






通过url下载网络文件至本地
所需依赖和工具类代码
所需依赖
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.5</version>
</dependency> <dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.12.0</version>
</dependency>
工具类代码
package com.example.util;
import org.apache.commons.lang3.StringUtils;
import org.apache.http.*;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.HttpClients;
import java.io.File;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.util.HashMap;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 下载网络文件至本地
*
* @Author: haoyalei
* @CreateTime: 2021-06-04 10:10
* @Description: HttpDownload
*/
public class HttpDownloadUtil {
public static final int cache = 10 * 1024;
public static void main(String[] args) {
String url = "http://localhost:8080/file/1657781484678.mp3";
String targetUrl = "../newDir/";
HttpDownloadUtil.download(url,targetUrl);
}
/**
* 根据url下载文件,保存到filepath中
*
* @param url 文件的url
* @param diskUrl 本地存储路径
* @return
*/
public static String download(String url, String diskUrl) {
String filepath = "";
String filename = "";
try {
HttpClient client = HttpClients.createDefault();
HttpGet httpget = new HttpGet(url);
// 加入Referer,防止防盗链
httpget.setHeader("Referer", url);
HttpResponse response = client.execute(httpget);
HttpEntity entity = response.getEntity();
InputStream is = entity.getContent();
if (StringUtils.isBlank(filepath)){
Map<String,String> map = getFilePath(response,url,diskUrl);
filepath = map.get("filepath");
filename = map.get("filename");
}
File file = new File(filepath);
file.getParentFile().mkdirs();
FileOutputStream fileout = new FileOutputStream(file);
byte[] buffer = new byte[cache];
int ch = 0;
while ((ch = is.read(buffer)) != -1) {
fileout.write(buffer, 0, ch);
}
is.close();
fileout.flush();
fileout.close();
} catch (Exception e) {
e.printStackTrace();
}
return filename;
}
/**
* 根据contentType 获取对应的后缀 (列出常用的ContentType对应的后缀)
*
* @param contentType
* @return
*/
static String getContentType(String contentType){
HashMap<String, String> map = new HashMap<String, String>() {
{
put("application/msword", ".doc");
put("image/jpeg", ".jpeg");
put("application/x-jpg", ".jpg");
put("video/mpeg4", ".mp4");
put("application/pdf", ".pdf");
put("application/x-png", ".png");
put("application/x-ppt", ".ppt");
put("application/postscript", ".ps");
put("application/vnd.android.package-archive", ".apk");
put("video/avi", ".avi");
put("text/html", ".htm");
put("image/png", ".png");
put("application/x-png", ".png");
put("audio/mpeg", ".mp3");
put("image/gif", ".gif");
}
};
return map.get(contentType);
}
/**
* 获取response要下载的文件的默认路径
*
* @param response
* @return
*/
public static Map<String,String> getFilePath(HttpResponse response, String url, String diskUrl) {
Map<String,String> map = new HashMap<>();
String filepath = diskUrl;
String filename = getFileName(response, url);
String contentType = response.getEntity().getContentType().getValue();
if(StringUtils.isNotEmpty(contentType)){
// 获取后缀
String suffix = getContentType(contentType);
String regEx = ".+(.+)$";
Pattern p = Pattern.compile(regEx);
Matcher m = p.matcher(filename);
if (!m.find()) {
// 如果正则匹配后没有后缀,则需要通过response中的ContentType的值进行匹配
if(StringUtils.isNoneBlank(suffix)){
filename = filename + suffix;
}
}else{
if(filename.length()>20){
filename = getRandomFileName() + suffix;
}
}
}
if (filename != null) {
filepath += filename;
} else {
filepath += getRandomFileName();
}
map.put("filename", filename);
map.put("filepath", filepath);
return map;
}
/**
* 获取response header中Content-Disposition中的filename值
* @param response
* @param url
* @return
*/
public static String getFileName(HttpResponse response,String url) {
Header contentHeader = response.getFirstHeader("Content-Disposition");
String filename = null;
if (contentHeader != null) {
// 如果contentHeader存在
HeaderElement[] values = contentHeader.getElements();
if (values.length == 1) {
NameValuePair param = values[0].getParameterByName("filename");
if (param != null) {
try {
filename = param.getValue();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}else{
// 正则匹配后缀
filename = getSuffix(url);
}
return filename;
}
/**
* 获取随机文件名
*
* @return
*/
public static String getRandomFileName() {
return String.valueOf(System.currentTimeMillis());
}
/**
* 获取文件名后缀
* @param url
* @return
*/
public static String getSuffix(String url) {
// 正则表达式“.+/(.+)$”的含义就是:被匹配的字符串以任意字符序列开始,后边紧跟着字符“/”,
// 最后以任意字符序列结尾,“()”代表分组操作,这里就是把文件名做为分组,匹配完毕我们就可以通过Matcher
// 类的group方法取到我们所定义的分组了。需要注意的这里的分组的索引值是从1开始的,所以取第一个分组的方法是m.group(1)而不是m.group(0)。
String regEx = ".+/(.+)$";
Pattern p = Pattern.compile(regEx);
Matcher m = p.matcher(url);
if (!m.find()) {
// 格式错误,则随机生成个文件名
return String.valueOf(System.currentTimeMillis());
}
return m.group(1);
}
}
运行main方法结果:
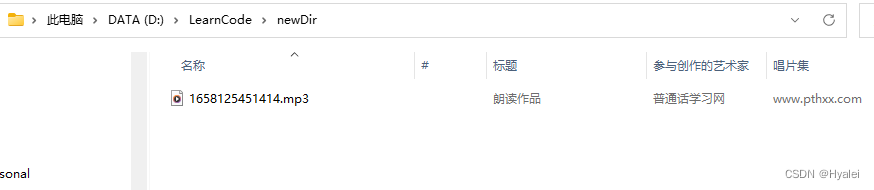
屏蔽org.apache.http的日志
另外有一个小问题,在运行main方法的时候,控制台会打印很多org.apache.http的日志
实际上,这写日志并没有什么作用,我们可以在main方法中添加以下代码来屏蔽这些日志信息
import org.slf4j.LoggerFactory;
import ch.qos.logback.classic.Level;
import ch.qos.logback.classic.Logger;
public static void main(String[] args) {
Logger logger = (Logger) LoggerFactory.getLogger("org.apache.http");
logger.setLevel(Level.INFO);
logger.setAdditive(false);
String url = "http://10.220.10.19:9180/file/c26055d232d5426ba75dca34c9b56230.mp3";
String targetUrl = "../newDir/";
HttpDownloadUtil.download(url,targetUrl);
}
如此一来控制台就会清爽很多,也容易debug
手动添加Content-Type
比如有些Content-Type并没有在此工具类的getContentType(String contentType)方法中收录,这可能会导致有些文件下载下来没有文件后缀,如下图:
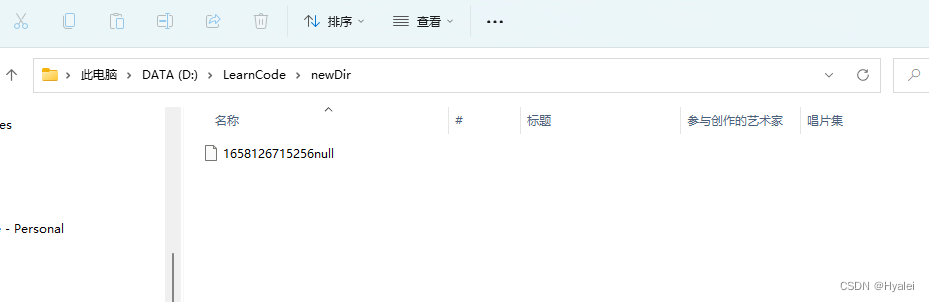
这时候就需要我们手动添加网络文件的后缀:
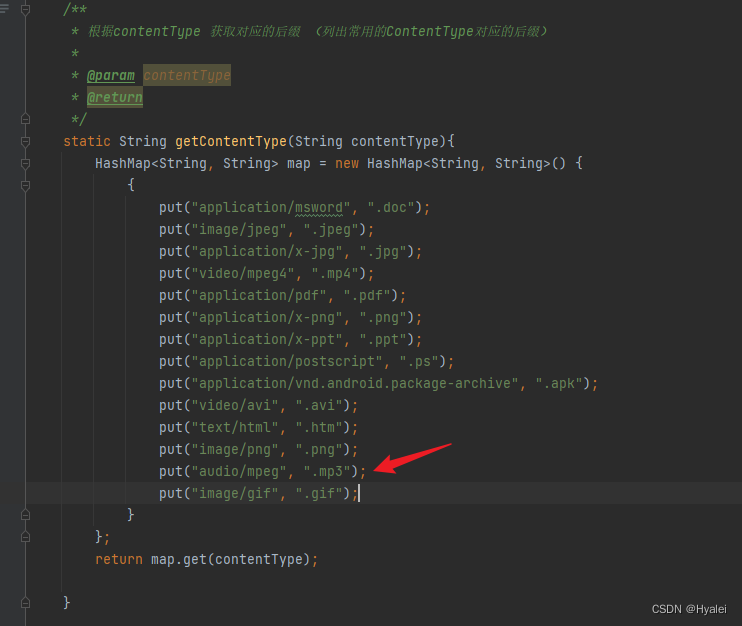
我们需要在getFilePath(HttpResponse response, String url, String diskUrl)方法中先打印此文件的Content-Type,然后在getContentType(String contentType)方法的map中添加对应的键值对
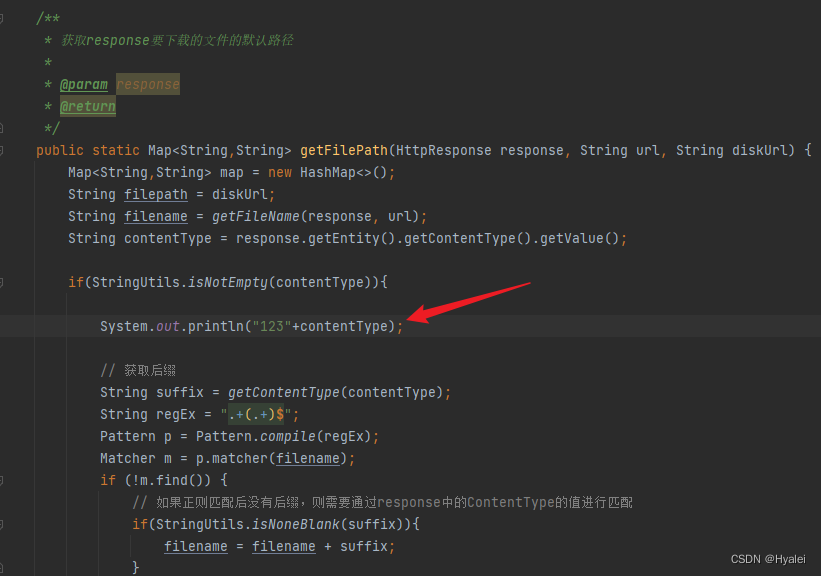
但是由于之前的日志打印太多了,运行结果中根本找不到打印在控制台的Content-Type信息
 这时候关闭这些无效的日志就显得很重要了,让我们在main方法中添加设置日志等级的代码之后,再次运行main方法查看结果:
这时候关闭这些无效的日志就显得很重要了,让我们在main方法中添加设置日志等级的代码之后,再次运行main方法查看结果:
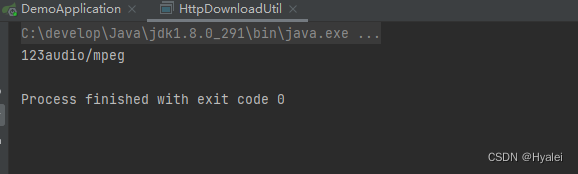
这时候我们便知道mp3对应的Content-Type是audio/mpeg,随后便在getContentType(String contentType)添加键值对即可
再次运行main方法,查看文件是否有后缀:
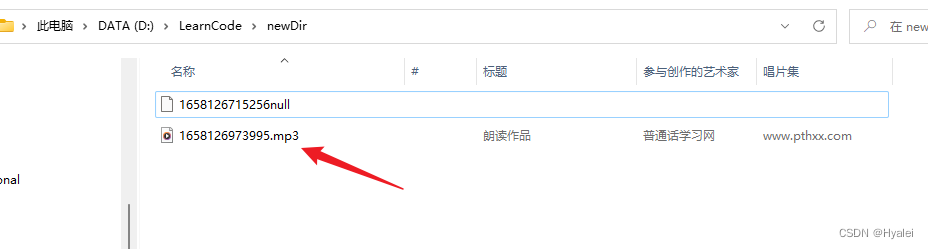
成功!
————————————————
版权声明:本文为CSDN博主「Hyalei」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_45379185/article/details/125844724















 2842
2842











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









