






看这篇文章时正值高考季,AI大热的今天,人工智能参加高考的消息也偶见新闻报道,但也没注意到到底达到了什么程度,能够拿多少分。想来技术还未完全成熟,高考题目千变万化要完全攻克应该还需不少技术发展创新吧。那么,AI参与高考到底要涉及到哪些技术方法呢?这是一个有趣的问题,带着兴趣我们来学习一下这篇文章。
文章所做的工作是对机器参与高考的一个初步尝试,主要注重于对高考中单项选择题的解决方法。文章提出了一种“三级策略”,分为三步利用并扩展了信息检索技术找出正确答案。求解答案的知识库来源于维基百科,首先用字符串匹配和基于上下文消除歧义的方法,从维基百科中获取到和疑问相关的页面。然后用多重的排名和过滤方法找出最能决定答案的页面。最后用基于相关的蕴含方法对每一个选项进行评估,找出最佳的选项。实验用了历年来真实的历史高考题目作为实验数据,相比依靠猜测25%的正确率,文章提到的方法的实验结果远胜于此,已经取得了足够鼓舞人心的成绩。
文章注重于对高考历史单选题的自动答题方法的研究,选取如下例子进行说明。图1 是原文截图,是对一上海高考历史题的英文翻译,其中画线部分表示这是对古汉语的翻译。图右是我找到的原题和它的解释。

图1

图 2
可以看出,单选题的题目可能是很复杂的,一个题目会包含几个句子,而且会以一些背景句子开头,如该题中荀子的话,这些背景句对于理解题目和选择答案是不可缺少的。如例题中的背景句给出了之后提出问题的句子中,是给予同姓亲属土地和人口的答案(立七十一国,立国即分土地)。但是背景句往往是古文经典,是很难被理解的。而且与答案就在给出的文本里的阅读理解不同,高考中的单选需要搜索许多外部的资源使用。对于例题,它考察的是考生是否知道周朝的分封制度,主要是由土地和人口组成的,这一点是不会在题干中给出的。
鉴于这么多与众不同的特征,文章提出了要采用一种三级架构的方法来解决问题。第一步,和问题相关的知识需要从存储器中检索出来,文章中的存储器指的是维基百科,文章需要检索出两类页面:“概念页”和“引用页”。第二步,文章涉及到三种策略,要用多重策略对第一步检索到的页面进行排名和过滤,评估它们的有效性,过滤掉非解释问题本质,排名靠后的页面,得到可以证明答案的页面。第三步,在分析第二步获得的可以证明答案的页面上,剩余的页面内容将在一定程度上蕴含各选项,分析每一个选项,分析出最可能正确的答案。
为了能够获取到可以回答问题q知识,需要从维基百科中检索到两类不同的匹配问题q的页面,一种是概念页面,另一种是引用页面。
一些出现在问题q中的概念会提供解决问题的重要线索,例如例题中的西周和受封。在维基百科中可以获取到标题中含有这些概念的网页,我们称之为“概念页”。文章采用了简单而又高效的“最左最长法则”(leftmost longest principle),匹配维基百科页面中可以和问题q匹配的标题。算法重复地搜素能够和题干Sq最左最长匹配的页面标题,同时要排除掉预定义在stopword(解释见文章最后)列表中的词汇。这样就能够获取到概念页面集合Pc(Sq),类似的对Qq中的每一个选项o进行同样的过程,获得集合Pc(o)。算法和算法流程图如下所示:


检索到的概念页面并不都能直接用于回答问题,其中有可能包含了两类维基百科的页面,一种是“消歧义页面”,另一种是“重定向页面”。这两种页面不能直接用于寻找答案,需要被替换成其他页面。
首先来看看消歧义页面。一个概念名称可能是模棱两可的,例如封建主义在不同的国家就有着不同的形式,也就有了不同的概念。所以检索一个这样模棱两可的概念名时,得到的常常是消歧义页面。如同下图所示,搜索到的页面中没有对概念的详细消歧义,只是给出了到其他描述相同概念名页面的链接。

图 3
上图是我将原题中带有的“分封"一词,拿到维基百科搜索到的结果,这是一个消歧义页面。可以看到搜索的结果中对”分封“这个概念没有详细的解释,因为分封是一个模棱两可的词,不同国家的分封是有不同含义的,所以检索到的页面是一个消歧义页面,有对模糊的概念词各种简短的解释,在解释中存在的蓝色字是为了消除歧义,对概念词详细解释而链接到其他页面。因此,为了得到对需要查询的概念词的详细准确的解释,需要用消歧义页面中一个链接到的页面替换了消歧义页面。对此文章中采用的方法是,结合其他出现在问题q中的概念词作为上下文信息来消除歧义。
下面将要正式开始介绍消歧的方法。用cn表示一个出现在问题q中的概念词,dp(cn)表示检索到的标题含有概念词cn的消歧义页面,消歧义页面中含有的链接,链接到消除歧义页面集合P(cn)。我们需要做的是用P(cn)集合中的一个页面p代替dp(cn)。PT(cn)表示其他用”最左最短算法“检索出的页面标题集合。用abstr(p)表示概念页面p的摘要,用body(p)表示概念页面p的正文。用sd(p)表示消歧义页面中链接到页面p时用到的简短说明。tf(pt,t)表示一个页面的标题pt出现在文本t中的次数,也就是词频。我们要用集合P(cn)中的一个页面p替代dp(cn),目标是用一个得分公式评价出P(cn)集合中每个页面的得分,并取出最高得分的页面替换dp(cn)。得分公式如下
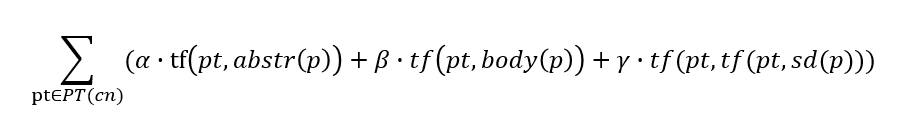
其中α,β,γ∈[0,1],文章作者在实验中分别取值为0.8,0.5,1。pt表示用“最左最长匹配”从问题q中得到的标题之一,也就是存有歧义的概念词cn的上下文信息。要做到选择出一个最合适的页面p,也就是要做到选择出和问题q中概念词cn意思最接近的一个页面,很容易想到问题q中和cn共同出现的概念词在页面p中也同样共同出现的话,那么这个页面与问题q很可能更相关。如果共现的概念词在文章中的地位还更高的话,也就是在摘要或者链接描述上出现,那么这个词与问题q更加相关。文章通过用比较上下文信息pt在页面p的摘要、正文、链接描述中出现的次数来确定哪一个页面与cn真实的解释最接近,次数越多的越接近。
还有一种页面是重定向页面。有的页面只会简单的将读者链接到其他页面而不会提供其他任何信息,这种页面就需要用它链接到的页面替换了它。例如下图所示,在维基百科中搜索“分封”,它将不会给出任何和“分封”有关的信息,只会给出一个和它相关“封建”的信息,这时就要重定向到“封建”并用重定向后的页面代替原页面。而“封建”的搜索结果是一个消歧义页面,也就是图3所示的页面,其中有“封建”在中国、日本、马克思中的不同解释。题目中封建显然是在中国的封建,我们作为人很容易会选择“中国”相关的链接到的页面来替换该消歧义页面,但是机器要做到这一点,需要用上述页面消歧方法,即通过评分算法比较出“中国”链接到的页面的内容和简短描述中的很多概念词与问题q中的相同,例如其中提到了周代,所以选择这个页面来替换消歧义页面。

在高考的多门考试中,引用常常会出现,如同例题中的引用了荀子的话。而且最令人头疼的是这些引用往往是古汉语,含义十分模糊很难理解。在维基百科中可以获得到和应用准确匹配的页面,这些页面就是“引用页面”。定义在题干Sq中用引号标记的文本为引用,要检索的引用页面就是要能够最多数量的和题干中的引用相匹配。题干Sq的引用页面标记为PQ(Sq)。对于Oq中的每一个选项o都执行类似的操作,得到引用页面PQ(o)。如果选项中没有引号,就把整个选项当作一个引用去检索。
首先,文章把用两种方式检索到的页面按照题干和选项整合成了一个集合,也就形成了题干Sq的检索页面集合PR(Sq),单个选项的检索页面集合PR(o),所有选项的检索页面集合PR(Oq)。定义如下公式,其中PC()表示用检索概念页面的方法检索到的概念页面集合,PQ()表示用检索引用页面的方式检索到的页面。
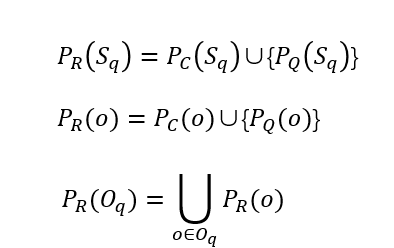
但是这些检索得到的这些页面并不都是对于回答问题q有用的信息,其中可能包含了噪声,有的页面甚至干扰了其他页面给出正确的答案,因此要对页面集合进行过滤。文章提出了三种排名策略用来过滤页面,分别是基于向心性的策略,基于领域的策略,基于相关性的策略。
首先分析考题我们可以知道,高考的问题主要注重一个考察点,一个特定的主题,所以要评价一个页面好不好,可以通过考察这个页面的内容和主题是否相似来确定。文章中用被检索到的n个页面的在向量空间的中心表示主题,用余弦相识度评价每个页面到中心的距离。下面给出具体公式,pi是一个检索到的页面,F(pi)表示由pi转化来的一个向量,那么评价函数如下:
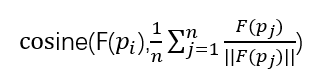
接下来要讨论的就是如何定义向量F(pi)了。文章用了基于词、链接、类别的三种定义方式,三种方式的效率作者通过实验比对而出。
基于词的向量F(pi)定义其实就是信息检索中经常用到的TF-IDF方法,如果一个词语在一篇文章中出现次数越多(TF越大), 同时在所有文档中出现次数越少(IDF越大), 越能够代表该文章。向量F(pi)中的每一个维度都是一个从页面经过分离得到的词wi在文件中的TF-IDF得分,问题q分离出的所有词在页面pi的TF-IDF得分组合成一个向量。计算公式如下,其中tf(wj,pi)表示词wj在文章pi中出现的次数,dfW(wj)表示维基百科中出现词wj的页面的总数,N表示维基百科页面的总数。
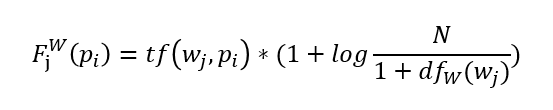
第二种方法是基于页面pi中链接到其他页面的数量来考虑。向量的每一个维度都相当于是一个分离出来的链接,并且它的值也是通过一个类似TF-IDF的公式计算的。计算公式如下,其中tf(lj,pi)表示链接lj在文章pi中出现的次数,dfL(lj)表示维基百科中出现链接lj的页面的总数,N表示维基百科页面的总数。
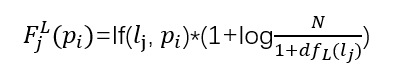
第三种是基于考虑页面pi所属的类别,向量的每一维度表示一个分离开了的类别,它的值的计算方法来源于IDF。计算公式如下,其中dfC(cj)表示维基百科中属于类别cj以及属于类别cj子类的页面总数,N表示维基百科页面的总数。
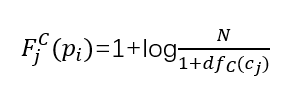
用上述三种方法之一,我们可以获得到一个页面pi的特征向量。将页面表示到向量空间后,我们可以方便的用余弦定理计算出页面与页面中心的相似度,也就是得到了一个页面的评分,将评分低的页面淘汰是对页面集合的一种过滤过程。
这个策略很简单,如果已知问题q是属于一个特殊的领域,例如例题是高考历史中的题目,毫无疑问是属于历史领域,那么在检索这道题的答案啊的时候,就可以毫无疑问的把不属于历史这类的页面给过滤了。所谓属于历史类别的类是指所有类别名中包含了“历史”一词的类,以及他们的子类。
这里考虑的相关性是指题干和选项的相关性。一个页面能否给出问题的答案,最直观的就是看这个页面的内容是否即包括了题干的内容,也包括了选项的内容,这样的页面很可能就是对提问的知识点进行解释。所以一个检索页面如果既包含了题干sq也包含了选项O的话,可以认为这个页面是有用的。因此我们需要计算一个页面pi中题干sq和选项O之间的相关度,基于相关度来过滤页面。这里用到的相似度算法也是类似于余弦相似度,不同的是评价一个页面pi,既要考虑它与选项Oq的相似度,也要考虑它与题干sq的相似度。余弦相似度中用到的特征向量是通过上文提到的基于词的向量Fjw(pi)求得的。计算相关性的公式如下:
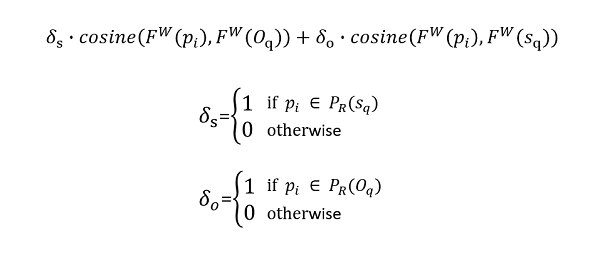
这个公式很有意思,它分别计算了页面pi和选项Oq,页面pi和题干sq之间的相似性,但是如果仅仅是页面与题干相似度高,或者仅仅是页面与问题相似度高这都是不够的,必须要页面中同时与题干和页面都相似才能有高的相关性得分。公式由相似的两项组成,一个由题干sq检索而来的页面,这个页面首先是和题干sq相似性比较大的,这时就需要用余弦相似度公式计算它与选项Oq的相似性大不大,如果与选项Oq的相似性很小,那么这个页面在这一项上的相关性得分就不高。如果一个页面并非从题干sq检索而来,那么即使它与选项相似性高也无法提供任何相关性得分。如果一个页面既能从题干sq检索出,也能从选项Oq检索出,那么它就很可能有高的相关性得分。
用PF(Sq)和PF(o)表示用上述的方法结合后过滤留下的页面(PF(Sq)∈PR(Sq),PF(o)∈PR(o))。那么,通过评估问题q在页面PF(Sq)和PF(o)的内容的蕴含程度,可以选择出一个最可能正确选项。
文章系将蕴含分为两个方点考虑。一是题干Sq和选项o的结合在Sq和PF(Sq)的蕴含程度,另一个是题干Sq和选项o的结合在o和PF(o)的蕴含程度。假定两方面是独立的,取消两方面的相同因素,评估方式变成测量以下两点:
1、选项o蕴含在剩余的由提干Sq检索出的页面集合PF(Sq)的程度。
2、题干Sq蕴含在剩余的由选项o检索出的页面集合PF(o)的程度。
最后,用相关性度量来表示蕴含程度。用如下公式计算:
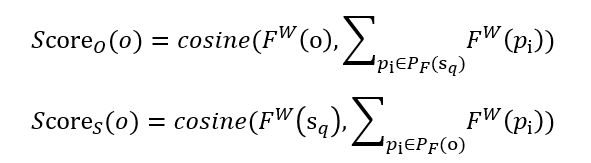
特别的,当PF(Sq)或者PF(o)集合为空时,上述的两个公式分别用FW(Sq)和FW(o)替换。在实验中作者对比了两种得分以及两种得分结合的办法的有效性。
实验中使用的数据是来自正式的高考题目。实验者邀请了三位人类专家,共同只用中文维基百科网页内容来解答问题,三位专家给出了如下结果:1、有123道题目被标记为了QS-A类题目。这类题目专家能够通过维基百科的内容找到蕴含其中的正确选项。2、有454道题目被专家标记为QS-B类题目。这类题目的超出了维基百科的范围,必须参考历史教科书或者其他资源才能给出正确答案。
QS-A和QS-B两类题目都被用来评估实验方法。QS-A也被用作分别测量三级策略中的第一级(检索页面)和第二级(排名过滤页面)。对于QS-A类的每一个问题,专家都会给出一个可以找出正确答案的最小维基百科页面集合,作为对于本实验的“黄金标准”。对于本实验的测试数据,专家给出了一共345个页面,或者平均每个问题需要2.80个页面的黄金标准。在这些问题中,有46(37.4%)个页面仅需要1个页面就可以正确的回答。但也有8个页面需要用到8个页面才能回答。
下面将介绍用QS-A度量第一级、第二级策略的方法。用G表示由专家给出的能够正确回答问题的“黄金标准”页面集合。用A表示自动答题用到的页面集合。需要测量三个值:精确率P,召回率R和F-Score(F)。还计算了回答问题的准确度,即正确回答了问题的比例。
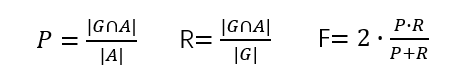
用最左最长匹配算法,实验中QS-A类问题一共检索到了2383个页面,平均每个页面19.37个。实验者人工的随机从中选择200个页面,其中只有13个(6.5%)匹配是不精确的分界是错误的。表明了这个这个算法是很有效率的。
在检索到的概念页面中,151(6.34%)个页面是消歧义页面,其中91个页面正确的被消歧页面替换了。替换错误的页面中有23个是因为不存在,也就是说维基百科中只给正确的解释一个简短的描述,而没有给出一个链接将其链接到另一个页面上,所以也不可能用正确的页面替换。实验的结果在截图如下,和“黄金标准”的对比中我们可以看到,检索到的概念页面达到了0.807的平均召回率。但是它的精确度比较低,说明还需要第二步过滤的过程。
对QS-A类问题检索得到的引用页面一共224个,平均1.98个每个。虽然引用页面得到的精确度、召回率等都很低,但是它与概念页面的检索结果相结合后,能够提高总体的性能。
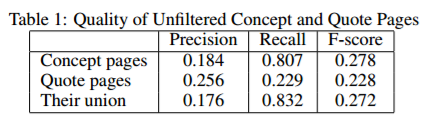
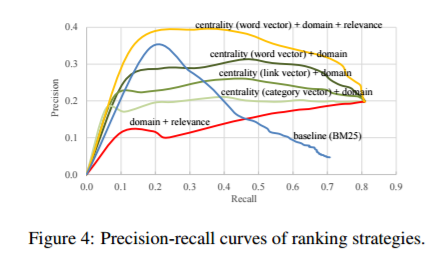
对于上文提到的几种排名和过滤策略,实验中将采用多种的结合方式来过滤检索到的概念页面和引用页面。实验测试了几种不同结合的过滤方法下,返回得分前K(1~40)个页面时的F等分情况,文章中的实验结果截图如下。可以看到,在基于中心性的策略中,基于词的向量构造方法得到的性能较基于链接和基于类的向量构造方法要好。结合基于中心性、领域、相关性三种方式的过滤方法是性能最好的一种结合方式,它性能要远比基于领域和相关性的性能要好。三种方式结合的策略中,第一步先是把所有不属于历史类别的页面过滤了,再用基于中心性和相关性的得分对剩余的页面排名,过滤。对比最基础的方法,把整个问题当做关键字去检索,并用BM25得分排名,三种方式结合的策略也要远胜之。
使用上文实验得出的最好的过滤方法,设置返回Top-k排名页面的k值为6,并用3.3中提到的公式计算,选择得分最高的选项作为答案。下表表示了实验结果中回答的准确度。可以看到,在QS-A类问题中,大约有三分之一的问题可以用ScoreO或者ScoreS两种得分方式之一单独的得到正确的答案,比起随机选择25%的正确率要好。在结合两种策略后,准确率达到了43.09%,着对于AI参与高考这个问题来说是一个很值得高兴的实验结果。对于QS-B类问题,虽然他们或多或少的超出了维基百科的范围,但是实验的方法利用了维基百科中可以利用的知识,正确率也达到了31.28%。
5、后续讨论
作者接着讨论了一些存在的问题和后续可以进行的工作。作者发现,有一些页面包含了广阔的话题,比如说中国,这个词检索出来的范围面太广了,它的得分也会因此更高。具体来分析:1、这种页面的内容与其他许多页面相重合,所以有利于它在中心性得分中容易胜出。2、它属于历史范围,所以在基于领域的策略中容易胜出。3、它包含了很多出现在问题中的词汇,所以在基于相关性的策略中也容易胜出。但是这种页面的内容往往对问题的答案没有太大帮助。由此也激发了作者对于后续工作的考虑。作者认为,后续工作不应该只把页面内容作为一个整体来参与排名,而应该考虑页面内容中更小的一部分,这样更能紧密的匹配问题。换句话说,检索和排名不能注重于页面,而是要考虑到段落或者句子上。此外,实验中固定设置Top-k排名页面k值为6,但是根据专家给出的“黄金标准”,找到蕴含正确答案的网页数量会在1~8中变化,因此作者认为未来的工作中如何做到对于每个问题自动的设置k值,用于避免得到的页面太少而不能包含足够的知识,或者得到的页面过多,其中包含了噪声。
高考的问题是多种多样的,因此作者认为本文只是解决高考问题其中的一种方法,对于问题题目还需要有更深刻的理解。比如说有的问题需要给出一个否定的选项,有的问题是需要给出年代的顺序,那么本文这种相关性的测量就不合适了。还有一点,现存的语义分析和智能问答解决方法由于它们能解决的问题和高考问题的不同,并没有使用到。
6、文章贡献
1、文章作者是最早的一批致力于研究人工智能解决高考题目的研究者,他们提出了一种自动回答高考单选题的三级工作框架。2、作者实现的三级框架利用并扩大了信息检索技术,先用字符串匹配和基于上下文消除歧义的方法,从维基百科中获取到和疑问相关的页面,再用“中心性”、“问题领域”、“关联性”三种方法,对页面排名和过滤。最后用“基于关联蕴含”的方法,得到正确的选项。
3、实验使用从最近几年真实的高考历史试题作为测试数据,实验结果证明本文的策略有着不错的效果。
方法来处理高考挑战。
7、个人思考
本人中学时历史成绩还是很不错的,即使后来作为了一名理科生但历史成绩至少会有文科生中上水平吧,那么我就来结合自己的做题经验来谈谈自己的想法。
文章中使用的方法,引用对于解题非常重要。但是我以前在做题时,为了节省时间应用的内容经常没有去看,或者只是一扫而过没有去理解,但是考试分数还是很高的。为什么呢,现在分析起来是因为我抓住了题目中的几个关键词。例如如果我做例题,我会直接抓住题干中“西周”,“分封”两个关键词。当然仅有题目的关键词还是不够的,还需要选项中的关键词,包括“土地”,“人口”,“耕牛”,“铁犁”。然后我会将题目的关键词和选项的关键词连起来看,组合成“西周 土地”,“西周 分封 土地” ,“分封 土地”,“西周 铁犁”,“西周 分封 铁犁”等组合词。之后我会根据这些组合词,思索出存在于脑海中的组合。我会从脑袋中挖掘出“分封 土地”的组合,答案已经出来一半了。我想,这个过程添加到文章中是否可以呢。而用直接拿选项用“最左最短匹配法”去检索,由于选项一般简短,概念特别模糊,往往不能搜索到对解释问题有用的内容,我认为提前将题干和选项关联起来去搜索也能减少页面集合中混入噪声页面的概率。
第一步,从题干中提取出几个关键词,这几个关键词首先要是概念词。但是提取出来的概念词可能会很多,还要用一些方法测量出他们权重,选择出其中一两个。一般是在题目最后一句话,并且具有明显历史特征的词汇,如年代、事件等,和选项组合起来时有用。可在排除了stopword的历史题库中查询概念词的出现频率作为权重,确认题目中的2-3个关键词,他们的作用主要是给模糊的选项概念词添加一个具体的限定。
第二步,从选项中提取出几个关键词,因为选项一般较短,除去stopword后剩余的词汇基本都可作为关键词。
第三步,将题目中的关键字与选项中的关键字组合连接后,用维基百科搜索,搜索到的结果中可能标题与搜索并不一致,但是内容中存在相同的,用上述消歧义的方法选择页面并加入页面集合中,之后用同样的排名过滤方法处理后续过程。
考虑需要降低在组合搜索中没有检索到页面最终的评估得分。
与文章中不同的是,我考虑的是提前找出题干与选项强关联的页面,减少由于选项内容较少,模糊的搜索带来的噪声。例如用选项中“土地”的概念词搜索到的结果与题目几乎无关,虽然很可能在之后的过滤中排除了该页面,但是有可能因此带来了噪声没被消除而影响了结果。如果用组合而成的“西周 分封 土地”或者“分封 土地”
相关知识
stop word的概念是把一些对短语表述不构成直接影响的单词的的搜索结果直接过滤掉,包括a,an,the等冠词,in, at, of等介词, 一些人称代词,时态的助动等。中文中的"的、"了"等也类似。这些词因为使用频率过高,几乎每个网页上都存在,所以搜索引擎将这一类词语忽略掉。
2、余弦相似性
该相似性由余弦定理引出,首先我们都知道在向量(x1,y1)和(x2,y2)之间,它们的夹角余弦值为: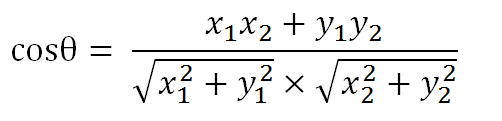
余弦相似性就是通过两个向量之间夹角的余弦值来表示相似性,如果两个向量完全一致,则它们的方向相同,余弦值为1,最为相似。下面给出一个例子:
句子A:我/在/南航/学/计算机,不/在/南航/开/飞机。
句子B:我/不/在/南航/学/计算机,也/不/在/南航/开/飞机。
得到词频率:
句子A:我 1,在 2,南航 2,计算机1,飞机1,不1,学 1,开 1。
句子B:我 1,在 2,南航 2,计算机 1,飞机 1,不 2,学 1,开 1。
得到向量
A:(1,2,2,1,1,1,1,1) B:(1,2,2,1,1,2,1,1)
根据以下公式计算,可得到两者相似性。
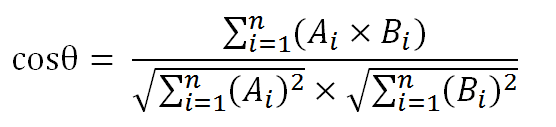
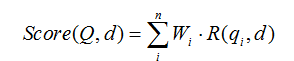
其中,Q表示Query。qi表示Q解析之后的一个Term。d表示一个搜索结果文档。Wi表示语素qi的权重,用IDF计算。R(qi,d)表示词qi与文档d的相关性得分。其实就是计算一个query里面所有词和文档的相关度,然后在把分数做累加操作,而每个词的相关度分数主要还是受到TF-IDF的影响。
更完整的BM25公式如下:
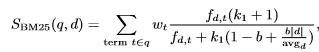
其中k1,b都是调节因子,|d|是文档d的长度,avgd是这个文档集的平均文档长度。fd,t是词t在文档d中出现的次数wt是用IDF计算而来的。
总结一下影响BM25公式的因数主要有三点:1、IDF越高分数越高。2、TF越高分数越高。3 如果查询到的文档长度相对文档集的平均长度越长,则分数越低。
文献来源:
[Gong Chengh et al., 2016] Gong Cheng, Weixi Zhu, Ziwei Wang, Jianghui Chen, Yuzhong Qu,Taking up the Gaokao Challenge: An Information Retrieval Approach,Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-16)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









