







原文链接 https://www.cnblogs.com/xiaolincoding/p/12442435.html
WEB API接口 大都是基于 HTTP 协议的,所以,要进行接口测试 首先要了解 HTTP 协议 的 基础知识。
学习准备
本教程讲解过程中,需要使用 白月SMS系统 进行演示
学会以下内容:
1、查看http请求:https://www.yuque.com/mengxiaoqi-lrqrz/ylw9z8/vpq00r
HTTP 五大类知识
- HTTP 基本概念
- Get 与 Post
- HTTP 特性
- HTTPS 与 HTTP
- HTTP/1.1、HTTP/2、HTTP/3 演变
01 HTTP 基本概念
HTTP 是什么?描述一下
HTTP 协议 全称是 超文本传输协议, 英文是 Hypertext Transfer Protocol 。
解释下超文本传输协议:
HTTP的名字「超文本协议传输」,它可以拆成三个部分:
- 协议:即【协】即两者以上的参与者,如你、公司、学校+【仪】即行为约定和规范
- 传输:就是两点之间传输数据的约定和规范。如一堆东西从 A 点搬到 B 点,或者从 B 点 搬到 A 点。
- 超文本:【普通文本】就是简单的字符文字,【超文本】就是文字、图片、视频等的混合体最关键有超链接,能从一个超文本跳转到另外一个超文本。
总结:HTTP 是一个在计算机世界里专门在「两点」之间「传输」文字、图片、音频、视频等「超文本」数据的「约定和规范」。
http实现的原理机制
整个流程步骤
域名解析--》发起tcp的三次握手--》发起http请求--》服务器响应http请求--》浏览器解析html代码,并请求html代码中的资源--》浏览器对页面进行渲染呈现给用户
HTTP版本
HTTP 最初是用来 在 浏览器和 网站服务器(web服务)之间 传输超文本(网页、视频、图片等)信息的。
由于 HTTP 简洁易用,后来,不仅仅是浏览器 和 服务器之间 使用它, 服务器和服务器之间, 手机App 和 服务器之间, 都广泛的采用。 成了一个软件系统间 通信 的首选协议 之一。
HTTP 有好几个版本,包括: 0.9 、 1.0 、 1.1 、 2 、 3 ,当前最广泛使用的是 HTTP/1.1 版本。
HTTP 协议最大的特点是 通讯双方 分为 客户端 和 服务端 。
由于 目前 HTTP是基于 TCP 协议的, 所以要进行通讯,客户端 必须先 和服务端 创建 TCP 连接。
而且 HTTP 双方的信息交互,必须是这样一种方式:
- 客户端 先发送 http请求(request)给 服务端
- 然后服务端 发送 http响应(response)给 客户端
特别注意:HTTP协议中,服务端不能主动先发送信息给 客户端。
而且在1.1 以前的版本, 服务端 返回响应给客户端后,连接就会 断开 ,下一次双方要进行信息交流,必须重复上面的过程,重新建立连接,客户端发送请求,服务返回响应。
到了 1.1 版本, 建立连接后,这个连接可以保持一段时间(keep alive), 这段时间,双方可以多次进行 请求和响应, 无需重新建立连接。
如果客户端是浏览器,如何在chrome浏览器中查看 请求和响应的HTTP消息,请参考视频讲解
HTTP 常见的状态码【重】

每发出一个http请求之后,都会有一个响应,http本身会有一个状态码,来标示这个请求是否成功,常见的状态码有以下几种:
• 1xx :提示信息/参考信息(Info)——表示服务器收到请求,需要请求者继续执行操作;
• 2xx :成功(Successful)——表示请求已被成功接收、理解、接受;
• 3xx :重定向(Redirection)——要完成请求必须进行更进一步的操作;
• 4xx:客户端错误(Client Error)——表示请求可能有语法错误或请求无法实现,妨碍了服务器的处理;
• 5xx :服务器端错误(Server Error)——表示服务器在处理请求的过程中发生了内部错误,未能实现合法的请求;
(1)2开头,表示成功处理了请求的状态代码
- 200 OK :服务器已成功处理了请求;如果是非
HEAD请求,服务器返回的响应头都会有 body 数据。
204 No Content :也是常见的成功状态码,与 200 OK 基本相同,但响应头没有 body 数据。
206:是应用于 HTTP 分块下载或断电续传,表示响应返回的 body 数据并不是资源的全部,而是其中的一部分,也是服务器处理成功的状态。
(2)3开头表示客户端请求的资源发送了变动,需要客户端用新的 URL 重新发送请求获取资源,也就是重定向。
- 「301 Moved Permanently」表示永久重定向,说明请求的资源已经不存在了,需改用新的 URL 再次访问。不影响搜索引擎排名,实施301后,新网址完全继承旧网址,旧网址的排名等完全清零;
- 「302 Found」表示临时重定向,说明请求的资源还在,但暂时需要用另一个 URL 来访问。301 和 302 都会在响应头里使用字段
Location,指明后续要跳转的 URL,浏览器会自动重定向新的 URL。影响搜索引擎排名,实施302后,对旧网址没有影响,但新网址不会有排名。 - 「304 Not Modified」不具有跳转的含义,表示资源未修改,重定向已存在的缓冲文件,也称缓存重定向,用于缓存控制。
- 303 See Other临时重定向,期望使用GET定向获取
- 307 Temporary Redirect临时重定向,POST不会变成GET
(3)4开头(客户端发送的报文有误,服务器无法处理)
- 400 :错误请求(Bad Request )——由于客户端请求有语法错误,不能被服务器所理解;
- 401 :未授权(Unauthorized)——访问的页面没有授权,这个状态代码必须和WWW-Authenticate报头域一起使用;
- 403:禁止(Forbidden)——(即没有权限访问这个页面)服务器收到请求,但是拒绝提供服务。服务器通常会在响应正文中给出不提供服务的原因;
- 404:未找到(Not Found )——(即没有这个页面)请求的资源不存在,例如,输入了错误的URL;
(4)5开头(表示客户端请求报文正确,但是服务器处理时内部发生了错误,属于服务器端的错误码。)
- 500 :服务器内部错误( Internal Server Error )——服务器发生不可预期的错误,导致无法完成客户端的请求;
- 「501 Not Implemented」表示客户端请求的功能还不支持,类似“即将开业,敬请期待”的意思。
- 502(错误网关)服务器作为网关或代理,从上游服务器收到无效响应
- 503 : 服务不可用(Service Unavailable )——服务器当前不能够处理客户端的请求,在一段时间之后,服务器可能会恢复正常;
- 504代表服务器端超时,没返回结果
- 505(http版本不支持)
https://www.yuque.com/mengxiaoqi-lrqrz/ylw9z8/ha9uct
HTTP 常见字段有哪些
Host
客户端发送请求时,用来指定服务器的域名。
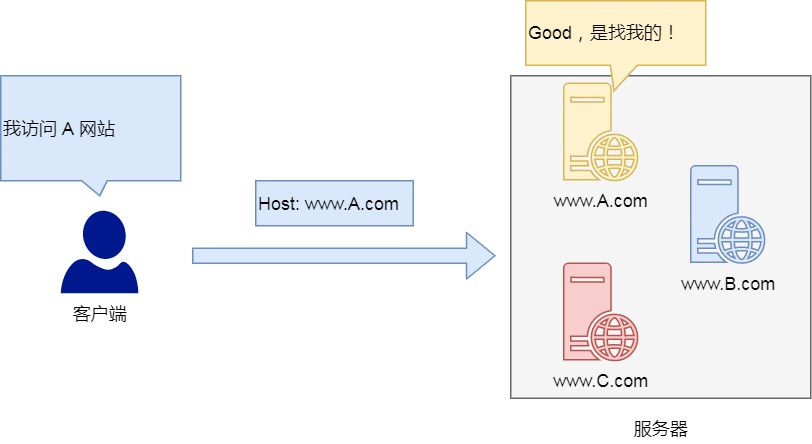
Host: www.A.com
有了 Host 字段,就可以将请求发往「同一台」服务器上的不同网站。
Content-Length 字段
服务器在返回数据时,会有 Content-Length 字段,表明本次回应的数据长度。
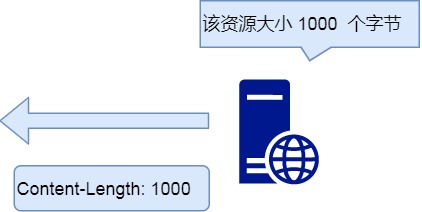
Content-Length: 1000
如上面则是告诉浏览器,本次服务器回应的数据长度是 1000 个字节,后面的字节就属于下一个回应了。
Connection 字段
Connection 字段最常用于客户端要求服务器使用 TCP 持久连接,以便其他请求复用。
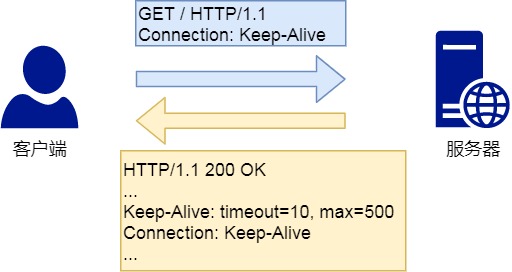
image
HTTP/1.1 版本的默认连接都是持久连接,但为了兼容老版本的 HTTP,需要指定 Connection 首部字段的值为 Keep-Alive。
Connection: keep-alive
一个可以复用的 TCP 连接就建立了,直到客户端或服务器主动关闭连接。但是,这不是标准字段。
Content-Type 字段
Content-Type 字段用于服务器回应时,告诉客户端,本次数据是什么格式。
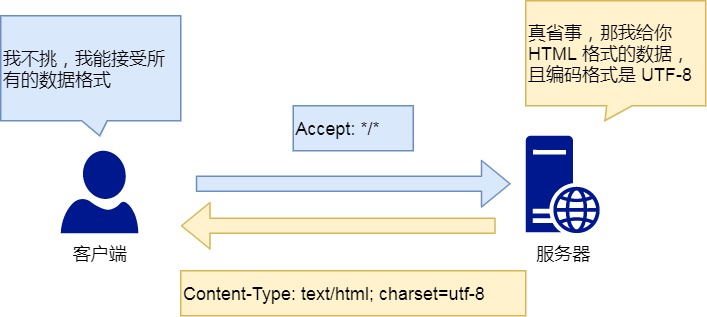
Content-Type: text/html; charset=utf-8
上面的类型表明,发送的是网页,而且编码是UTF-8。
客户端请求的时候,可以使用 Accept 字段声明自己可以接受哪些数据格式。
Accept: */*
上面代码中,客户端声明自己可以接受任何格式的数据。
Content-Encoding 字段
Content-Encoding 字段说明数据的压缩方法。表示服务器返回的数据使用了什么压缩格式
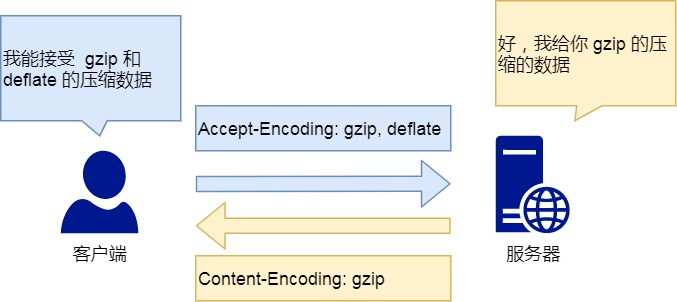
Content-Encoding: gzip
上面表示服务器返回的数据采用了 gzip 方式压缩,告知客户端需要用此方式解压。
客户端在请求时,用 Accept-Encoding 字段说明自己可以接受哪些压缩方法。
Accept-Encoding: gzip, deflate
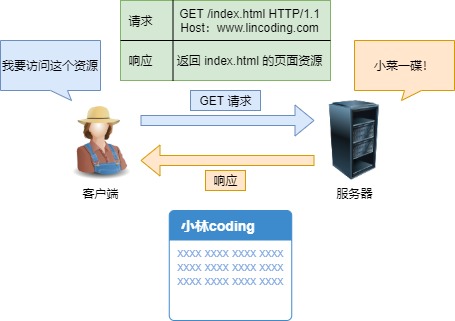
02 HTTP请求消息格式【重】
请求报文包括:
(1)请求行(第一行内容):包含请求方法,URL、http版本协议
(2)请求首部字段
(3)请求内容实体
下面是2个http请求消息的示例
GET /mgr/login.html HTTP/1.1 Host: www.baiyueheiyu.com User-Agent: Mozilla/6.0 (compatible; MSIE5.01; Windows NT) Accept-Language: zh-cn Accept-Encoding: gzip, deflate
POST /api/medicine HTTP/1.1 Host: www.baiyueheiyu.com User-Agent: Mozilla/6.0 (compatible; MSIE5.01; Windows NT) Content-Type: application/x-www-form-urlencoded Content-Length: 51 Accept-Language: zh-cn Accept-Encoding: gzip, deflate name=qingmeisu&sn=099877883837&desc=qingmeisuyaopin
http请求消息由下面几个部分组成
请求行 request line
请求行(第一行内容):包含请求方法,URL、http版本协议
例如
GET /mgr/login.html HTTP/1.1
表示要 获取 资源, 资源的 地址 是 /mgr/login.html , 使用的 协议 是 HTTP/1.1
而
POST /api/medicine HTTP/1.1
表示 添加 资源信息, 添加资源 到 地址 /api/medicine , 使用的 协议 是 HTTP/1.1
HTTP请求方式:
GET、POST是请求的方法,表示这个动作的大体目的,是获取信息,还是提交信息,还是修改信息等等
- GET:获取资源,发送一个请求来获取服务器上的某一资源,如获取图片资源、获取用户信息数据等、多用于查询数据(如列表查询);
- POST:传输资源,将数据添加到服务器中的现有文件或资源(如提交表单或者上传文件),POST 请求可能会导致新的资源的建立或已有资源的修改;比如 要 添加用户信息、上传图片数据 到服务器 等等具体的数据信息,通常在 HTTP消息体中
- HEAD:获取报文首部,响应与GET请求相同,但没有响应正文;
- PUT:更新资源,替换服务器中的现有文件或资源,多用于向指定资源位置上传最新内容(如修改评价或笔记);比如 要 更新 用户姓名、地址 等等具体的更新数据信息,通常在 HTTP消息体中
- DELETE:删除资源,从服务器中删除数据(如取消收藏或删除评价);比如 要 删除 某个用户、某个药品 等等
- PATCH:是对 PUT 方法的补充,用于对资源进行局部更新;
- OPTIONS:用于描述目标资源的通信选项;
- CONNECT:HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器;
- TRACE:回显服务器收到的请求,主要用于测试或诊断;
POST提交数据的方式有哪些?
主要有四种方式:四种方式取决于Content-Type这个请求头;
- application/x-www-form-urlencoded 特点:数据报文是字典,相当于通过表单方式去提交数据,数据的格式: a=1&b=2&c=3
- multipart/form-data 特点:报文包含有文件上传,
- application/json(text/plain, text/xml...) 特点:报文都是字符串类型。
- binary 特点:报文类型是以二进制的方式上传文件。
操作资源地址URL
比如
/mgr/login.html
url表示要获取资源的具体路径,而url参数(问号后面的部分 wd=iphone&rsv_spt=1 就是 url 参数,每个参数之间用 & 隔开)
比如:
https://www.baidu.com/s?wd=iphone&rsv_spt=1
上面的例子中 有两个参数 wd 和 rsv_spt, 他们的值分别为 iphone 和 1 。
url参数的格式,有个术语叫 urlencoded 格式。
注意:
- get和post的区别
- post提交数据有哪些?
请求头 request headers
- 请求头是http请求行下面的 的内容,里面存放 一些 信息。
- 比如,请求发送的服务端域名是什么, 希望接收的响应消息使用什么语言,请求消息体的长度等等。
- 通常请求头 都有好多个,一个请求头 占据一行
- 单个请求头的 格式是: 名字: 值
- HTTP协议规定了一些标准的请求头,点击查看MDN的描述
- 开发者,也可以在HTTP消息中 添加自己定义的请求头
常见请求头和其作用为:
- Accept:字段声明客户端请求的时候可以接受哪些数据格式。Accept: */*表示可以接受任何格式的数据。(例如:Accept:text/html,image/、image/webp,/*)、json、html格式;
- Accept-Encoding:用于告诉服务器,客户机支持的数据压缩格式;
- Accept-Language:客户机语言环境;
- Accept-Charset:用于告诉服务器,客户机采用的编码格式;
- Connection:字段最常用于客户端要求服务器使用 TCP 持久连接,以便其他请求复用。
- Cookie:客户机通过这个头,将Cookie信息带给服务器;
- Host:客户端发送请求时,用来指定服务器的域名。有了
Host字段,就可以将请求发往「同一台」服务器上的不同网站。
比如
客户端访问A网站 ----> Host: www.A.com -----> 服务器:www.A.com /www.B.com /www.C.com (服务器可以有多个域名,客户端寻找对应的域名即可)
- Referer:客户机通过这个头告诉服务器,它(客户端)是从哪个资源来访问服务器的(防盗链);
- If-Modified-Since:客户机通过这个头告诉服务器,资源的缓存时间;
- User-Agent:客户机通过这个头告诉服务器,客户机的软件环境(操作系统,浏览器型号和版本等);
- Date:告诉服务器,当前请求的时间;
- Content-Type:用于服务器回应时,告诉客户端,本次数据是什么报文格式。
- X-Requested-Wh:异步请求。ajax异步请求,无刷新。
- User-Agent:发送请求的客户端的类型.
- content-Encoding: gzip表示服务器返回的数据采用了 gzip 方式压缩,告知客户端需要用此方式解压。
- Content-Length:服务器在返回数据时,表明本次回应的数据长度。如Content-Length: 1000,表明本次服务器回应的数据长度是 1000 个字节,后面的字节就属于下一个回应了。
消息体 message body
请求的url、请求头中 可以存放 一些数据信息, 但是 有些数据信息,往往需要 存放在消息体中。
特别是 POST、PUT等请求,添加、修改的数据信息 通常都是 存放在 请求消息体 中的。
如果 HTTP 请求 有 消息体, 协议规定 需要在 消息头和消息体 之间 插入一个空行, 隔开 它们。
请求消息体中保存了要提交给服务端的数据信息。
比如:客户端要上传一个文件给服务端,就可以通过HTTP请求发送文件数据给服务端。
文件的数据 就应该在请求的消息体中。
再比如:上面示例中 客户端要添加药品,药品的名称、编码、描述,就存放在请求消息体中。
WEB API 请求消息体 通常是某种格式的文本,常见的有
- Json
- Xml
- www-form-urlencoded
后面会有详细的讲述
03 HTTP响应消息格式【重】
一个http response(http响应)指的是从服务端到客户端的响应消息,它包括了以下信息:响应状态码、响应头、响应报文
- 状态码:标记响应状态的一个标识,200-成功,404-资源找不到,500服务器异常,302-重定向等,
- 响应头信息:告诉客户端关于服务器,响应报文相关的一些信息,例如,服务器类型,响应报文格式
- 响应报文:针对请求从服务响应回来的数据,比如html、xml、json等
下面是1个http响应消息的示例
HTTP/1.1 200 OK
Date: Thu, 19 Sep 2019 08:08:27 GMT
Server: WSGIServer/0.2 CPython/3.7.3
Content-Type: application/json
Content-Length: 37
X-Frame-Options: SAMEORIGIN
Vary: Cookie
{"ret": 0, "retlist": [], "total": 0}
HTTP响应消息包含如下几个部分
状态行 status line
状态行在第一行,包含3个部分:
- 协议版本上面的示例中,就是 HTTP/1.1
- 状态码上面的示例中,就是 200
- 描述状态的短语上面的示例中,就是 OK
响应头 response headers
响应头 是 响应状态行下面的 的内容,里面存放 一些 信息。 作用 和 格式 与请求头类似,不再赘述。
消息体 message body
有时候,http响应需要消息体。
同样, 如果 HTTP 响应 有 消息体, 协议规定 需要在 消息头和消息体 之间 插入一个空行, 隔开 它们。
比如,白月SMS系统 请求 列出 药品 信息,那么 药品 信息 就在HTTP响应 消息体中
再 比如,浏览器地址栏 输入 登录网址,浏览器 请求一个登录网页的内容,网站服务器,就在响应的消息体中存放登录网页的html内容。
和请求消息体一样,WEB API 响应消息体 通常也是某种格式的文本,常见的有:
- Json
- Xml
- www-form-urlencoded
关于这些格式,我们会在后续课程中进行讲解
04 GET 和 POST
(1)GET和Post的区别【重】
Get 方法的含义是请求从服务器获取资源,这个资源可以是静态的文本、页面、图片视频等。
比如,你打开我的文章,浏览器就会发送 GET 请求给服务器,服务器就会返回文章的所有文字及资源。
而POST 方法则是相反操作,它向 URI 指定的资源提交数据,数据就放在报文的 body 里。
比如,你在我文章底部,敲入了留言后点击「提交」(暗示你们留言),浏览器就会执行一次 POST 请求,把你的留言文字放进了报文 body 里,然后拼接好 POST 请求头,通过 TCP 协议发送给服务器。
GET 请求 POST 请求
GET 和 POST 方法都是安全和幂等的吗?
先说明下安全和幂等的概念:
- 在 HTTP 协议里,所谓的「安全」是指请求方法不会「破坏」服务器上的资源。
- 所谓的「幂等」,意思是多次执行相同的操作,结果都是「相同」的。
那么很明显 GET 方法就是安全且幂等的,因为它是「只读」操作,无论操作多少次,服务器上的数据都是安全的,且每次的结果都是相同的。
POST 因为是「新增或提交数据」的操作,会修改服务器上的资源,所以是不安全的,且多次提交数据就会创建多个资源,所以 不是幂等的。
get和post的区别
| 区别 | Get | Post | |
| 1 | 目标 | 获取信息 | 提交服务器资源 |
| 2 | 传送数据方式 |
|
|
| 3 | 传参长度 | GET是直接在浏览器地址栏输入,直接影响到了URL的长度,但HTTP协议规范中其实是没有对URL限制长度的,限制URL长度的是客户端或服务器的支持的不同所影响:比如IE对URL长度的限制是2083字节(2K+35)。对于其他浏览器,如Netscape、FireFox等,理论上没有长度限制,其限制取决于操作系统的支持。由于浏览器有限制,一般整个URL的长度可以很长,但是不能超过2049KB的大小限制 | POST没有大小限制。 |
| 4 | 请求体 | 无 | 有 |
| 5 | 效率 | GET产生一个TCP数据包; (包含请求头和data) | POST产生两个TCP数据包,POST需要两步,时间上消耗要多一点,GET比POST更有效; (1请求头,返回100,2.data,返回200) |
| 6 | 编码方式 | 只支持ASCII | 没有限制 |
| 7 | 请求过程 | 浏览器会把http header和data一并发送出去,服务器响应200(返回数据) | 浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok; |
| 8 | 提交数据的安全性 | 由于GET的参数是在浏览器地址栏URL直接拼接,用户名和密码将明文出现在URL上,暴露在互联网中,安全性差,不能用来传递敏感信息。 | POST请求参数放在Body里,是通过表单数据提交,POST比GET方式的安全性要高,因为数据在地址栏上不可见; |
05 HTTP 特性
HTTP(1.1)的优点
HTTP 最凸出的优点是「简单、灵活和易于扩展、应用广泛和跨平台」。
1. 简单
HTTP 基本的报文格式就是 header + body,头部信息也是 key-value 简单文本的形式,易于理解,降低了学习和使用的门槛。
2. 灵活和易于扩展
HTTP协议里的各类请求方法、URI/URL、状态码、头字段等每个组成要求都没有被固定死,都允许开发人员自定义和扩充。
同时 HTTP 由于是工作在应用层( OSI 第七层),则它下层可以随意变化。
https工作在应用层.会话层为7层协议的第五层,为表示层提供建立、维护和结束会话连接的功能,并提供会话管理服务。 【问题:HTTPS在哪一层, 会话层在第几层】
HTTPS 也就是在 HTTP 与 TCP 层之间增加了 SSL/TLS 安全传输层,HTTP/3 甚至把 TCPP 层换成了基于 UDP 的 QUIC。
3. 应用广泛和跨平台
互联网发展至今,HTTP 的应用范围非常的广泛,从台式机的浏览器到手机上的各种 APP,从看新闻、刷贴吧到购物、理财、吃鸡,HTTP 的应用片地开花,同时天然具有跨平台的优越性。
HTTP(1.1)的缺点
HTTP 协议里有优缺点一体的双刃剑,分别是「无状态、明文传输」,同时还有一大缺点「不安全」。
1. 无状态双刃剑
无状态的好处,因为服务器不会去记忆 HTTP 的状态,所以不需要额外的资源来记录状态信息,这能减轻服务器的负担,能够把更多的 CPU 和内存用来对外提供服务。
无状态的坏处,既然服务器没有记忆能力,它在完成有关联性的操作时会非常麻烦。
例如:登录->添加购物车->下单->结算->支付,这系列操作都要知道用户的身份才行。但服务器不知道这些请求是有关联的,每次都要问一遍身份信息。
这样每操作一次,都要验证信息,这样的购物体验还能愉快吗?别问,问就是酸爽!
对于无状态的问题,解法方案有很多种,其中比较简单的方式用 Cookie 技术。
Cookie 通过在请求和响应报文中写入 Cookie 信息来控制客户端的状态。
相当于,在客户端第一次请求后,服务器会下发一个装有客户信息的「小贴纸」,后续客户端请求服务器的时候,带上「小贴纸」,服务器就能认得了了,
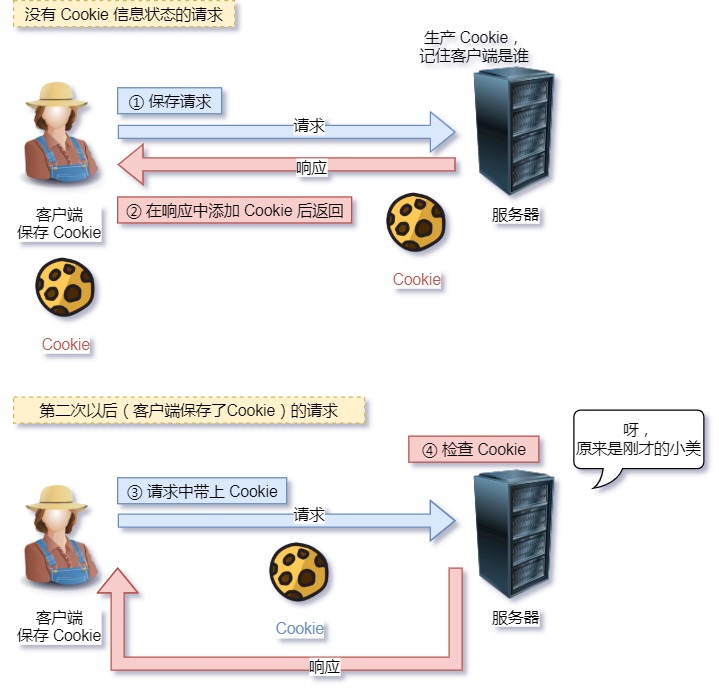
Cookie 技术
2. 明文传输双刃剑
明文意味着在传输过程中的信息,是可方便阅读的,通过浏览器的 F12 控制台或 Wireshark 抓包都可以直接肉眼查看,为我们调试工作带了极大的便利性。
但是这正是这样,HTTP 的所有信息都暴露在了光天化日下,相当于信息裸奔。在传输的漫长的过程中,信息的内容都毫无隐私可言,很容易就能被窃取,如果里面有你的账号密码信息,那你号没了。
3. 不安全
HTTP 比较严重的缺点就是不安全:
- 通信使用明文(不加密),内容可能会被窃听。比如,账号信息容易泄漏,那你号没了。
- 不验证通信方的身份,因此有可能遭遇伪装。比如,访问假的淘宝、拼多多,那你钱没了。
- 无法证明报文的完整性,所以有可能已遭篡改。比如,网页上植入垃圾广告,视觉污染,眼没了。
HTTP 的安全问题,可以用 HTTPS 的方式解决,也就是通过引入 SSL/TLS 层,使得在安全上达到了极致。
HTTP/1.1 的性能如何
HTTP 协议是基于 TCP/IP,并且使用了「请求 - 应答」的通信模式,所以性能的关键就在这 两点里。
1. 长连接
早期 HTTP/1.0 性能上的一个很大的问题,那就是每发起一个请求,都要新建一次 TCP 连接(三次握手),而且是串行请求,做了无畏的 TCP 连接建立和断开,增加了通信开销。
为了解决上述 TCP 连接问题,HTTP/1.1 提出了长连接的通信方式,也叫持久连接。这种方式的好处在于减少了 TCP 连接的重复建立和断开所造成的额
外开销,减轻了服务器端的负载。
持久连接的特点是,只要任意一端没有明确提出断开连接,则保持 TCP 连接状态。
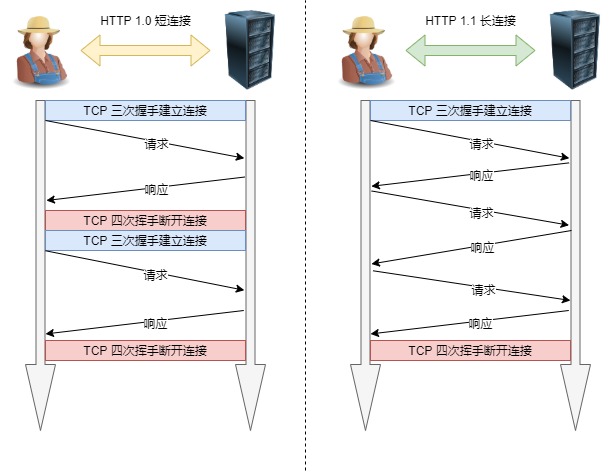
短连接与长连接
2. 管道网络传输
HTTP/1.1 采用了长连接的方式,这使得管道(pipeline)网络传输成为了可能。
即可在同一个 TCP 连接里面,客户端可以发起多个请求,只要第一个请求发出去了,不必等其回来,就可以发第二个请求出去,可以减少整体的响应时间。
举例来说,客户端需要请求两个资源。以前的做法是,在同一个TCP连接里面,先发送 A 请求,然后等待服务器做出回应,收到后再发出 B 请求。管道机制则是允许浏览器同时发出 A 请求和 B 请求。
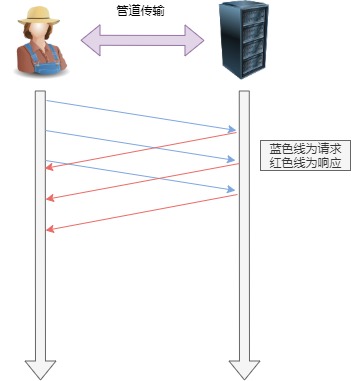
管道网络传输
但是服务器还是按照顺序,先回应 A 请求,完成后再回应 B 请求。要是 前面的回应特别慢,后面就会有许多请求排队等着。这称为「队头堵塞」。
3. 队头阻塞
「请求 - 应答」的模式加剧了 HTTP 的性能问题。
因为当顺序发送的请求序列中的一个请求因为某种原因被阻塞时,在后面排队的所有请求也一同被阻塞了,会招致客户端一直请求不到数据,这也就是「队头阻塞」。好比上班的路上塞车。
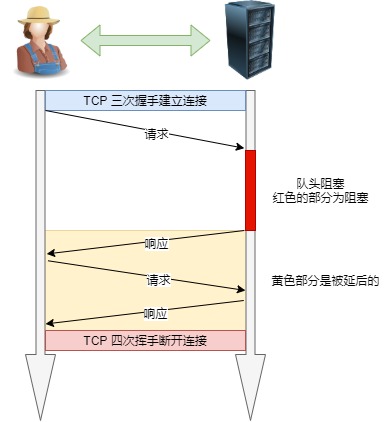
队头阻塞
总之 HTTP/1.1 的性能一般般,后续的 HTTP/2 和 HTTP/3 就是在优化 HTTP 的性能。
06 HTTP 与 HTTPS
HTTP 与 HTTPS 有哪些区别?
- HTTP 是超文本传输协议,信息是明文传输,存在安全风险的问题。HTTPS 则解决 HTTP 不安全的缺陷,在 TCP 和 HTTP 网络层之间加入了 SSL/TLS 安全协议,使得报文能够加密传输。
- HTTP 连接建立相对简单, TCP 三次握手之后便可进行 HTTP 的报文传输。而 HTTPS 在 TCP 三次握手之后,还需进行 SSL/TLS 的握手过程,才可进入加密报文传输。
- HTTP 的端口号是 80,HTTPS 的端口号是 443。
- HTTPS 协议需要向 CA(证书权威机构)申请数字证书,来保证服务器的身份是可信的。
HTTPS 解决了 HTTP 的哪些问题?
HTTP 由于是明文传输,所以安全上存在以下三个风险:
- 窃听风险,比如通信链路上可以获取通信内容,用户号容易没。
- 篡改风险,比如强制入垃圾广告,视觉污染,用户眼容易瞎。
- 冒充风险,比如冒充淘宝网站,用户钱容易没。
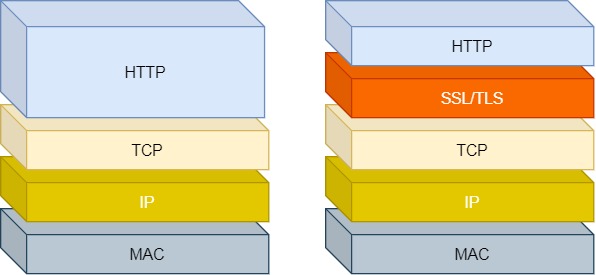
HTTP 与 HTTPS 网络层
HTTPS 在 HTTP 与 TCP 层之间加入了 SSL/TLS 协议,可以很好的解决了上述的风险:
- 信息加密:交互信息无法被窃取,但你的号会因为「自身忘记」账号而没。
- 校验机制:无法篡改通信内容,篡改了就不能正常显示,但百度「竞价排名」依然可以搜索垃圾广告。
- 身份证书:证明淘宝是真的淘宝网,但你的钱还是会因为「剁手」而没。
可见,只要自身不做「恶」,SSL/TLS 协议是能保证通信是安全的。
HTTPS 是如何解决上面的三个风险的
- 混合加密的方式实现信息的机密性,解决了窃听的风险。
- 摘要算法的方式来实现完整性,它能够为数据生成独一无二的「指纹」,指纹用于校验数据的完整性,解决了篡改的风险。
- 将服务器公钥放入到数字证书中,解决了冒充的风险。
1. 混合加密
通过混合加密的方式可以保证信息的机密性,解决了窃听的风险。
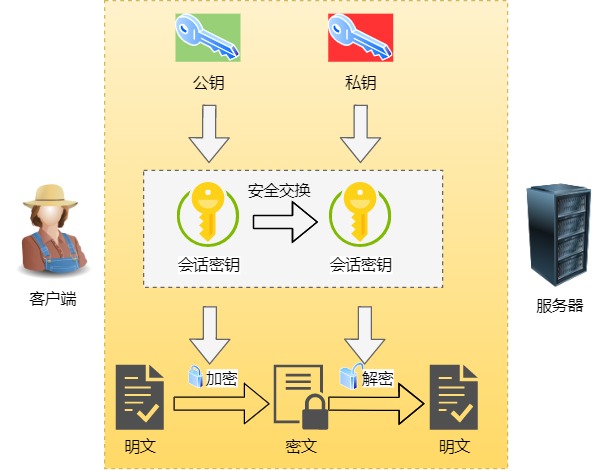
混合加密
HTTPS 采用的是对称加密和非对称加密结合的「混合加密」方式:
- 在通信建立前采用非对称加密的方式交换「会话秘钥」,后续就不再使用非对称加密。
- 在通信过程中全部使用对称加密的「会话秘钥」的方式加密明文数据。
采用「混合加密」的方式的原因:
- 对称加密只使用一个密钥,运算速度快,密钥必须保密,无法做到安全的密钥交换。
- 非对称加密使用两个密钥:公钥和私钥,公钥可以任意分发而私钥保密,解决了密钥交换问题但速度慢。
2. 摘要算法
摘要算法用来实现完整性,能够为数据生成独一无二的「指纹」,用于校验数据的完整性,解决了篡改的风险。
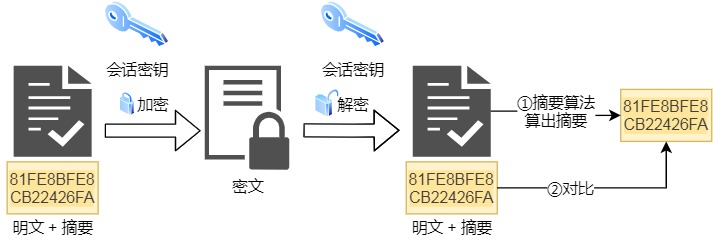
校验完整性
客户端在发送明文之前会通过摘要算法算出明文的「指纹」,发送的时候把「指纹 + 明文」一同
加密成密文后,发送给服务器,服务器解密后,用相同的摘要算法算出发送过来的明文,通过比较客户端携带的「指纹」和当前算出的「指纹」做比较,若「指纹」相同,说明数据是完整的。
3. 数字证书
客户端先向服务器端索要公钥,然后用公钥加密信息,服务器收到密文后,用自己的私钥解密。
这就存在些问题,如何保证公钥不被篡改和信任度?
所以这里就需要借助第三方权威机构 CA (数字证书认证机构),将服务器公钥放在数字证书(由数字证书认证机构颁发)中,只要证书是可信的,公钥就是可信的。
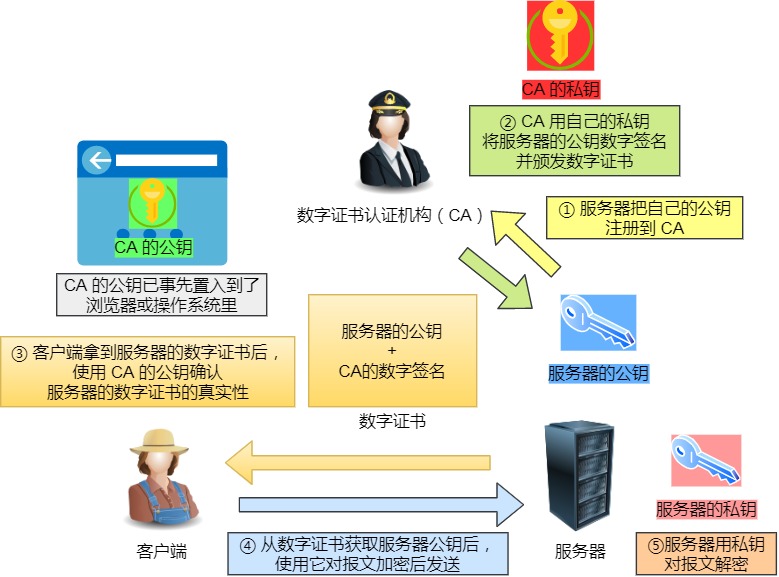
数子证书工作流程
通过数字证书的方式保证服务器公钥的身份,解决冒充的风险。
HTTPS 是如何建立连接的,其间交互了什么
SSL/TLS 协议基本流程:
- 客户端向服务器索要并验证服务器的公钥。
- 双方协商生产「会话秘钥」。
- 双方采用「会话秘钥」进行加密通信。
前两步也就是 SSL/TLS 的建立过程,也就是握手阶段。
SSL/TLS 的「握手阶段」涉及四次通信,可见下图:
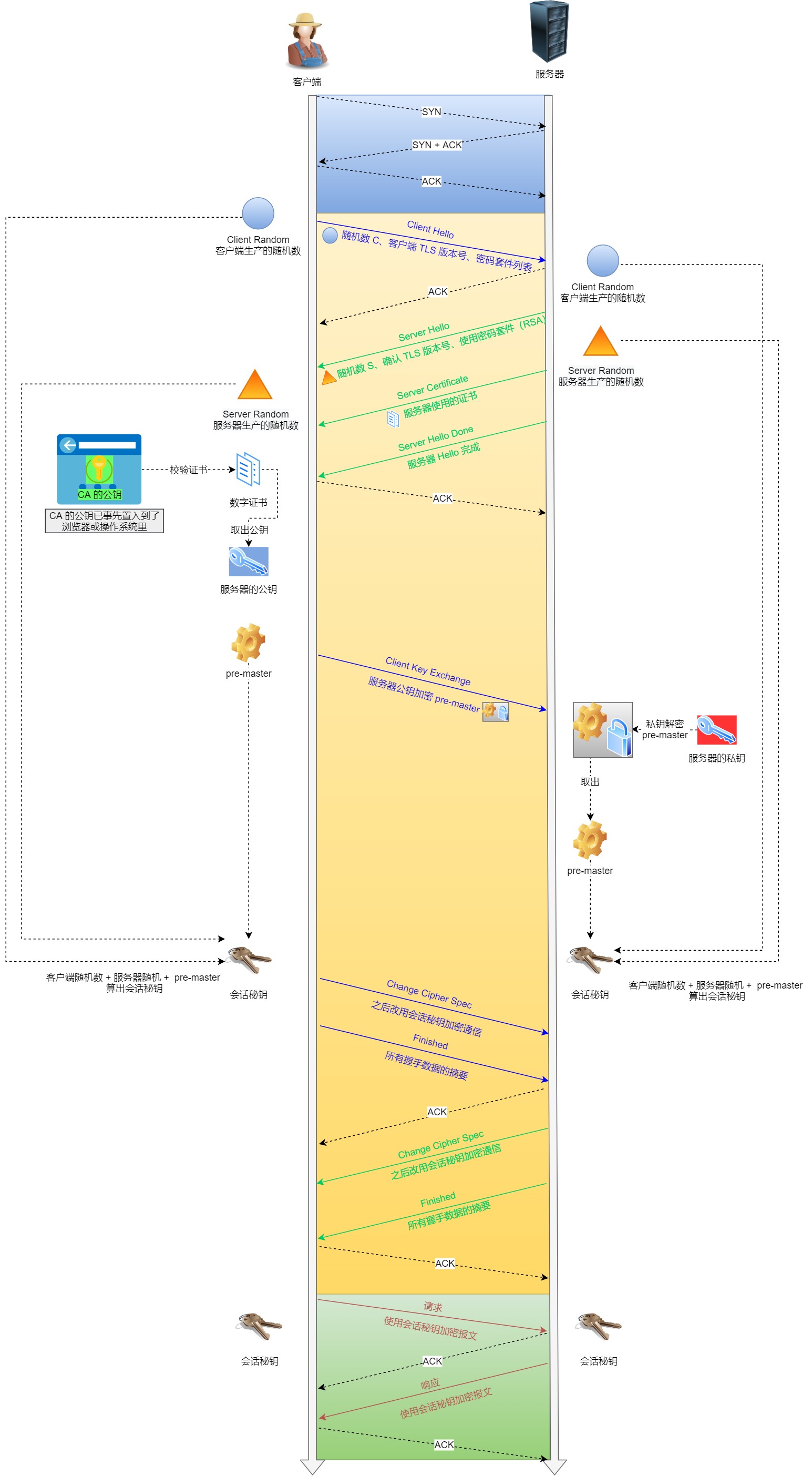
HTTPS 连接建立过程
SSL/TLS 协议建立的详细流程:
1. ClientHello
首先,由客户端向服务器发起加密通信请求,也就是 ClientHello 请求。
在这一步,客户端主要向服务器发送以下信息:
(1)客户端支持的 SSL/TLS 协议版本,如 TLS 1.2 版本。
(2)客户端生产的随机数(Client Random),后面用于生产「会话秘钥」。
(3)客户端支持的密码套件列表,如 RSA 加密算法。
2. SeverHello
服务器收到客户端请求后,向客户端发出响应,也就是 SeverHello。服务器回应的内容有如下内容:
(1)确认 SSL/ TLS 协议版本,如果浏览器不支持,则关闭加密通信。
(2)服务器生产的随机数(Server Random),后面用于生产「会话秘钥」。
(3)确认的密码套件列表,如 RSA 加密算法。
(4)服务器的数字证书。
3.客户端回应
客户端收到服务器的回应之后,首先通过浏览器或者操作系统中的 CA 公钥,确认服务器的数字证书的真实性。
如果证书没有问题,客户端会从数字证书中取出服务器的公钥,然后使用它加密报文,向服务器发送如下信息:
(1)一个随机数(pre-master key)。该随机数会被服务器公钥加密。
(2)加密通信算法改变通知,表示随后的信息都将用「会话秘钥」加密通信。
(3)客户端握手结束通知,表示客户端的握手阶段已经结束。这一项同时把之前所有内容的发生的数据做个摘要,用来供服务端校验。
上面第一项的随机数是整个握手阶段的第三个随机数,这样服务器和客户端就同时有三个随机数,接着就用双方协商的加密算法,各自生成本次通信的「会话秘钥」。
4. 服务器的最后回应
服务器收到客户端的第三个随机数(pre-master key)之后,通过协商的加密算法,计算出本次通信的「会话秘钥」。然后,向客户端发生最后的信息:
(1)加密通信算法改变通知,表示随后的信息都将用「会话秘钥」加密通信。
(2)服务器握手结束通知,表示服务器的握手阶段已经结束。这一项同时把之前所有内容的发生的数据做个摘要,用来供客户端校验。
至此,整个 SSL/TLS 的握手阶段全部结束。接下来,客户端与服务器进入加密通信,就完全是使用普通的 HTTP 协议,只不过用「会话秘钥」加密内容。
07 HTTP/1.1、HTTP/2、HTTP/3 演变
HTTP/1.1 相比 HTTP/1.0 提高了什么性能
HTTP/1.1 相比 HTTP/1.0 性能上的改进:
- 使用 TCP 长连接的方式改善了 HTTP/1.0 短连接造成的性能开销。
- 支持 管道(pipeline)网络传输,只要第一个请求发出去了,不必等其回来,就可以发第二个请求出去,可以减少整体的响应时间。
但 HTTP/1.1 还是有性能瓶颈:
- 请求 / 响应头部(Header)未经压缩就发送,首部信息越多延迟越大。只能压缩
Body的部分; - 发送冗长的首部。每次互相发送相同的首部造成的浪费较多;
- 服务器是按请求的顺序响应的,如果服务器响应慢,会招致客户端一直请求不到数据,也就是队头阻塞;
- 没有请求优先级控制;
- 请求只能从客户端开始,服务器只能被动响应。
相对 HTTP/1.1 的性能瓶颈,HTTP/2 的优化
HTTP/2 协议是基于 HTTPS 的,所以 HTTP/2 的安全性也是有保障的。
那 HTTP/2 相比 HTTP/1.1 性能上的改进:
1. 头部压缩
HTTP/2 会压缩头(Header)如果你同时发出多个请求,他们的头是一样的或是相似的,那么,协议会帮你消除重复的分。
这就是所谓的 HPACK 算法:在客户端和服务器同时维护一张头信息表,所有字段都会存入这个表,生成一个索引号,以后就不发送同样字段了,只发送索引号,这样就 提高速度了。
2. 二进制格式
HTTP/2 不再像 HTTP/1.1 里的纯文本形式的报文,而是全面采用了二进制格式,头信息和数据体都是二进制,并且统称为帧(frame):头信息帧和数据帧。
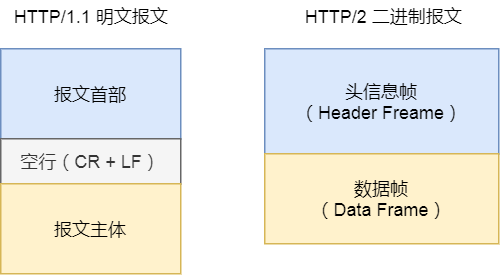
报文区别
这样虽然对人不友好,但是对计算机非常友好,因为计算机只懂二进制,那么收到报文后,无需再将明文的报文转成二进制,而是直接解析二进制报文,这增加了数据传输的效率。
3. 数据流
HTTP/2 的数据包不是按顺序发送的,同一个连接里面连续的数据包,可能属于不同的回应。因此,必须要对数据包做标记,指出它属于哪个回应。
每个请求或回应的所有数据包,称为一个数据流(Stream)。每个数据流都标记着一个独一无二的编号,其中规定客户端发出的数据流编号为奇数, 服务器发出的数据流编号为偶数
客户端还可以指定数据流的优先级。优先级高的请求,服务器就先响应该请求。
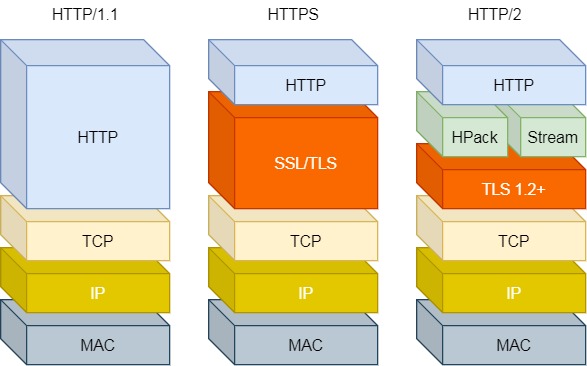
HTTP/1 ~ HTTP/2
4. 多路复用
HTTP/2 是可以在一个连接中并发多个请求或回应,而不用按照顺序一一对应。
移除了 HTTP/1.1 中的串行请求,不需要排队等待,也就不会再出现「队头阻塞」问题,降低了延迟,大幅度提高了连接的利用率。
举例来说,在一个 TCP 连接里,服务器收到了客户端 A 和 B 的两个请求,如果发现 A 处理过程非常耗时,于是就回应 A 请求已经处理好的部分,接着回应 B 请求,完成后,再回应 A 请求剩下的部分。
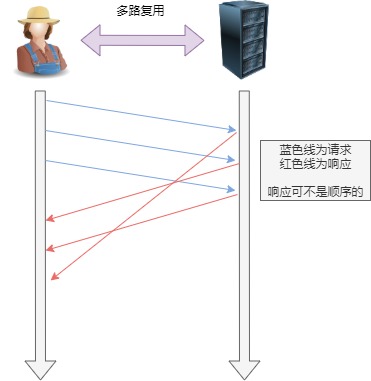
多路复用
5. 服务器推送
HTTP/2 还在一定程度上改善了传统的「请求 - 应答」工作模式,服务不再是被动地响应,也可以主动向客户端发送消息。
举例来说,在浏览器刚请求 HTML 的时候,就提前把可能会用到的 JS、CSS 文件等静态资源主动发给客户端,减少延时的等待,也就是服务器推送(Server Push,也叫 Cache Push)。
HTTP/2 有哪些缺陷,HTTP/3 做了哪些优化
HTTP/2 主要的问题在于,多个 HTTP 请求在复用一个 TCP 连接,下层的 TCP 协议是不知道有多少个 HTTP 请求的。所以一旦发生了丢包现象,就会触发 TCP 的重传机制,这样在一个 TCP 连接中的所有的 HTTP 请求都必须等待这个丢了的包被重传回来。
- HTTP/1.1 中的管道( pipeline)传输中如果有一个请求阻塞了,那么队列后请求也统统被阻塞住了
- HTTP/2 多请求复用一个TCP连接,一旦发生丢包,就会阻塞住所有的 HTTP 请求。
这都是基于 TCP 传输层的问题,所以 HTTP/3 把 HTTP 下层的 TCP 协议改成了 UDP!
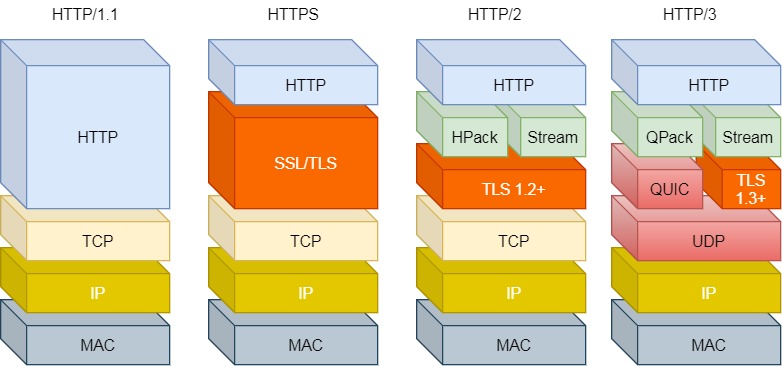
HTTP/1 ~ HTTP/3
UDP 发生是不管顺序,也不管丢包的,所以不会出现 HTTP/1.1 的队头阻塞 和 HTTP/2 的一个丢包全部重传问题。
大家都知道 UDP 是不可靠传输的,但基于 UDP 的 QUIC 协议 可以实现类似 TCP 的可靠性传输。
- QUIC 有自己的一套机制可以保证传输的可靠性的。当某个流发生丢包时,只会阻塞这个流,其他流不会受到影响。
- TL3 升级成了最新的
1.3版本,头部压缩算法也升级成了QPack。 - HTTPS 要建立一个连接,要花费 6 次交互,先是建立三次握手,然后是
TLS/1.3的三次握手。QUIC 直接把以往的 TCP 和TLS/1.3的 6 次交互合并成了 3 次,减少了交互次数。
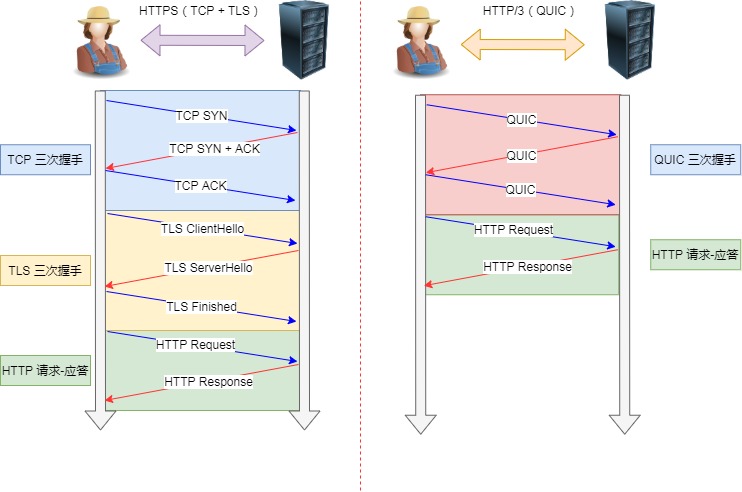
TCP HTTPS(TLS/1.3) 和 QUIC HTTPS
所以, QUIC 是一个在 UDP 之上的伪 TCP + TLS + HTTP/2 的多路复用的协议。
QUIC 是新协议,对于很多网络设备,根本不知道什么是 QUIC,只会当做 UDP,这样会出现新的问题。所以 HTTP/3 现在普及的进度非常的缓慢,不知道未来 UDP 是否能够逆袭 TCP。
08 cookie工作原理
09 session机制
一个网站,比如一个购物网站,服务成千上万的客户。
这么多客户同时访问网站,挑选商品,购物结算,都是通过HTTP请求访问网站的。
这个网站服务程序 怎么每个HTTP请求(比如付费 HTTP 请求)对应的是哪个客户的呢?
网站是怎么做到这点的呢?
一种常见的方式就是:通过 Session机制
(1)什么是Session机制?
用户使用客户端登录,服务端进行验证(比如验证用户名、密码)。
验证通过后,服务端系统就会为这次登录创建一个session。
session就是一个数据结构,保存该客户这次登录操作相关信息。通常保存在数据库中。
同时创建一个唯一的sessionid(就是一个字符串),标志这个session。
然后,服务端 通过 HTTP的响应头 Set-Cookie 把产生的sessionid 告诉 客户端。
客户端在后续的 HTTP请求消息头Cookie 告诉服务端它所持有的sessionid的。这样服务端就会知道,这个请求对应哪个session,从而知道对应哪个客户。
HTTP 协议规定了, 网站服务端放HTTP响应中 消息头 Set-Cookie 里面的数据, 叫做 cookie 数据, 浏览器客户端 必须保存下来。而且后续访问该网站,必须在 HTTP的请求头 Cookie 中携带保存的所有cookie数据。
session 机制大体原理如下图所示 :
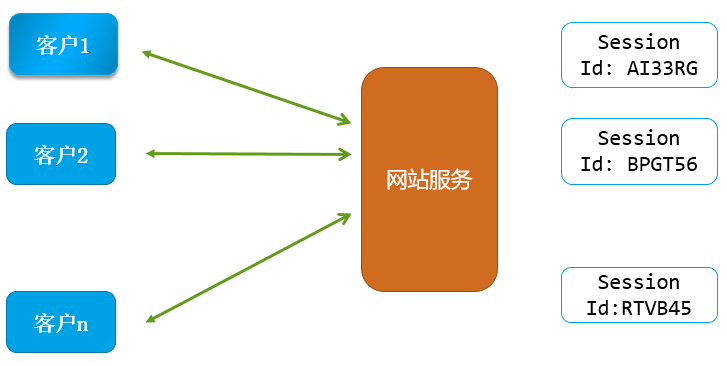
(2)requests处理session-cookie
requests库给我们提供一个 Session 类 。
操作:
- 导入requests库
- 创建一个session对象
- 通过session对象发送请求
例子:
import requests
# 打印HTTP响应消息的函数
def printResponse(response):
print('\n\n-------- HTTP response * begin -------')
print(response.status_code)
for k, v in response.headers.items():
print(f'{k}: {v}')
print('')
print(response.content.decode('utf8'))
print('-------- HTTP response * end -------\n\n')
# 创建 Session 对象
s = requests.Session()
# 通过 Session 对象 发送请求
response = s.post("http://127.0.0.1/api/mgr/signin",
data={
'username': 'byhy',
'password': '88888888'
})
printResponse(response)
# 通过 Session 对象 发送请求
response = s.get("http://127.0.0.1/api/mgr/customers",
params={
'action' : 'list_customer',
'pagesize' : 10,
'pagenum' : 1,
'keywords' : '',
})
printResponse(response)
打印全部http消息,如:
import requests
# 打印请求消息, 参数为 PreparedRequest 对象
def pretty_print_request(req):
if req.body == None:
msgBody = ''
else:
msgBody = req.body
print(
'{}\n{}\n{}\n\n{}'.format(
'\n\n----------- 发送请求 -----------',
req.method + ' ' + req.url,
'\n'.join('{}: {}'.format(k, v) for k, v in req.headers.items()),
msgBody,
))
# 打印响应消息
def pretty_print_response(res):
print(
'{}\nHTTP/1.1 {}\n{}\n\n{}'.format(
'\n\n----------- 得到响应 -----------',
res.status_code,
'\n'.join('{}: {}'.format(k, v) for k, v in res.headers.items()),
res.text,
))
req = requests.Request(
'post',
'http://www.baidu.com',
headers={
'head1':'value1',
'head2':'value2',
},
data={
'item1':'body-value1',
'item2':'body-value2',
})
session = requests.Session()
# 如果这样写 prepared = req.prepare()
# 后续发送会 请求消息头中,会丢掉session中的cookie数据
# 必须像下面这样写,才能让请求包含cookie数据
prepared = session.prepare_request(req)
pretty_print_request(prepared)
r = session.send(prepared)
pretty_print_response(r)
课后练习
题目1
根据教程
- 下载运行白月SMS系统
- 练习用chrome浏览器查看 界面操作时,对应的 HTTP请求、响应消息的 各个组成部分,包括:请求行 请求消息头 请求消息体 响应行 响应消息头 响应消息体
参考:
















 12万+
12万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









