







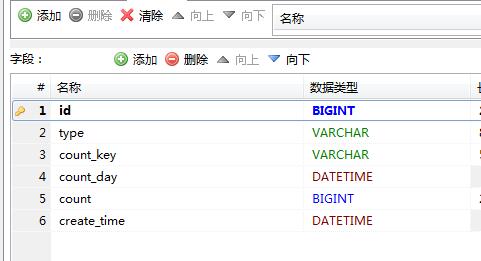
今天遇到一个问题是分组统计问题,表结构如下,我们的需求是按小时去聚合统计不同type和count_key的和。
这里可以用聚合函数:
SELECT type,count_key,count,DATE_FORMAT(count_hour,"%H") as hour FROM statistic_hourly GROUP BY type,count_key,DATE_FORMAT(count_hour,"%Y-%m-%d %H");这个脚本的意思就是唯一的type,count_key,小时下的count的和。
DATE_FORMAT是MySQL自带的时间转换函数,GROUP BY的意思就是对后面的字段进行分组,与前面的AVG,COUNT,SUM聚合函数等结合使用,对于GROUP BY后面的字段只会返回一行,聚合函数统计该组内字段的结果,WHERE子句是在分组前对数据进行筛选,GROUP BY … HAVING 是分组后的数据进行筛选。
1.WHERE 筛选 FROM 子句中指定的条件的行。
2.GROUP BY 用来分组 WHERE 子句的输出结果。
3.HAVING 用来从分组的结果中筛选行。















 1649
1649

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









