









目录
主要内容

特征工程: 大神们怎么看
l Coming up with features is difficult, time-consuming, requires expert knowledge.
"Applied machine learning" is basically feature engineering.
——Andrew Ng
l Actually the success of all Machine Learning algorithms depends on how you
present the data.
——Mohammad Pezeshki
l …some machine learning projects succeed and some fail. What makes the
difference? Easily the most important factor is the features used.
——Pedro Domingos
l The algorithms we used are very standard for Kagglers. […] We spent most of our
efforts in feature engineering.
—— Xavier Conort
特征工程
o 特征 => 数据中抽取出来的对结果预测有用的信息
o 特征工程是使用专业背景知识和技巧处理数据, 使得特征能在机器学习算法上发挥更好的作用的过程。
意义
o 更好的特征意味着更强的灵活度
o 更好的特征意味着只需用简单模型
o 更好的特征意味着更好的结果
互联网公司机器学习的“真相”

数据与特征处理
数据采集

大多数情况下, 你的工作: 思考哪些数据有用
埋点和数据打标存储会有其他的同学做
数据格式化
数据清洗

数据清洗示例/思考角度

数据采样

正负样本不平衡处理办法

特征处理

特征处理之数值型

数值型特征Python处理


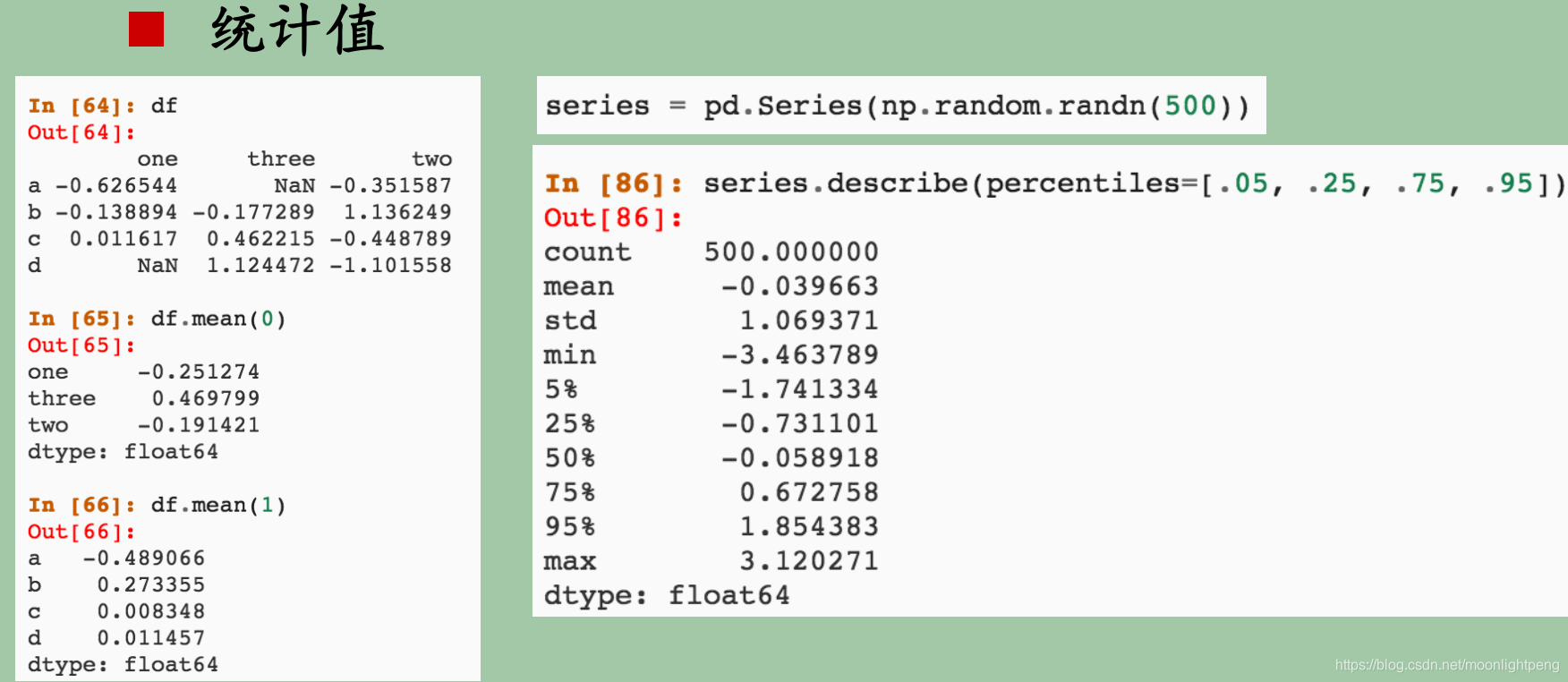
分位数,从大到小排序后,25%, 50%,的样本

原来是连续,现在离散,如果其值落在某个区段则其为1,其它为0
变为稀疏的离散的向量
pandas as pd
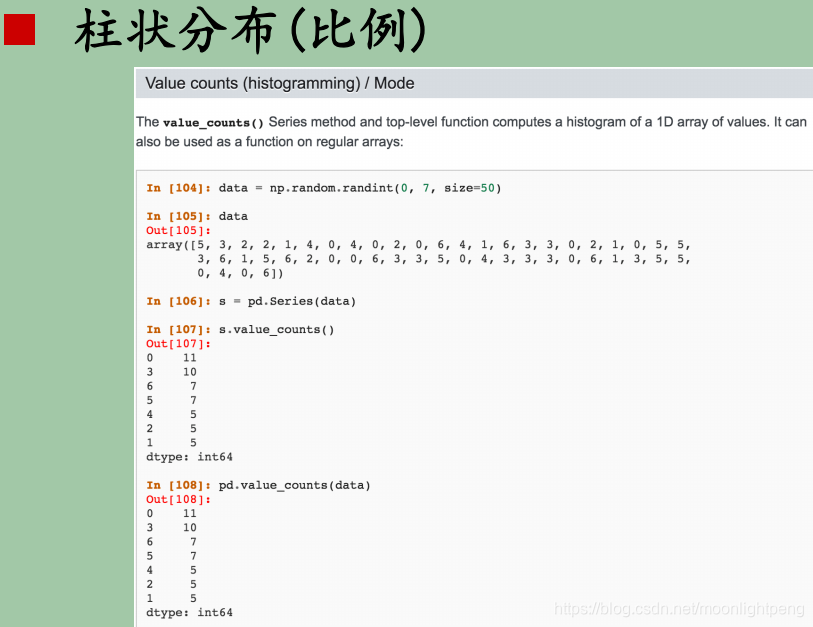
特征处理之类别型
o one-hot编码
o 哑变量
o Hash与聚类处理
o 小技巧:统计每个类别变量下各个target比例, 转成数值型
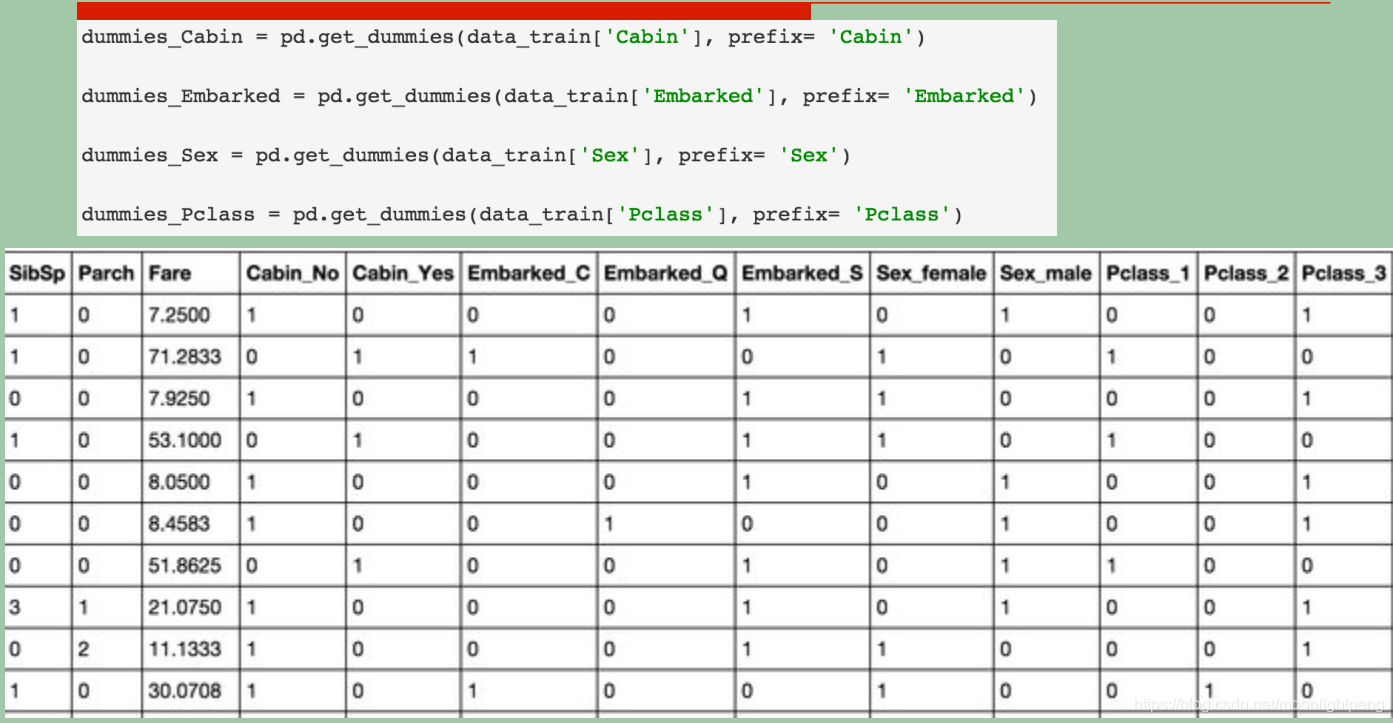
类别型特征Python处理: Hash技巧
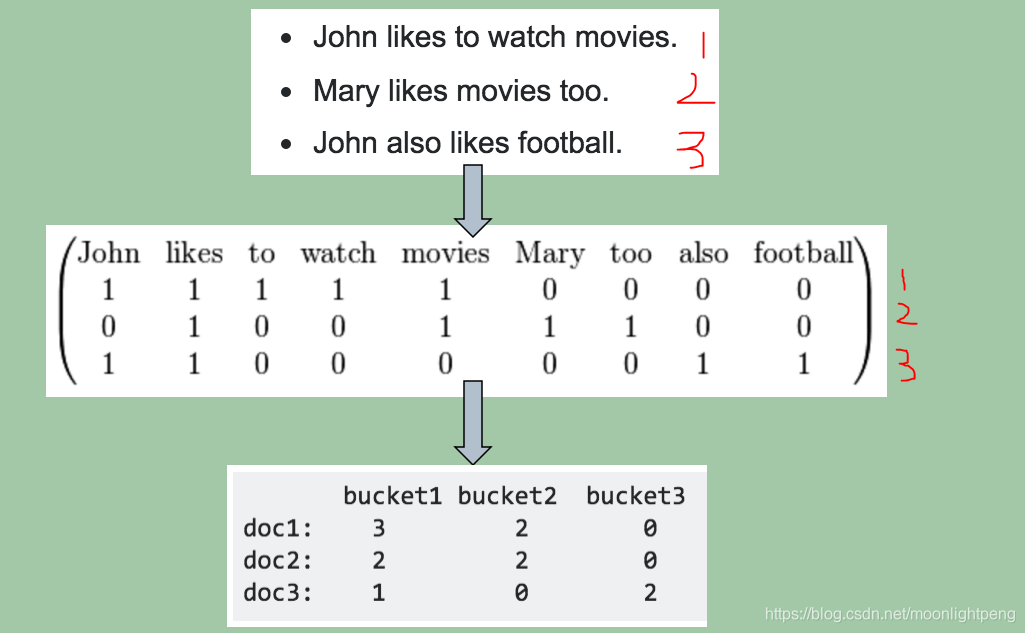
bucket是词集 word list
类别型特征Python处理: Histogram映射

【散步,足球, 看电视视】
特征处理之时间型

特征处理之文本型
词袋

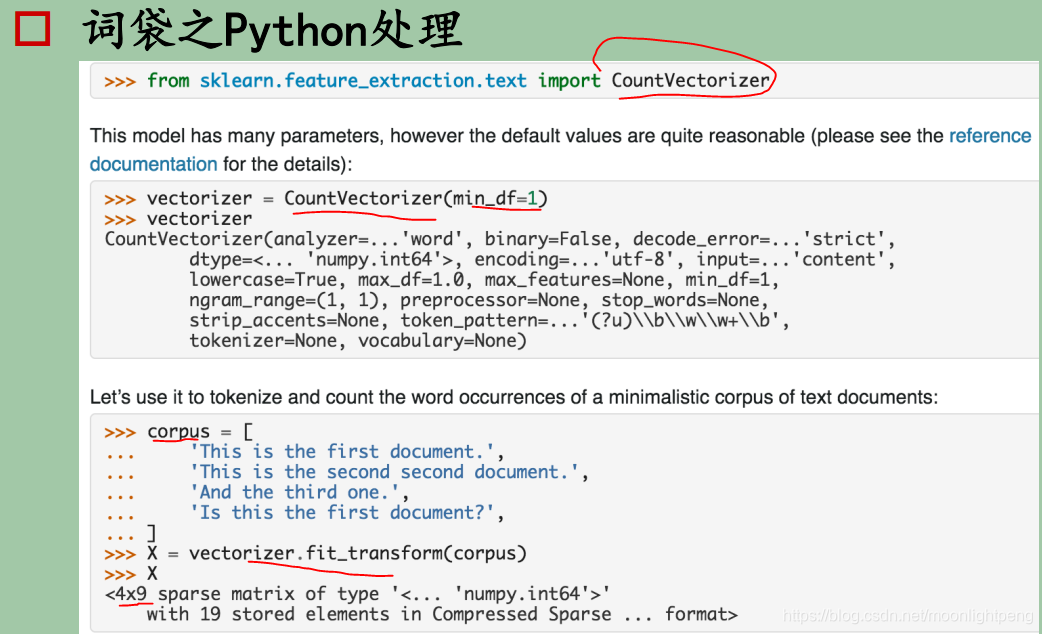
bags of words
把词袋中的词扩充到n-gram

n-gram, 将词语组合,放到里面
我很喜欢你
你很喜欢我
我,很喜欢,(很和喜欢组合),喜欢你(喜欢和你组合)
使用Tf–idf 特征
TF-IDF是一种统计方法, 用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。 字词的重要性随着它在文件中出现的次数成正比增加, 但同时会随着它在语料库中出现的频率成反比下降。

深度学习用的word2vec

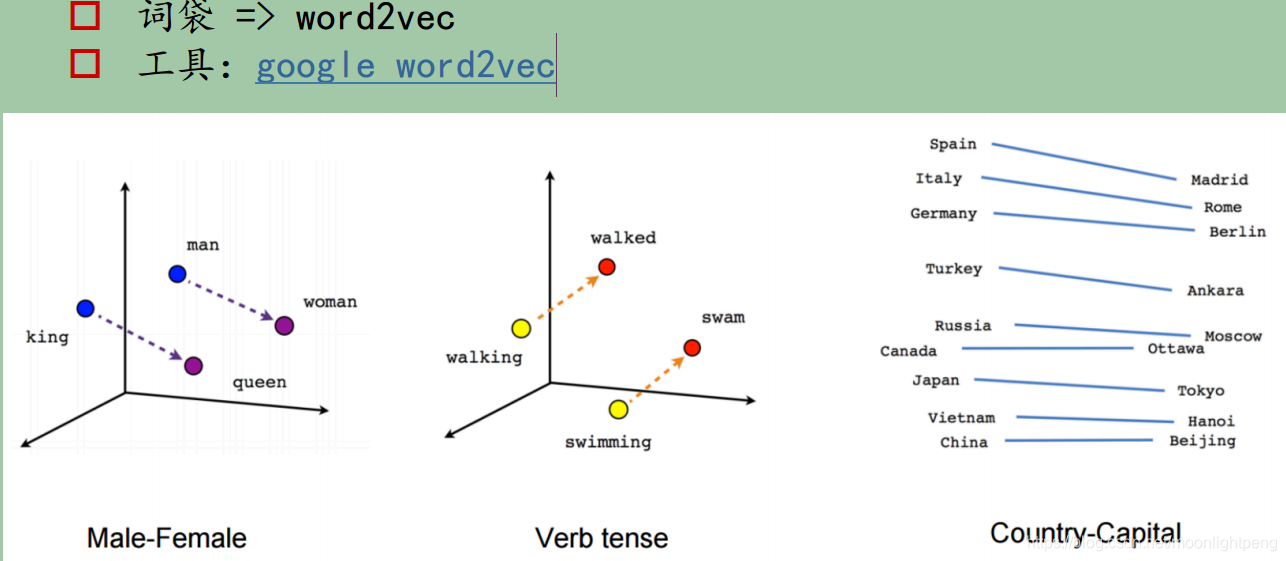
king和queen 与man和woman的关系类似,其距离差不多的,
word2vec能得到一个词相对于另一个词的特征
特征处理之统计特征

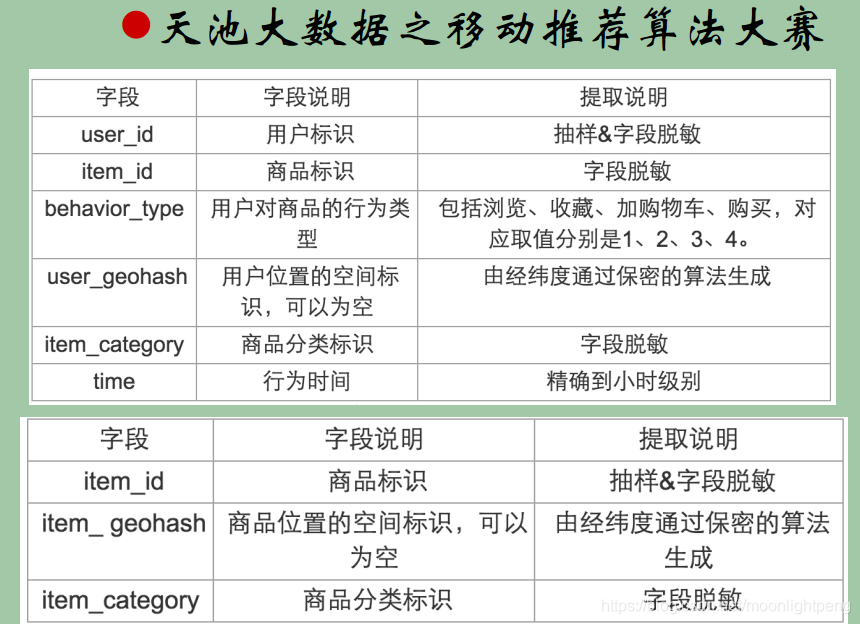
特征处理示例


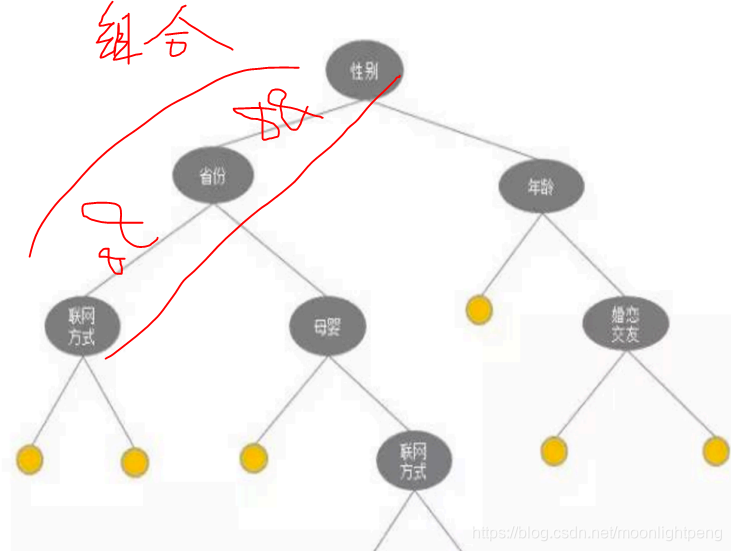
特征处理之组合特征

特征选择
o 原因:
冗余: 部分特征的相关度太高了, 消耗计算性能。
噪声: 部分特征是对预测结果有负影响
特征选择 VS 降维
前者只踢掉原本特征里和结果预测关系不大的, 后者做特征的计算组合构成新特征
SVD或者PCA确实也能解决一定的高维度问题
特征选择不会改变原来的特征
降维会做一些运算
常见特征选择方式之 过滤型

过滤型特征选择Python包

K的选择不好定,通过SelectPercentile设定百分比来确定
常见特征选择方式之 包裹型
把特征选择看做一个特征子集搜索问题, 筛选各种特征子集, 用模型评估效果。
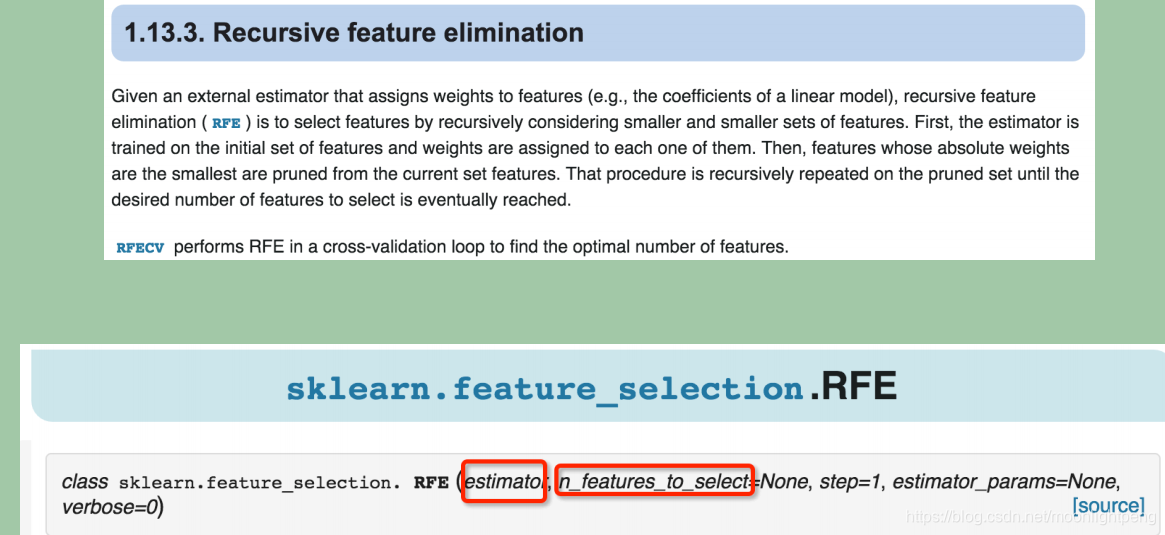
典型的包裹型算法为 “递归特征删除算法” (recursive feature elimination algorithm)
比如用逻辑回归, 怎么做这个事情呢?
① 用全量特征跑一个模型
② 根据线性模型的系数(体现相关性), 删掉5-10%的弱特征, 观察准确率/auc的变化
③ 逐步进行, 直至准确率/auc出现大的下滑停止
包裹型特征选择Python包

特征映射得到的如one-hot编码
常见特征选择方式之 嵌入型
根据模型来分析特征的重要性(有别于上面的方式,是从生产的模型权重等) 。
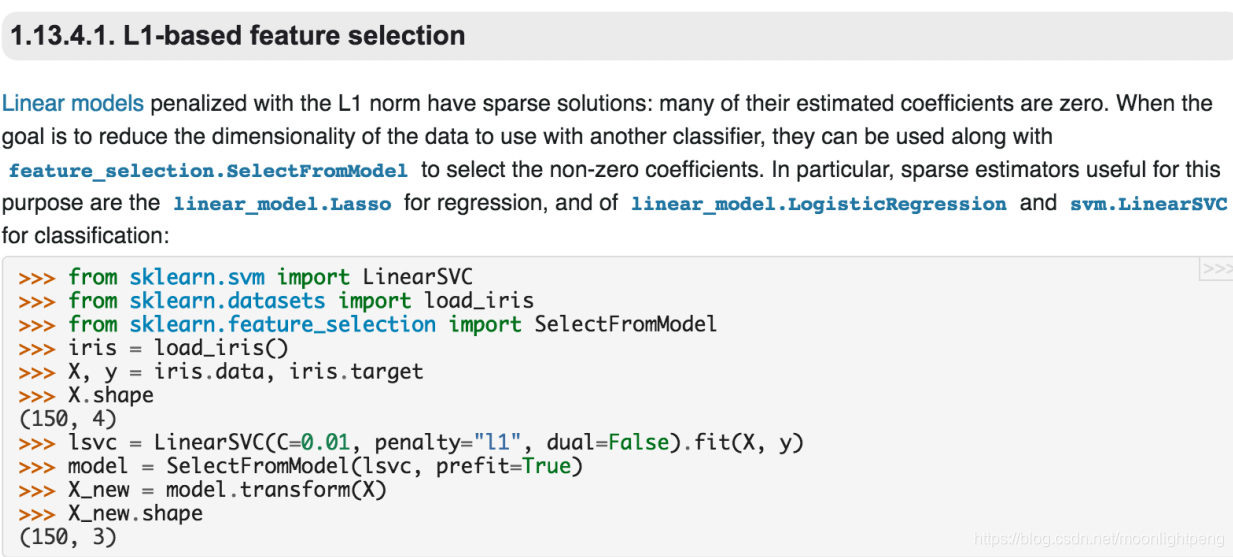
最常见的方式为用正则化方式来做特征选择。
举个例子, 最早在电商用LR做CTR预估, 在3-5亿维的系数特征上用L1正则化的LR模型。 剩余2-3千万的feature, 意
味着其他的feature重要度不够
theta0 + theta1*x1 + theta2*x2+-----+ thetan*xn
x1,x2----特征重要则theta大否则就小
L1截断性效应,不重要就不要了
L2是缩小
嵌入型特征选择Python包














 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









