






 本文介绍了在MySQL中如何匹配包含中文的字符串,包括完全匹配中文的方法。讲解了HEX函数用于将字符串转换为十六进制以及UNHEX函数的用途。同时,讨论了使用REGEXP进行正则表达式匹配时的注意事项,强调了BINARY关键字在区分大小写匹配中的作用。
本文介绍了在MySQL中如何匹配包含中文的字符串,包括完全匹配中文的方法。讲解了HEX函数用于将字符串转换为十六进制以及UNHEX函数的用途。同时,讨论了使用REGEXP进行正则表达式匹配时的注意事项,强调了BINARY关键字在区分大小写匹配中的作用。
mysql匹配中文
匹配包含中文
select DiSTINCT pick_up, HEX(pick_up) hex
from back_query
where HEX(pick_up) REGEXP '^(..)*(E[4-9])';
结果:

完全匹配中文
select DiSTINCT pick_up, HEX(pick_up) hex
from back_query
where NOT (pick_up REGEXP "[u0391-uFFE5]");
结果:

HEX
hex:可以用HEX()函数将一个字符串或数字转换为十六进制格式的字符串
unhex:把十六进制格式的字符串转化为原来的格式,(转为控制字符,不是ASCALL值)图1
REGEXP
| 模式 | 描述 |
|---|---|
| ^ | 匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 ‘\n’ 或 ‘\r’ 之后的位置。 |
| $ | 匹配输入字符串的结束位置。如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 ‘\n’ 或 ‘\r’ 之前的位置。 |
| . | 匹配除 “\n” 之外的任何单个字符。要匹配包括 ‘\n’ 在内的任何字符,请使用象 ‘[.\n]’ 的模式。 |
| - | 范围,例如a-d ,则为abcd |
| […] | 字符集合。匹配所包含的任意一个字符。例如, ‘[abc]’ 可以匹配 “plain” 中的 ‘a’。 |
| [^…] | 负值字符集合。匹配未包含的任意字符。例如, ‘[^abc]’ 可以匹配 “plain” 中的’p’。 |
| p1|p2|p3 | 匹配 p1 或 p2 或 p3。例如,'z |
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 “z” 以及 “zoo”。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,‘zo+’ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z”。+ 等价于 {1,}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,‘o{2}’ 不能匹配 “Bob” 中的 ‘o’,但是能匹配 “food” 中的两个 o。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。 |
MySQL 的正则表达式匹配(自3.23.4版本后)不区分大小写(即大写和小写都匹配)。为区分大小写,可以使用 BINARY 关键字,例如:WHHERE name REGEXP BINARY ‘Hern .000’。
下图是ASCALL值与十六进制与控制字符对应的图。其中ASCLL值:左边是ASCLL值,右边是十六进制
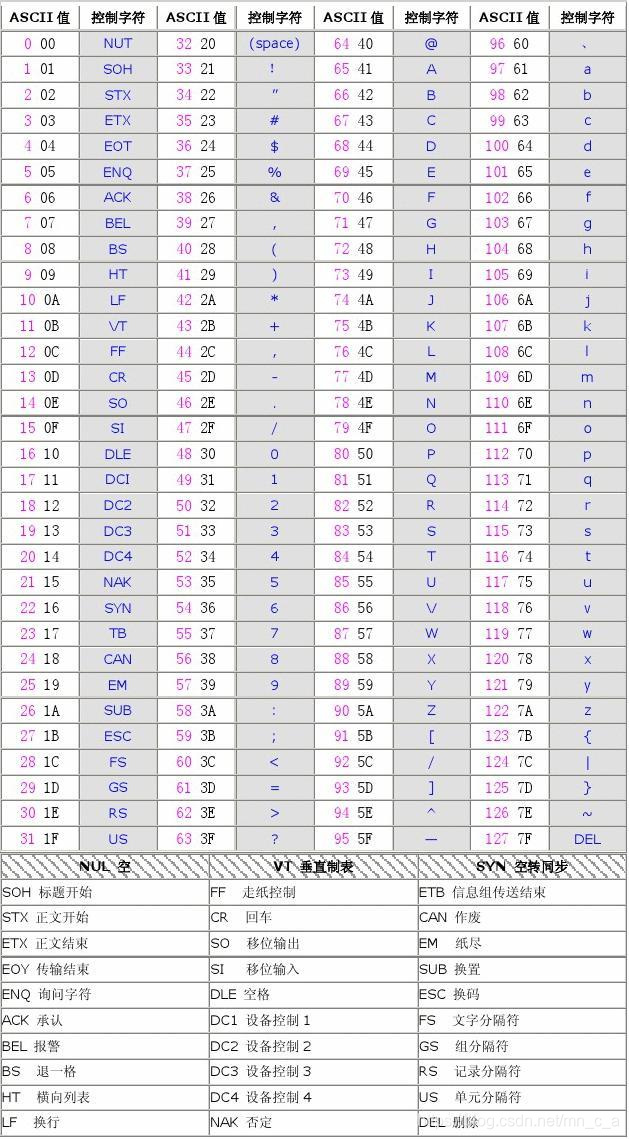 ↩︎
↩︎

















 1502
1502

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









