







本文详细介绍了hadoop的集群搭建
文章目录
环境
-
3台linux虚拟机,他们的ip对应关系为:
- 192.168.31.201 mym
- 192.168.31.202 mini2
- 192.168.31.203 mini3
-
hadoop版本:hadoop-2.4.1
-
jdk7 (本文前提是安装了jdk7并配好环境变量)
-
centos7
-
三台主机间可以互相网络通信
-
ip固定(否则不能映射正确的主机,导致不能通信)
修改主机名
便于使用主机名代替ip,每台都改成对应的主机名。如下mym机器主机名修改
vi /etc/sysconfig/network
# Created by anaconda
NETWORKING=yes
HOSTNAME=mym
修改主机名和IP的映射关系
便于使用主机名代替ip,通过主机找到对应ip。如mym机器的映射关系
vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.31.201 mym
192.168.31.202 mini2
192.168.31.203 mini3
关闭防火墙
开发环境为了方便。生产环境就应该详细端口开放
#查看防火墙状态
service iptables status
#关闭防火墙
service iptables stop
#查看防火墙开机启动状态
chkconfig iptables --list
#关闭防火墙开机启动
chkconfig iptables off
三台机器创建同名用户
这里也可以直接使用root用户,不过一般不建议。这里得创建同名用户,因为之前笔者使用不同用户就出现了点问题。本文使用用户名为mym。
su root 换root
useradd mym 新建用户
passwd mym 设置密码
输入两次密码即可,不用理会密码简不简单的警告
给用户赋予执行权限
若用户不是root用户,则需要执行权限,否则很多文件都没有执行权限
例如当前用户是mym用户,那么给mym用户执行权限的方式:
su root
vi /etc/sudoers
在root的下方模仿添加一行即可
## Next comes the main part: which users can run what software on
## which machines (the sudoers file can be shared between multiple
## systems).
## Syntax:
##
## user MACHINE=COMMANDS
##
## The COMMANDS section may have other options added to it.
##
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
mym ALL=(ALL) ALL
最后接下来的操作就可以切换到mym用户下操作了
安装hadoop
把文件上传到/home/mym/工作空间下操作
解压即可,然后添加到环境变量中
vi /etc/profile
######################hadoop etc###########
export HADOOP_HOME=/home/mym/apps/hadoop-2.4.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
让环境变量修改生效
source /etc/profile
配置hadoop
伪分布式需要修改5个配置文件
所有配置文件如下
[root@mym hadoop]# pwd
/home/mym/apps/hadoop-2.4.1/etc/hadoop
[root@mym hadoop]# ll
total 128
-rw-r--r--. 1 mym mym 3589 Jun 21 2014 capacity-scheduler.xml
-rw-r--r--. 1 mym mym 1335 Jun 21 2014 configuration.xsl
-rw-r--r--. 1 mym mym 318 Jun 21 2014 container-executor.cfg
-rw-r--r--. 1 mym mym 976 Jan 31 12:58 core-site.xml
-rw-r--r--. 1 mym mym 3589 Jun 21 2014 hadoop-env.cmd
-rw-r--r--. 1 mym mym 3504 Jan 28 08:32 hadoop-env.sh
-rw-r--r--. 1 mym mym 1774 Jun 21 2014 hadoop-metrics2.properties
-rw-r--r--. 1 mym mym 2490 Jun 21 2014 hadoop-metrics.properties
-rw-r--r--. 1 mym mym 9257 Jun 21 2014 hadoop-policy.xml
-rw-r--r--. 1 mym mym 967 Jan 31 12:59 hdfs-site.xml
-rw-r--r--. 1 mym mym 1449 Jun 21 2014 httpfs-env.sh
-rw-r--r--. 1 mym mym 1657 Jun 21 2014 httpfs-log4j.properties
-rw-r--r--. 1 mym mym 21 Jun 21 2014 httpfs-signature.secret
-rw-r--r--. 1 mym mym 620 Jun 21 2014 httpfs-site.xml
-rw-r--r--. 1 mym mym 11169 Jun 21 2014 log4j.properties
-rw-r--r--. 1 mym mym 918 Jun 21 2014 mapred-env.cmd
-rw-r--r--. 1 mym mym 1383 Jun 21 2014 mapred-env.sh
-rw-r--r--. 1 mym mym 4113 Jun 21 2014 mapred-queues.xml.template
-rw-r--r--. 1 mym mym 850 Jan 28 08:35 mapred-site.xml
-rw-r--r--. 1 mym mym 850 Jan 28 08:35 mapred-site.xml.template
-rw-r--r--. 1 mym mym 10 Feb 4 06:42 slaves
-rw-r--r--. 1 mym mym 2316 Jun 21 2014 ssl-client.xml.example
-rw-r--r--. 1 mym mym 2268 Jun 21 2014 ssl-server.xml.example
-rw-r--r--. 1 mym mym 2178 Jun 21 2014 yarn-env.cmd
-rw-r--r--. 1 mym mym 4564 Jun 21 2014 yarn-env.sh
-rw-r--r--. 1 mym mym 899 Jan 28 08:36 yarn-site.xml
注:可能有些配置文件只有模板文件(mapred-site.xml.template),我们需要赋值一份作为配置使用
配置hadoop运行环境:hadoop-env.sh
这里修改JAVA_HOME路径
vi hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.7.0_65
配置公共配置信息:core-site.xml
vi core-site.xml
<configuration>
<!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mym:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/mym/apps/hadoop-2.4.1/hdData</value>
</property>
</configuration>
注:/home/mym/apps/hadoop-2.4.1/hdData得手动创建
配置hdfs信息(非必需,可用默认值):hdfs-site.xml
vi hdfs-site.xml
<configuration>
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 指定secondaryNamenode的地址 -->
<property>
<name>dfs.secondary.http.address</name>
<value>192.168.31.201:50090</value>
</property>
</configuration>
配置计算平台resourceManager的信息:yarn-site.xml
vi yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 指定YARN的(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>mym</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
配置计算程序mapreduce运行平台:mapred-site.xml
vi mapred-site.xml
<configuration>
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
分发已配置好的到其他机器上
可以配置免密登陆,然后写一个交互式的分发脚本。
注意,这里要分发到对应用户目录下去
scp -r hadoop-2.4.1/ mym@mini2:/home/mym/apps/
scp -r hadoop-2.4.1/ mym@mini3:/home/mym/apps/
建立数据目录
三台机器上,配置hdfs-site.xml文件中的hadoop运行文件目录不存在时,需要手动创建
mkdir -p /home/mym/apps/hadoop-2.4.1/hdData
格式化namenode(对namenode初始化)
在hadoop目录下
bin/hdfs namenode -format
或者
bin/hadoop namenode -format
执行后看到日志中,namenode文件生成成功就说明成功格式化
...
18/06/20 16:44:13 INFO common.Storage: Storage directory /home/mym/apps/hadoop-2.4.1/hdData/dfs/name has been successfully formatted.
18/06/20 16:44:13 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
18/06/20 16:44:13 INFO util.ExitUtil: Exiting with status 0
18/06/20 16:44:13 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at mym/192.168.31.201
************************************************************/
启动/关闭hadoop
- 启动hadoop
启动namenode、datanode
sbin/hadoop-daemon.sh start namenode
sbin/hadoop-daemon.sh start datanode
启动一台后(当前启动mym机器的namenode和datanode,注hadoop集群中namenode一台就可以,并且已经在配置文件中指定了的),
可通过jps查看
[mym@mym hadoop-2.4.1]$ jps
18741 NameNode
18907 Jps
18839 DataNode
也可以通过namenode的管理后台查看服务
http://192.168.31.201:50070
如图(已经启动了两台datanode节点:mym和mini2)
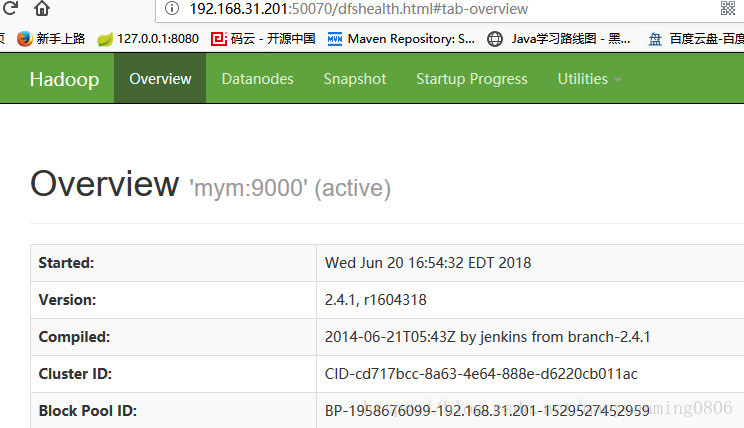
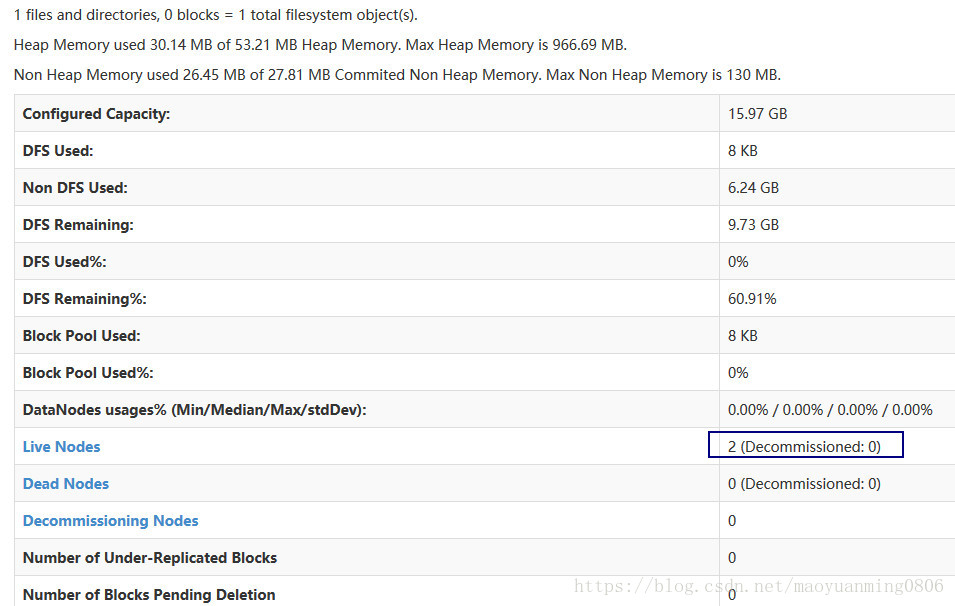
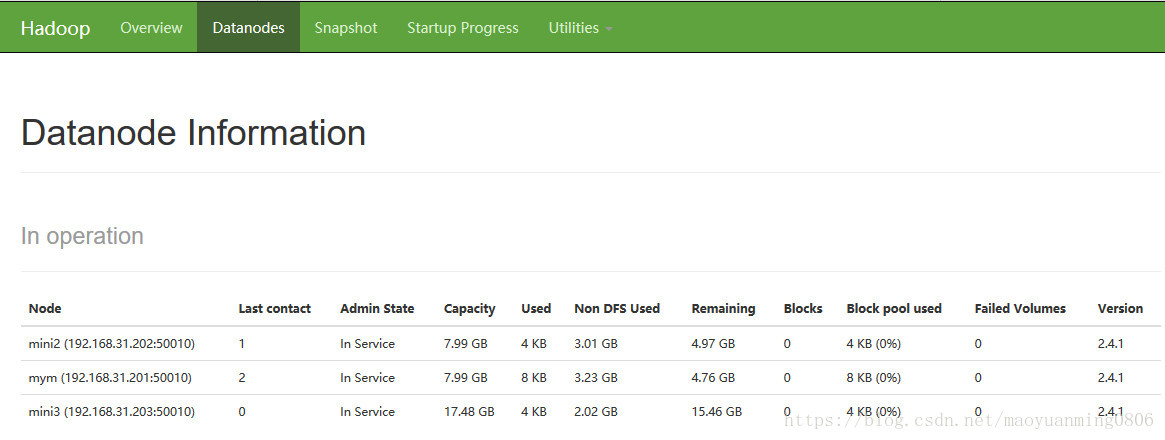
若再启动mini3机器,一会儿就可以查询得到
- 关闭hadoop
sbin/hadoop-daemon.sh stop namenode
sbin/hadoop-daemon.sh stop datanode
配置机器间免密登陆 一步启动集群
之前启动都是到各个机器上执行启动命令,那么集群机器一多就不方便且繁琐,此时可以在所有机器间配置免密登陆然后通过一个命令即可启动所有机器
配置免密登陆
-
进入到我的home目录
cd ~/.ssh -
执行
ssh-keygen -t rsa(四个回车) -
执行完这个命令后,会生成两个文件
id_rsa(私钥)、id_rsa.pub(公钥) -
将公钥拷贝到要免密登陆的目标机器上
ssh-copy-id localhost
如拷贝到mini2机器上ssh-copy-id mini2
配置免密登录无效问题解决
按如上步骤处理完可能仍然无法进行免密登录,可能原因:
~/.ssh文件夹和authorized_keys文件的权限不对
解决:先删除生成的rsa…*文件(公钥和私钥),再进行修改权限命令如下,然后再重新配置免密步骤和原来一样
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
配置开启集群所有机器
在namenode节点的机器上的配置文件目录下有个slave文件(没有可以创建),把所有节点的主机名或者ip配置到里面即可,前提是配置了免密登陆
[mym@mym hadoop]$ pwd
/home/mym/apps/hadoop-2.4.1/etc/hadoop
[mym@mym hadoop]$ vi slaves
添加如下内容
mym
mini2
mini3
保存后可通过命令直接
启动/停止所有机器的hdfs服务
sbin/start-dfs.sh
sbin/stop-dfs.sh
启动YARN
sbin/start-yarn.sh
sbin/stop-yarn.sh
查看启动hdfs和yarn
根据上小节内容成功启动hdfs和yarn后,可通过jps命令查看机器上的服务启动情况
- mym机器
[mym@mym hadoop-2.4.1]$ jps
20801 DataNode
21214 ResourceManager
21312 NodeManager
21476 Jps
21054 SecondaryNameNode
20676 NameNode
- mini2机器
[mym@mini2 hadoop-2.4.1]$ jps
5590 NodeManager
5689 Jps
5488 DataNode
- mini3机器
[mym@mini3 hadoop-2.4.1]$ jps
4722 Jps
4620 NodeManager
4517 DataNode
同时可通过后台管理查看节点情况
QA
- Q:namenode不能发现其它节点的datanode
A:几种可能的情况(前提是其他节点的datanode成功启动)
(1)配置文件hdfs-site和core有误
(2)没有关闭防火墙-网络不通
(3)集群间hadoop运行在不同的用户上,本文演示的都是运行在三台机器的mym用户上
-
Q:免密登陆无效
A:没有配置或配置失败host名和映射。本文前文已有说明方式 -
Q:运行的日志文件在哪?
A:启动namenode或datanode时有提示日志文件位置。一些错误也可以根据日志去排查
[mym@mini2 hadoop-2.4.1]$ sbin/hadoop-daemon.sh start datanode
starting datanode, logging to /home/mym/apps/hadoop-2.4.1/logs/hadoop-mym-datanode-mini2.out
以上就是部署hadoop集群的详细流程,若有疑问或错误的步骤,希望留言指出!
后续将继续hadoop的shell和java api操作以及mapreduce的操作














 2623
2623











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









