






Spark 伪分布式 & 全分布式 安装指南
目录[-]
http://my.oschina.net/leejun2005/blog/394928
0、前言
3月31日是 Spark 五周年纪念日,从第一个公开发布的版本开始,Spark走过了不平凡的5年:从刚开始的默默无闻,到13年的鹊起,14年的大爆发。Spark核心之上有分布式的机器学习,SQL,streaming和图计算库。
4月1日 spark 官方正式宣布 Spark 2.0 对Spark重构,更好支持手机等移动终端。Databricks创始人之一hashjoin透漏了相关的重构方法:利用Scala.js项目把Spark代码编译成JavaScript,然后利用Safari / Chrome在手机上执行。一个代码可以支持Android / iOS。但是考虑到性能关系,可能需要重写底层的网络模块来支持zero-copy。(确定是否愚人节玩笑呢 :) )
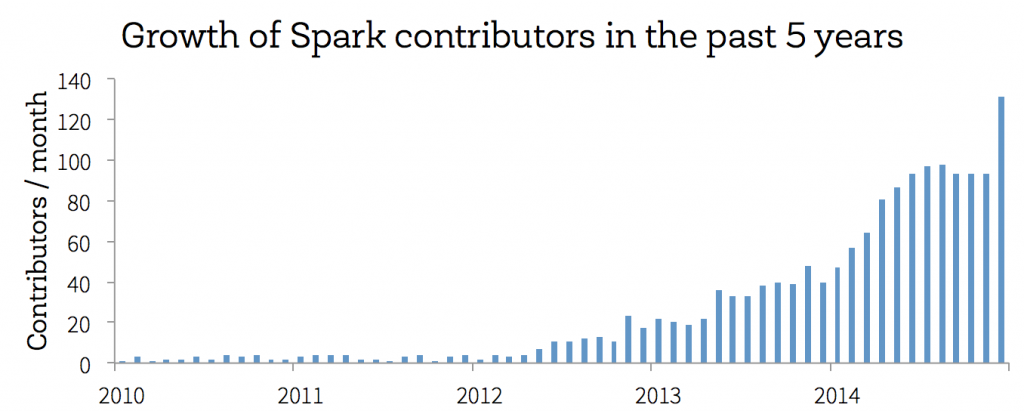
ok,言归正传。Spark目前支持多种分布式部署方式:一、Standalone Deploy Mode;二、Amazon EC2 ;三、Apache Mesos;四、Hadoop YARN。第一种方式是单独部署(可单机或集群),不需要有依赖的资源管理器,其它三种都需要将spark部署到对应的资源管理器上。

除了部署的多种方式之外,较新版本的Spark支持多种hadoop平台,比如从0.8.1版本开始分别支持Hadoop 1 (HDP1, CDH3)、CDH4、Hadoop 2 (HDP2, CDH5)。目前Cloudera公司的CDH5在用CM安装时,可直接选择Spark服务进行安装。
目前Spark最新版本是1.3.0,本文就以1.3.0版本,来看看如何实现Spark 单机伪分布式以及分布式集群的安装。
1、安装环境
Spark 1.3.0需要JDK1.6或更高版本,我们这里采用jdk 1.6.0_32;
Spark 1.3.0需要Scala 2.10或更高版本,我们这里采用scala 2.11.6;
记得配置下 scala 环境变量:
|
1
2
3
|
vim
/etc/profile
export
SCALA_HOME=
/home/hadoop/software/scala-2
.11.4
export
PATH=$SCALA_HOME
/bin
:$PATH
|
2、伪分布式安装
2.1 解压缩、配置环境变量即可
直接编辑 /etc/profile 或者 ~/.bashrc 文件,然后加入如下环境变量:
|
1
2
3
4
5
6
7
8
9
10
|
export
HADOOP_CONF_DIR=$HADOOP_HOME
/etc/hadoop
export
SCALA_HOME=
/home/hadoop/software/scala-2
.11.4
export
JAVA_HOME=
/home/hadoop/software/jdk1
.7.0_67
export
SPARK_MASTER=localhost
export
SPARK_LOCAL_IP=localhost
export
HADOOP_HOME=
/home/hadoop/software/hadoop-2
.5.2
export
SPARK_HOME=
/home/hadoop/software/spark-1
.2.0-bin-hadoop2.4
export
SPARK_LIBARY_PATH=.:$JAVA_HOME
/lib
:$JAVA_HOME
/jre/lib
:$HADOOP_HOME
/lib/native
export
YARN_CONF_DIR=$HADOOP_HOME
/etc/hadoop
export
PATH=$PATH:$SCALA_HOME
/bin
:$SPARK_HOME
/bin
|
2.2 让配置生效
source /etc/profile
source ~/.bashrc
2.3 启动spark
进入到SPARK_HOME/sbin下,运行:
start-all.sh
[root@centos local]# jps
7953 DataNode
8354 NodeManager
8248 ResourceManager
8104 SecondaryNameNode
10396 Jps
7836 NameNode
7613 Worker
7485 Master
有一个Master跟Worker进程 说明启动成功
可以通过http://localhost:8080/查看spark集群状况
2.4 两种模式运行Spark例子程序
2.4.1 Spark-shell
此模式用于interactive programming,具体使用方法如下(先进入bin文件夹)
|
1
2
3
4
5
6
7
8
9
10
|
./spark-shell
...
scala>
val
days
=
List(
"Sunday"
,
"Monday"
,
"Tuesday"
,
"Wednesday"
,
"Thursday"
,
"Friday"
,
"Saturday"
)
days
:
List[String]
=
List(Sunday, Monday, Tuesday, Wednesday, Thursday, Friday, Saturday)
scala>
val
daysRDD
=
sc.parallelize(days)
daysRDD
:
org.apache.spark.rdd.RDD[String]
=
ParallelCollectionRDD[
0
] at parallelize at <console>
:
14
scala>daysRDD.count()
scala>res
0
:
Long
=
7
|
2.4.2 运行脚本
运行Spark自带的example中的SparkPi,在
这里要注意,以下两种写法都有问题
./bin/run-example org.apache.spark.examples.SparkPi spark://localhost:7077
./bin/run-example org.apache.spark.examples.SparkPi local[3]
local表示本地,[3]表示3个线程跑
这样就可以:
|
1
2
3
4
5
6
|
.
/bin/run-example
org.apache.spark.examples.SparkPi 2 spark:
//192
.168.0.120:7077
15
/03/17
19:23:56 INFO scheduler.DAGScheduler: Completed ResultTask(0, 0)
15
/03/17
19:23:56 INFO scheduler.DAGScheduler: Stage 0 (reduce at SparkPi.scala:35) finished
in
0.416 s
15
/03/17
19:23:56 INFO spark.SparkContext: Job finished: reduce at SparkPi.scala:35, took 0.501835986 s
Pi is roughly 3.14086
|
3、全分布式集群安装
其实集群安装方式也很简单。
3.1 添加环境变量
|
1
2
3
4
5
6
7
8
9
10
11
|
cd
spark-1.3.0
cp
.
/conf/spark-env
.sh.template .
/conf/spark-env
.sh
vi
.
/conf/spark-env
.sh 添加以下内容:
export
SCALA_HOME=
/usr/lib/scala-2
.10.3
export
JAVA_HOME=
/usr/java/jdk1
.6.0_31
export
SPARK_MASTER_IP=10.32.21.165
export
SPARK_WORKER_INSTANCES=3
export
SPARK_MASTER_PORT=8070
export
SPARK_MASTER_WEBUI_PORT=8090
export
SPARK_WORKER_PORT=8092
export
SPARK_WORKER_MEMORY=5000m
|
SPARK_MASTER_IP这个指的是master的IP地址;SPARK_MASTER_PORT这个是master端口;SPARK_MASTER_WEBUI_PORT这个是查看集群运行情况的WEB UI的端口号;SPARK_WORKER_PORT这是各个worker的端口号;SPARK_WORKER_MEMORY这个配置每个worker的运行内存。
-
vi ./conf/ slaves 每行一个worker的主机名(最好是用 host 映射 IP 成主机名),内容如下:
10.32.21.165
10.32.21.166
10.32.21.167
-
设置 SPARK_HOME 环境变量,并将 SPARK_HOME/bin 加入 PATH:
vi /etc/profile ,添加内容如下:
export SPARK_HOME=/usr/lib/spark-1.3.0
export PATH=$SPARK_HOME/bin:$PATH
然后将配置以及安装文件同步到各节点上,并让环境变量生效。
3.2 启动spark集群
执行 ./sbin/start-all.sh
如果start-all方式无法正常启动相关的进程,可以在$SPARK_HOME/logs目录下查看相关的错误信息。其实,你还可以像Hadoop一样单独启动相关的进程,在master节点上运行下面的命令:
在Master上执行:./sbin/start-master.sh
在Worker上执行:./sbin/start-slave.sh 3 spark://10.32.21.165:8070 --webui-port 8090
然后检查进程是否启动,执行jps命令,可以看到Worker进程或者Master进程。然后可以在WEB UI上查看http://masterSpark:8090/可以看到所有的work 节点,以及他们的 CPU 个数和内存等信息。
3.3 Local模式运行demo
比如:./bin/run-example SparkLR 2 local 或者 ./bin/run-example SparkPi 2 local
这两个例子前者是计算线性回归,迭代计算;后者是计算圆周率
3.4 shell 交互式模式
./bin/spark-shell --master spark://10.32.21.165:8070 , 如果在conf/spark-env.sh中配置了MASTER(加上一句export MASTER=spark://${SPARK_MASTER_IP}:${SPARK_MASTER_PORT}),就可以直接用 ./bin/spark-shell启动了。
spark-shell作为应用程序,是将提交作业给spark集群,然后spark集群分配到具体的worker来处理,worker在处理作业的时候会读取本地文件。
这个shell是修改了的scala shell,打开一个这样的shell会在WEB UI中可以看到一个正在运行的Application
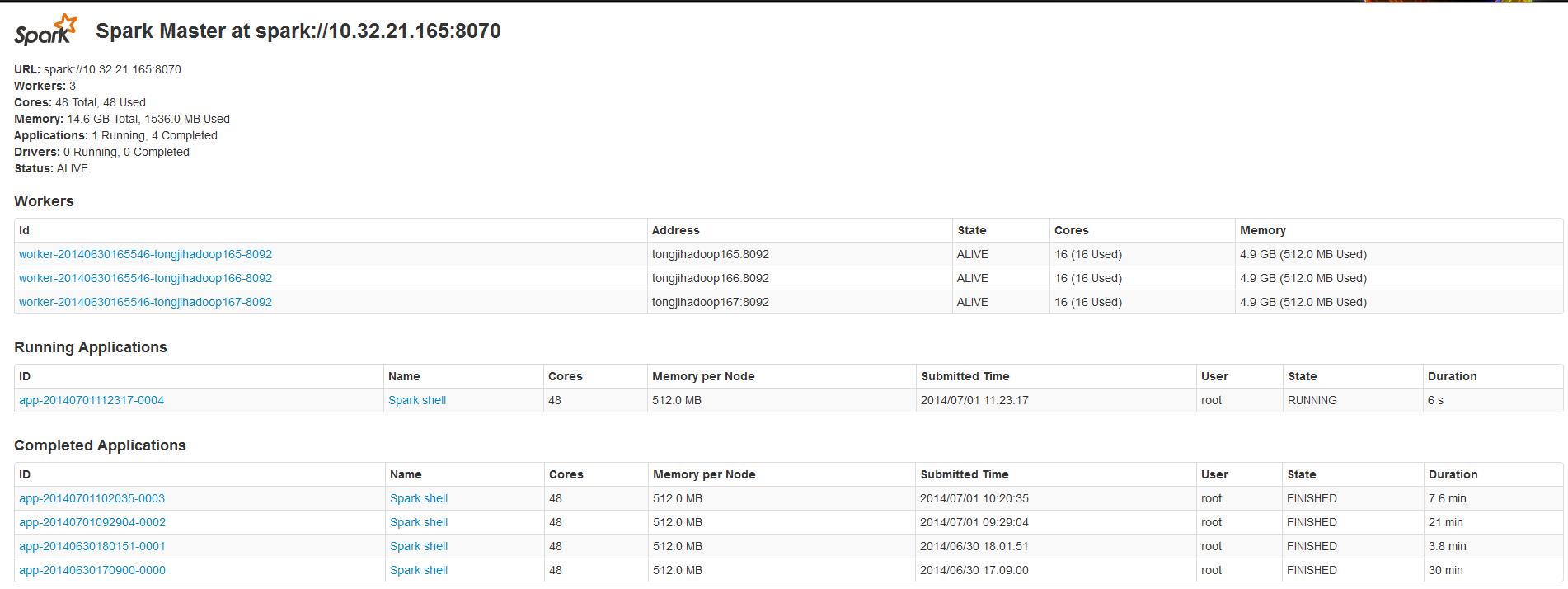
4、一个 scala & spark 例子
这个例子首先用 shell 生成 150,000,000 个随机数,然后用 spark 统计每个随机数频率,以观察随机数是否均匀分布。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
getNum(){
c=1
while
[[ $c -
le
5000000 ]]
do
echo
$(($RANDOM
/500
))
((c++))
done
}
for
i
in
`
seq
30`
do
getNum > ${i}.txt &
done
wait
echo
"--------------- DONE -------------------"
cat
[0-9]*.txt > num.txt
|
|
1
2
3
4
5
|
val
file
=
sc.textFile(
"hdfs://10.9.17.100:8020/tmp/lj/num.txt"
)
val
count
=
file.flatMap(line
=
> line.split(
" "
)).map(word
=
> (word,
1
)).reduceByKey(
_
+
_
)
//count.collect().sortBy(_._2)
//count.sortBy(-_._2).saveAsTextFile("hdfs://10.9.17.100:8020/tmp/lj/spark/numCount")
count.sortBy(
_
.
_
2
).map(x
=
> x.
_
1
+
"\t"
+ x.
_
2
).saveAsTextFile(
"hdfs://10.9.17.100:8020/tmp/lj/spark/numCount"
)
|
|
1
2
3
4
5
6
7
8
9
10
11
12
|
hadoop fs -
cat
hdfs:
//10
.9.17.100:8020
/tmp/lj/spark/numCount/p
*|
sort
-k2n
65 1228200
55 2285778
59 2285906
7 2286190
24 2286344
60 2286554
37 2286573
22 2286719
...
13 2291903
43 2292001
|
5、题外话:拥抱 Scala
scala 如下几个特性,或许值得你去学习这门新语言:
-
它最终也会编译成Java VM代码,看起来象不象Java的壳程序?- 至少做为一个Java开发人员,你会松一口气
-
它可以使用Java包和类 - 又放心了一点儿,这样不用担心你写的包又得用另外一种语言重写一遍
-
更简洁的语法和更快的开发效率 - 比起java臃肿不堪的指令式语言,scala 函数式风格会让你眼前一亮
-
spark 在 scala shell 基础之上提供交互式 shell 环境让 spark 调试方便,比起笨重的 Java MR,一念天堂一念地狱。
6、Refer:
[1] 在Hadoop2.2基础上安装Spark(伪分布式)
http://www.cnblogs.com/kxdblog/p/4345356.html
[2] Spark一:Spark伪分布式安装
http://bit1129.iteye.com/blog/2171761
[3] Spark-1.0.0 standalone分布式安装教程
http://www.cnblogs.com/lxf20061900/p/3819499.html
[4] namenode元数据管理进程端口号获取:
http://10.9.17.100:50070/dfshealth.html#tab-overview
http://blog.cloudera.com/blog/2009/08/hadoop-default-ports-quick-reference/
http://docs.hortonworks.com/HDPDocuments/HDP1/HDP-1.3.7/bk_using_Ambari_book/content/reference_chap2_2x.html














 1779
1779











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









