









前言:
MapReduce是一个高性能的批处理分布式计算框架,用于对海量数据进行并行分析和处理。与传统方法相比较,MapReduce更倾向于蛮力去解决问题,通过简单、粗暴、有效的方式去处理海量的数据。通过对数据的输入、拆分与组合(核心),将任务分配到多个节点服务器上,进行分布式计算,这样可以有效地提高数据管理的安全性,同时也能够很好地范围被管理的数据。
- mapreduce概念+实例
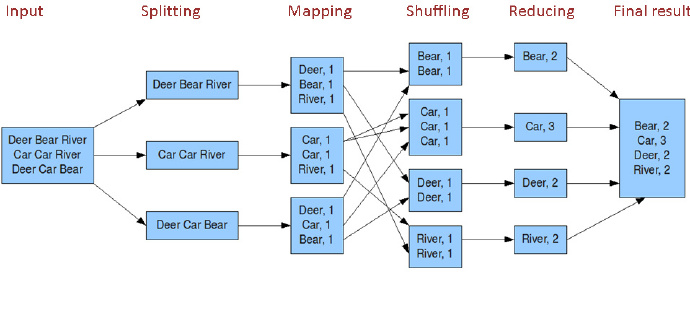
- mapreduce核心就是map+shuffle+reducer,首先通过读取文件,进行分片,通过map获取文件的key-value映射关系,用作reducer的输入,在作为reducer输入之前,要先对map的key进行一个shuffle,也就是排个序,然后将排完序的key-value作为reducer的输入进行reduce操作,当然一个mapreduce任务可以不要有reduce,只用一个map,接下来就来讲解一个mapreduce界的“hello world”。
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
这个是hadoop自带的一个demo,使用mapreduce来对文本单词数量进行一个统计,所以叫做wordcount,自带的wordcount demo使用的是新版本的api,由于mapreduce做过一次重大的升级,升级后通过yarn进行map,reduce资源的配置,所以我们也使用新的api进行讲解
1、新的api放在:org.apache.hadoop.mapreduce,旧版api放在:org.apache.hadoop.mapred下面,大家写程序的时候可以注意一下
- 从上面的程序可以看出,上面的TokenizerMapper以及IntSumReducer分别 继承了Mapper以及Reducer这两个类,并重写map()和reduce()方法
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException- key和value是数据读取到的key和value,默认每一行的字节偏移量为key,输入的读取格式可以自定义,一整行的数据为value,比如:
One needs three things to be
truly happy living in the world
some thing to do some one to love
some thing to hope for(0,One needs three things to be)
(29,truly happy living in the world)
(61,some thing to do some one to love)
(95,some thing to hope for)- contex则是用于记录key和value,用做上下文关联,比如map输出的值给reducer就是用过context进行关联的
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException - reduce的key和value对应的分别是map输出的key和value,两者的类型是一样的,但是value是以迭代器的形式展现的,也就是说一个key对应的是一组value的值,这其实也挺好想通的,map在生成key和value的时候,会存在相同的key,比如我们统计一片文章里面每个单词出现的次数,以单词为key,value为1生成键值对,由于单词会出现重复,所以reduce输入的value是一个一对多的迭代器
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}首先是新建了一个configuration对象,configuration对象主要是用来初始化使用,读取hadoop配置文件中的一些配置信息,配置文件有core-site.xml、hdfs-site.xml、mapred-site.xml等,只所以要读取这些配置文件,就是为了告诉这个框架,hdfs在哪里,yarn在哪里等等信息。
otherArgs则是对输入参数的解析,这里一般可以传入输入文件路径,输出文件路径(输出文件路径必须是空的,要不然会报错),而且这些路径都是hdfs上的路径,hdfs和mapreduce天生好基友,不过一般会使用一个自带的工具类来做这件事情,这里不详细讲解。
接下来就是创建一个job作业,运行一个mapreduce应用,就会提交一个job作业,map和reduce则是一个个task,在提交job之前,要先对job进行一个设置
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);- setJarByClass用于设置主要工作类
- setMapperClass用于设置Mapper类,就是map的实现类
- setReducerClass用于设置Reducer类,就是reduce的实现类
- setOutputKeyClass和setOutPutValueClass分别用于设置输出的key和value的类型
FileInputFormat.addInputPath
FileOutputFormat.setOutputPath- 这两个就是为了指定输入文件和输出文件的路径
job.waitForCompletion(true) - 最后一步就是为了提交job,并开始处理
- mapreduce进一步介绍
在上面的wordcount程序里面,可以看见IntWritable、Text、LongWritable等数据类型,这些数据类型都是实现了writable接口的,你也可以自定义,自定义数据也需要去实现writabel接口,之所以要实现这些接口,就是为了实现序列化,让这些数据能够在网络上传输。
前面我讲过,map去读取文件的时候,默认是通过每一行的字节偏移量作为key,对应的那一行为value作为映射的,它可以通过自定义进行设置,在讲自定义之前,我们先看一下系统自带的几种输入输入格式
| 输入格式 | 描述 | 键 | 值 |
| TextInputFormat | 默认格式,读取文件的行 | 行的字节偏移量 | 行的本身 |
| KeyValueInputFormat | 把行解析为键值对 | 第一个tab字符前的所有字符 | 行剩下的内容 |
| NLineInputFormat | 固定长度分割 | 行的偏移量,这里只是指定了N行 | 行本身 |
| SequenceFileInputFormat | Hadoop定义的高性能二进制格式 | 用户自定义 | 用户自定义 |
| DBInputFormat | DBInputForma是一个使用JDBC并且从关系数据库中读取数据的一种输入格式。由于它没有任何碎片技术,所以在访问数据库的时候必须非常小心,太多的mapper可能会事数据库受不了。因此DBInputFormat最好在加载小量数据集的时候用。 |
TextInputFormat就是我前面讲到的偏移量为key的一种输入格式,这对一些文本处理比较有用,和TextInputFormat相似的是KeyValueInputFormat,默认情况下,KeyValueInputFormat是将一行文本通过‘\t’制表符来进行分割,制表符之前的作为key,制表符之后的作为value。
自定义输入格式:
具体请看这篇博客:自定义输入
剩余部分待续。。。。。。。。。。。。














 2181
2181











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









