







HDFS文件写入与读写
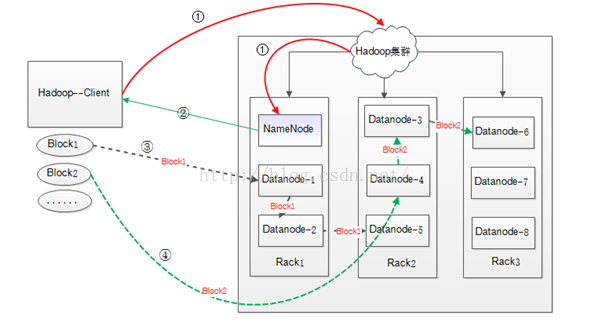
副本(3个)选择策略说明:
1. 若client为DataNode节点,那存储block时,规则为:副本1,同client的节点上;副本2,不同机架节点上;副本3,同第二个副本机架的另一个节点上;其他副本随机挑选。
2. 若client不为DataNode节点,那存储block时,规则为:副本1,随机选择一个节点上;副本2,不同副本1,机架上;副本3,同副本2相同的另一个节点上;其他副本随机挑选。
将一个100M的文件上传到HDFS中,Hadoop集群如上图所示的三个Rack,8个DataNode节点,集群配置采用默认配置。HDFS数据块的默认大小为64M,则该文件被分为两个BLOCK进行写入:Block1(64M)和Block2(36M)。
① Hadoop的Client向集群中的NameNode请求文件的写入(图中红色实线)
② NameNode节点接收到写入请求,记录block信息,并返回可用的DataNode节点。比如: Block1 : DataNode1——DataNode2——DataNode5
Block2 : DataNode4——DataNode3——DataNode6
需要说明的是:
(1) 如果上传本机不是一个datanode,而是一个客户端,那么就从所有slave机器中随机选择一台datanode作为第一个块的写入机器(datanode1)。
而此时如果上传机器本身就是一个datanode(例如mapreduce作业中task通过DFSClient向hdfs写入数据的时候),那么就将该datanode本身作为第一个块写入机器(datanode1)。
(2) 随后在datanode1所属的机架以外的另外的机架上,随机的选择一台,作为第二个block的写入datanode机器(datanode2)。
(3) 在写第三个block前,先判断前两个datanode是否是在同一个机架上,如果是在同一个机架,那么就尝试在另外一个机架上选择第 三个datanode作为写入机器(datanode3)。而如果datanode1和datanode2没有在同一个机架上,则在datanode2所 在的机架上选择一台datanode作为datanode3。
③Client接受到NameNode发送的可用DataNode列表(各个DataNode有排序,后面说明)之后,开始用流式的方式发送文件的Block,过程如下:
1 > 将block1(64M)划分为64k的packet;
2 > 然后Client将第一个64k的packet发送给DataNode1;
3 > DataNode1接收完后,将第一个packet发送给DataNode2,同时client向DataNode1发送第二个64k的packet;
4 > DataNode2接收完第一个packet后,发送给DataNode5,同时接收DataNode1发来的第二个packet;
5 > 以此类推,直到将block1发送完毕;
6 > DataNode1,DataNode2,DataNode5向NameNode发送“已完成”消息,DataNode1同时向Client发送完成通知;
7 > client收到DataNode1发来的消息后,向NameNode发送消息,表示已完成写入。
8 > 发送完block1后,再向DataNode4、DataNode3、DataNode6发送Block2,以此类推。
对③的说明:
NameNode根据Client的写入请求选取可用的DataNode节点,在NameNode返回该DataNode列表到客户端Client之前,会在NameNode端根据该写入客户端跟 DataNode列表中每个DataNode之间的“距离”由近到远进行一个排序。如果此时写入端不是DataNode,则选择DataNode列 表中的第一个排在第一位。客户端根据这个顺序有近到远的进行数据块的写入。在此,判断两个DataNode之间“距离”的算法就比较关键,hadoop目前距离计算如下:
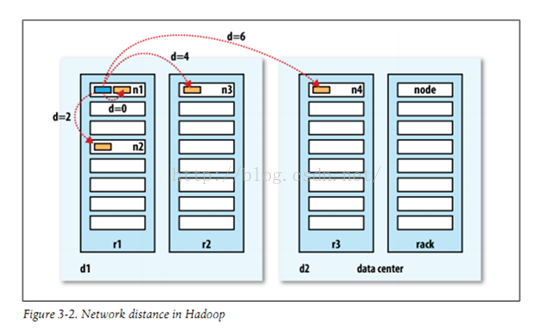
每个DataNode都会对应自己在集群中的位置和层次,如n1的位置信息为“/r1/n1”,那么它所处的层次就为2,其余类推。得到两个node的层次后,会沿着每个node所处的拓朴树中的位置向上查找,如“/r1/n1”的上一级就是“ /r1”,此时两个节点之间的距离加1,两个node分别同上向上查找,直到找到共同的祖先节点位置,此时所得的距离数就用来代表两个节点之间的距离。如上图所示,n2与蓝色所示DataNode(命名为node)之间的距离就为2(因为node:/r1/node,而n2:/r1/n2,,为了找到相同的祖先节点,二者需要各自向上级查找1位,即找到共同祖先节点为r1,则1+1=2),而n3则为4(同理)。
如下图所示为从源码角度对HDFS文件写入的程序控制流程的描述:
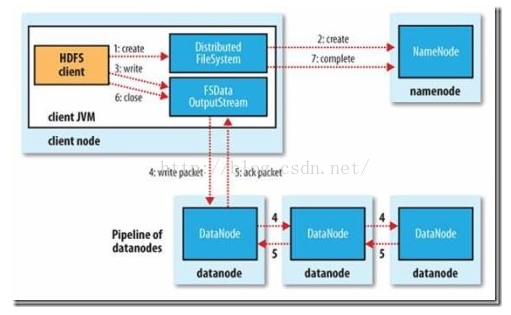
(1) 客户端通过调用DistributedFileSystem的create方法创建新文件。
(2)DistributedFileSystem通过RPC调用namenode去创建一个没有blocks关联的新文件,创建前,namenode会做各种校验,比如文件是否存在,客户端有无权限去创建等。如果校验通过,namenode就会记录下新文件,否则就会抛出IO异常。
(3)前两步结束后会返回FSDataOutputStream的对象,和读文件的时候相似,FSDataOutputStream被封装成DFSOutputStream,DFSOutputStream可以协调namenode和datanode。客户端开始写数据到DFSOutputStream,DFSOutputStream会把数据切成一个个小packet,然后排成队列data quene。
(4)DataStreamer会去处理接受data quene,他先问询namenode这个新的block最适合存储的在哪几个datanode里,比如重复数是3,那么就找到3个最适合的datanode,把他们排成一个pipeline。DataStreamer把packet按队列输出到管道的第一个datanode中,第一个datanode又把packet输出到第二个datanode中,以此类推。
(5)DFSOutputStream还有一个对列叫ack quene,也是有packet组成,等待datanode的收到响应,当pipeline中的所有datanode都表示已经收到的时候,这时akc quene才会把对应的packet包移除掉。
(6)客户端完成写数据后调用close方法关闭写入流
(7)DataStreamer把剩余得包都刷到pipeline里然后等待ack信息,收到最后一个ack后,通知datanode把文件标示为已完成。
补充:读取数据
当对某个文件的某个block进行读取的时候,hadoop采取的策略也是一样:
1.首先得到这个block所在的datanode的列表,有几个副本数该列表就有几个datanode。
2.根据列表中datanode距离读取端的距离进行从小到大的排序:
a)首先查找本地是否存在该block的副本,如果存在,则将本地datanode作为第一个读取该block的datanode
b)然后查找本地的同一个rack下是否有保存了该block副本的datanode
c)最后如果都没有找到,或者读取数据的node本身不是datanode节点,则返回datanode列表的一个随机顺序。














 392
392











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









