






 本文详细描述了一种数据处理项目的过程,包括数据建模,从DPI数据中抽取关键信息,存储策略以及处理失败后的应对措施。强调了数据粒度和维度表设计的重要性,以及在Hadoop环境中处理大数据的注意事项,如避免小文件过多和合理分区。此外,文章提出了数据任务失败后的重试和容错机制。
本文详细描述了一种数据处理项目的过程,包括数据建模,从DPI数据中抽取关键信息,存储策略以及处理失败后的应对措施。强调了数据粒度和维度表设计的重要性,以及在Hadoop环境中处理大数据的注意事项,如避免小文件过多和合理分区。此外,文章提出了数据任务失败后的重试和容错机制。
注:本文写的过程为项目实际处理过程,与规范流程、大神们的流程有很多不合之处,限于本人能力,各位多理解。
目录:
1、背景
2、步骤
2.1、数据建模
2.2、数据抽取
2.3、数据存储
3、经验教训
3.1、维表的低耦合与适度耦合。
3.2、建模过程中的注意事项。
3.3、数据任务处理失败后的处理。
一、背景:取移动设备每小时上网详细数据(DPI数据),进行分拆处理后放入小时表、天表,留做业务后续使用。其中数据识别过程、小时表存放在数据方,天表通过限定查询量的方式导入到本方机房。
二、步骤:
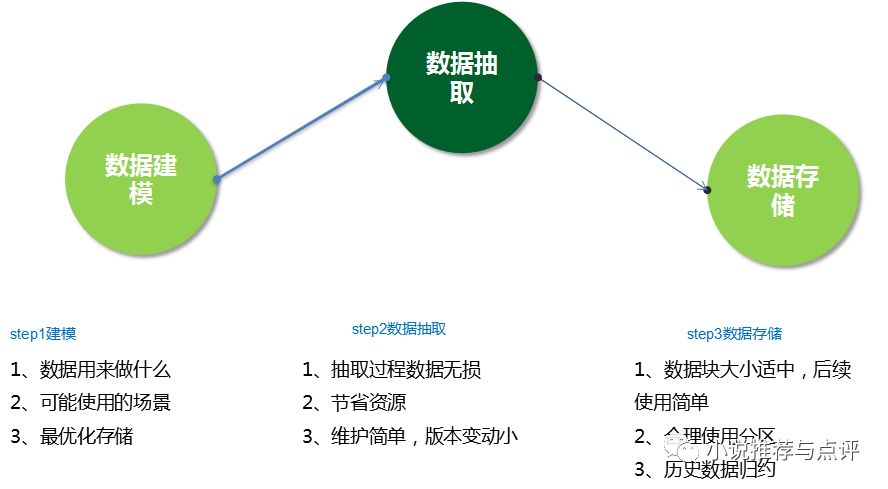
1、数据库建模(也有人说是数据建模)
建模前首先确定数据是用来做什么,可能使用的场景,以及最优化存储(后续使用(例如查询)容易,存储空间小)。
数据源情况:DPI数据因为获取的滞后性,一般会与数据提供方滞后一日,所以不能做实时响应场景。DPI包含url、ua、imei、经纬度,时间等信息;其中过于敏感数据,如位置数据、实际购买商品,不在存储和分析范围之内。
确定数据粒度:(此步很重要,需要业务、数据、开发都知晓)
原始DPI数据,体量很大,一天十几个T,这需要将我们认为有用的数据抽取,同时相应的认为有用的关系不能丢掉过多、也不能保留过多。
比如 数据中 包含 我 今天 上午十点49分打开掌阅阅读,50分打开浏览器搜索小说,然后退出浏览器,然后打开掌阅,浏览20分钟后关闭,又打开浏览器,搜索多个词。
这里面包含了时间、app、频次、顺序、app使用时间、搜索词,搜索词顺序,浏览器,搜索引擎网站 信息。 这就需要来确定保留哪些数据,抛弃哪些数据。保留越多,信息越详细,但是相应需要的存储空间与计算空间也越大。一般来说,时序是很少有客户需要的,出于经济考虑,舍弃。但是本人做了什么还是需要记录的。
最终结果:保留客户使用app的小时id,site名称、app名称,关键词,基本能断定该人的行为;若需要有时间频次,可添加字段尝试。
确定数据维度:
首先是维表,维表需要考虑到数据识别结果表:一般来说,维表不建议多个因素放一起,比如app、site 本身可能有对应关系,但是数据识别结果如果分开,这里就没必要混合。但是有些项又最好放一起,比如手机型号,品牌,厂商,价格。
这里重点提一下,app、site都会有大量的垃圾数据,比如cdn的url,这种本身是利用价值比较低的,建议在数据定义阶段就排除(定义唯一后,置为失效,维护方便)
其次是数据识别结果表,结果表需要根据不同的数据用途、数据的类似程度来存储。
2、数据抽取(远程传输,跨公司部门传输)
基本原则: 抽取过程数据无损,节省资源,维护简单,版本变动小。
项目的数据抽取,逻辑是:在提供方取数据,填充到redis,然后本方查询redis,将数据查询后写入本地hadoop,根据各种数据维表和规则,对结果进行拆分转换。
dmp_redis_table-》分拆为 stags_bd,id_rel_bd
3、数据存储
基本要求:数据块大小适中,后续使用简单,合理使用分区。
这里重点说一下 ,hadoop对小文件的处理,是比较头疼的,如果有大量数据,尽量避免几千几万个小文件同时生成或使用的情况,会导致查询、写入时候耗费大量时间。
将上一步抽取到的数据,按业务需求分拆到表 stdtags_bd,user_rel_bd,个人测试认为单个存储文件大小为400M-1G为最优。
三、经验教训以及注意事项:
1、维表的低耦合与适度耦合。
这里延续 二-1 的数据维度的详细解释。在定义维表方面,如果与其他维度关联不大,尽量单独建表,容易维护和查询;如app名称,domain名称,识别搜索关键词,识别用户兴趣和倾向。
如果两者之间关联较大,如用户设备的信息,都与具体型号关联,可以做到一起;某些特殊品类app或者网站,也可以把分类写到定义维表,这样下一步使用都相对简单。
2、建模过程中的注意事项。
主要是建成的库表要切实符合已有业务需求,适度覆盖可能的业务需求,能够适度升级扩展。过程中主要是与各个同事和业务方的沟通,然后通过对业务逻辑的梳理,进行建模。
落实到数据库上,有业务表的字段制定、生成的文件数、文件大小的控制。
表和表内字段,最好在这一步都定义清晰明了,尽量符合整个部门甚至多个部门对数据处理的需求,切实符合已有业务需求,适度考虑未来可能的业务需求,可以预留几个字段,预留字段一般放在行尾。
适当的数据分区:有效分区能够分割大文件,提高后续使用效率,但是过多的分区会导致维护麻烦,后续使用中可能会出现无法查询全体需求分区的情况(数据库参数和能力限制)
3、数据任务处理失败后的处理。
这里包含两种:
1、数据库内处理时异常和失败
这里需要明确的是,数据处理失败率多少可以接受。在hadoop处理数据中,不能保证每一次都丝毫不差;如果数据源数据过大,处理时集群偶尔抽风,都可能导致处理失败,是否能够接受,不接受的话是否重新执行。这里一般是在MAPReduce过程中通过程序重试完成,设置最多重试次数,若还失败,放弃。
2、程序流程失败
程序流程的失败,包括升级测试不充分导致结果异常、中途网络延迟、网络间断、内存需求超过实际提供量导致泄露、操作人员误操作杀死进程、操作人员主动杀死进程等情况。
大体要求:
1\每一步都可单独重新执行,此步至关重要!因为谁都无法保证流程永远畅通,一旦出问题,从头再来的代价往往是几个小时的计算量,会让集群和业务崩溃。
2\其他诸如网络延迟错误、部分数据丢失或重复等问题,需要考虑适度的容错机制。例如在MapReduce阶段设定容许失败率;设定程序每个阶段可以尝试执行的次数。
3、开发和持有整个流程启动的备份代码,哪怕仅仅是执行脚本。一旦程序和集群出现崩溃,能够迅速有效的进行恢复。
参考:
1、业务文档
2、http://www.cnblogs.com/arnold/articles/2311192.html
原文链接:数据仓库搭建实例


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









