







中文文本分词
中文分词的四个难题:
1) “词”的界定。
2) 分词与理解孰先孰后。
3) 分词歧义。
4) 未登录词识别。
四个难题的解决方案:
1) 分词规范+词表+分词语料库 来界定词。从单一的“分词规范”到“规范+词表”,再从“规范+词表”到“分词语料库”,关于词语的定义越来越趋向实用。
2) 手工规则系统不敌统计分词系统。
3) 未登录词造成的分词精度失落至少比歧义大5倍以上,重点在于识别未登录词,分词歧义的影响比较小。如果没有未登录词,则分词准确率至少可以达到98%;包含未登录词以后,分词准确率一般不会超过90%【1】。
4) 大量实验表明,能够提高未登录词识别准确率的字本位方法优于词本位的方法。2002年之前,分词方法一般基于词典,然后使用规则和进行统计。2002年之后,字本位的分词系统开始崭露头脚,现在已经居于主流。
字本位的分词方法
每个字占据一个构词位置,例如B(词首)、M(词中)、E(词尾)、S(单独构词),则分词结果可以表示为:
l 分词结果:上海 计划 到 本 世纪 末 实现 人均 国内 生产 总值 五千美元 。
l 构词位置:上/B 海/E 计/B 划/E 到/S 本/S 世/S 纪/E 末/S 实/B 现/E 人/B 均/E 国/B 内/E 生/B 产/E 总/B 值/E 五/B 千/M 美/M 元/E 。/S
字本位分词方法把词表词和未登录词一视同仁,把分词位置转变为词位的标注问题,然后通过词位得到分词结果。
字本位分词的特征
常用的特征包括字本身和词位转移概率,一般前后各两个字的窗口即可。
MSRA的n元特征模板集合
| 模板集 | 类型 | 特征 |
|
MSRA 特征模板 | Unigram | , n=-1,0,1 |
|
Bigram | , n=-1,0 | |
|
|
代表当前字,如 表示前一个字, 表示后一个字。
三类词位标记集
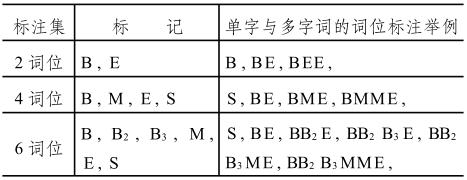
6词位包括:B、B2、B3、M、E、S。
B 和E表示多字词的首尾位置。S表示单字词。B2和B3表示多字词的第2和第3个位置,这种多字词的长度大于2字词和3字词。M表示长度大于4字的词中的其它位置。
特征模板集和词位标记集的不同应用会带来不同的分词结果。
字本位的表现
字本位的Unigram模板分词方法的总体表现不及最大匹配,但在未登录词的识别准确率上要好。字本位的Bigram模板的表现由于最大匹配。
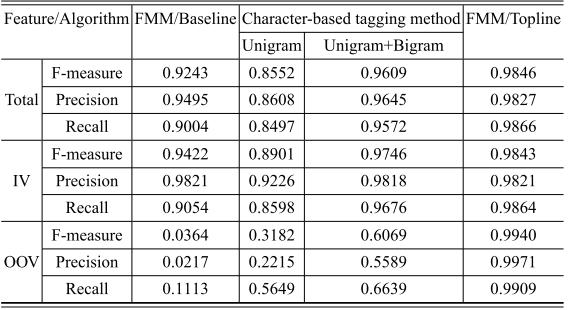
微软2006年的字本位分词系统
特征模板集合
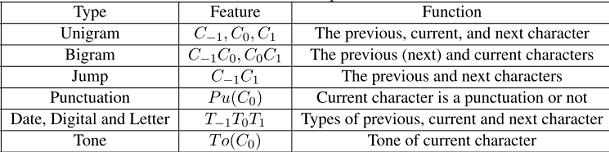
标记集采用上文提到的6种位置标记。
字本位分词系统的实现:
1. 从文献【4】下载CRF++工具包,编译,并注意阅读doc/index.html。
2. 根据预先定义的特征模板组织数据。训练语料采用北大人民日报,大约135MB。
3. 分词语料转换为词位格式。例如:“解放思想 、 实事求是 , 是 邓小平理论 的 精髓”转换为:“解/B 放/B2 思/B3 想/E 、/S 实/B 事/B2 求/B3 是/E ,/S 是/S 邓/B 小/B2 平/B3 理/M 论/E 的/S 精/B 髓/E”。
4. 词位格式转换为CRF++输入格式。“迈 n_punc n_num B”、“向 n_punc n_num E”。
参考文献:
【1】 黄昌宁, 赵海. 2007. 中文分词十年回顾. 中文信息学报, 第3期.
【2】 Hai Zhao, Chang-Ning Huang and Mu Li. 2006. An Improved Chinese Word Segmentation System with Conditional Random Field. Proceedings of the Fifth SIGHAN Workshop on Chinese Language Processing (SIGHAN-5).
【3】 参考ACL下属的“中文处理专业委员会”SIGHAL网址:http://www.sighan.org.
【4】 CRF工具包:http://chasen.org/~taku/software/CRF++.
前两天用字本位的模型进行分词实验,在16核的机器上用10个线程训练900MB的训练语料,整整训练了2天,不过分词准确率还可以。















 2957
2957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









