







参考文献:https://www.cnblogs.com/chuyiwang/p/17566583.html
目录
Kubectl get pod --namespace=kube-system
Kubernetes 集群中的 Service 不可访问,怎么办?
Node 节点加入 Kubernetes 集群后无法被调度,怎么办?
Kubernetes 集群中的 PersistentVolume 挂载失败,怎么办?
Kubernetes API Server 不可用,如何排查?
Kubernetes 集群绕过了 LoadBalancer,直接访问 Pod,怎么办?
Kubernetes 集群中的 Deployment 自动更新失败,怎么办?
Kubernetes 集群无法连接 etcd 存储系统,怎么办?
1、master节点无法访问nodeport类型的service
K8s 出错排查三大步
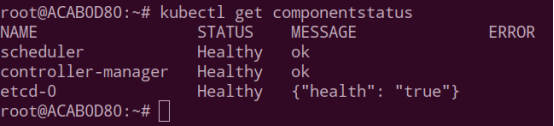
kubectl get componentstatus
查看 scheduler/controller-manager/etcd 等组件 Healthy
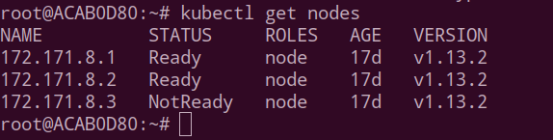
Kubectl get nodes
查看节点的状态,判断是不是有出错的节点
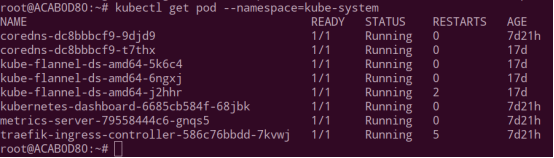
Kubectl get pod --namespace=kube-system
查看系统命名空间 kube-system 里组件的状态
pod问题排查
Pod 无法启动,如何查找原因?
- 使用
kubectl describe pod [pod_name] -n [namespace_name]命令查看该 Pod 的状态信息,检查容器的状态和事件信息,判断是否出现问题。 - 使用
kubectl logs [pod_name] -n [namespace_name]命令查看该 Pod 容器的日志信息,判断是否有错误或异常信息。 - 使用
kubectl get events --field-selector involvedObject.name=[pod_name] -n [namespace_name]命令查看该 Pod 相关的事件信息,判断是否有异常事件发生。
Pod 无法连接到其他服务,如何排查?
- 使用
kubectl exec -it [pod_name] -n [namespace_name] -- /bin/bash命令进入该 Pod 所在的容器,尝试使用 ping 或 telnet 等命令测试与其他服务的网络连接情况。 - 使用
kubectl describe pod [pod_name] -n [namespace_name]命令检查 Pod 的NetworkPolicy配置,判断是否阻止了该 Pod 访问其他服务。 - 使用
kubectl describe service [service_name] -n [namespace_name]命令检查目标服务的配置和状态信息,判断是否存在故障。
Pod 运行缓慢或异常,如何排查?
- 使用
kubectl top pod [pod_name] -n [namespace_name]命令查看该 Pod 的 CPU 和内存使用情况,判断是否存在性能瓶颈。 - 使用
kubectl exec -it [pod_name] -n [namespace_name] -- /bin/bash命令进入该 Pod 所在的容器,使用 top 或 htop 命令查看容器内部进程的 CPU 和内存使用情况,找出可能存在的瓶颈。 - 使用
kubectl logs [pod_name] -n [namespace_name]命令查看该 Pod 容器的日志信息,寻找可能的错误或异常信息。
Pod 无法被调度到节点上运行,如何排查?
- 使用
kubectl describe pod [pod_name] -n [namespace_name]命令查看 Pod 的调度情况,判断是否存在资源不足、调度策略等问题。 - 使用
kubectl get nodes和kubectl describe node [node_name]命令查看所有节点的资源使用情况,判断是否存在节点资源不足或故障的情况。 - 使用
kubectl describe pod [pod_name] -n [namespace_name]命令检查 Pod 所需的标签和注释,以及节点的标签和注释,判断是否匹配。
Pod 状态一直是 Pending ,怎么办?
- 查看该 Pod 的事件信息:
kubectl describe pod <pod-name> - 查看该节点资源利用率是否过高:
kubectl top node - 如果是调度问题,可以通过以下方式解决:
- 确保有足够的节点资源满足该 Pod 调度需求
- 检查该节点的
taints和tolerations是否与 Pod 的selector匹配 - 调整 Pod 的调度策略,如使用
NodeSelector、Affinity等
Pod 无法访问外部服务,怎么办?
- 查看 Pod 中的 DNS 配置是否正确
- 检查 Pod 所在的命名空间中是否存在 Service 服务
- 确认该 Pod 是否具有网络访问权限
- 查看 Pod 所在的节点是否有对外的访问权限
- 检查网络策略是否阻止了 Pod 对外的访问
Pod 启动后立即退出,怎么办?
- 查看该 Pod 的事件信息:
kubectl describe pod <pod-name> - 查看该 Pod 的日志:
kubectl logs <pod-name> - 检查容器镜像是否正确、环境变量是否正确、入口脚本是否正常
- 尝试在本地使用相同的镜像运行该容器,查看是否有报错信息,如执行
docker run <imagename>
Pod 启动后无法正确运行应用程序,怎么办?
- 查看 Pod 中的应用程序日志:
kubectl logs <pod-name> - 查看该 Pod 的事件信息:
kubectl describe pod <pod-name> - 检查应用程序的配置文件是否正确
- 检查应用程序的依赖是否正常
- 尝试在本地使用相同的镜像运行该容器,查看是否有报错信息,如执行
docker run <imagename> - 确认该应用程序是否与 Pod 的资源限制相符
Kubernetes 集群中的 Service 不可访问,怎么办?
- 检查
Service的定义是否正确 - 检查
endpoint是否正确生成 - 检查网络插件配置是否正确
- 确保防火墙配置允许
Service对外开放
Node 相关问题及排查
Node 状态异常,如何排查?
- 使用
kubectl get nodes命令查看集群中所有节点的状态和信息,判断是否存在故障。 - 使用
kubectl describe node [node_name]命令查看目标节点的详细信息,包括 CPU、内存、磁盘等硬件资源的使用情况,判断是否存在性能瓶颈。 - 使用
kubectl get pods -o wide --all-namespaces命令查看集群中所有 Pod 的状态信息,判断是否有 Pod 运行在目标节点上导致资源紧张。
Node 上运行的 Pod 无法访问网络,如何排查?
- 使用
kubectl describe node [node_name]命令查看目标节点的信息,检查节点是否正常连接到网络。 - 使用
kubectl describe pod [pod_name] -n [namespace_name]命令查看 Pod 所运行的节点信息,判断是否因为节点状态异常导致网络访问失败。 - 使用
kubectl logs [pod_name] -n [namespace_name]命令查看 Pod 容器的日志信息,寻找可能的错误或异常信息。
Node 上的 Pod 无法访问存储,如何排查?
- 使用
kubectl describe pod [pod_name] -n [namespace_name]命令检查 Pod 的 volumes配置信息,判断是否存在存储挂载失败的情况。 - 使用
kubectl exec -it [pod_name] -n [namespace_name] -- /bin/bash命令进入 Pod 所在的容器,尝试使用 ls 和 cat 等命令访问挂载的文件系统,判断是否存在读写错误。 - 使用
kubectl describe persistentvolumeclaim [pvc_name] -n [namespace_name]命令查看相关 PVC 配置和状态信息,判断是否存在故障。
存储卷挂载失败,如何处理?
- 使用
kubectl describe pod [pod_name] -n [namespace_name]命令检查 Pod 的 volumes配置信息,判断是否存在存储卷定义错误。 - 使用
kubectl describe persistentvolumeclaim [pvc_name] -n [namespace_name]命令检查 PVC 的状态和信息,判断是否存在存储配额不足或存储资源故障等原因。 - 如果是
NFS或Ceph等网络存储,需要确认网络连接是否正常,以及存储服务器的服务是否正常。
Node 节点加入 Kubernetes 集群后无法被调度,怎么办?
- 检查该节点的
taints和tolerations是否与 Pod 的selector匹配 - 检查该节点的资源使用情况是否满足 Pod 的调度要求
- 确保该节点与
Kubernetes API server的连接正常
Kubernetes 集群中的 PersistentVolume 挂载失败,怎么办?
- 检查
PersistentVolume和 Pod 之间的匹配关系是否正确 - 检查
PersistentVolumeClaim中的storageClassName是否与PersistentVolume的storageClassName匹配 - 检查节点存储配置和
PersistentVolume的定义是否正确 - 自动供给层面的权限是否已经给到位
集群层面问题及排查
集群中很多 Pod 运行缓慢,如何排查?
- 使用
kubectl top pod -n [namespace_name]命令查看所有 Pod 的 CPU 和内存使用情况,判断是否存在资源瓶颈。 - 使用
kubectl get nodes和kubectl describe node [node_name]命令查看所有节点的资源 - 使用情况,判断是否存在单个节点资源紧张的情况。
- 使用
kubectl logs [pod_name] -n [namespace_name]命令查看 Pod 容器的日志信息,寻找可能的错误或异常信息。
集群中某个服务不可用,如何排查?
- 使用
kubectl get pods -n [namespace_name]命令查看相关服务的所有 Pod 的状态信息,判断是否存在故障。 - 使用
kubectl describe pod [pod_name] -n [namespace_name]命令检查 Pod 的网络连接和存储访问等问题,寻找故障原因。 - 使用
kubectl describe service [service_name] -n [namespace_name]命令查看服务的配置和状态信息,判断是否存在故障。
集群中的 Node 和 Pod 不平衡,如何排查?
- 使用
kubectl get nodes和kubectl get pods -o wide --all-namespaces命令查看所有Node 和 Pod 的状态信息,判断是否存在分布不均的情况。 - 使用
kubectl top pod -n [namespace_name]命令查看所有 Pod 的 CPU 和内存使用情况,判断是否存在资源瓶颈导致 Pod 分布不均。 - 使用
kubectl describe pod [pod_name] -n [namespace_name]命令查看 Pod 所运行的节点信息,并使用kubectl describe node [node_name]命令查看相关节点的状态信息,判断是否存在节点不平衡的情况。 - 使用
kubectl describe pod / node [node_name]查看当前Pod / Node上是否有相关的亲和或反亲和策略导致固定调度。
集群中某个节点宕机,如何处理?
- 使用
kubectl get nodes命令检查节点状态,找到异常节点。 - 使用
kubectl drain [node_name] --ignore-daemonsets命令将节点上的 Pod 驱逐出去,并将其部署到其他节点上。添加--ignore-daemonsets参数可以忽略DaemonSet资源。 - 如果需要对节点进行维护或替换硬件:
- 先将节点设置为不可以调度
kubectl cordon [node_name] - 再通过
kubectl drain [node_name] --ignore-daemonsets命令将节点上的 Pod 驱逐出去,并将其部署到其他节点上。 - 然后再次
kubectl delete node [node_name]安全的进行节点下线。
- 先将节点设置为不可以调度
Kubernetes API Server 不可用,如何排查?
- 使用
kubectl cluster-info命令查看集群状态,判断是否存在API Server不可用的情况。 - 使用
kubectl version命令查看集群版本,确认Kubernetes API Server和kubelet版本是否匹配。 - 使用
systemctl status kube-apiserver命令检查API Server运行状态,确认是否存在故障或错误。 - 结合
apiServer所在的节点查看系统层面的日志,进一步定位问题点。
Kubernetes 命令执行失败,怎么办?
- 检查
Kubernetes API server是否可用:kubectl cluster-info - 检查当前用户对集群的权限是否足够:
kubectl auth can-i <verb> <resource> - 检查
kubeconfig文件中的登录信息是否正确:kubectl config view
Kubernetes master 节点不可用,怎么办?
- 检查
kube-apiserver、kube-scheduler、kube-controller-manager是否都在运行状态 - 检查
etcd存储系统是否可用 - 尝试重新启动
master节点上的kubelet和容器运行时
Kubernetes 集群绕过了 LoadBalancer,直接访问 Pod,怎么办?
- 检查
Service和Pod的通信是否使用了ClusterIP类型的Service - 确认该
Service的selector是否匹配到了正确的Pod
Kubernetes 集群中的 Deployment 自动更新失败,怎么办?
- 检查更新策略是否设置正确,如
rollingUpdate或recreate - 检查
Kubernetes API server和kubelet之间的连接是否正常 - 检查
Pod的定义是否正确
Kubernetes 集群中的状态检查错误,怎么办?
- 检查节点日志和事件信息,并确认错误类型
- 确认该状态检查是否与
kubelet的版本兼容 - 尝试升级
kubelet和容器运行时等组件
Kubernetes 集群中的授权配置有误,怎么办?
- 检查
RoleBinding和ClusterRoleBinding定义是否正确 - 检查用户或服务账号所绑定的角色是否正确
- 检查
kubeconfig文件中的用户和访问权限是否正确
Kubernetes 集群无法连接 etcd 存储系统,怎么办?
- 检查
etcd存储系统是否正常运行 - 检查
kube-apiserver配置文件中etcd的连接信息是否正确 - 尝试手动连接
etcd集群,如执行etcdctl cluster-health
日常k8s遇到的问题记录
1、master节点无法访问nodeport类型的service
问题描述:通过master节点ip无法访问nodeport类型的service,通过node节点ip可以访问。
问题定位:
kubectl get cs
查看 scheduler/controller-manager/etcd 等组件 Healthy 正常
kubectl get nodes
查看节点信息正常
kubectl get pods -n kube-system
查看 kube-system的pods 发现 flannel 网络pods 在不停的重启

kubectl delete -n kube-system pod kube-flannel-ds-sw64-9z8lb kube-flannel-ds-sw64-smdrk kube-flannel-ds-sw64-tll8p
删除 flannel 的pods 然后等pods自动重新创建后恢复















 5585
5585

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









