







Hive Create Table和Load DATA详解
Hive在使用创建表的时候,有有一系列的语法,在官网上都有介绍,这里讲解一些重要和常用的语法,在Hive创建好表后,一般是从HDFS LOAD DATA到表中。分别对这两部分进行讲解。
一、Hive Create Table详细讲解
Hive在创建表的时候一般有几个比较重要的参数,分别为:分区、行格式化、文件存储类型、文件位置,这里以一条简单的语句来讲解这几个参数
create external table person(
id int,
name string,
hobbies ARRAY <string>,
address MAP <string, string>)
PARTITIONED BY(dt string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '|'
COLLECTION ITEMS TERMINATED BY '-'
MAP KEYS TERMINATED BY ':'
LINES TERMINATED BY '\n'
STORED AS TEXTFILE
LOCATION '/tmp/person';
在本条创建语句中,分别指定了分区、行格式化、文件存储类型、文件保存位置。
分区
PARTITIONED BY是指定了该表格以dt为分区,在存储表格的文件夹/tmp/t_user下会出现以分区命名的文件夹,同时在操作表格数据的时候,都需要加上分区。
行格式化
行格式化语句是和FIELDS TERMINATED、COLLECTION ITEMS TERMINATED、MAP KEYS TERMINATED一起使用的,Hive数据类型与关系型数据库不一样,多了ARRAY,MAP的类型。其中
FIELDS TERMINATED制定了表格数据在保存时候,每列数据的分隔符,这里指定了|,在load data的数据的时候,会以这个分隔符来分割每列数据,然后导入到相应的表格中
COLLECTION ITEMS TERMINATED,Hive中有集合类型的数据,例如Array,MAP,这个字符定义了,集合间数据的保存,以及LOAD DATA到表格中的数据的切MAP KEYS TERMINATED,Map集合的数据保存和导入的形式,与COLLECTION ITEMS TERMINATED一样,在LOAD DATA的时候,会有一个详细的介绍。
LINES TERMINATED,行数据之间保存的分隔符,在导入的时候,会以这个分隔符来切分每一条数据。
STORED AS
这个是指定保存数据文件的类型。有TEXTFILE、SEQUENCEFILE、ORC、PARQUET、AVRO、RCFILE、JSONFILE,每种文件对应着不同的INPUTFORMAT、OUTPUTFORMAT,在创建表格的后,都会翻译成INPUTFORMAT、OUTPUTFORMAT,可以通过语句show create table person来查看,比如LZO压缩类型的文件就是这样的:STORED AS INPUTFORMAT com.hadoop.mapred.DeprecatedLzoTextInputFormat
OUTPUTFORMAT org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat。
LOCATION:
表格文件保存的位置。
CREATE TABLE的详细讲解如
二、LOAD DATA详解
LOAD DATA的格式为:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
中括号里面的为可选项,如果设定了LOCAL,则表明,filepath是本地文件,默认是HDFS上的文件,OVERWRITE是把原来表格中的数据清空,再导入,默认:APPEND。
当导入数据到HIVE里面,源数据会被移动到表格的LOCATION目录,使用drop table命令后,默认不会删除数据文件,在源表的LOCATION位置会保留源数据文件。如需设置,则要指定属性:external.table.purge = true
二、LOAD DATA 测试使用
表的创建语句在上面,然后分别准备了一些数据,如下
1|Lilei|book-tv-code|beijing:chaoyang-shanghai:pudong
2|Hanmeimei|book-Lilei-code|beijing:haidian-shanghai:huangpu
命名为person.txt,然后使用hadoop fs -put person.txt /hivetest上传文件到HDFS目录
执行以下命令到数据到Hive中
load data inpath '/hivetest/person.txt' overwrite into table person partition(dt='p')
然后再Hive中查询,查看数据详详情,如下图所示
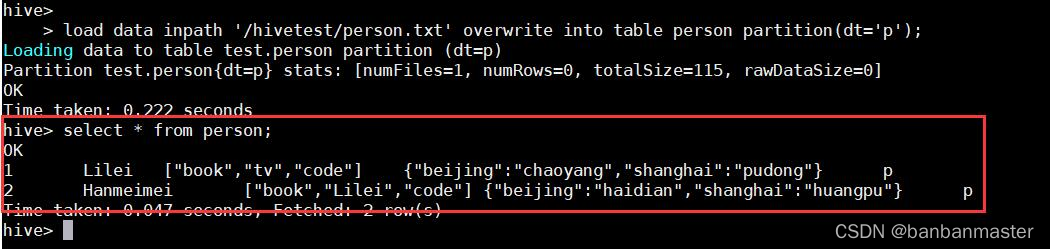
Array,Map数据类型都如期导入实现了
三、内部表和外部表区别
1.删除数据时删除外部表不会把文件删除
2.外部表可以存储数据到ES、HBase中(暂时验证了这个,其他以后再说)














 1698
1698











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









