别
#!/bin/bash
test_fun(){
echo "函数中输出:进程ID$$"
}
test_fun
echo "脚本文件中:进程ID$$"

Shell重定向输入输出
概念
标准输入
从键盘读取用户输入的数据,然后再把数据拿到Shell程序中使用。
标准输出
Shell程序产生的数据,这些数据一般都是呈现到显示器上供用户浏览查看
输入输出重定向
输入方向就是数据从哪里流向程序。数据默认从键盘流向程序,如果改变了它的方向,数据就从其它地方流入,这就是输入重定向。
输出方向就是数据从程序流向哪里。数据默认从程序流向显示器,如果改变了它的方向,数据就流向其它地方,这就是输出重定向。
文件描述符
linux命令默认从标准输入设备(stdin)获取输入,将结果输出到标准输出设备(stdout)显示。一般情况下,标准输入设备就是键盘,标准输出设备就是终端,即显示器。
在linux shell执行命令时,每个进程都和三个打开的文件相联系,并使用文件描述符来引用这些文件。由于文件描述符不容易记忆,shell同时也给出了相应的文件名。

重定向命令列表

输出重定向



输入重定向
wC命令可以用来对文本进行统计,包括单词个数、行数、字节数。
wc语法格式:
wc [options] [文件名]
options有如下:


【示例】读取文件每行内容
#!/bin/bash
# 输入重定间
# 读取文件内容
r=1
while read m
do
echo"第$r行,内容是:$m"
let r++
done < log.txt
【示例】标记位读取内容

文本处理工具
grep文本搜索
grep是一种强大的文本搜索工具,用于根据关键字进行行过滤,并把匹配的行打印出来。
grep语法格式:
grep [选项] '关键字' 文件名
它在一个或多个文件中搜索满足模式的文本行。
常用的grep选项:









cut按列切分文本
cut译为“剪切、切割”,是一个强大文本处理工具,它可以将文本按列进行划分的文本处理。cut命令逐行读入文本,然后按列划分字段并进行提取、输出等操作。
语法格式:
cut [options] 文件名
options参数说明

提取范围说明

【示例】cut的使用
准备test_cut.xt文件内容

【示例】cut截取列数据


【示例】cut按字符提取



【示例】cut的切割获取指定单词

【示例】cut的切割bash进程的PID号

【示例】cut的切割当前服务器的IP

sed文本编辑器
sed是Liux下一款功能强大的非交互流式文本编辑器,可以对文本文件进行增、删改、查等操作,支持按行、按字段、按正则匹配文本内容,灵活方便,特别适合于大文件的编辑。
sed工作原理:sed会读取每一行数据到模式空间中,判断当前行是否符合模式心配要求,符合要求就会执行sed程序命令,否则不会执行sed程序命令,如果不写四配模式,那么每一行都会执行sed程序命令。
sed的使用语法:
sed [选项参数] [模式匹配 | sed程序命令] [文件名]
sed的常用选项:


【示例】向文件中添加或插入行
1.准备test_sed.txt内容
2.sed '3aworld' test_sed.txt #向第三行后面添加world,3表示行号

注意:预览可以看到是添加了,但实际没有添加到文件内容。想要真是的添加到文件,需要加选项 -i。




【示例】更改文件中指定的行


【示例】删除文件中的行


2.删除3~5之外的所有行

3.删除从匹配abc的行到最后一行

4.删除空行

5.删除不匹配hello或abc的行,/hello\|abc/表示匹配hello或abc,!表示取反

6.删除1~3行中,匹配内容hello的行,1,3表示匹配1~3行,{/hello/d}表示删除匹配hello的行

【示例】替换文件中的内容
1.将文件中的a替换为123,默认只替换每行第一个123



4.将每行中所有匹配的a替换为123,并将替换后的内容写入test_sed2.txt


5.匹配有#号的行,替换匹配行中逗号后的所有内容为空(,.*)表示逗号后的所有内容

6.替换每行中的最后两个字符为空,每个点代表一个字符,$表示匹配末尾(...$)表示匹配最后两个字符

7.在test_sed.txt文件的每一行后面加上"hahha"字段

【示例】打印文件中的行
1.打印文件中的第三行内容

2.从第一行开始,每隔两行打印一行,波浪号后面的2表示步长

3.打印文件的最后一行

4.打印1-3行

5.打印匹配的行

【示例】打印文件的行号
1.打印test sed.txt文件最后一行的行号

2.打印匹配abc的行的行号

3.打印空行行号

【示例】从文件中读取内容
1.将文件test_sed3.txt中的内容,读入test_sed4.txt中,会在test_sed4.txt中的每一行后都读入test_sed3.txt的内容

2.在test_sed.3.txt的第3行之后插入文件test_sed4.txt的内容(可用于向文件中插入内容)

3.在匹配456的行之后插入文件test_sed4.txt的内容,如果test_sed3.txt中有多行匹配456则在每一行之后都会插入

4.在test_sed3.txt的最后一行插入test_sed4.txt的内容

【示例】向文件中写入内容
1.将test_sed3.txt文件的内容写入test_sed4.txt文件,如果test_sed3.txt文件不存在则创建,如果test_sed.4.txt存在则覆盖之前的内容

2.将文件test_sed3.txt中的第2行内容写入到文件test_sed4.txt

3.将test_sed3.txt的第2行和最后一行内容写入test_sed4.txt

-e: 它告诉sed将下一个参数解释为一个sed指令,只有当命令行上给出多个sed指令时才需要使用-e选项
4.将test_sed3.txt的第2行和最后一行内容分别写入test_sed4.txt和test_sed5.txt中

5.将test_sed3.txt中匹配789或123的行的内容,写入到test_sed4.txt中

6.将test_sed.3.txt中从匹配123的行到最后行的内容,写入到test_sed.4.txt中
,$:到最后一行

7.将test_sed3.txt中从匹配456的行及其后2行的内容,写入到test_sed4.txt中

awk文本分析工具
awk概述
awk是一种强大的文本分析工具,主要用于在linux/uniⅸ下对文本和数据进行处理。对数据进行分析、统计并生成报表,比如网站的访问量,访问的IP量等等。
awk是种编程语言,awk可以定义变量、运算符,使用流程控制语句进行深度加工与分析。
awk其名称得自于它的创始人Alfred Aho、Peter Weinberger和Brian Kernighan姓氏的首个字母。
awk的处理文本和数据的方式:把文件逐行读入,以空格为默认分隔符将每行切片。切片的部分再进行各种分析处理。
awk基本使用
使用方法:
awk 选项 '命令部分' 文件名
特别说明:引用shell变量需用双引号引起
常用命令选项

AWK内置变量


【示例】awk匹配内容整行输出,默认每行空格切割数据,并将这行赋给内部变量$0

【示例】awk匹配以root开头的行

【示例】awk使用一行作为输入,默认每行空格切割数据,并将这行赋给内部变量$0

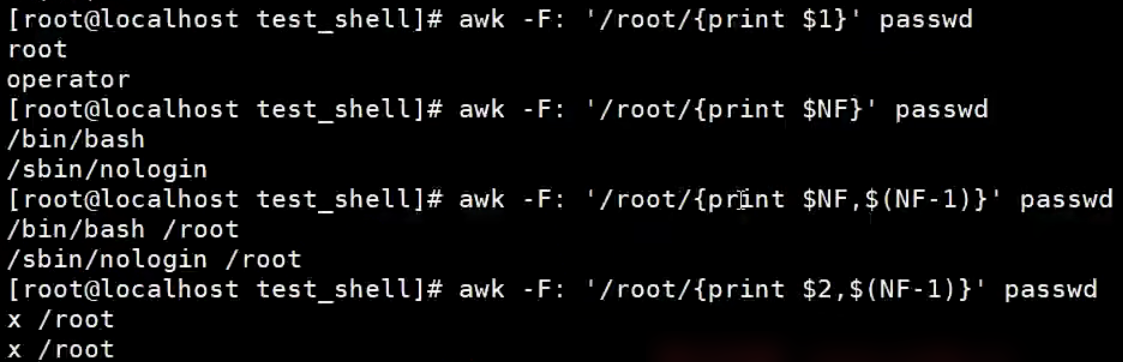
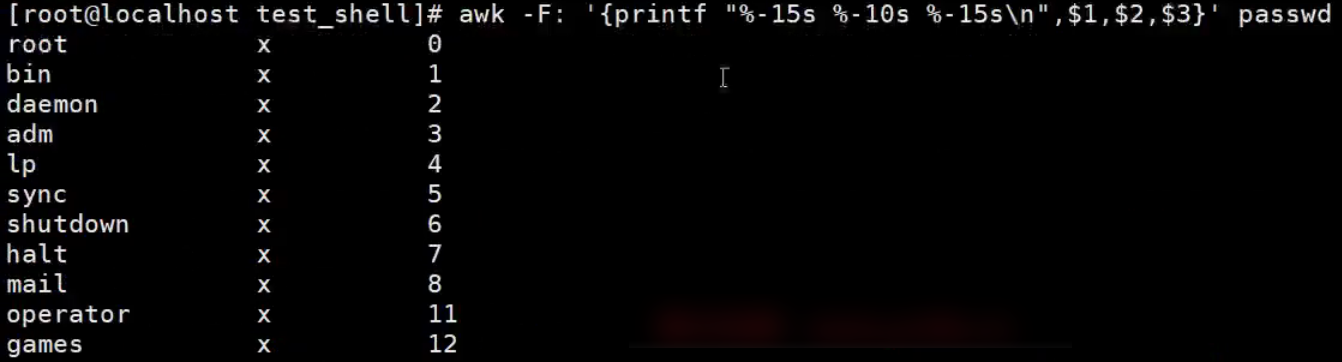
格式化输出print和printf
print函数:类似echo,它是换行输出
printf函数:类似echo-n,它不换行输出,可以使用%s、%d进行占位。其中%s表示字符类型,%d数值类型。
-:表示左对齐,默认是右对齐
例如:%-15s 表示所占15字符,使用左对齐方式显示。
【示例】print的使用

【示例】printf占位的使用
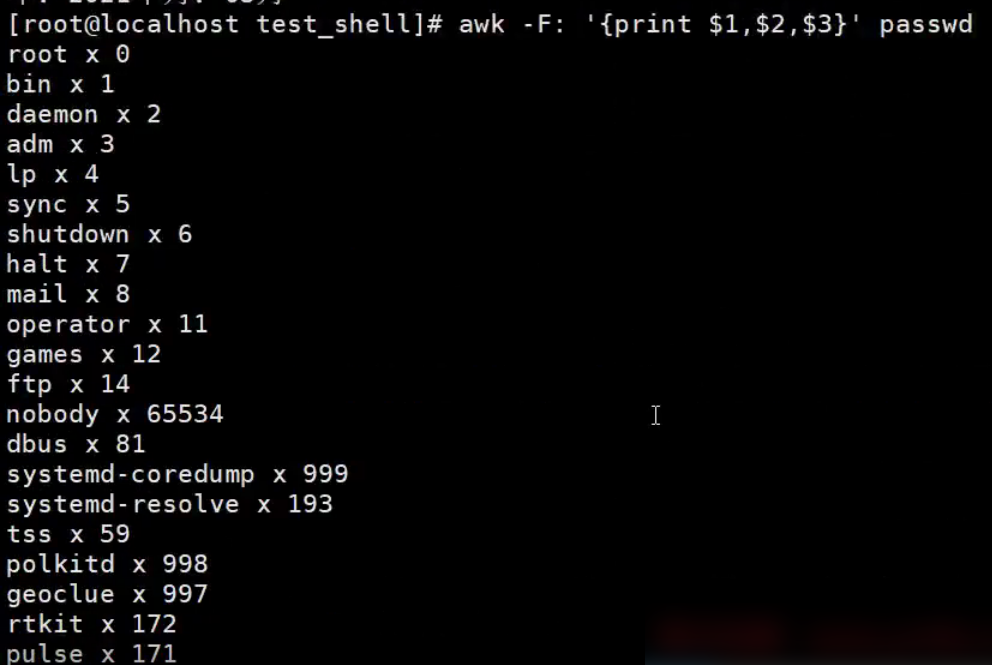

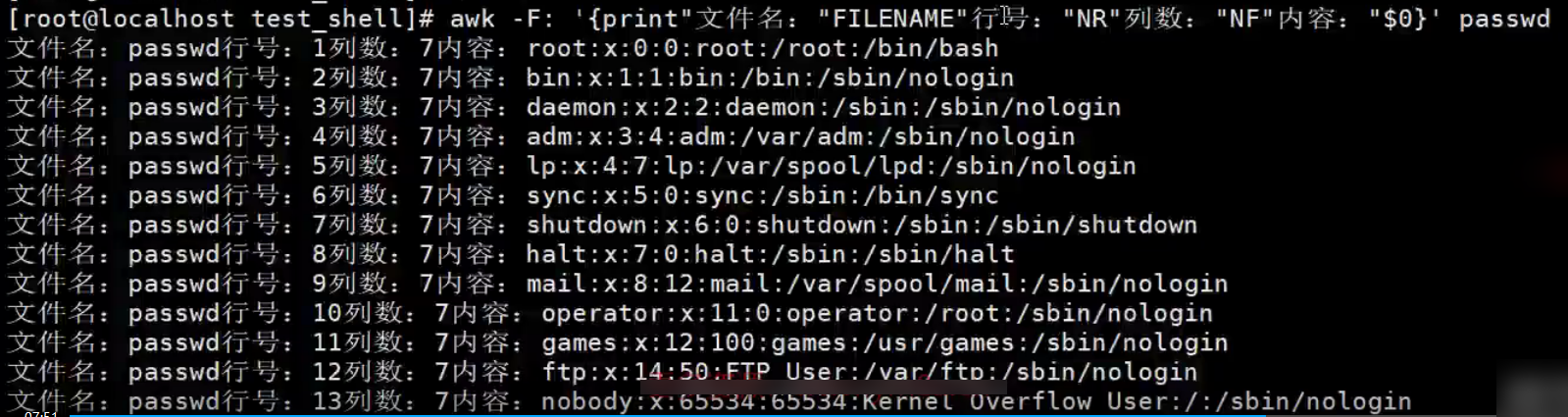
【示例】print打印文件每行属性信息
统计passwd文件名,每行的行号,每行的列数,对应的完整行内容
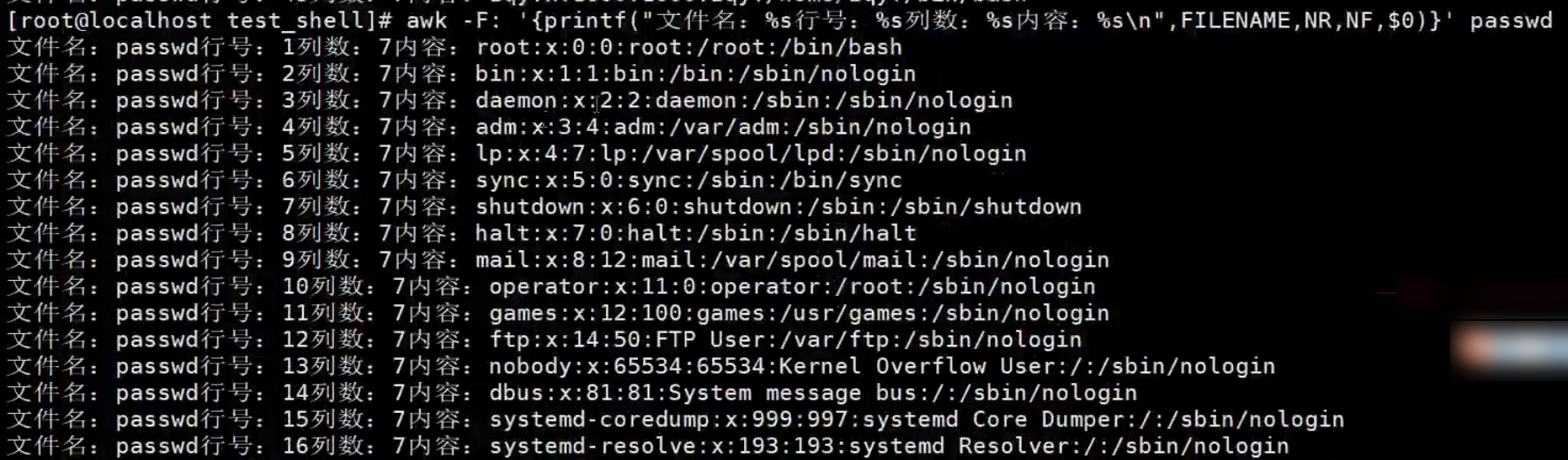
【示例】打印第三行信息

awk中BEGIN…END使用
BEGIN:表示在程序开始前执行
END:表示所有文件处理完后执行
用法:'BEGIN{开始处理之前};{处理中};END{处理结束后}'
【示例】添加开始与结束内容



awk变量定义
【示例】-v定义变量

awk中流程控制语句

-
if语句语法格式
{ if(表达式) {语句1;语句2;...} }
准备test_awk.txt文件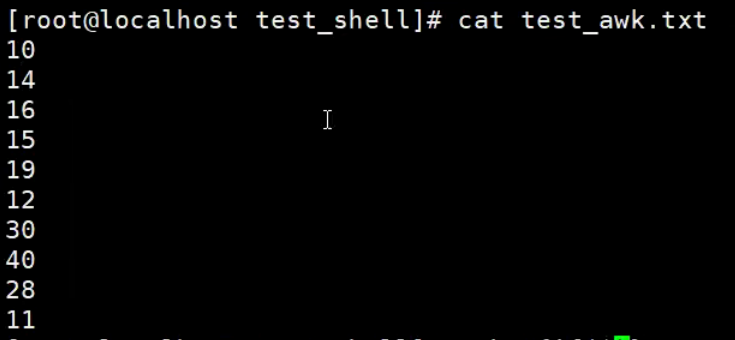
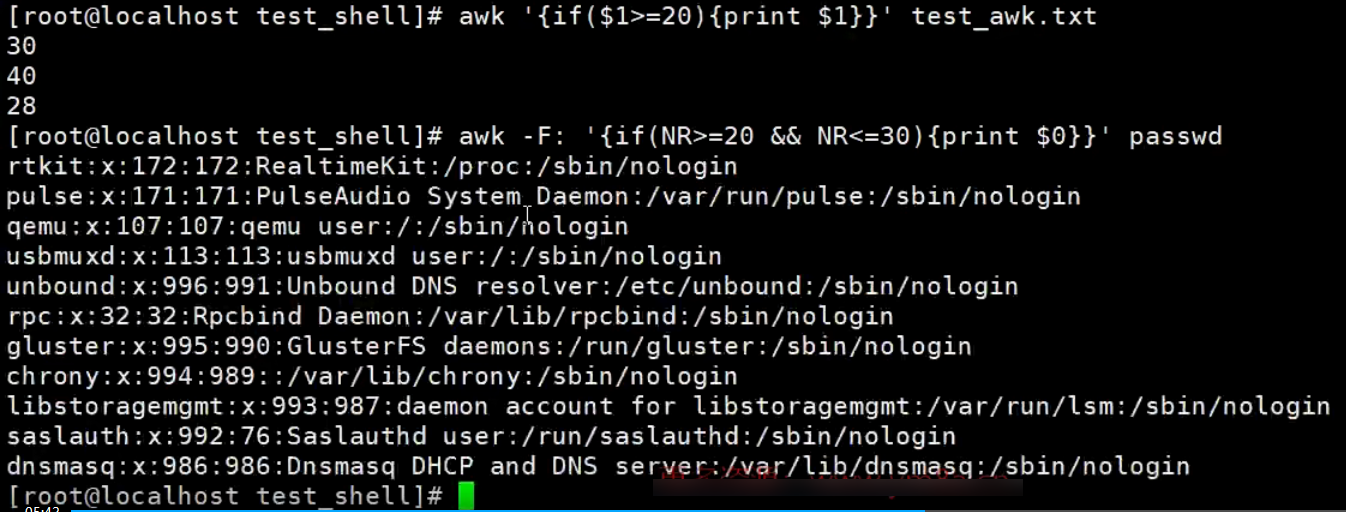
-
if else的语法格式
{if(表达式) {语句;语句;...} else{语句;语句;...}}【示例】awk中使用
if...else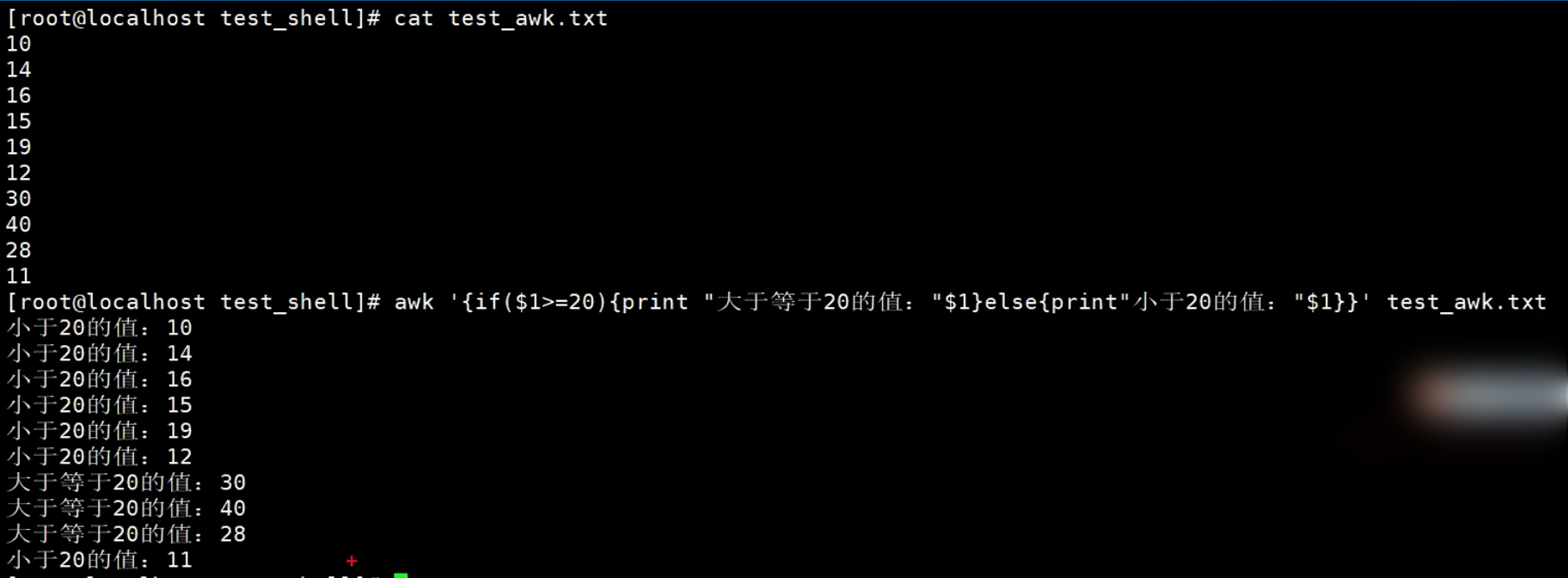

-
if else if else if的语法格式
{if(表达式1){语句;语句;...} else if(表达式2){语句;语句; ...} else if(表达式3){语句;语句; ...} else{语句;语句; ...}}

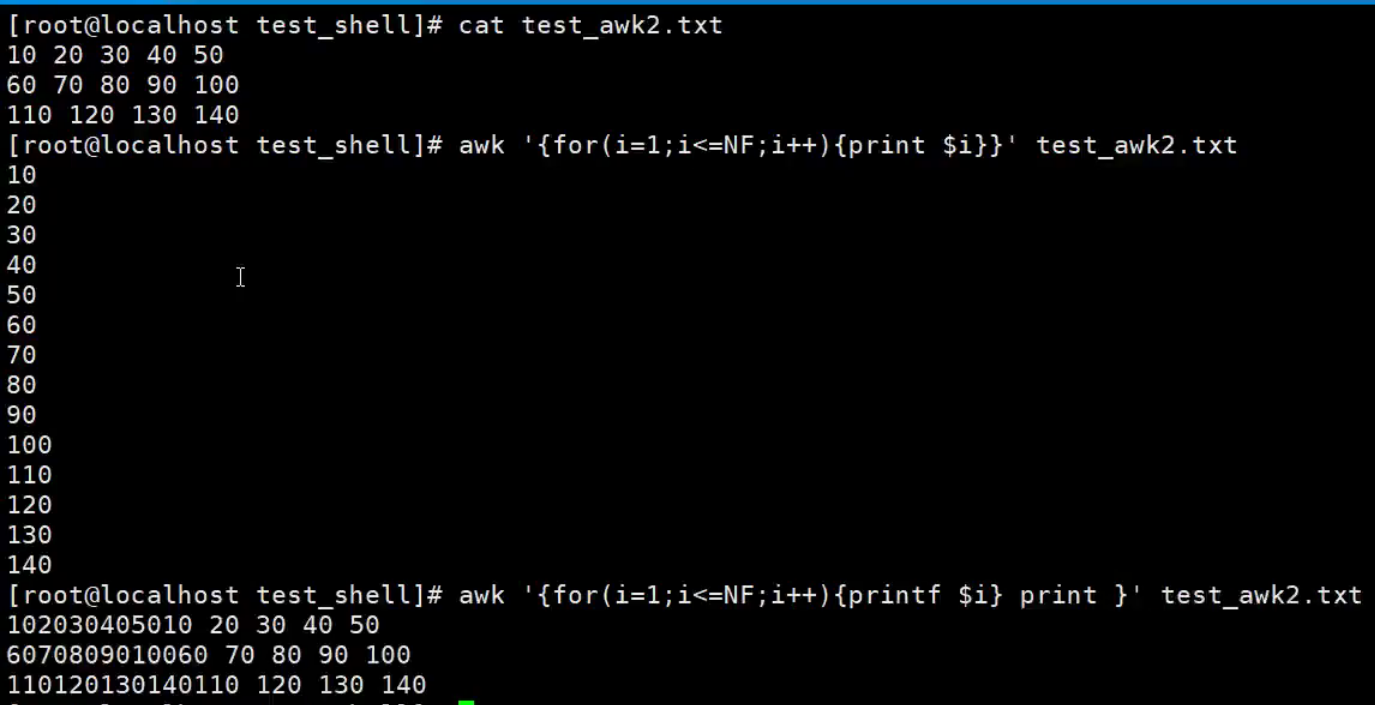
awk中循环语句的使用
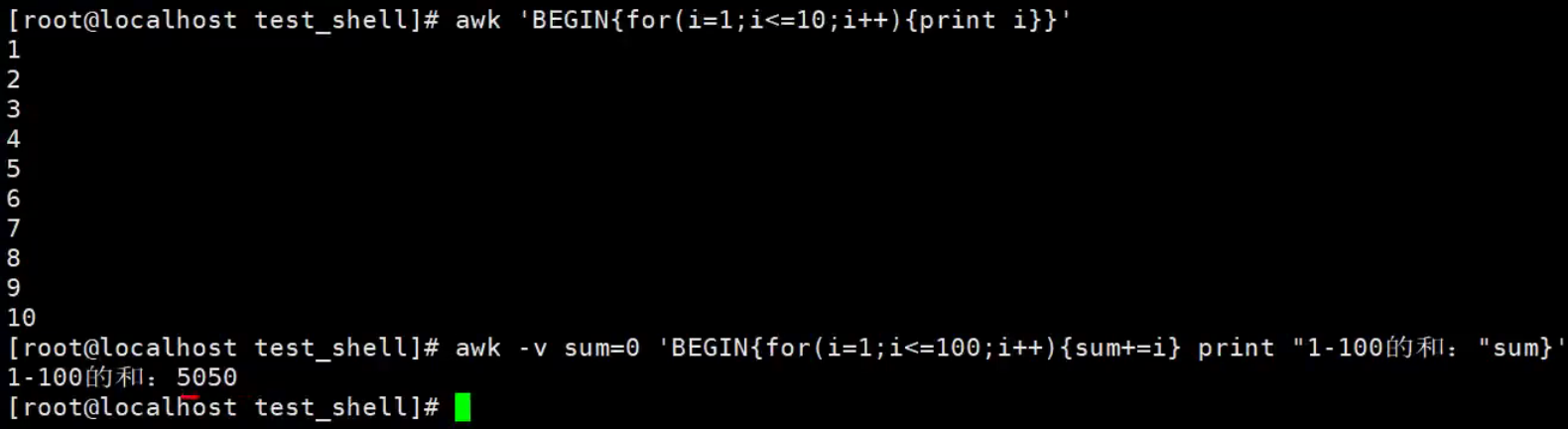
【示例】使用循环拼接字符串

【示例】使用循环计算每行的和

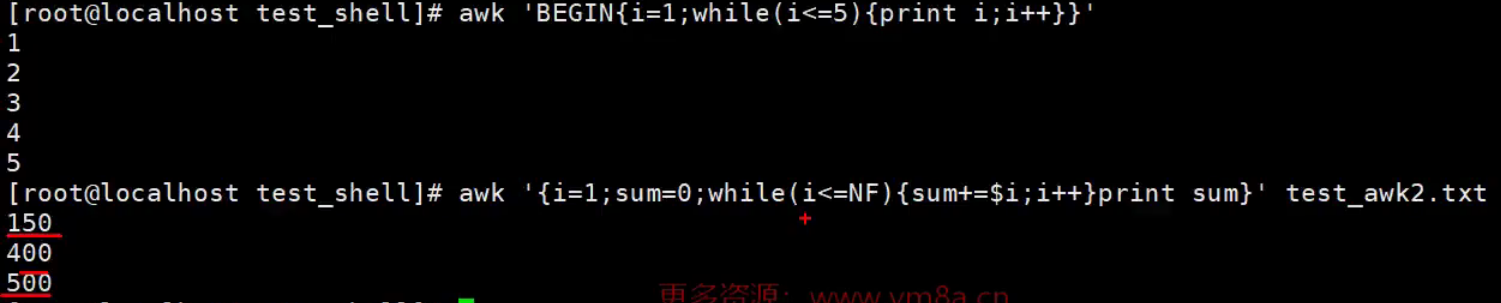
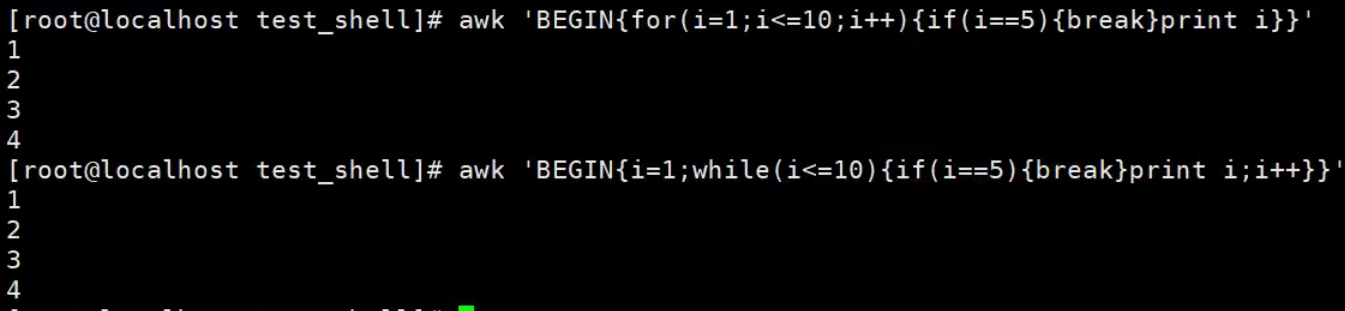
【示例】循环中使用break
【示例】操指定数字运算



【示例】切割ip

【示例】显示空行行号
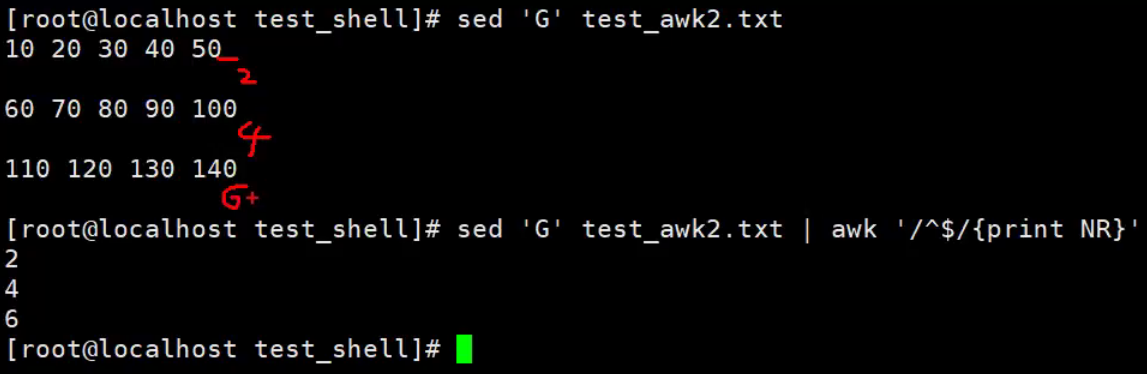
sort
sort命令以行为单位对文本进行排序。sort将文件的每一行作为一个单位,相互比较,比较原则是从首字符向后,依次按ASCII码值进行比较,最后将他们按升序输出。
【示例】sort的使用
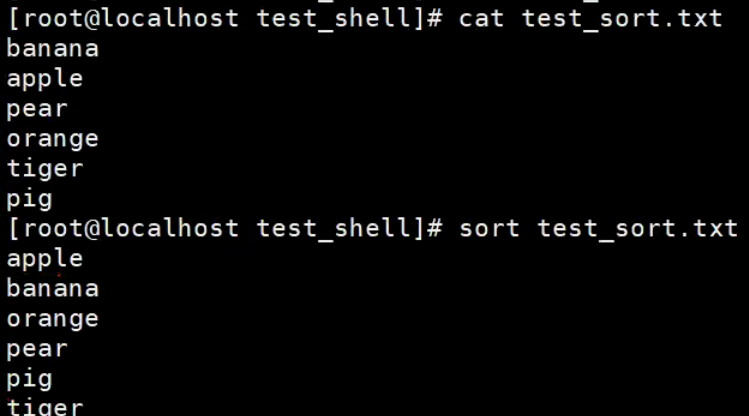
【示例】sort的-u选项
在输出行中去除重复行。
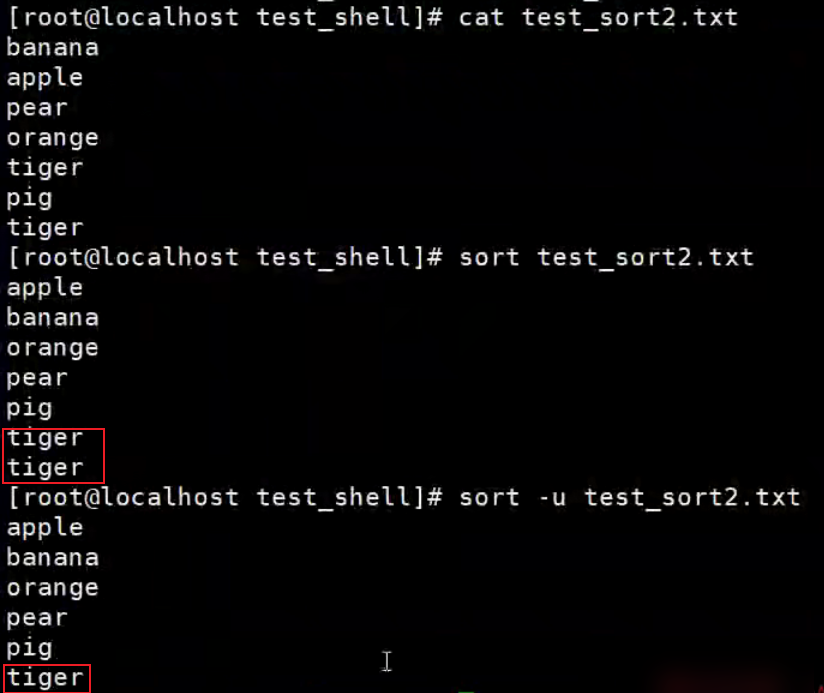
【示例】sort的-r选项
sort默认的排序方式是升序,如果想改成降序,就加个-r就搞定了。
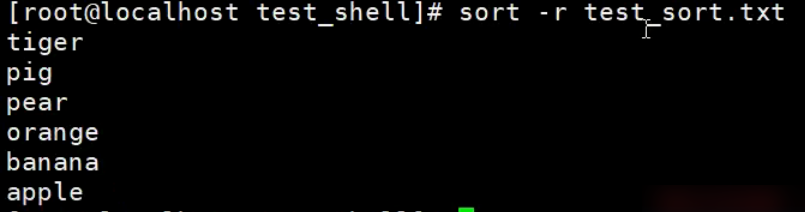
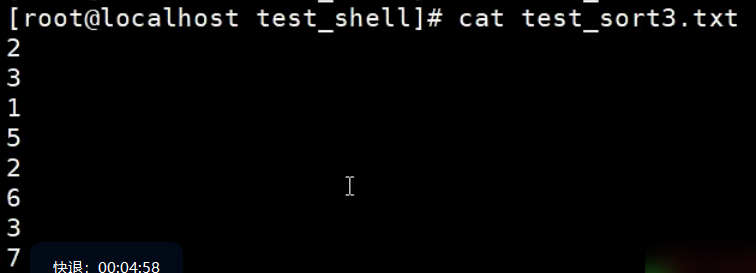
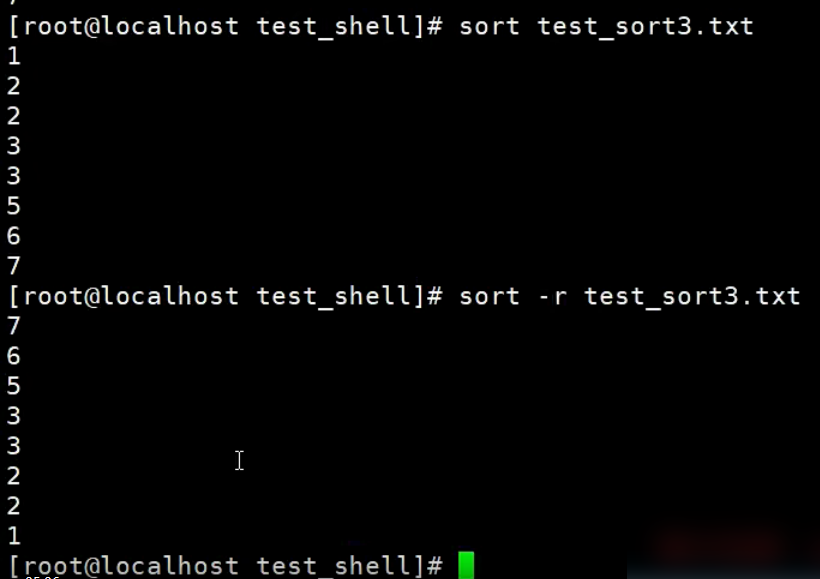
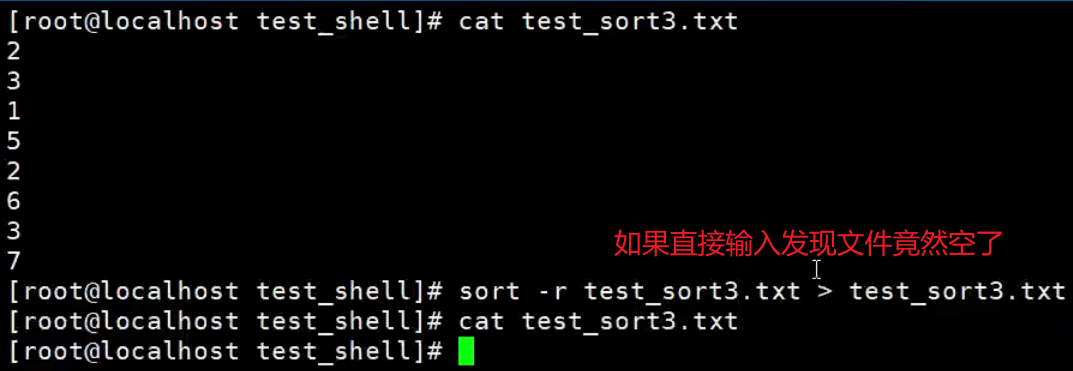
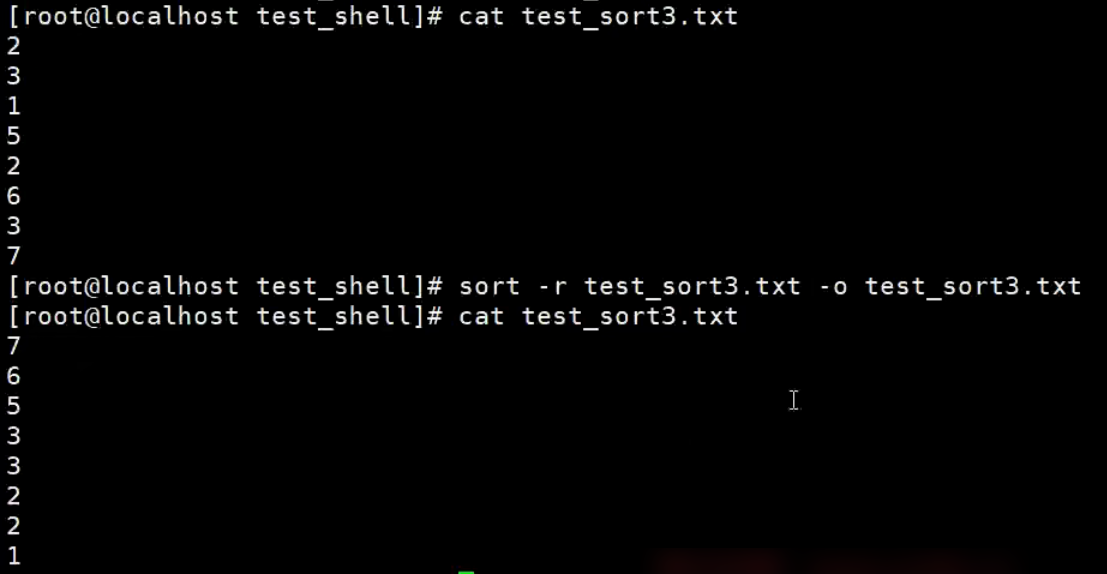
【示例】sort的-o选项
由于sort默认是把结果输出到标准输出,所以需要用重定向才能将结果写入文件,形如 sort filename > newfile,
但是,如果你想把排序结果输出到原文件中,用重定向可就不行了。
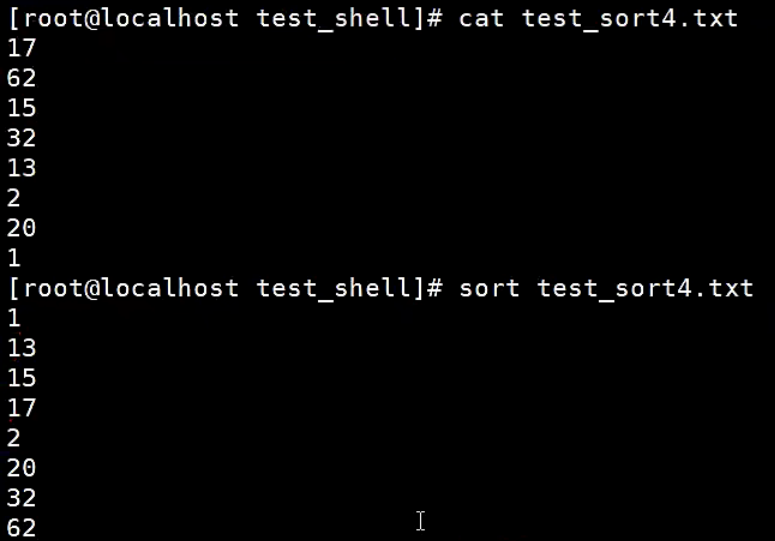
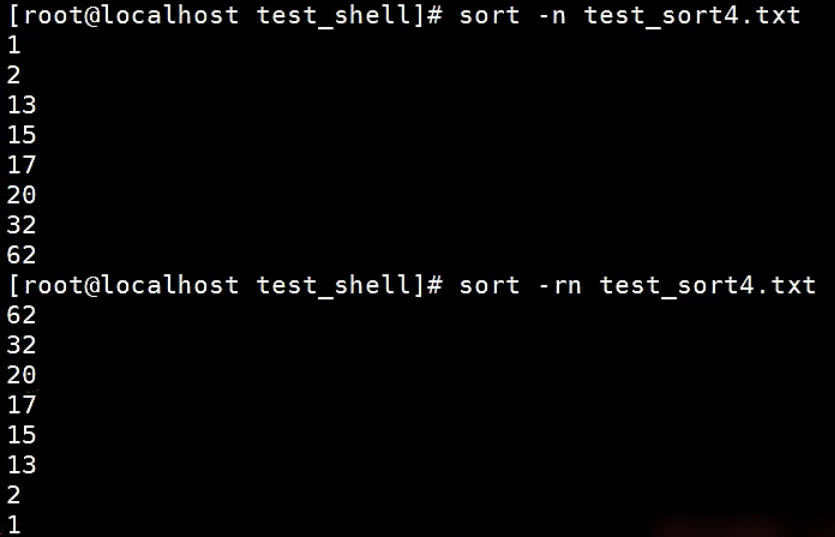
【示例】sort的-n选项
对数字排序,会出现一种现象,如10比2小的情况。出现这种情况是由于排序程序将这些数字按字符来排序了,排序程序会先比较1和2,显然1小,所以就将10放在2前面。这也是sort的一贯作风。
如果想改变这种现状,就要使用-n选项,“要以数值来排序”!
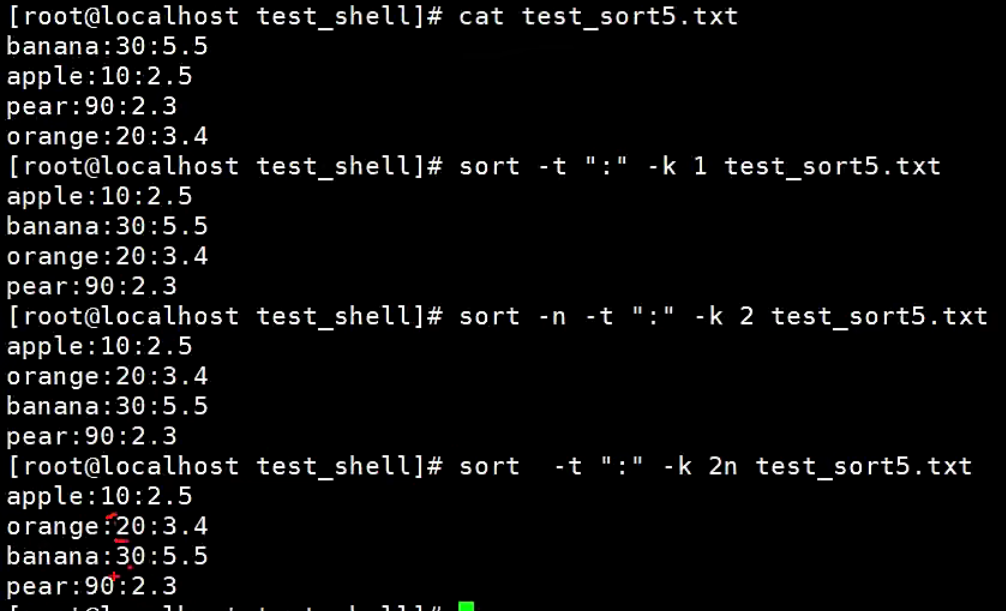
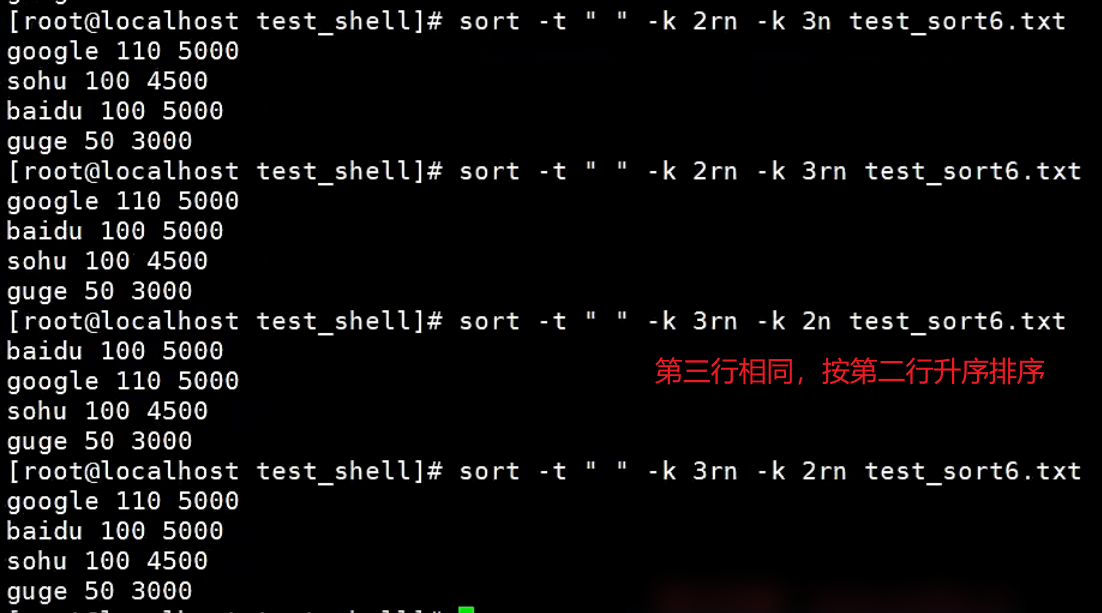
【示例】sort的-t选项和-k选项
-t选项,后面可以设定间隔符。
-k选项,分割后用来指定列数了。

这个文件有三列,列与列之间用冒号隔开了,第一列表示水果类型,第二列表示水果数量,第三列表示水果价格。
现在想以水果数量来排序,也就是以第二列来排序,如何利用sort实现?

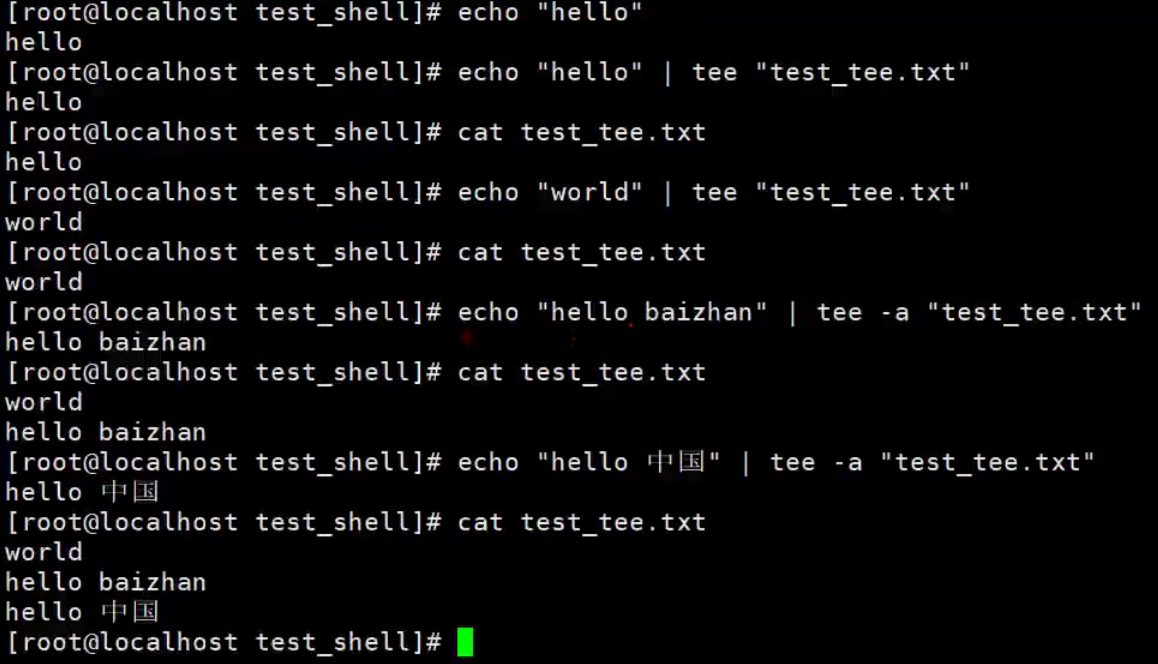
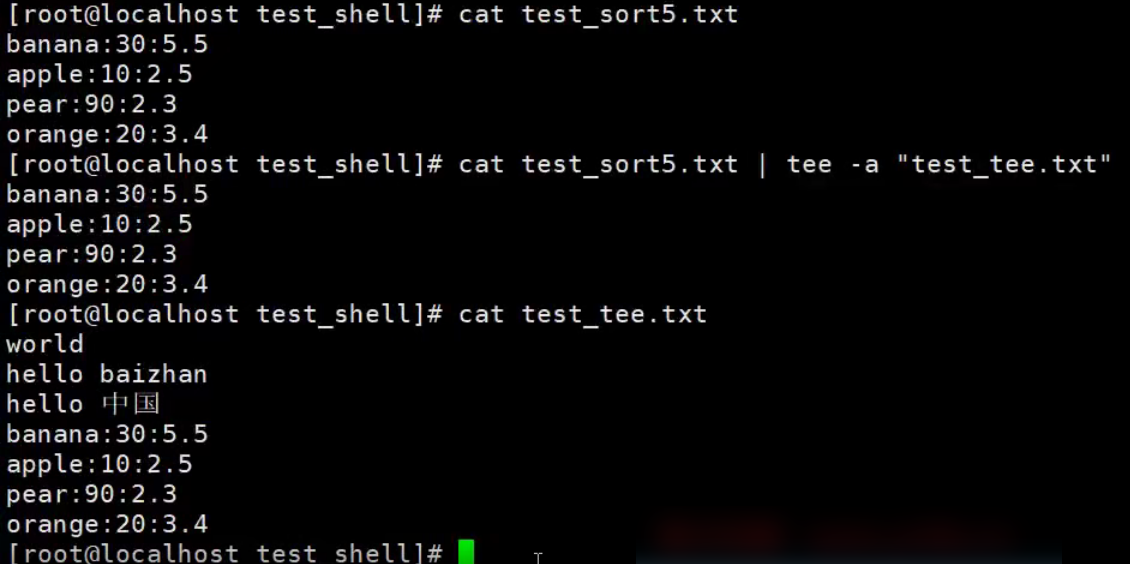
tee
tee命令作用把输出的一个副本输送到标准输出,另一个副本拷贝到相应的文件中。如果希望在看到输出的同时,也将其存入一个文件,那么这个命令再合适不过了。
它的使用语法格式:
tee [-a] files
其中,-a表示追加到文件末尾。
当执行某些命令或脚本时,如果希望把输出保存下来,tee命令非常方便。
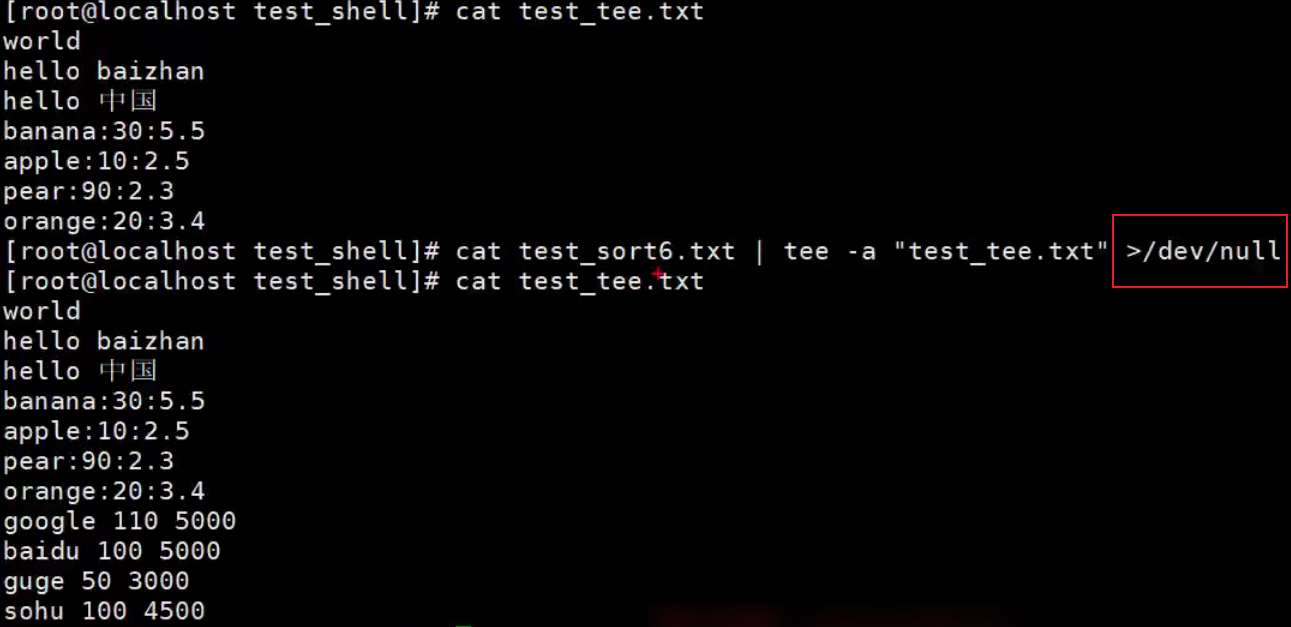
>/dev/null:不显示在屏幕上
案例
批量修改文件
将某目录下.txt文件全部修改为.bat。
1.批量创建文件
mkdir test_filedir
touch test_filedir/file{1...10).txt
2.重命名文件语法
rename 旧文件名 新文件名 旧文件所在位置
注意:旧文件所在位置后面加/* 例如:/root/test filedir/*s
#!/bin/bash
# 批量修改文件
# 获取所有要修收的文件
filenames=$(ls /root/test_shell/test_filedir | grep 'txt')
for fname in $filenames
do
echo"文件名:"$fname
newname=$(basename $fname .txt)".bat"
echo "新文件名:"$newname
rename $fname $newname /root/test_shell/test_filedir/*
done
批量创建用户
添加用户的命令
useradd 用户名
给用户设置默认密码
echo "123456" | passwd-stdin 用户名
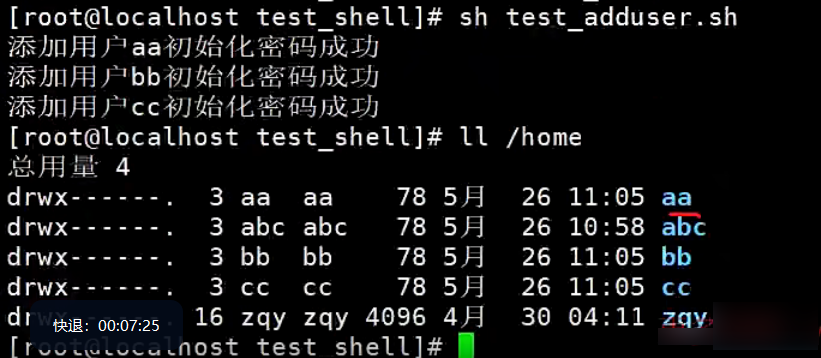
【示例】批量添加用户
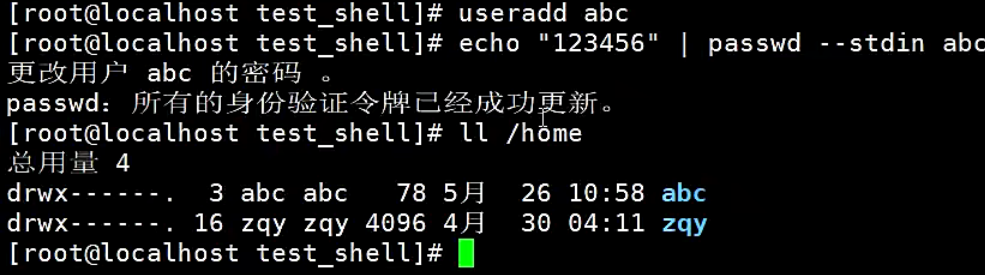
#!/bin/bash
# 批量创建用户
# 获取文件中要添加的所有用户名
users=$(cat /root/test_shell/test_adduser.txt)
for u in $users
do
# echo $u
# 添加用户
useradd $u
#初始化密码
echo "123456" | passwd --stdin $u &>/dev/null
[ $? -eq 0 ] && echo "添加用户"$u"初始化密吗成功”
done
计算linux系统所有进程占用内存大小的和
1.查看进程内存大小
ps-aux
2.可以看到有多列,RSS这列表示所占内存大小。提取RSS这列并去掉RSS这行
ps -aux | awk '{print $6}' | grep -v 'RSS'
3.统计进程大小之和
#!/bin/bash
# 统计linux系统中所有进程所占内存大小之和
ps_aux=$(ps -aux | awk '{print $6}' | grep -v 'RSS')
sum=0
for n in $ps_aux
do
sum=$[ $sum + $n ]
done
sum=$[ $sum / 1024 ]
echo "所占内存:$sum""M"
【示例】统计系统中各种类型的shell并按降序排序显示
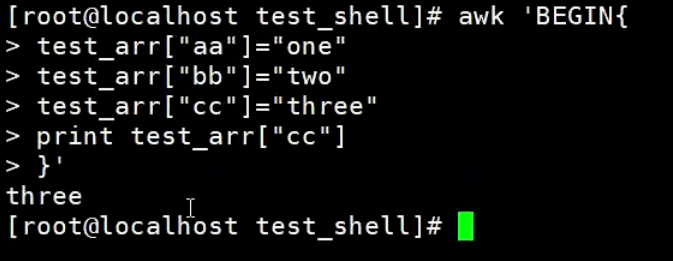
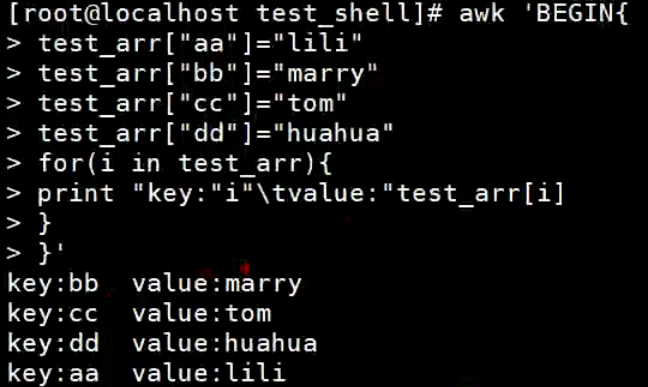
在awk中数组叫做关联数组(associative arrays)。awk中的数组不必提前声明,也不必声明大小。数组元素用0或空字符串来初始化,这根据上下文而定。
1.awk中的数组赋值并获取
2.统计系统中各种类型的shell并按降序排序显示




















 450
450



 到【灌水乐园】发言
到【灌水乐园】发言









