






作者:Liping Mao 发表于:2014-08-20
版权声明:可以任意转载,转载时请务必以超链接形式标明文章原始出处和作者信息及本版权声明
最近Assaf Muller写了一篇关于Neutron L3 HA的文章很不错。
建议看原文,地址如下:
http://assafmuller.wordpress.com/category/ml2/
大致翻译如下:
L3 Agent Low Availability(L3 agent的低可用性)
目前,在Openstack中,你只能用多个网络节点达到负载分流,但是做不到HA。假设我们有3个网络节点,创建的一些虚拟路由会被分配到这三个节点上。然而,如果某一个节点down掉了,所有在这个节点上的虚拟路由器会中断服务。在Icehouse的neutron中还没有build-in的解决方案。
A Detour to the DHCP Agent(看看DHCP Agent是怎么做的)
DHCP是完全不同的情况。DHCP协议支持多个DHCP Server拥有相同的pool同时共存。
通过修改以下配置:
neutron.conf: dhcp_agents_per_network = X
你就会将每个network的DHCP分配到X个DHCP agents。所以,如果你部署了3个网络节点,并且设置了dhcp_agents_per_network=2,那么每个neutron的network会被这3个网络节点中的2个DHCP agents服务。那么这是如何工作的呢?

首先我们看一下在实体机的情况下是怎么做的。当server连入到10.0.0.0/24子网时,它会广播出DHCP discover。两个DHCP Servers dnsmasq1和dnsmasq2(或者其他的DHCP Server实现)会收到广播包,之后回复一个offer ip是10.0.0.2。假设第一台dnsmasq1的response被server先收到,它就会广播request 10.0.0.2,并且指定dnsmasq1的ip 10.0.0.253 。两台DHCP server都会收到广播包,但是只有dnsmasq1会回复ACK。由于所有的DHCP通信都是通过广播,那么dnsmasq2也会收到ACK,可以标记10.0.0.2被AA:BB:CC:11:22:33使用了,就不会将此IP分配给其他Server了。总的来说,因为clients和servers所有的通信都是通过广播,这样就只需要简单的部署多个DHCP server就能达到HA的效果了。
在Neutron的情况下,MAC和IP的绑定关系是在创建port时设置好的。因此,所有的dnsmasq都会在收到请求前就知道MAC(AA:BB:CC:11:22:33)和IP(10.0.0.2)绑定了。可以看出DHCP HA是在协议层面就支持的。
Back to the Lowly Available L3 Agent(回到L3 Agent的低可用性)
L3 agent目前和DHCP的情况不同,那么如果需要做HA是怎么做的呢?
使用外部的Cluster技术(Pacemaker / Corosync)指定一个Standby网络节点,当active网络节点发生问题时,L3agent会起到standby节点上。两个节点拥有相同的hostname。
另一个方案是写一个脚本作为cron job,它会调用api获得哪些L3 agents死了,然后将属于这些L3 agents的虚拟路由reschedule到其他L3 agents。
在Juno里面Kevin Benton写了一个neutron内置的reschedule,代码是:
https://review.openstack.org/#/c/110893/
Rescheduling Routers Takes a Long, Long Time(rescheduling虚拟路由会花很长时间。。。)
所有的这些都需要很长的时间将虚拟路由reschedule到新的L3 agent。如果有上千个虚拟路由的话那failover可能需要以小时计的down time。
Distributed Virtual Router(分布式虚拟路由)
这里有些文档说明它是如何工作的:
http://specs.openstack.org/openstack/neutron-specs/specs/juno/neutron-ovs-dvr.html
https://docs.google.com/document/d/1jCmraZGirmXq5V1MtRqhjdZCbUfiwBhRkUjDXGt5QUQ/
https://docs.google.com/document/d/1depasJSnGZPOnRLxEC_PYsVLcGVFXZLqP52RFTe21BE/
https://docs.google.com/document/d/1jCmraZGirmXq5V1MtRqhjdZCbUfiwBhRkUjDXGt5QUQ/
https://docs.google.com/document/d/1depasJSnGZPOnRLxEC_PYsVLcGVFXZLqP52RFTe21BE/
它主要是将路由移至计算节点:
DVR只处理Floating IPs, 默认网关的SNAT还是在网络节点的L3 agent上做。
DVR目前不支持VLAN模式,只能同tunnels和L2pop启用时工作。
在每一个计算节点上都需要连接到外部网络。
总的来说,如果你的部署是基于havana或者icehouse,那DVR会需要对你的部署有比较大的改动。而L3 HA会更贴近你当前的部署。
理想情况下,你应该使用DVR+L3 HA 。 Floating IP将被你计算节点直接路由,网关SNAT的traffic将会走网络节点带HA的L3 agent。
Layer 3 High Availability(L3的高可用性)
在Juno里,我们使用keepalived做L3的HA。 Keepalived内部使用的是VRRP,那么首先我们看一下VRRP。
What is VRRP, how does it work in the physical world?(什么是VRRP,它是如何工作的)
VRRP是为了解决网络默认网关的HA的问题。那么是怎么做的呢?当我们在有两台路由的网络拓扑中,你可以指定一半的server是第一个路由的IP地址,另外一半server指定到第二个路由的IP地址。

这样可以提供负载分流,但是如果一个路由器down了就有问题了。自然的就会想到使用一个虚拟IP作为server的默认网关。当Master的路由down了之后,standby的路由器不会收到从Master发出的VRRP hello包,这样就会导致standbys的路由器的一次选举,获胜者将作为新的Master。新的Master将使用VIP,并需要发出gratuitous ARP用于刷新servers的ARP cache,交换机也会知道此虚拟MAC从旧的port移动至了新的port。
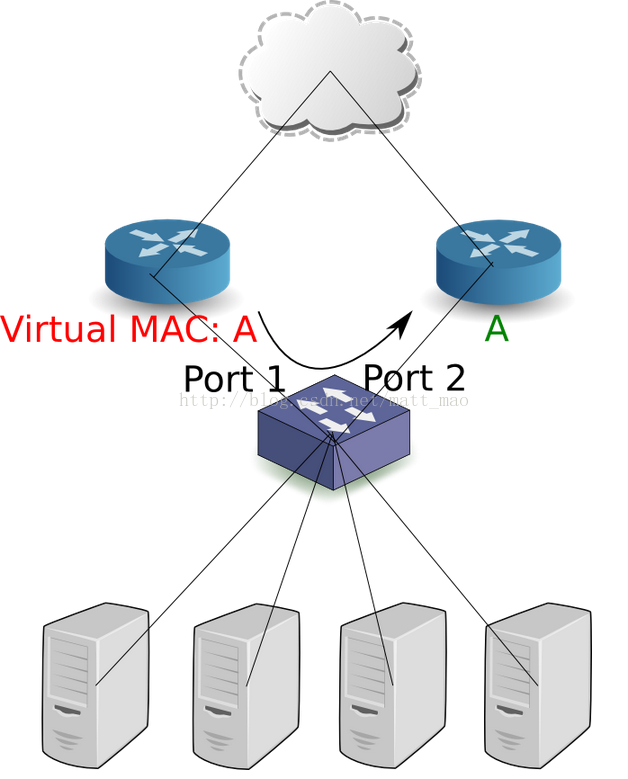
通过这样做了之后,默认路由会改为新的Active的路由,但是没有实现负载分流。那么如何同时做到负载分流呢?可以通过VRRP groups,一半的servers使用第一个VIP,另一半的servers使用第二个VIP。这样的话任意的路由 down掉之后就会移至另一台路由。
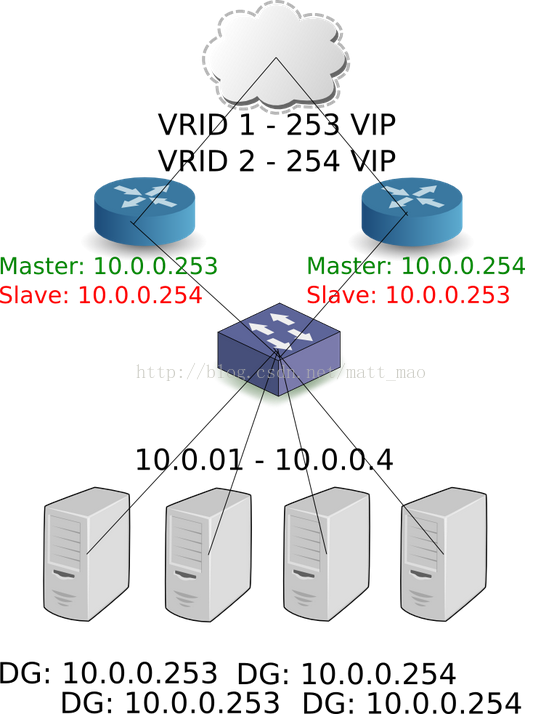
细心的读者可能会想到一个问题,如果路由的external网络连接断了会怎么样呢?他还会是active的路由吗?其实VRRP是有能力监控external网络,这样就可以把external网络断掉的路由器标示为failure。
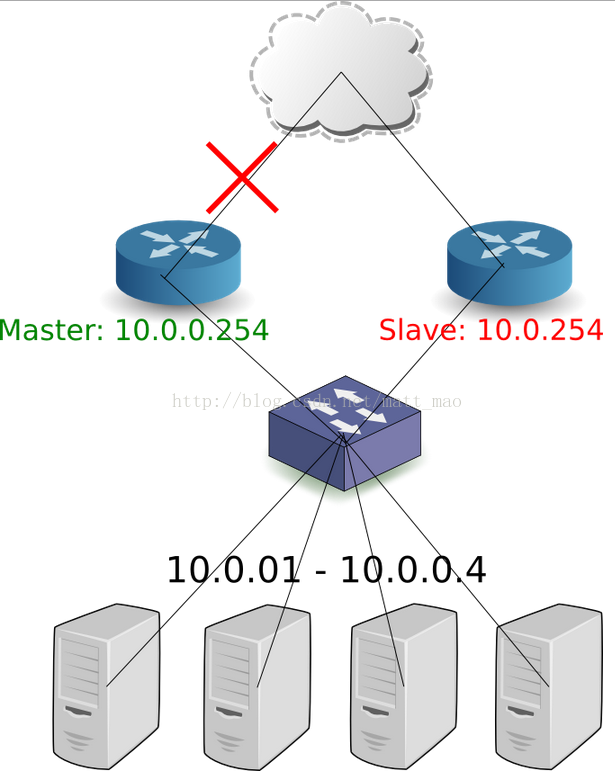
Note:对于IP地址,有下面两种可行的方案:
1. 每个路由器都拥有自己的IP地址,VIP在master作为additional或者secondary IP。
2. 只有VIP一个地址,只有master有IP地址,slaves没有IP地址。
VRRP – The Dry Facts(VRRP基本知识)
1. 直接通过IP协议封装。
2. master使用组播地址224.0.0.18 MAC地址为01-00-5E-00-00-12发送给standby节点Hello消息。
3. 虚拟MAC的地址是00-00-5E-00-01-{VRID}, 因此在同一个广播域中有256个VRIDs(0到255)。
4. 选举的过程使用的是用户设定的priority值,范围是1-255, 数值越大优先级越高。
5. 抢占式(preemptive)选举,这和其他的网络协议一样,当优先级高的路由器加入或者从错误状态中恢复时,会抢占成为master。
6. 非抢占式(non-preemptive)选举,当优先级高的路由器加入或者从错误状态中恢复时,不会抢占成为master,还是维持slave的状态。
7. hello消息的周期是可配置的,如果standby在3倍周期内没有收到hello消息就会发起选举。
Back to Neutron-land(回来看neutron的情况)
L3 HA会在每一个router的namespace中启动一个keepalived。不同的router通过专用的HA网络通信。每一个tenant一个有一个专用的HA网络。HA网络和一般的网络没什么不同,只是它本身没有属于某个tenant,所以在CLI和GUI中是看不到的。HA routers在namespace中,有一个'HA' device:当一个HA router被创建时,它会被schedule到多个网络节点,每个namespace都会通过HA device连接到HA网络。Keepalived的控制流就是通过HA device转发的。以下是router namespace的"ip addr"输出:
[stack@vpn-6-88 ~]$ sudo ip netns exec qrouter-b30064f9-414e-4c98-ab42-646197c74020 ip address
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default
...
2794: ha-45249562-ec: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default
link/ether 12:34:56:78:2b:5d brd ff:ff:ff:ff:ff:ff
inet 169.254.0.2/24 brd 169.254.0.255 scope global ha-54b92d86-4f
valid_lft forever preferred_lft forever
inet6 fe80::1034:56ff:fe78:2b5d/64 scope link
valid_lft forever preferred_lft forever
2795: qr-dc9d93c6-e2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default
link/ether ca:fe:de:ad:be:ef brd ff:ff:ff:ff:ff:ff
inet 10.0.0.1/24 scope global qr-0d51eced-0f
valid_lft forever preferred_lft forever
inet6 fe80::c8fe:deff:fead:beef/64 scope link
valid_lft forever preferred_lft forever
2796: qg-843de7e6-8f: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default
link/ether ca:fe:de:ad:be:ef brd ff:ff:ff:ff:ff:ff
inet 19.4.4.4/24 scope global qg-75688938-8d
valid_lft forever preferred_lft forever
inet6 fe80::c8fe:deff:fead:beef/64 scope link
valid_lft forever preferred_lft forever
这是master的输出,在另一个网络节点上会有同样的ha, qr 和qg,但是他们没有IP。同时也没有floating ip并且路由表为空。 他们是作为配置项写在keepalived的配置文件中的。当keepalived检测到master down掉时,这些地址将会被配置上去。这里是keepalived.conf的例子:
vrrp_sync_group VG_1 {
group {
VR_1
}
notify_backup "/path/to/notify_backup.sh"
notify_master "/path/to/notify_master.sh"
notify_fault "/path/to/notify_fault.sh"
}
vrrp_instance VR_1 {
state BACKUP
interface ha-45249562-ec
virtual_router_id 1
priority 50
nopreempt
advert_int 2
track_interface {
ha-45249562-ec
}
virtual_ipaddress {
19.4.4.4/24 dev qg-843de7e6-8f
}
virtual_ipaddress_excluded {
10.0.0.1/24 dev qr-dc9d93c6-e2
}
virtual_routes {
0.0.0.0/0 via 19.4.4.1 dev qg-843de7e6-8f
}
}
这里的notify脚本是什么呢?这些脚本是keepalived在状态转换为master、backup或者fault时执行的。这里是转换为master的脚本例子:
#!/usr/bin/env bash neutron-ns-metadata-proxy --pid_file=/tmp/tmpp_6Lcx/tmpllLzNs/external/pids/b30064f9-414e-4c98-ab42-646197c74020/pid --metadata_proxy_socket=/tmp/tmpp_6Lcx/tmpllLzNs/metadata_proxy --router_id=b30064f9-414e-4c98-ab42-646197c74020 --state_path=/opt/openstack/neutron --metadata_port=9697 --debug --verbose echo -n master > /tmp/tmpp_6Lcx/tmpllLzNs/ha_confs/b30064f9-414e-4c98-ab42-646197c74020/state
这个脚本仅仅是启动了neutron-ns-metadata-proxy,再将状态写到了状态文件中(状态文件之后会被L3读取)。backup和fault脚本会kill neutron-ns-metadata-proxy进程,并记录对应状态。这意味着neutron-ns-metadata-proxy只会在master上存在。
* Aren’t We Forgetting the Metadata Agent?(我们忘了Metadata agent了吗?)
你只需要将其(neutron-metadata-agent)在每个网络节点上跑着就可以了。
Future Work & Limitations(将来的工作和目前的限制)
1. TCP连接 -- 目前的实现中,TCP sessions会在failover的时候中断。理想情况下,使用conntrackd应该可以做到sessions在failover时不中断。
2. Master Router在哪里? 目前管理员不知道master在哪个网络节点中,计划是agents上报这个信息,然后通过API暴露出去。
3. 当需要维护一个网络节点时,我们所有Master能够放弃Master状态,这样可以加快failover。
4. 通知l2pop VIP的移动。Master节点会拥有VIP,但是Standby会存在同样的neutron port和MAC地址。这会对L2pop产生不利影响,因为它认为MAC地址是只存在于网络的某一位置的。解决这个问题的计划是:当agent检测到VRRP状态发生变化时,发送RPC消息,也就是说当一个路由变为Master时,Controller会收到消息并通知L2pop更新。
5. FW, VPN和LB,与DVR和L3 HA集成时都有问题,在Kilo版本中会深入去看。
6. 每个tenant有1个HA网络,这就限制了每个tenant有255个HA Router,因为VRID在同一广播域中有255个的限制。
Usage & Configuration(使用和配置)
neutron.conf: l3_ha = True max_l3_agents_per_router = 2 min_l3_agents_per_router = 2
l3_ha=Ture表示所有的虚拟路由都是HA模式的,默认为false
你可以设置HA Router被schedule到max和min数目的网络节点数。比如你有4个网络节点,你设置了max和min为2,那么每个HA router会被schedule到两个L3 agent上。当你的网络节点个数小于min时,HA路由会创建失败。
CLI可以覆盖l3_ha的配置(必须拥有admin权限):
neutron router-create --ha=<True | False> router1
References
BP:
spec:
How to test:
Code:
https://review.openstack.org/#/q/topic:bp/l3-high-availability,n,z
Wiki:
Section in Neutron L3 sub team wiki (Including overview of patch dependencies and future work):
https://wiki.openstack.org/wiki/Meetings/Neutron-L3-Subteam#Blueprint:_l3-high-availability_.28safchain.2C_amuller.29















 1276
1276

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









