







Hadoop 2.x新特性
将Mapreduce框架升级到Apache YARN,YARN将Map reduce工作区分为两个:JobTracker组件:实现资源管理和任务JOB;计划/监视组件:划分到单独应用中。 使用MapReduce的2.0,开发人员现在可以直接Hadoop内部基于构建应用程序。Hadoop2.2也已经在微软widnows上支持。
YARN带来了什么
1.HDFS的高可靠性
2.HDFS snapshots快照
3.支持HDFS中的 NFSv3 文件系统。
Yarn/map reduce2.0架构图

简单介绍一下这个图:右边的3个节点中的NodeManager会定期的向ResourceManager(简写为RM)报告该节点的状态(块信息,存储信息,该节点中的Map或Reduce任务执行情况等信息),红色的Client向RM提交任务(包括输入文件位置、Mapper和Reducer),RM根据各个节点汇报的情况,为这个Job创建一个Application Master(即图中红色的App Mstr)用于管理这个Job的执行情况。
App Master创建好并接到任务后,会向RM申请资源(包括输入文件位置,内存使用,计算过程等),申请到一些Container(可能在不同节点上)后,会开始在这些节点上执行(根据提供的输入文件位置读取输入文件,执行Map或Reduce任务)这个Job(的部分),App Mstr同时会管理这些节点中的container,并监控这些container的运行情况。
蓝色部分Client----App Mstr----Container过程和红色部分的过程完全相同。
官方的解释在这里:http://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/YARN.html,细节可能有偏差,但大体是这么回事。
准备工作
系统环境如下:

安装好JDK并配置好变量$JAVA_HOME。由于我的机器是Ubuntu的,因此使用apt-get可以安装open-jdk,这里我安装的jdk版本为jdk7u55。
安装Hadoop 2.4
说明:由于我只有一台电脑,所以这里将所有关于hadoop的服务都配置在这里(文章最后将会看到),而HDFS的备份因子默认为3,又由于只有一台机器,因此只能设置为1(下面也有说明)。此种模式除了并非真正意义的分布式之外,其程序执行逻辑完全类似于分布式,因此常用于开发人员测试程序执行。
从http://mirror.metrocast.net/apache/hadoop/common/hadoop-2.4.0/下载。
1.解压到/home/hduser/yarn目录,假设user是用户名(我这里的用户名为wxl)。
|
1
2
3
4
5
|
$
tar
-xvzf hadoop-2.4.0.
tar
.gz
$
mv
hadoop-2.4.0
/home/user/Software/hadoop-2
.4.0
$
cd
/home/user/Software
$
sudo
chown
-R user:user hadoop-2.4.0
$
sudo
chmod
-R 755 hadoop-2.4.0
|
2.在~/.bashrc设置环境,将下面加入:
|
1
2
3
4
5
6
|
export
HADOOP_HOME=
/home/hadoop/hadoop-2
.4.0
export
HADOOP_MAPRED_HOME=$HADOOP_HOME
export
HADOOP_COMMON_HOME=$HADOOP_HOME
export
HADOOP_HDFS_HOME=$HADOOP_HOME
export
YARN_HOME=$HADOOP_HOME
export
HADOOP_CONF_DIR=$HADOOP_HOME
/etc/hadoop
|
3.然后再执行下面的命令使配置生效:
|
1
|
$
source
~/.bashrc
|
4.创建Hadoop数据目录:
|
1
2
|
$
mkdir
-p $HADOOP_HOME
/yarn/yarn_data/hdfs/namenode
$
mkdir
-p $HADOOP_HOME
/yarn/yarn_data/hdfs/datanode
|
5.配置过程:
|
1
2
|
$
cd
$HADOOP_HOME
$
vi
etc
/hadoop/yarn-site
.xml
|
6.编辑 $HADOOP_HOME/etc/hadoop/yarn-site.xml,在<configuration>标签中加入以下内容:
|
1
2
3
4
5
6
7
8
|
<
property
>
<
name
>yarn.nodemanager.aux-services</
name
>
<
value
>mapreduce_shuffle</
value
>
</
property
>
<
property
>
<
name
>yarn.nodemanager.aux-services.mapreduce.shuffle.class</
name
>
<
value
>org.apache.hadoop.mapred.ShuffleHandler</
value
>
</
property
>
|
7.单个集群节点设置,在$HADOOP_HOME/etc/hadoop/core-site.xml文件的<configuration>标签中加入下面内容在配置:
|
1
2
3
4
5
|
<
property
>
<
name
>fs.default.name</
name
>
<!-- 这个地址用于程序中访问HDFS使用 -->
<
value
>hdfs://localhost:9000</
value
>
</
property
>
|
8.在$HADOOP_HOME/etc/hadoop/hdfs-site.xml文件的<configuration>标签中加入下面内容
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
<
property
>
<
name
>dfs.replication</
name
>
<!-- 单机版的一般设为1,若是集群,一般设为3 -->
<
value
>1</
value
>
</
property
>
<
property
>
<
name
>dfs.namenode.name.dir</
name
>
<!-- 即第4步中创建的namenode文件夹位置 -->
<
value
>file:/home/hadoop/hadoop-2.4.0/yarn/yarn_data/hdfs/namenode</
value
>
</
property
>
<
property
>
<
name
>dfs.datanode.data.dir</
name
>
<!-- 即第4步中创建的datanode文件夹位置 -->
<
value
>file:/home/hadoop/hadoop-2.4.0/yarn/yarn_data/hdfs/datanode</
value
>
</
property
>
|
9.在$HADOOP_HOME/etc/hadoop/mapred-site.xml文件(如果这个文件不存在,里面有个mapred-site.xml.template文件,拷贝为mapred-site.xml即可)中的<configuration>标签内加入下面的配置:

|
1
2
3
4
|
<
property
>
<
name
>mapreduce.framework.name</
name
>
<
value
>yarn</
value
>
</
property
>
|
10.格式化namenode,这个过程仅仅在第一次使用之前执行一次。
|
1
|
$ bin
/hadoop
namenode -
format
|
11.启动HDFS处理和Map-Reduce 处理(当然,懒人(我就是一个,呵呵)可以把这几句话写在一个诸如"start.sh"的脚本里面,每次就只需要执行./start.sh就可以启动hadoop的所有服务了,同理,停止hadoop的脚本过程也可以这样做。)
|
1
2
3
4
5
6
7
8
9
10
11
|
# HDFS(NameNode & DataNode)部分:
$ sbin
/hadoop-daemon
.sh start namenode
$ sbin
/hadoop-daemon
.sh start datanode
# MR(Resource Manager, Node Manager & Job History Server).部分:
$ sbin
/yarn-daemon
.sh start resourcemanager
$ sbin
/yarn-daemon
.sh start nodemanager
$ sbin
/mr-jobhistory-daemon
.sh start historyserver
|
此时终端会提示启动的相关日志被记录在$HADOOP_HOME/logs文件夹中,如图:

12.下面来确认是否成功启动了相关服务:
|
1
|
$ jps
|
# 如果成功,应该有类似下面的输出:
|
1
2
3
4
5
6
|
22844 Jps
28711 DataNode
29281 JobHistoryServer
28887 ResourceManager
29022 NodeManager
28180 NameNode
|
如果不成功,在启动这些服务的时候会看到有相关的日志输出,可以去$HADOOP_HOME/logs下面查看相关日志来检查哪些服务失败了,然后再对症处理。
13.HDFS还提供了一个WebUI用于查看该文件系统的状态,浏览器打开端口:http://localhost:50070,其中Utilities标签下有个File Browser,可以浏览HDFS中的文件。
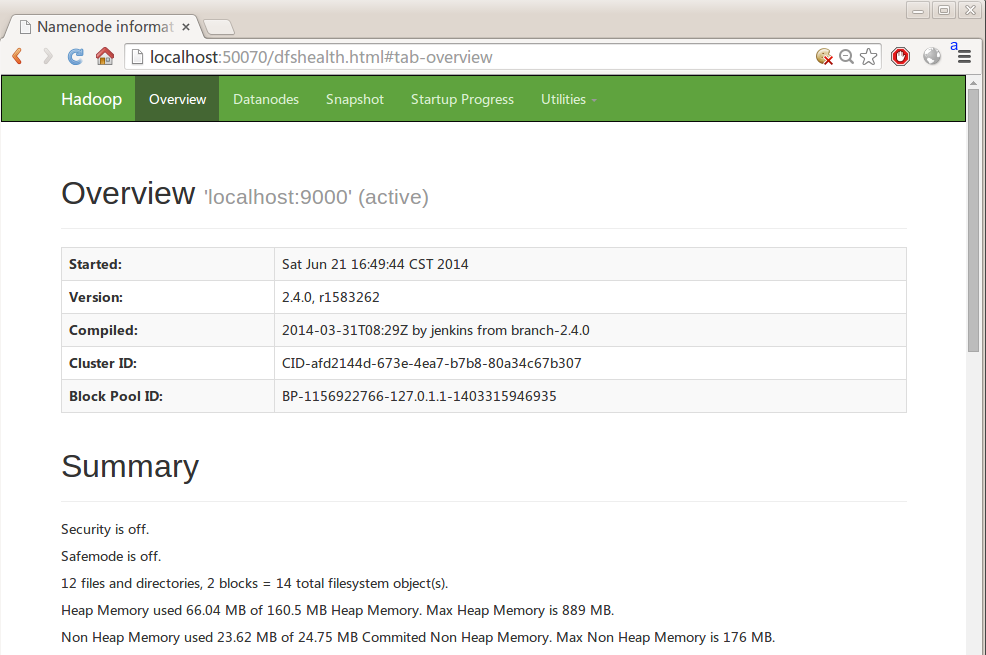
14.可以在http://localhost:8088检查应用程序的状态:

15. 在http://localhost:8088/conf查看hadoop集群的所有配置信息:

到此,Hadoop安装算是完成了。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









