






日常生活中,你是否经常通过微信识图,获取图片中的文字信息?除此之外,还有拍照搜题、拍照翻译、证件信息提取、物流信息识别等等,都归功于 OCR 技术的支持。
随着深度学习技术的不断发展,智能 OCR 算法与应用日益丰富,对相关数据的需求也随之增加。
本文将介绍几个 OCR 开源工具包和数据集,以帮助开发者们更好地进行文字识别相关的工作。
Surya
Surya 是多语言文档 OCR 工具包,可进行准确的文本行检测,目前支持 90 多种语言,以及即将推出表格和图表检测功能。
开源地址:https://github.com/VikParuchuri/surya

EasyOCR
EasyOCR 是一个用 Python 编写的 OCR 库,用于识别图像中的文字并输出为文本,支持 80 多种语言和常用书写文字。
开源地址:https://github.com/JaidedAI/EasyOCR

MMOCR
MMOCR 是基于 PyTorch 和 mmdetection 的开源工具箱,专注于文本检测,文本识别以及相应的下游任务,如关键信息提取。
开源地址:https://github.com/open-mmlab/mmocr

PaddleOCR
PaddleOCR 是基于飞桨的 OCR 工具库,包含总模型仅 8.6M 的超轻量级中文 OCR,单模型支持中英文数字组合识别、竖排文本识别、长文本识别。同时支持多种文本检测、文本识别的训练算法。
开源地址:https://github.com/PaddlePaddle/PaddleOCR

CnOCR
CnOCR 是 Python 3 下的文字识别 OCR 工具包,能够识别简体中文、繁体中文(部分模型)、英文和数字等常见字符,并支持竖排文字的识别。该工具包内置了 20 多个预训练模型,可满足各种不同的应用需求,用户安装后即可立即投入使用。
开源地址:https://github.com/breezedeus/CnOCR

COCO-Text V2.0
COCO-Text 数据集包含 63686 幅图像,239506 个文本实例。包括手写版和打印版,清晰版和非清晰版,英语版和非英语版。
下载地址:https://bgshih.github.io/cocotext/


SynthText in the Wild dataset
该数据集是一个合成数据集,包含 800 万幅图像,80 万个合成词实例。每个文本实例都使用其文本字符串、字级和字符级边界框进行标注。
下载地址:https://www.robots.ox.ac.uk/~vgg/data/scenetext/

Uber Text dataset
Uber Text 数据集包含从车载传感器采集的街道级图像和由图像分析师团队标注的 Ground Truth。
特点如下:
街道图像及其文本区域多边形和相应文字说明
包含企业名称、街道名称和街道编号文本等 9 个类别
包含超 11 万幅图像
每幅图像平均有 4.84 个文本实例
下载地址:https://s3-us-west-2.amazonaws.com/uber-common-public/ubertext/index.html
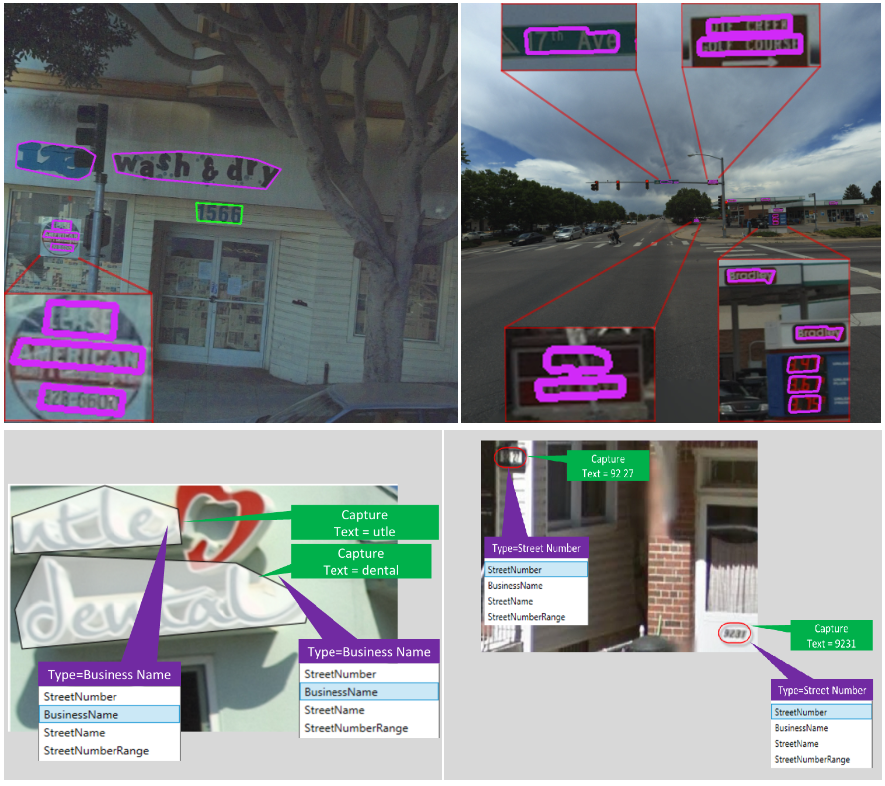
Chinese Text Dataset in the Wild(CTW)
CTW 是由清华大学与腾讯联合推出的一个大型中文自然文本数据集,包含 32285 幅图像,1018402 个中文字符,3850 个字符类别和 6 种属性。
下载地址:https://ctwdataset.github.io/

MSRA Text Detection 500 Database(MSRA-TD500)
MSRA-TD500 数据集包含 500 幅自然图像,使用袖珍相机从室内(办公室和商场)和室外(街道)场景进行拍摄。室内图像主要是标志牌、门牌和警示牌,室外图像主要是复杂背景下的引导牌和广告牌。
下载地址:http://www.iapr-tc11.org/mediawiki/index.php/MSRA_Text_Detection_500_Database_%28MSRA-TD500%29

趋动云拥有高性能的计算资源,能够快速处理海量数据,为文本识别算法提供强大的支持。此外,趋动云还拥有上千条数据集,包括文本相关的DocRED等。这些数据集可供开发人员一键使用,助力开发人员快速实现文本识别算法的开发和测试。
趋动云
连接算力・连接人
注册即可获得 168 元体验金!

更多福利,扫码添加小助手 邀你入群~
注册+关注,额外赠送 10 元算力金

请注册后联系小助手,立即领取
▼HOT
趋动云火热注册中!点击“阅读原文”即可尝鲜~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









