







一、目录
- 样本概述和说明
- 数据源
- 目标变量的定义
- 样本统计
- 数据可视化
- 特征工程
- 缺失值处理
- 同值化处理
- 业务相关性
- IV值筛选变量
- 皮尔森系数
- 最优分箱
- 等距分箱
- 卡方分箱
- 模型评估
- 准确率
- 召回率
- ROC曲线
- KS值
- 评分卡
- 模型结果
二、样本概述和说明
1.数据源
本文的数据源从Lending Club官方网站下载
开发数据集:2017.01-2017.06
验证数据集:2017.07-2017.09
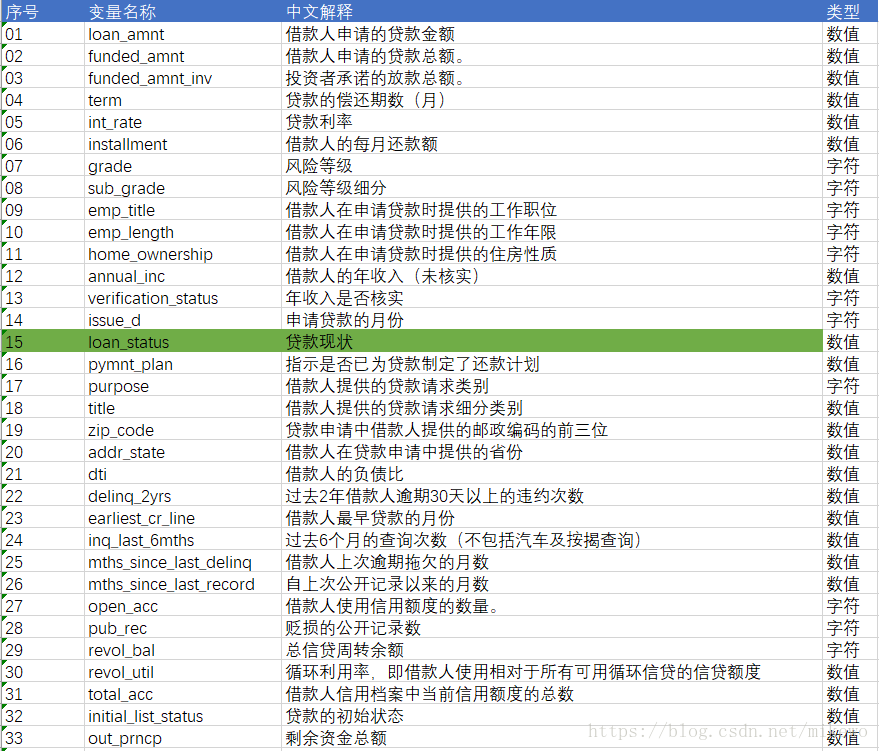
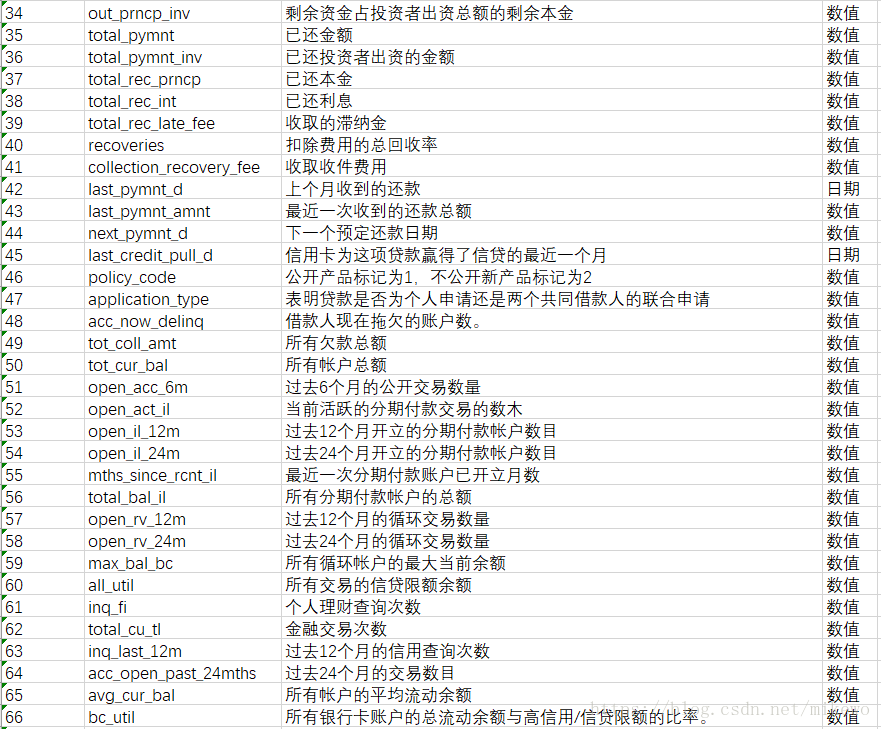
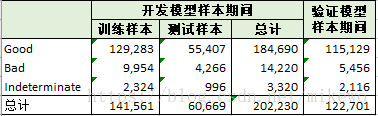
选取的开发数据集共计202234条数据,变量总数为145个,验证数据集共计122703条数据,变量总数为145个。其145个变量的部分解释如下:
2. 目标变量的定义
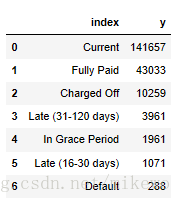
在释义中,绿色标注的就是目标变量,为了方便将其变量名标注为y,其变量名和统计个数如下:
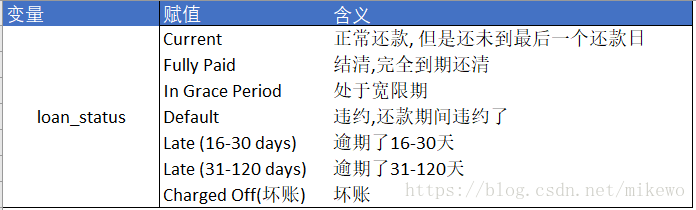
根据业务场景对其进行定义,一般逾期超过30天以上的客户定义为信用较差的客户,对于一些客户无法直接定义其信用的优劣,则将这部分不确定的客户,定义为信用中等的客户,具体的定义如下:

#定义新函数 , 给出目标Y值
def coding(col, codeDict):
colCoded = pd.Series(col, copy=True)
for key, value in codeDict.items():
colCoded.replace(key, value, inplace=True)
return colCoded
codeDict = {'Current':0,'Fully Paid':0,
'Late (31-120 days)':1,'Charged Off':1,
'Late (16-30 days)':2,'In Grace Period':2,'Default':2}
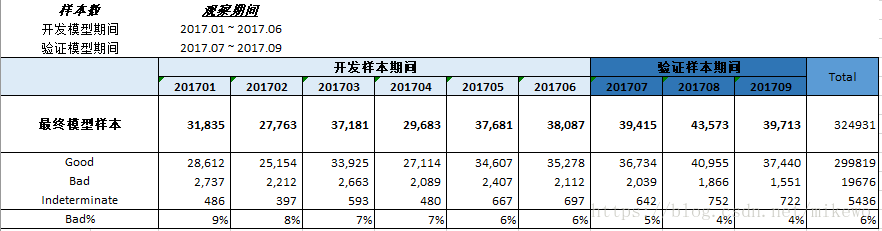
3. 样本统计
表现窗口:在时间轴上从观察点向后推得的表现窗口,用来提取目标变量和进行表现排除。
观察窗口:从观察点向前推一段时间得到观察窗口,用来提取自变量信息和进行观察窗口排除,观察窗口一般长度通常为6-12个月。
可以看出其特征值数量过大,需要进行有效的筛选,而且其坏样本的占比比较低,仅6-7%,在后续的处理中需要做不平衡样本处理。
4. 数据可视化
数据可视化可以比较直观的观察数据,对数据有一个整体的了解,在开发样本中,风险评估(grade)处于B和C的比较多,换言之,申请贷款的人风险评估大多数处于中等偏上。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1915
1915











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









