







CPU
在服务器上使用 lscpu 命令展示 CPU 相关架构信息。
# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 56
On-line CPU(s) list: 0-55
Thread(s) per core: 2
Core(s) per socket: 14
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
L1d cache: 32K
L1i cache: 32K
L2 cache: 4096K
…
NUMA node0 CPU(s): 0,2,4,6,8,10,12,14,16,18,20,22,24,26,28,30,32,34,36,38,40,42,44,46,48,50,52,54
NUMA node1 CPU(s): 1,3,5,7,9,11,13,15,17,19,21,23,25,27,29,31,33,35,37,39,41,43,45,47,49,51,53,55
Socket
Socket(s) 代表主板上的物理 CPU 个数,这里有两块 CPU。
Core
Core(s) per socket 代表每块 CPU 的物理核数,也就是日常说的单核、双核、多核,这里每块 CPU 有 14 核。
Thread
Thread(s) per core 代表每个物理核的硬件线程数,即超线程。现在主流的 CPU 处理器中,每个物理核通常都会运行两个超线程,也叫作逻辑核。Intel 官方数据显示,开启超线程一般情况下只能达到不开启状态下 30% 左右的性能提升。
这样 2*14*2 = 56 正好对上 CPU(s) 的 56,其中 56 代表的是逻辑核数。
L1、L2、L3
每个物理核都拥有私有的一级缓存(Level 1 cache,简称 L1 cache),包括一级指令缓存和一级数据缓存,以及私有的二级缓存(Level 2 cache,简称 L2 cache),同时每个 Socket 里的所有物理核共享三级缓存(Level 3 cache,简称 L3 cache)。
如上显示,L1d cache 和 L1i cache 说明一级数据缓存和一级指令缓存大小皆为 32K,L2 cache 大小为 4096K 即 4M。

Cache Line
上文提到的 L1、L2、L3 的基本单位是 Cache Line,默认为 64 Byte(也有的 CPU 用 32Byte 和 128Byte),也就是从主存(内存)加载数据不是一个字节一个字节的获取,而是以 Cache Line 为单位加载。比如 L1d cache 大小为 32K,那么就有 32K/64B 共 512 个 Cache Line。
# cat /sys/devices/system/cpu/cpu1/cache/index0/coherency_line_size
64
MESI
技术架构从单台到集群,遇到的一个必然的现象就是一致性的问题,这对 CPU 也亦然。CPU 进入多核时代,若一个变量被分别加载到不同核中,这势必涉及到缓存的一致性,对于主流的 CPU 来说,缓存的写操作基本上是两种策略。
- 写直达(Write-Through),写操作同时写到 Cache 和内存上。这个策略速度慢,毕竟 CPU 和内存 100ns 的速度差异。
- 写回(Write-Back),写操作只要在 Cache 上,然后再 flush 到内存上。主流 CPU 都采用此策略。

如上图,内存中变量 num 被两个核加载,其中一个已经被更新成 100,那么这时该如何同步到其他核中使数据都一致呢?
到这里,就引出这篇博文的第一个主题 MESI 协议。MESI 是一个写失效(Write Invalidate)协议,其主要表示缓存数据有四个状态:
-
Modified(已修改)
-
Exclusive(独占的)
-
Shared(共享的)
-
Invalid(无效的)。

如上述图中内存中的变量 num 为例, -
T1 时刻被 CPU 核心 0 加载,此时此 CPU 有 num 变量,因此 num 状态是 Exclusive;
-
T2 时刻被 CPU 核心 1 加载,此时由于有两个 CPU 核读取,因此 num 状态变为 Shared;
-
T3 时刻 CPU 核心 0 把 num 更新成 100,此时 CPU 核心 0 中 num 状态为 Modified,而 CPU 核心 1 中 num 的状态为 Invalid;
-
T4 时刻,变量 num 被 CPU 核心 0 写回到内存,此时,状态不变;
-
T5 时刻,变量同步到所有的 Cache 中,状态回到 Shared。
下面放张 MESI 状态转换图,细细体会。
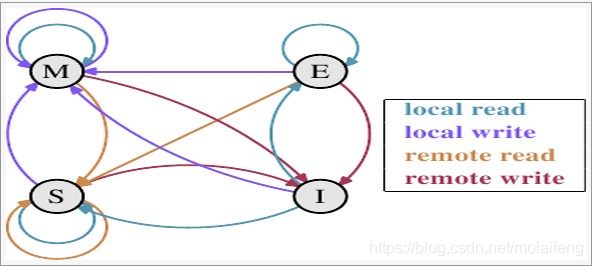
注:上面的 local read/write (本地读/写)就是在同一个 CPU Socket 里读写,remote read/write 就跨 CPU Socket 读写,可以参考上面 L1、L2、L3 那幅插图。
内存
FSB
在早些年里,电脑主板上是有北桥芯片的,CPU 通过 FSB(Front Side BUS,前端总线) 总线连接到北桥芯片,然后再连接到内存。

QPI
由于摩尔定律的影响,CPU 在主频到达 3GHz 后,逐渐到达硬件的极限,于是性能改进趋向纵向发展,改成向多核、多 CPU 方向发展。此时 CPU 制造商们把内存控制器从北桥搬到了 CPU 内部,这样 CPU 便可以直接和自己的内存进行通信了。那么,如果 CPU 想要访问不和自己直连的内存条怎么办呢?所以就诞生了新的总线类型,它就叫 QPI 总线。

SMP
SMP(Symmetric Multi-Processor),对称多处理器结构,是指服务器中多个 CPU 对称工作,无主次或从属关系,共享相同的物理内存,每个 CPU 访问内存中的任何地址所需时间是相同的,因此 SMP 也被称为一致存储器访问结构(UMA:Uniform Memory Access)。
由于每个 CPU 必须通过相同的内存总线访问相同的内存资源,因此随着 CPU 数量的增加,内存访问冲突将迅速增加,最终会造成 CPU 资源的浪费,使 CPU 性能的有效性大大降低。实验证明,SMP 服务器 CPU 利用率最好的情况是 2 至 4 个 CPU。

NUMA
NUMA(Non Uniform Memory Access),非一致性内存访问,在多 CPU 架构下,一个应用程序访问所在 Socket 的本地内存和访问远端内存的延迟并不一致,也把这个架构称为非统一内存访问架构(NUMA 架构)。
如果应用程序先在一个 Socket 上运行,并且把数据保存到了内存,然后被调度到另一个 Socket 上运行,此时,应用程序再进行内存访问时,就需要访问之前 Socket 上连接的内存,这种访问属于远端内存访问。和访问 Socket 直接连接的内存相比,远端内存访问会增加应用程序的延迟。
现代的服务器里,CPU 和内存条各有多个,目前主要采用的是 NUMA 架构进行互联,也就是把服务器里的 CPU 和内存分组划分成了不同的 node。
假设有 2 个 CPU Socket,每个 Socket 上有 6 个物理核,每个物理核又有 2 个逻辑核,总共 24 个逻辑核。我们可以执行 lscpu 命令,查看到这些核的编号:
# numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 12 13 14 15 16 17
node 0 size: 32756 MB
node 0 free: 19642 MB
node 1 cpus: 6 7 8 9 10 11 18 19 20 21 22 23
node 1 size: 32768 MB
node 1 free: 18652 MB
node distances:
node 0 1
0: 10 21
1: 21 10
可以看到,node0 的 CPU 核编号是 0 到 5、12 到 17,node1 的 CPU 核编号是 6 到 11、18 到 23,那么这些编号如何对应上述的 24 个逻辑核呢?
原来在 CPU 的 NUMA 架构下,对 CPU 核的编号规则,并不是先把一个 CPU Socket 中的所有逻辑核编完,再对下一个 CPU Socket 中的逻辑核编码,而是先给每个 CPU Socket 中每个物理核的第一个逻辑核依次编号,再给每个 CPU Socket 中的物理核的第二个逻辑核依次编号。

再来看看上述命令中 node distances 这个返回值, 是一个二维矩阵,描述 node 访问所有内存条的延时情况。 node 0 里的 CPU 访问 node 0 里的内存相对距离是 10,因为这时访问的内存都是和该 CPU 直连的。而 node 0 如果想访问 node 1 节点下的内存的话,就需要走 QPI 总线了,这时该相对距离就变成了 21。
注:这里的内存和 CPU 直连访问,就是上述 MESI 章节中的 local read/write,走 QPI 访问,就是 remote read/write,效率是不一样的。
因此,在 NUMA 架构下,CPU 访问自己同一个 node 里的内存要比其它内存要快。

最后聊聊 NUMA 架构下的内存陷进,如果服务器打开了 NUMA,NUMA 为了高效,会仅仅只从你的当前 node 里分配内存,只要当前 node 里用光了(即使其它 node 还有),也仍然会启用硬盘 swap。
当然了,这种情况不多见,而且需要在 zone_reclaim_mode 模式里调整控制。zone_reclaim_mode 模式是在 2.6 版本后期开始加入内核的一种模式,可以用来管理当一个内存区域(zone)内部的内存耗尽时,是从其内部进行内存回收还是可以从其他 zone 进行回收的选项,可以通过 /proc/sys/vm/zone_reclaim_mode 文件对这个参数进行调整。
- 0, 关闭 zone_reclaim 模式,可以从其他 zone 或 NUMA 节点回收内存;
- 1, 打开 zone_reclaim 模式,这样内存回收只会发生在本地节点内;
- 2, 在本地回收内存时,可以将 cache 中的脏数据写回硬盘,以回收内存;
- 4, 在本地回收内存时,表示可以用 Swap 方式回收内存。
# cat /proc/sys/vm/zone_reclaim_mode
0
运行中的进程在不绑定亲和性的话,当前进程在哪个 node 上的 CPU 发起内存申请,就优先在哪个 node 里分配内存。若是进程因 IO 调用而阻塞让出 CPU, 之后再唤醒,可能 CPU 就换了,比如之前在 CPU Socket 1 内,这时在 CPU Socket 2 中 。此时分两种情形,若是读取以前的内存,那么就会发起 remote read,若是申请新的内存,就会在当前 node 里分配。
numactl --cpunodebind=0 --membind=0 /usr/local/testNumaTask
若 zone_reclaim_mode 模式为 1,且绑定了 CPU 和内存的亲和性,那么当进程分配的内存持续增长并超过 node 里的内存限制时,此时便会发生 Swap,之后持续一会,就会被系统因 OOM 给 kill 掉。














 2686
2686











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









