







论文地址:https://arxiv.org/pdf/2409.11402
背景
传统的多模态 LLM 有两种主要方法:纯解码器架构(如 LLaVA)和基于交叉注意力的架构(如 Flamingo)。混合架构,既提高了训练效率,又增强了多模态推理能力。
论文还介绍了一种名为 "1-D 瓦片标签设计 "的新技术,它能以瓦片格式处理高分辨率图像。这大大提高了 OCR(光学字符识别)相关任务和多模态推理能力。
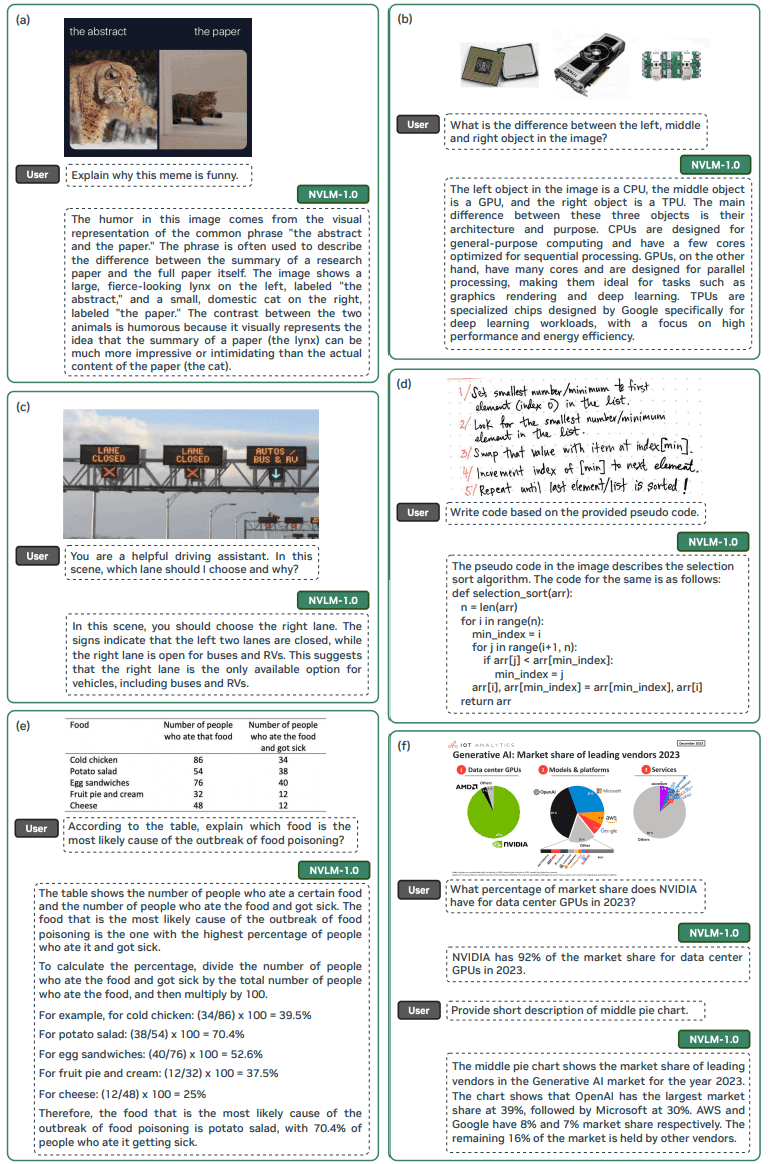
此外,还详细介绍了多模态预训练和监督微调数据集,表明数据质量和任务多样性比规模更重要。
技术
NVLM 1.0 的主要特点是它是一个具有三种不同架构的模型系列。它们分别是纯解码器 NVLM-D、基于交叉注意的 NVLM-X 和混合架构 NVLM-H,后者结合了两种架构的优点。这种组合可确保每个模型在不同类型的任务中发挥最佳性能。
NVLM-D 直接在纯解码器网络中处理视觉特征,提供统一的推理能力。另一方面,NVLM-X 利用交叉注意有效捕捉视觉信息,使其在处理高分辨率图像时更具优势。最后,NVLM-H 在解码器层处理缩略图信息,在交叉注意层处理其他平铺图像信息,从而在利用两者优势的同时提高了计算效率。
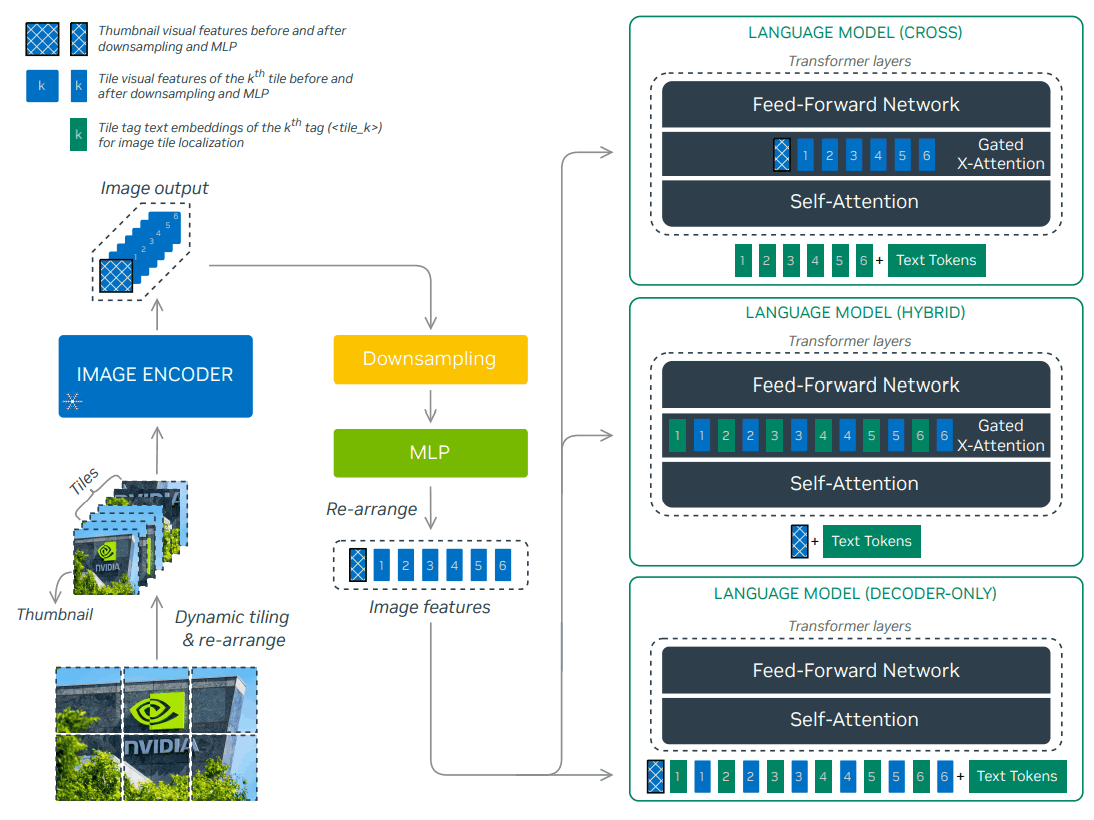
此外,NVLM 1.0 还引入了一种处理高分辨率图像的方法,称为 “1-D 瓦片标签设计”。这种方法将图像分为多个瓦片,并为每个瓦片贴上标签,以便模型识别,从而显著提高了 OCR 相关任务的准确性。

这些设计和数据方面的创新使 NVLM 1.0 不仅在视觉和语言任务中表现出很高的性能,而且在纯文本任务中的表现也优于以前的模型。
试验
本文的实验在多个基准上进行了测试,以评估 NVLM 1.0 模型的性能。实验主要集中在视觉与语言相结合的任务和纯文本任务上。分别使用了不同架构的模型(NVLM-D、NVLM-X 和 NVLM-H),以比较不同模型的能力。
首先,我们使用了几个基准来评估视觉和语言相结合的任务。具体来说,这些基准包括需要复杂推理的多模态推理(MMMU)、涉及数学推理的视觉情境问题(MathVista)、图像理解(VQAv2)和评估 OCR 能力的 OCRBench。这些测试验证了每个模型在不同类型任务中的表现。
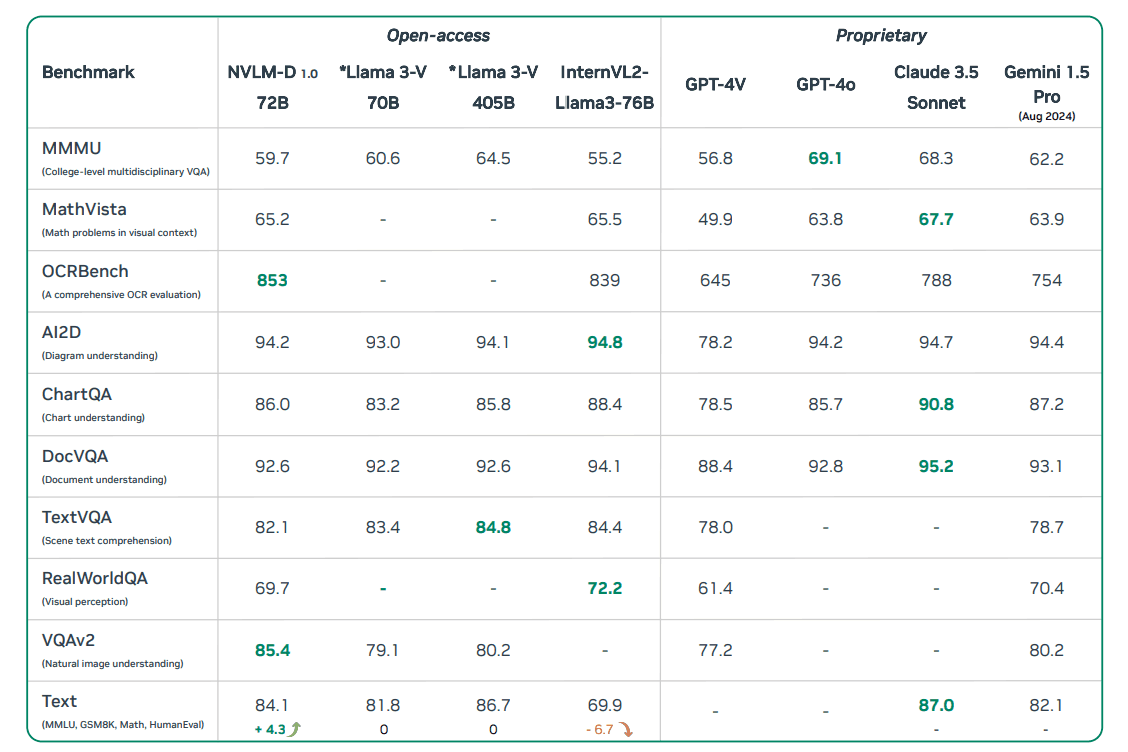
NVLM-D 模型的准确率很高,特别是在 OCR 任务和图像理解方面,比其他模型更具优势。另一方面,NVLM-X 模型利用交叉注意提高了处理高分辨率图像的效率,在推理速度和准确性方面都表现出了卓越的效果;NVLM-H 模型采用了解码器和交叉注意相结合的设计,其表现优于其他模型,尤其是在数学推理和复杂视觉问题方面。NVLM-H模型的特点是结合了解码器和交叉注意的设计,其表现优于其他模型,尤其是在数学推理和复杂视觉问题方面。
我们还在纯文本任务中对这些模型进行了评估,以研究多模态训练后它们的纯文本成绩是否会下降。结果显示,经过训练后,NVLM 模型在文本任务中的表现保持不变,甚至有所提高。
实验结果表明,NVLM 1.0 在视觉和语言任务上的表现都非常出色,尤其是在 OCR 任务和需要复杂推理的场景上。
总结
论文的结论指出,NVLM 1.0 在各种任务中都表现出很高的性能,为多模态大规模语言建模开辟了新的可能性。特别是在需要整合视觉和语言的任务上,NVLM 1.0 的性能达到或超过了其他最先进模型的性能。
总的来说,NVLM 1.0 所显示的结果为广泛的应用提供了灵活而强大的解决方案,特别是扩大了其对同时处理视觉和语言的高级任务的可用性。我们希望这项研究能为未来多模态模型的发展做出贡献,并希望已发布的模型权重和代码能促进进一步的研究和应用。
















 1017
1017

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











