









一、hbase简介
1、hbase产生背景
以前Google存储大量的网页信息,如何存储,如何计算,如何快速查询就成为了一个问题,后来在2003年Google发表了3篇论文提供了解决思路,分别是GFS、MAPREDUCE、BigTable ,但是没有讲源码开源出来,后来这几篇论文被Doung Cutting看见了,由于Doung Cutting是做搜索引擎lucence,遇到和Google同样的问题,在03年看到google发表的论文后,就使用java语言实现了三篇论文,与之对应的就是:
GFS— HDFS 分布式存储
MAPREDUCE—MAPREDUCE 分布式计算
bigtable — hbase 分布式数据库,海量数据随机近实时查询
2、什么是hbase
HBase是BigTable的开源(源码使用Java编写)版本。是 Apache Hadoop的数据库,是建立在 HDFS之上,被设计用来提供高可靠性、高性能、列存储、可伸缩、多版本的 NoSQL 的分布式数据存储系统,实现对大型数据的实时、随机的读写访问。
HBase 依赖于 HDFS 做底层的数据存储,BigTable 依赖 Google GFS 做数据存储;
HBase依赖于 MapReduce做数据计算,BigTable 依赖 Google MapReduce 做数据计算
HBase 依赖于 ZooKeeper 做服务协调,BigTable 依赖 Google Chubby 做服务协调
备注:nosql的概念
NoSQL = NO SQL或者NoSQL = Not Only SQL:会有一些把 NoSQL 数据的原生查询语句封装成 SQL ,
比如HBase 就有 Phoenix 工具
3、hbase的特点
3.1HBase这个NoSQL数据库的要点
①它介于 NoSQL 和 RDBMS 之间,仅能通过主键(rowkey)和主键的 range 来检索数据
②HBase查询数据功能很简单,不支持 join 等复杂操作
③不支持复杂的事务,只支持行级事务(可通过 hive 支持来实现多表 join等复杂操作)。
④HBase中支持的数据类型:byte
⑤主要用来存储结构化和半结构化的松散数据。
3.2HBase中的表特点
①大:一个表可以有上十亿行,上百万列
②面向列:面向列(族)的存储和权限控制,列(簇)独立检索。
③稀疏:对于为空(null)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
④无模式:每行都有一个可排序的主键和任意多的列,列可以根据需要动态的增加,同一 张表中不同的行可以有截然不同的列
4、HBase 应用场景
4.1半结构化或非结构化数据
对于数据结构字段不够确定或杂乱无章很难按一个概念去进行抽取的数据适合用 HBase。而 且 HBase 是面向列的,HBase支持动态增加字段
4.2记录非常稀疏
RDBMS 的行有多少列是固定的,为 null 的列浪费了存储空间。而 HBase 为 null 的 Column 是不会被存储的,这样既节省了空间又提高了读性能。
4.3多版本数据
对于需要存储变动历史记录的数据,使用 HBase 就再合适不过了。HBase 根据 Row key 和 Column key 定位到的 Value 可以有任意数量的版本值。
4.4超大数据量
当数据量越来越大,RDBMS 数据库撑不住了,就出现了读写分离策略,通过一个Master专门负责写操作,多个Slave负责读操作,服务器成本倍增。随着压力增加,Master 撑不住了, 这时就要分库了,把关联不大的数据分开部署,一些 join 查询不能用了,需要借助中间层。 随着数据量的进一步增加,一个表的记录越来越大,查询就变得很慢,于是又得搞分表,比 如按 ID 取模分成多个表以减少单个表的记录数。经历过这些事的人都知道过程是多么的折腾。采用 HBase 就简单了,只需要加机器即可,HBase 会自动水平切分扩展,跟 Hadoop 的无缝集成保障了其数据可靠性(HDFS)和海量数据分析的高性能(MapReduce)。
二、hbase的设计思想
bigtable即大表,能存储十亿行百万列,底层数据存储在hdfs上,对行键创建索引(二次索引(二级)),查询的时候,先查询高级索引表,再由高级索引表跳到初始索引表,再由初始索引表确定数据的存储位置,最终定位数据真实存储 ,总结下来hbase的设计思想就是:跳表结构 + 布隆过滤器
三、hbase的表结构
1、行键(rowkey)
与 NoSQL 数据库们一样,rowkey 是用来检索记录的主键。访问HBase Table中的行,只有三种方式:
1、通过单个 row key 访问
2、通过 row key 的 range
3、全表扫描
rowkey 行键可以是任意字符串(最大长度是 64KB,实际应用中长度一般为 10-100bytes),最好是16。在 HBase内部,rowkey保存为字节数组。HBase 会对表中的数据按照 rowkey 排序 (字典顺序)存储时,数据按照 rowkey 的字典序(byte order)排序存储。设计 key 时,要充分排序存储这个特性,将经常一起读取的行存储放到一起。(位置相关性)
注意:
字典序对 int 排序的结果是 1,10,100,11,12,13,14,15,16,17,18,19,2,20,21,„,9,91,92,93,94,95,96,97,98,99。 要保持整形的自然序,行键必须用 0 作为左填充。 行的一次读写是原子操作(不论一次读写多少列)。这个设计决策能够使用户很容易的理解程序在对同一个行进行并发更新操作时的行为。
2、列簇(Column Family)
HBase 表中的每个列,都归属与某个列簇。列簇是表的Schema
的一部分(而列不是),必须在使用表之前定义好,而且定义好了之后就不能更改。列名都以列簇作为前缀。例如 courses:history,courses:math 都属于 courses 这个列簇。
访问控制、磁盘和内存的使用统计等都是在列簇层面进行的。 列簇越多,在取一行数据时所要参与
IO、搜寻的文件就越多,所以,如果没有必要,不要设置太多的列簇(最好就一个列簇)
3、列(Column)
每一个列都属于一个列簇,列是属于表中数据,是插入的时候指定的
***注意:***重点理解这个“表中数据”的意思!
4、时间戳(TimeStamp)
HBase 中通过 rowkey 和 columns 确定的为一个存储单元称为 cell。
每个 cell 都保存着同一份数据的多个版本,版本通过时间戳来索引。时间戳的类型是 64 位整型。时间戳可以由hbase(在数据写入时自动)赋值,此时时间戳是精确到毫秒的当前系统时间。时间戳也可以由客户显式赋值。如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。 每个cell中,不同版本的数据按照时间倒序排序,即最新的数据排在最前面。
为了避免数据存在过多版本造成的的管理 (包括存贮和索引)负担,hbase
提供了两种数据版 本回收方式: 保存数据的最后 n 个版本 保存最近一段时间内的版本(设置数据的生命周期 TTL)。用户可以针对每个列簇进行设置。
5、单元格(Cell)
由{rowkey, column( = + ), version} 唯一确定的单元。 Cell中的数据是没有类型的,全部是字节码形式存贮。
四、hbase的使用
1、shell操作
进入hbase的客户端:安装过hbase的节点都可以 hbase shell hbase(main):001:0> hbase的客户端操作界面
善于运用help查看帮助
help command查询相关命令的帮助
使用help会出现很多命令,其中namespace、ddl、dml是我们学习的重点!!!
Group name: ddl
Commands: alter, alter_async, alter_status, create, describe, disable, disable_all, drop,
drop_all, enable, enable_all, exists, get_table, is_disabled, is_enabled, list,
locate_region, show_filters
Group name: namespace
Commands: alter_namespace, create_namespace, describe_namespace,
drop_namespace, list_namespace, list_namespace_tables
Group name: dml
Commands: append, count, delete, deleteall, get, get_counter, get_splits, incr, put,
scan, truncate, truncate_preserve
1.1namespace操作
1.1.1创建
help “create_namespace”
create_namespace “name”
1.1.2查看namespace列表
list_namespace
1.1.3查看详细描述信息
describe_namespace “name”
1.1.4显示当前namespace下的所有表
list_namespace_tables “name”
1.1.5删除 namespace
drop_namespace "name"
1.2ddl操作
Group name: ddl Commands: alter, alter_async, alter_status, create,
describe, disable, disable_all, drop, drop_all, enable, enable_all,
exists, get_table, is_disabled, is_enabled, list, locate_region,
show_filters
1.2.1建表
help "create"
hbase> create 'ns1:t1', {NAME => 'f1', VERSIONS => 5}
hbase> create 't1', {NAME => 'f1'}, {NAME => 'f2'}, {NAME => 'f3'}
hbase> create 't1', 'f1', 'f2', 'f3'
hbase> create 't1', {NAME => 'f1', VERSIONS => 1, TTL => 2592000, BLOCKCACHE => true}
hbase> create 't1', {NAME => 'f1', CONFIGURATION => {'hbase.hstore.blockingStoreFiles' => '10'}}
语法1:craete “namespace:表名”,“family column”,“family column”
create “bd1901:test1”,“info1”,“info2”
语法2:
{表的一些属性 必须包含列族}
create “namespace:表名”,{NAME => “”,VERSIONS => 3,TTL =>},{NAME => “”}
常用的属性:
VERSIONS => 1 指定数据版本, TTL => 2592000 指定数据存储周期
create “bd1901:test2”,{NAME => “info1”},{NAME => “info2”,VERSIONS => 3}
1.2.2查看表列表
list hbase> list
查看所有的表列表
hbase> list ‘abc.’ 查看所有的指定字符开头的表
default 下的 hbase> list 'ns:abc.’ 查看指定的namespace下的所有的指定字符开头的表列表 list
‘bd1901:t.’ hbase> list 'ns:.’ 查看指定namespace下的所有表列表 list
“bd1901:.*”
1.2.3查看表的详细信息
help ‘describe’
hbase> describe ‘t1’ 查看default下的表的描述信息 hbase>
describe ‘ns1:t1’ 查看指定namespace下的所有表描述信息的
简写: hbase> desc ‘t1’
hbase>desc ‘ns1:t1’
1.2.4查看表是否禁用
hbase中表有两种状态:
启用 enable ——可以执行操作
禁用 disable ——不可以执行操作
is_disabled 查看表是否禁用 禁用true 启用 false
is_disabled “namespace:表名”
is_disabled “bd1901:test1”
is_enabled 查看表是否启用 启用 true 禁用 false
is_enabled “namespace:表名”
is_enabled “bd1901:test1”
默认建表的时候是启用状态
1.2.5禁用表和启用表的相关操作
disable “namespace:表名”
enable “namespace:表名”
例子:
disable “test1”
enable “test1”
disable_all “namespace:.|t.” 禁用指定的所有表
enable_all "namespace:.|t."启用指定的所有表
例子:
disable_all “bd1901:.*”enable_all “bd1901:.*”
1.2.6修改表
alter
1)修改某一个列族的属性信息
alter ‘namespace:表名’, ‘列族’, {NAME => ‘列族’, IN_MEMORY => true}, {NAME
=> ‘列族’, VERSIONS => 5} alter “bd1901:test1”,{NAME => “info1”,VERSIONS => 3}
2)添加列族
语法同上
alter "bd1901:test1",{NAME => "info3",VERSIONS => 3}
修改表的时候列族不存在,事实上就是添加
alter "bd1901:test1","info4",{NAME => "info5",VERSIONS
=> 3}
3)删除列族
hbase> alter 'namespace:表名', NAME => '列族', METHOD => 'delete'
hbase> alter 'namespace:表名', 'delete' => '列族'
METHOD 用于指定对当前列族的操作
alter "bd1901:test1",NAME => "info5",METHOD => 'delete'
alter "bd1901:test1",'delete' => "info4"
注意: 表中至少有一个列族 如果表中只剩一个列族 不允许删除
1.2.7删除表
先禁用表,再删除表
drop “namespace:表名”
disable "bd1901:test1"
drop "bd1901:test1"
drop_all 删除指定的所有表
hbase> drop_all 'namespace:.*|t.*'
1.3dml操作
dml
Group name: dml
Commands: append, count, delete, deleteall, get, get_counter, get_splits, incr, put, scan, truncate, truncate_preserve
1.3.1向表中添加数据 put
行键 列族:列 值
hbase> put ‘namespace:表名’, ‘行键’, ‘列族:列’, ‘列的值’,[ts1(时间戳 不给默认系统时间戳)]
put "nm:test2","rk001","info1:name","zs"
put "nm:test2","rk001","info1:age","18"
put "nm:test2","rk001","info1:addr","hebei"
1.3.2查询表数据
1.3.2.1扫描查询 scan
1)全表扫描 表下的所有列族的所有列全部显示
scan “namespace:表名”
例子?:
scan “user_info”
2)指定列显示
scan “namespace:表名”,{COLUMNS => ‘列族:列名’}
scan “namespace:表名”,{COLUMNS=> [‘列族:列名’,“列族:列名”]}
例子?:
scan “user_info”,{COLUMNS => “base_info:age”}
scan “user_info”,{COLUMNS => [“base_info:name”,“base_info:age”]}
3)指定显示行数 LIMIT
scan “namespace:表名”,{COLUMNS => [‘列族:列名’,“列族:列名”],LIMIT => 需要显示的行数}
例子?:
scan “user_info”,{COLUMNS => “base_info:age”,LIMIT => 5}
4)指定rowkey范围显示
STARTROW 指定起始的行键 ENDROW 指定结束的行键 scan “namespace:表名”,{COLUMNS =>
[‘列族:列名’,“列族:列名”],LIMIT=> ,STARTROW => “起始行key”,ENDROW => “结束行key”}
例子?:
scan “user_info”,{STARTROW => “baiyc_20150716_0008”,ENDROW => “zhangsan_20150701_0004”}
注意:这种显示方式,包含左边界不包含右边界,只指定STARTROW不指定ENDROW的时候显示到结尾
5)可以指定时间戳范围 查询数据 TIMERANGE => [起始时间戳,终止的时间戳]
scan “namespace:表名”,{COLUMNS=>"",TIMERANGE=>,LIMIT=>}
例子?:
scan “user_info”,{COLUMNS => “base_info:name”,TIMERANGE =>
[1558844852080,1558844855890]}
时间戳范围是含头不含尾的
1.3.2.2单条查询 get
1)查询指定行键只能查询一条数据
hbase> get ‘namespace:表名’,“行键”
例子?:
get “user_info”,“zhangsan_20150701_0004”
2)指定需要查询的一行数据的列
COLUMN => []
get "namespace:表名","行键",{COLUMN => ["列族:列",“列族:列”]}
get "user_info","zhangsan_20150701_0004",{COLUMN => ["base_info:name","base_info:age"]}
3)指定需要查询一行数据的时间戳数据 TIMESTAMP => 时间戳
查看某一列指定版本的数据 get “user_info”,“zhangsan_20150701_0004”,{TIMESTAMP =>
1558844848954}
4)可以指定查询的数据的 时间戳范围的
get “user_info”,“zhangsan_20150701_0004”,{TIMERANGE =>
[1558844823464,1558847245992]}
时间戳含头不含尾
1.3.3删除数据 delete
hbase> delete ‘namespace:表名’, ‘行键’, ‘列族:列’, 时间戳
例子?:
delete “user_info”,“zhangsan_20150701_0004”,“base_info:age”,1558847233830
1.3.4清空表数据
truncate “namespace:表名”
分为三步:
先查看表状态:is_disabled "user_info"
1.- Disabling table... 禁用表
2.- Truncating table... 清空表
3.启用表
2、API操作
主要 Hbase API 类和数据模型之间的对应关系:
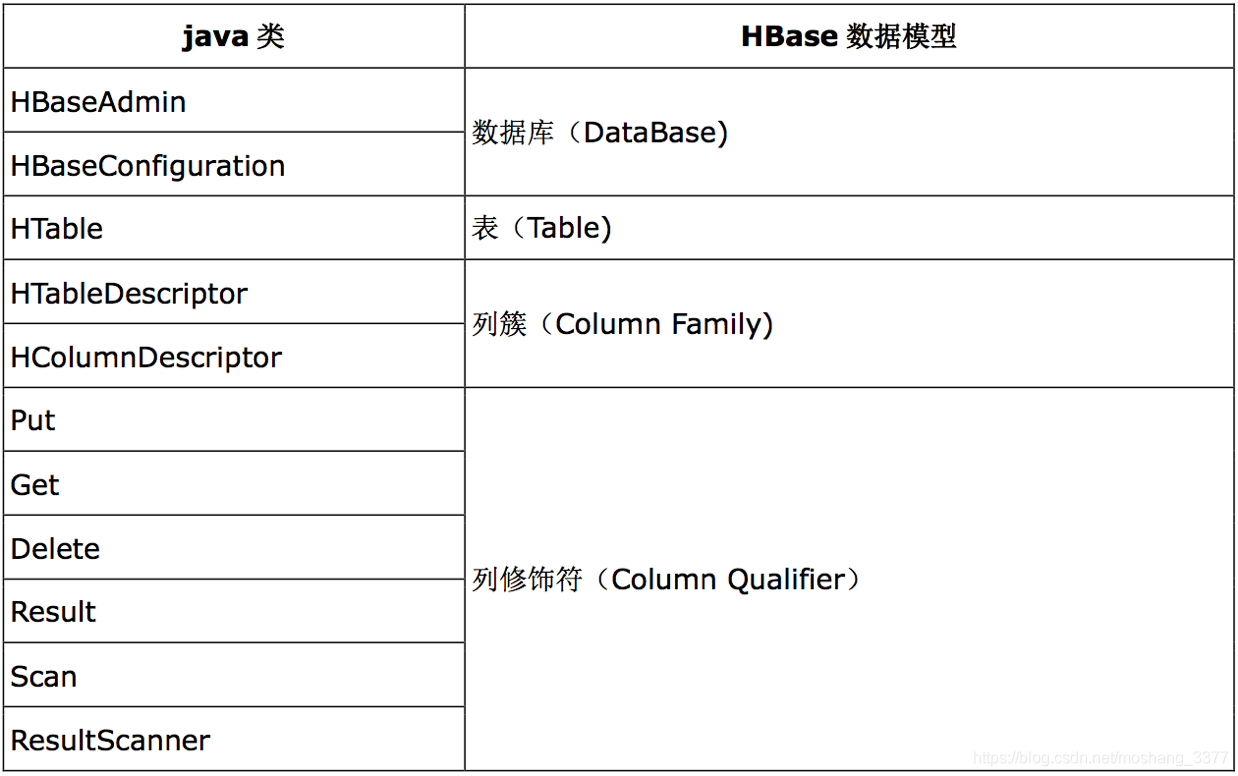
HbaseConfiguration——hbase的配置文件管理对象,加载hbase的配置
加载配置文件的时候重点加载zookeeper的位置配置信息
zookeeper中保存的是hbase中表的结构schema信息——hbase的寻址路径(索引表的存储位置)
HBaseAdmin | admin hbase的管理对象
hbase中的namespace或table创建/删除操作,可以理解为ddl的句柄操作
HTable | Table 表操作对象,对表的数据进行操作
HTableDescriptor 表描述器对象,描述表的信息,表名/列簇 HColumnDescriptor
列簇描述器,描述表中的列簇信息的
API?仅供参考,代码可能还有错误,欢迎大家指正!
2.1DDL
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.NamespaceDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class HbaseDDL {
static Configuration conf = null;
static HBaseAdmin admin = null;
static Connection conn = null;
// 创建namespace
public static void create_namespace() throws IOException {
NamespaceDescriptor ns = NamespaceDescriptor.create("test_api_1901").build();
// 参数namespacedescriptor
admin.createNamespace(ns);
}
public static void list_namespace() throws IOException {
NamespaceDescriptor[] nsDescriptors = admin.listNamespaceDescriptors();
for (NamespaceDescriptor ns : nsDescriptors) {
System.out.println(ns.getName());
}
}
public static void delete_namespace(String name) throws IOException {
admin.deleteNamespace(name);
System.out.println(name+"删除成功!");
}
//创建表
public static void create_table(String name,String...familys) throws IOException {
//判断是否存在
if (admin.tableExists(name)) {
System.out.println(name+"表已存在,请换个表名");
} else {
TableName tn = TableName.valueOf(name);
//参数 tablename对象,表名描述器
HTableDescriptor table = new HTableDescriptor(tn);
//一个表至少有一个列簇
//封装列簇描述器
for (String f : familys) {
HColumnDescriptor family = new HColumnDescriptor(f);
table.addFamily(family);
}
admin.createTable(table);
}
System.out.println("建表成功");
}
//查看表列表
public static void list_tables() throws IOException {
TableName[] tNames = admin.listTableNames();
for (TableName t : tNames) {
System.out.println(t.getNameAsString());
}
}
//删除表
public static void delete_table(String name) throws IOException {
if (admin.tableExists(name)) {
admin.deleteTable(name);
} else {
System.out.println(name+"不存在啊,请检查后再操作");
}
}
public static void main(String[] args) throws IOException {
conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "hadoop01:2181,hadoop02:2181,hadoop03:2181");
conn = ConnectionFactory.createConnection(conf);
// 获取ddl句柄
admin = (HBaseAdmin) conn.getAdmin();
//create_namespace();
//list_namespace();
//create_table("test_api_1901:table1", "f1","f2");
//list_tables();
delete_table("test1");
}
}
2.2DML
import java.io.IOException;
import java.util.ArrayList;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
public class HbaseDML {
static Configuration conf = null;
static HBaseAdmin admin = null;
static Connection conn = null;
static HTable table = null;
/*
* 数据导入 shell put "表名",”行键“,"列簇:列",”值“,ts
*/
// 插入单条数据
public static void insertOneData() throws IOException {
// put对象封装需要插入的数据是每一条对应一个put对象
Put put = new Put("rk001".getBytes());
put.addColumn("info1".getBytes(), "name".getBytes(), "zhangsan".getBytes());
table.put(put);
}
// 插入多条数据
public static void insertOneDatas() throws IOException {
// put对象封装需要插入的数据是每一条对应一个put对象
for (int i = 0; i < 10000; i++) {
Put put = new Put(("rk" + i).getBytes());
put.addColumn("info1".getBytes(), ("name" + i).getBytes(), ("zhangsan" + i).getBytes());
table.put(put);
}
}
// 先将数据放在list集合中,即先把数据房子list内存中,最终将内存中的数据一次性提交
public static void insertListDatas() throws IOException {
ArrayList<Put> list = new ArrayList<Put>();
for (int i = 0; i < 10000; i++) {
Put p = new Put(("rk" + i).getBytes());
p.addColumn("info1".getBytes(), "name".getBytes(), "zhangsan".getBytes());
list.add(p);
}
table.put(list);
}
// 批量数据导入,合并put次数,利用本地缓存(磁盘的)
public static void insertBufferDatas() throws IOException {
// 设置是否需要进行刷新提交put对象,默认是true,默认一条数据就提交一次
// 将参数值改为false,不会立即提交,达到设定值才会提交
table.setAutoFlushTo(false);
for (int i = 0; i < 10000; i++) {
Put put = new Put(("rk" + i).getBytes());
put.addColumn("info1".getBytes(), ("name" + i).getBytes(), ("zhangsan" + i).getBytes());
//不提交,提交到本地缓存中,没有连接hbaseServer
table.put(put);
//够10M提交一次,跟下面的条件是或者的关系,满足一个就能执行
table.setWriteBufferSize(10*1024*1024);
if (i%3000==0) {
//提交
table.flushCommits();
}
}
//将不够3000条的数据强制刷出
table.flushCommits();
}
//单条数据删除
public static void deleteOnedatas() throws IOException {
Delete delete=new Delete("rk1".getBytes());
delete.addColumn("info1".getBytes(), "name".getBytes());
table.delete(delete);
}
//多条数据删除
public static void deleteOnedata() throws IOException {
Delete delete1=new Delete("rk1".getBytes());
delete1.addColumn("info1".getBytes(), "name".getBytes());
table.delete(delete1);
Delete delete2=new Delete("rk2".getBytes());
delete2.addColumn("info1".getBytes(), "name".getBytes());
table.delete(delete2);
}
public static void main(String[] args) throws IOException {
conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "hadoop01:2181,hadoop02:2181,hadoop03:2181");
conn = ConnectionFactory.createConnection(conf);
// 一个Htable对象对应一个表
table = (HTable) conn.getTable(TableName.valueOf("test_api_1901:table1"));
insertOneDatas();
}
}
2.3DML——Quary
import java.io.IOException;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.filter.BinaryComparator;
import org.apache.hadoop.hbase.filter.FamilyFilter;
import org.apache.hadoop.hbase.filter.Filter;
import org.apache.hadoop.hbase.filter.CompareFilter.CompareOp;
public class HbaseDMLQuary {
static Configuration conf = null;
static HBaseAdmin admin = null;
static Connection conn = null;
static HTable table = null;
public static void main(String[] args) throws IOException {
conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "hadoop01:2181,hadoop02:2181,hadoop03:2181");
conn = ConnectionFactory.createConnection(conf);
// 一个Htable对象对应一个表
table = (HTable) conn.getTable(TableName.valueOf("test_api_1901:table1"));
}
//get查询单条
public static void getOneData() throws IOException {
//将需要查询的一条数据封装成一个get对象,参数rowkey
Get get = new Get("zhangsan_20150701_0001".getBytes());
//result的对象是封装的get查询结果,封装的是一行数据,包含多个列簇多个列多个单元格
Result result = table.get(get);
List<Cell> cells = result.listCells();
//循环遍历每一个单元格
//行键----列簇----列----时间戳 定位单元格
for (Cell cell : cells) {
System.out.print(new String(cell.getRow())+"\t");
System.out.print(new String(cell.getFamily())+"\t");
System.out.print(new String(cell.getQualifier())+"\t");
System.out.print(new String(cell.getValue())+"\t");
System.out.print(cell.getTimestamp());
System.out.println();
}
}
//批量查询
public static void getDatas() throws IOException {
ArrayList<Get> list = new ArrayList<Get>();
Get get1 = new Get("zhangsan_20150701_0001".getBytes());
list.add(get1);
Get get2 = new Get("zhangsan_20150701_0002".getBytes());
//参数1 列簇 参数2 列
get2.addColumn("base_info".getBytes(), "name".getBytes());
list.add(get2);
Result[] results = table.get(list);
for (Result r : results) { //每一个get提交的结果
List<Cell> cells = r.listCells();
for (Cell cell : cells) { //每一个单元格的结果
System.out.print(new String(cell.getRow())+"\t");
System.out.print(new String(cell.getFamily())+"\t");
System.out.print(new String(cell.getQualifier())+"\t");
System.out.print(new String(cell.getValue())+"\t");
System.out.print(cell.getTimestamp());
System.out.println();
}
}
}
/*
* scan 表扫描
*/
public static void scanData01() throws IOException {
//全表扫描
Scan scan = new Scan();
//扫描的结果集
ResultScanner results = table.getScanner(scan);
//获取标准的迭代器对象
Iterator<Result> rit = results.iterator();
while (rit.hasNext()) {
Result next = rit.next();
List<Cell> cells = next.listCells();
for (Cell cell : cells) {
System.out.print(new String(cell.getRow())+"\t");
System.out.print(new String(cell.getFamily())+"\t");
System.out.print(new String(cell.getQualifier())+"\t");
System.out.print(new String(cell.getValue())+"\t");
System.out.print(cell.getTimestamp());
System.out.println();
}
}
}
//指定起始行键扫描
public static void scanData02() throws IOException {
Scan scan = new Scan();
scan.setStartRow("rk01".trim().getBytes());
scan.setStopRow("zhangsan_20150701_0005".trim().getBytes());
//按照时间戳范围扫描
//scan.setTimeRange("", "");
//扫描的结果集
ResultScanner results = table.getScanner(scan);
//获取标准的迭代器对象
Iterator<Result> rit = results.iterator();
while (rit.hasNext()) {
Result next = rit.next();
List<Cell> cells = next.listCells();
for (Cell cell : cells) {
System.out.print(new String(cell.getRow())+"\t");
System.out.print(new String(cell.getFamily())+"\t");
System.out.print(new String(cell.getQualifier())+"\t");
System.out.print(new String(cell.getValue())+"\t");
System.out.print(cell.getTimestamp());
System.out.println();
}
}
}
public static void scanDataWithFilter() throws IOException {
Scan scan = new Scan();
/*
* final CompareOp familyCompareOp 比较规则
final ByteArrayComparable familyComparator 指定比较机制
*/
//对列簇进行过滤的
Filter f1 = new FamilyFilter(CompareOp.GREATER, new BinaryComparator("base_info".getBytes()));
scan.setFilter(f1);
ResultScanner results = table.getScanner(scan);
Iterator<Result> rit = results.iterator();
while (rit.hasNext()) {
Result next = rit.next();
List<Cell> cells = next.listCells();
for (Cell cell : cells) {
System.out.print(new String(cell.getRow())+"\t");
System.out.print(new String(cell.getFamily())+"\t");
System.out.print(new String(cell.getQualifier())+"\t");
System.out.print(new String(cell.getValue())+"\t");
System.out.print(cell.getTimestamp());
System.out.println();
}
}
}
}














 14万+
14万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









