









尼恩说在前面:
在40岁老架构师 尼恩的读者交流群(50+)中,最近有小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、shein 希音、shopee、百度、网易的面试资格,遇到很多很重要的面试题:
说说sql 解析和优化的 原理?
说说一条 sql从 SQL输入 到结果 返回的执行过程?
前几天 小伙伴面试 京东,遇到了这个问题。但是由于 没有回答好,导致面试挂了。
小伙伴面试完了之后,来求助尼恩。 那么,遇到 这个问题,该如何才能回答得很漂亮,才能 让面试官刮目相看、口水直流。
所以,尼恩给大家做一下系统化、体系化的梳理,使得大家内力猛增,可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”,然后实现”offer直提”。
当然,这道面试题,以及参考答案,也会收入咱们的 《尼恩Java面试宝典》V145版本PDF集群,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
最新《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》的PDF,请关注本公众号【技术自由圈】获取,后台回复:领电子书
文章目录:
- 尼恩说在前面:
- 一条 sql 执行总体过程
- 第一:词法分析
- 什么是 词法分析器?
- 什么是 DFA?
- 第二:语法分析
- 什么是 语法分析 ?
- 抽象语法树(AST)
- 第三:预处理器 (类似语义分析)
- 第四:优化器(逻辑优化 → 物理优化)
- 4.1 逻辑优化 ( 生成 逻辑执行计划)
- 语句的执行顺序
- 逻辑算子
- 表达式分析
- 逻辑查询计划生成
- 子查询 的执行计划
- 逻辑执行计划 优化
- 4.2 物理优化( 生成 物理执行计划)
- 物理分析的核心目标
- 物理分析的关键步骤
- 1、 物理算子转换
- 2、 成本估算模型
- 3、 高级优化策略
- 物理查询计划示例
- 物理分析的挑战
- 物理分析总结
- 第五:执行器
- 存储引擎(InnoDB)
- 遇到问题,找老架构师取经
一条 sql 执行总体过程
一条SQL语句的执行过程可以大致分为以下几个步骤:
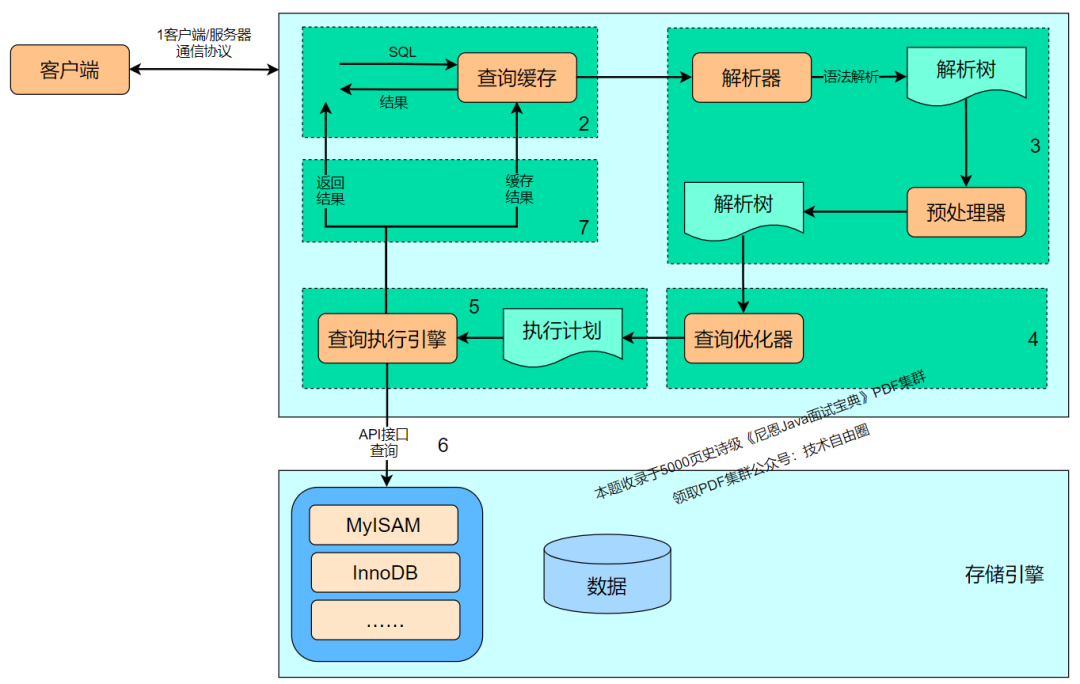
Client层:接收用户输入的SQL,显示响应的结果
Server层:对SQL进行格式的校验、语言分析、优化和执行,并对执行结果进行返回- 连接器:用户的认证和授权,对接口进行链接- 缓存:对查询结果进行缓存,并在对缓存进行查询时返回命中结果- 分析器:SQL的词法分析和语法分析- 优化器:生成SQL执行计划,操作索引进行数据的查询- 执行器:SQL操作引擎(如innodb 引擎),利用文件系统返回查询结果
文件系统层:对数据进行持久化
MySql中SQL语句核心执行流程如下:
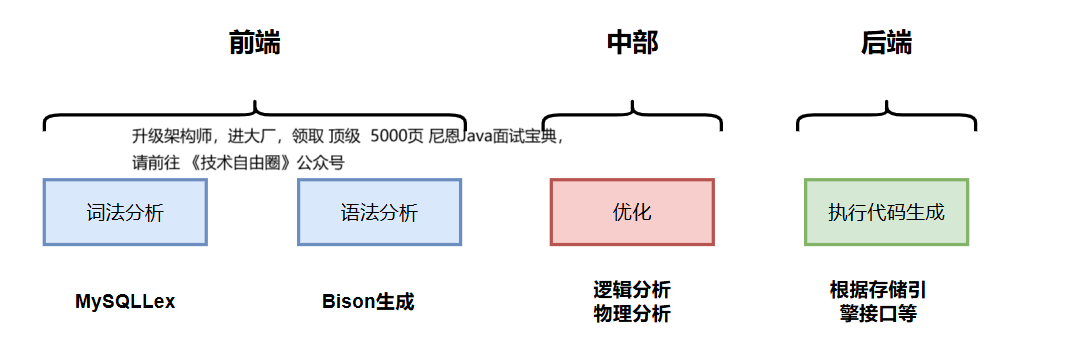
Mysql中sql语句执行顺序全景图:
SQL输入 → 解析器(词法分析 → 语法分析 → 语义分析)→ AST → 预处理器(类似语义分析)→ 优化器(逻辑优化 → 物理优化) → 物理查询计划 → 执行引擎 → 结果返回
核心步骤如下:
-
词法分析: 将SQL字符串拆解为原子单元(如关键字、表名、运算符等),生成Token序列
-
语法分析:验证Token组合是否符合SQL语法规则,构造抽象语法树(AST)描述查询结构
-
预处理器 ,根据一些 mysql规则进一步检查解析树是否合法。
-
逻辑优化:优化查询语义(如重写子查询、消除冗余列),生成逻辑执行计划(Logical Plan)
-
物理优化:将逻辑计划映射到物理操作(如选择索引、Join算法、数据分片策略),生成物理执行计划
-
执行代码:编译器或引擎将物理计划转换为底层可执行指令(如机器码/字节码),驱动数据库完成计算并返回结果。
下面重点分析SQL的解析和优化过程,包括词法分析、语法分析、逻辑分析和物理分析。
第一:词法分析
SQL解析与优化本质上属于编译器技术的一部分,和C语言等其他编程语言的处理方式没有本质区别。
SQL解析与优化 整个过程主要包括几个步骤:
-
词法分析 + 语法分析
-
语义分析
-
查询优化
-
物理执行计划。
SQL解析的主要目的,是把用户输入的一条“字符串”形式的SQL语句,转换成一种结构化的表示方式(称为结构体),让数据库系统能够理解并执行这条语句。
这个过程包括三个主要阶段:词法分析、语法分析和生成抽象语法树。
什么是 词法分析器?
词法分析器相当于扫描仪(专业叫DFA),将一串原始的字符流拆分成一个个有意义的基本单元——称之为“标记”(token)。
它基于预定义的一些语法规则,识别出关键字、标识符、数字、运算符等内容。
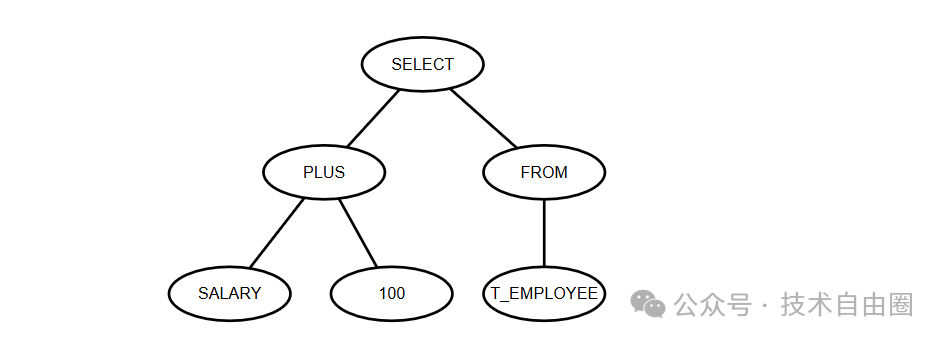
比如,下面这条简单的SQL语句:
下面这条简单的SQL语句:
SELECT
SALARY + 200
FROM
T_EMPLOYEE
经过词法分析后会被拆分成如下几个标记:
-
关键字:SELECT
-
标识符:SALARY
-
运算符:+
-
数值:200
-
关键字:FROM
-
标识符:T_EMPLOYEE
每个单词都被贴上类型标签,形成规范的碎片化元素。
这个过程消除了注释、空格等无效信息,为后续语法分析准备好结构化的数据原料。
在 SQL 解析过程中,词法分析器 就是一个 确定有限自动机 (DFA),它的主要任务是将输入的字符集按照预定义的词法规则转换为“单词”(即标记,tokens)。
这些单词是后续语法分析的基础,过程中的输入和输出分别是
-
输入:原始的字符流(如 SQL 语句)
-
输出:结构化的标记流(如关键字、标识符、数字等)
什么是 DFA?
DFA(确定有限自动机):就是一套“输入→处理→输出”的流水线机器,它干活的方式特别简单粗暴,
比如SQL解析中,DFA就像个“拆词小能手”,把SELECT A FROM B拆成:【关键词SELECT】→【字段A】→【关键词FROM】→【表名B】,中间遇到不认识的符号直接报错,绝不瞎猜
第二:语法分析
在词法分析完成之后,下一步就是语法分析。
什么是 语法分析 ?
sql解析执行包括了:词法分析,语法分析,分析机,生成语法树
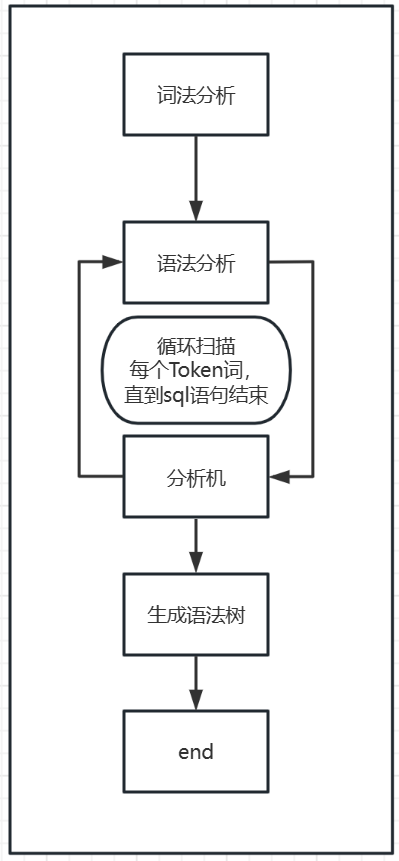
词法分析:从左到右一个字符、一个字符地输入,然后根据构词规则识别单词。
将会生成Token词
词法分析 在进行了词法分析以后,他会把sql默认扫描成两个部分,一个是关键字(select,insert,from,where,group by .......)一个是非关键字(查询的字段,查询的表,查询的筛选条件,分组条件)
语法分析,分析机:它们两个是一起工作的,它们对词法分析生成的Token词开始循环构造语法树,直到整个SQL语句扫描完成了,就构成了一棵语法树
语法分析 阶段会把词法分析生成的“单词”(也就是标记)作为输入,然后检查这些单词组合起来是否符合 SQL 的语法规则。
简单来说, 语法分析 要判断用户写的 SQL 语句是不是“结构正确”。
比如:
有这样一条语句:
SELECT SALARY + 100 FROM T_EMPLOYEE
语法分析器会认为这是合法的,因为它看起来结构完整:有查询字段、有表达式、也有数据来源(表名)。
但如果写成这样:
SELECT SALARY + 100 FROM
这就是一条不合法的语句,因为 FROM 后面没有指定表名,结构不完整。
这时候语法分析器就会报错,提示你缺少必要的内容。
总结: 语法判断的作用就是根据 SQL 的语法规范,判断用户写的语句是否格式正确,为后续处理打下基础。
语法分析的过程,就是 一步步构建出来 一科 抽象语法树(AST,全称 Abstract Syntax Tree) 。
值得注意的是,当SQL 关键字写错了,会在词法分析阶段报错,
比如,如果没有加上表名,或条件等格式错误了会在语法分析阶段报错
抽象语法树(AST)
抽象语法树(AST,全称 Abstract Syntax Tree)是用来表示用户输入的 SQL 语句的一种树状结构。
简单来说,它把一条 SQL 语句的“意思”用结构化的方式画成一棵树,每个节点代表一个词或一个操作,比如关键字、列名、表名、运算符等。
这棵 AST 树 是在语法分析过程中一步步构建出来的。
当语法分析顺利完成时,就会生成对应的抽象语法树。
这个树和用户输入的 SQL 是一一对应的,也就是说,输入的 SQL 字符串已经变成了数据库可以理解和处理的“结构体”。
举个简单的例子:原始 SQL 输入:
SELECT SALARY + 100 FROM T_EMPLOYEE
经过语法分析后,会生成一棵结构清晰的抽象语法树,树中包含以下信息:
-
查询类型是
SELECT -
要查询的内容是
SALARY + 100(其中SALARY是字段名,+是运算符,100是数值) -
数据来源是
T_EMPLOYEE表
通过这棵 AST 树,数据库就能清楚地知道这条 SQL 到底要做什么,为后续的执行和优化打下基础。
语法分析就是生成语法树的过程。这是整个解析过程中最精华,最复杂的部分。
这部分MySQL使用了Bison来完成。
如何设计合适的 AST 数据结构以及相关算法,去存储和遍历所有的信息,非常值得大家去理解,去研究。
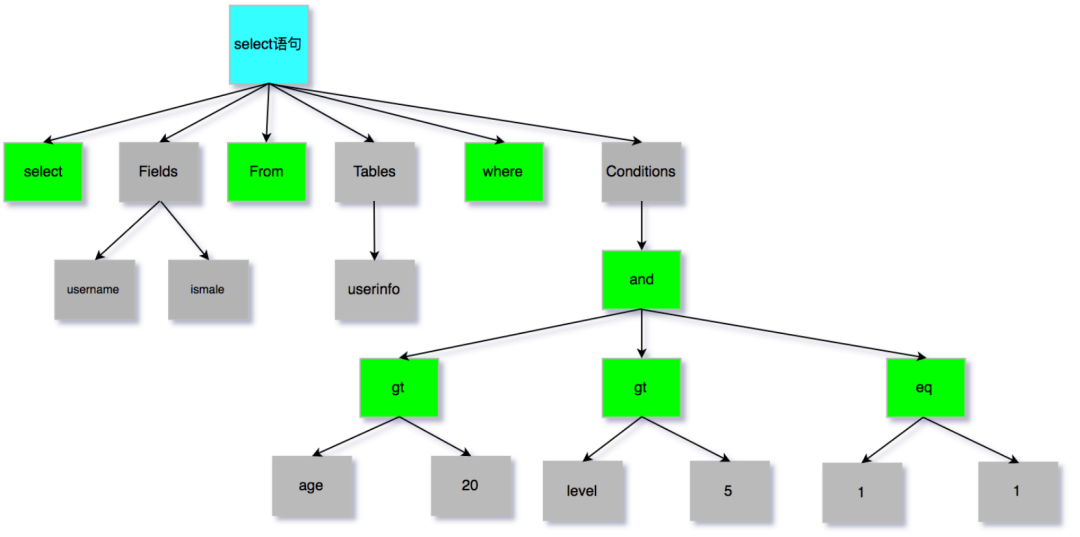
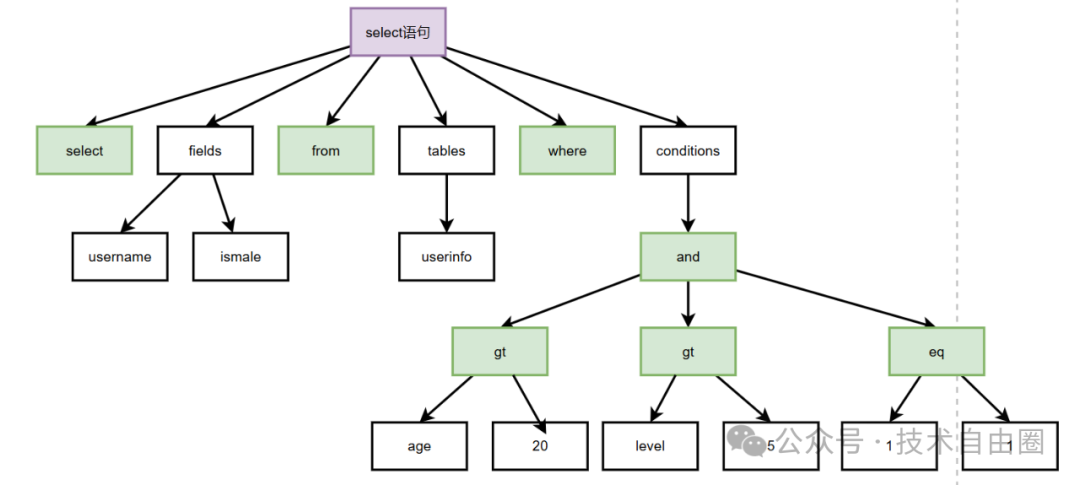
再给个简单案例,SQL语句如下:
select username, ismale from userinfo where age > 20 and level > 5 and 1 = 1
会生成如下 AST 语法树。
第三:预处理器 (类似语义分析)
预处理器 ,根据一些 mysql规则进一步检查解析树是否合法。
如检查查询的表名、列名是否正确,是否有表的权限
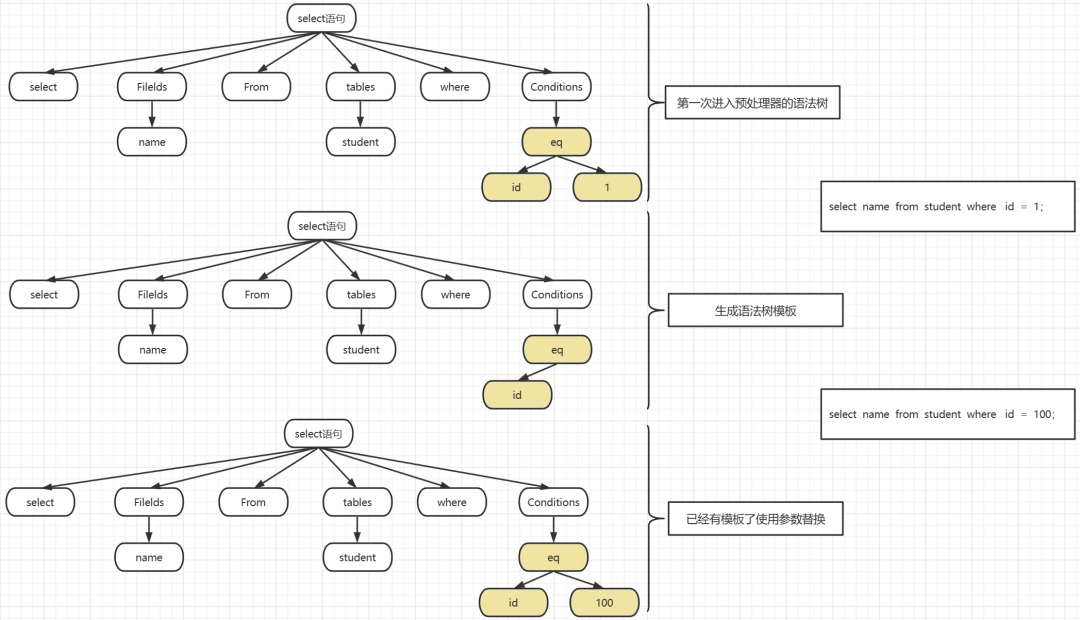
这一步操作目的是解决原来每一句sql都会单独解析执行的问题,后来变成了使用预处理器,对于相同的命令模板,不断的替换参数,减少对表权限和语法树是否合法的计算
生成命令模板:对于第一次进入的sql语句肯定是没有命令模板的,所以它需要参与生成命令模板 ,比如select id from student where id =1; 那么 “ select id from student where id = ” 就会成为模板
当模板生成了以后,对于student这个表,属性为id的字段,这个模板是已经检查过有没有权限的了,它在这个模板上都是有记录的
替换参数条件:这是对于有模板的情况下,我们就会直接使用参数替换的形式,把命令完成,比如这个时候有一条sql:select id from student where id = 100 ;很显然,上次我们已经生成过模板了,
就可以直接用,模板就是select id from student where id = 这个时候就只需要把参数替换掉,这次 id = 100;就把原来的 1 替换为100 ,
这样做的好处就是,不用再去检查语法树合不合法了,不用去看表是否有没有权限了,
因为在生成模板的时候这些操作都是做过的了,如果模板语法树不合法,拿这次的sql也不合法,如果模板没有student表的权限,那么这次也没有
极大避免了二次计算和操作,对性能的提升非常大
经过了预处理器以后,就拿到了这句sql是否有执行的权力,即能否更改表和查询表的权力,
如果权限没有问题,那么就可以进行下一步:SQL优化
第四:优化器(逻辑优化 → 物理优化)
接下来,就是结合 AST 语法树, 进行优化 。
当语法树被认为是合法的了,并且由优化器将其转化成执行计划。
一条查询可以有很多种执行方式,最后都返回相同的结果。
优化器的作用就是找到这其中最好的执行计划。
执行计划:mysql不会生成查询字节码来执行查询,mysql生成查询的一棵指令树,然后通过存储引擎执行完成这棵指令树并返回结果。
最终的执行计划包含了重构查询的全部信息。
查询的生命周期的下一步是将一个SQL转换成一个执行计划,mysql在依照这个执行计划和存储引擎进行交互。
这包含多个子阶段:解析SQL、预处理、优化SQL执行计划。
这个过程中任何错误都可能终止查询。
-
查询优化器:当语法树被认为是合法的了,并且由优化器将其转化成执行计划。一条查询可以有很多种执行方式,最后都返回相同的结果。优化器的作用就是找到这其中最好的执行计划。
-
执行计划:mysql不会生成查询字节码来执行查询,mysql生成查询的一棵指令树,然后通过存储引擎执行完成这棵指令树并返回结果。最终的执行计划包含了重构查询的全部信息。
在优化器的内部,是开发者定义的许多“优化规则”来进行优化的,如关联查询重排,索引优选,连接查询重组,优化排序,优化聚合函数,提前终止查询,等价变化等;
这里我们简单来列举一下索引优选:
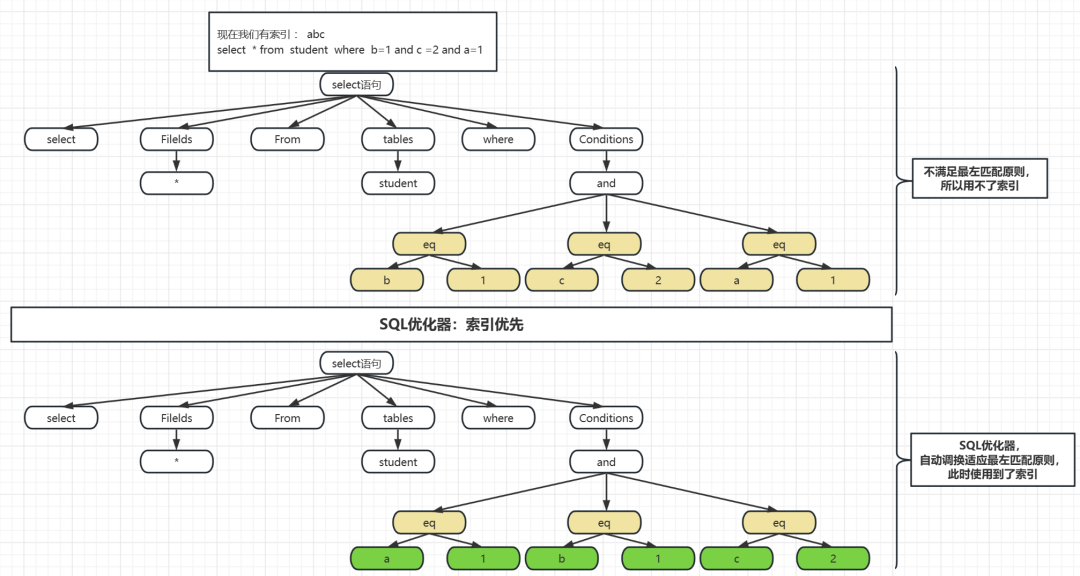
这个简单的例子应该可以感受到SQL优化器的作用是干什么的了,它内置很多规则,它贴合物理层,有自己的执行规则,同时又因为一些不合格的程序员写的sql不合规
SQL优化器非常重要,能到sql优化器处理的sql基本上语法都是没问题的,主要的是怎么提高sql的执行效率,这就是优化器最大的作用
只要SQL优化器处理完了以后,就会生成执行计划,这个执行计划就是存储引擎的处理单元
生成执行计划以后,他就会交给执行器,去调用存储存储引擎的相应Headler API来完成相应的执行计划
逻辑优化 → 物理优化 是整个 SQL 解析过程中最复杂、最关键的一个阶段,它不仅关系到 SQL 语句的含义是否正确,还涉及到后续的查询优化和执行效率。
逻辑优化 → 物理优化 的对比如下:
| 维度 | 逻辑优化 | 物理优化 |
| 优化目标 | 语义等价性 | 执行效率最大化 |
| 关注层级 | SQL语句结构 | 存储引擎与硬件交互 |
| 典型操作 | 子查询展开、谓词下推 | 索引选择、缓存策略调整 |
| 典型输出 | 逻辑执行计划 | 物理 执行计划 |
| 依赖信息 | 表结构、约束条件 | 数据分布统计、索引元数据 |
4.1 逻辑优化 ( 生成 逻辑执行计划)
顾名思义, 逻辑分析过程就是要分析一下输入的SQL语句到底是干什么的,都有哪些操作。然后生成 逻辑查询计划,并且进行优化。
一般来讲, 一个SQL语句总有一个输入,一个输出,输入数据经过SQL加工后得到输出数据。
语句的执行顺序
标准SQL语句基本可以分解成下面7大块:
(5)SELECT
(6)DISTINCT < select list >
(1)FROM < table source >
(2)WHERE < condition >
(3)GROUP BY < group by list >
(4)HAVING < having condition >
(7) ORDER BY < order by list >
计算机执行这些语句时,会按照标号 1 到 7 的顺序依次处理。
不过,有些部分是可以不写的,比如 where 子句。
如果一个sql语句的某个阶段 没写,计算机就直接跳过这一阶段。
注意:开头的 select 子句并不是最先执行的,而是处于第5个阶段,这是因为 SQL 语句这样设计,能让写代码的人更容易理解和使用,更贴合大家日常的思考习惯。
逻辑算子
在SQL处理过程中,定义了一些基本的逻辑算子(Operator),它们是执行特定操作的最小不可分割单元。以下是这些算子及其对应的基本操作:
-
TableScanOperator (TS):用于FROM操作,表示从哪个表读取数据。 -
FilterOperator (FIL):对应WHERE和HAVING操作,用于根据条件筛选数据。 -
GBYOperator (GBY):涉及GROUP BY和DISTINCT操作,用于对数据进行分组或去重。 -
JoinOperator (JOIN):负责JOIN操作,将两个或多个表的数据按照一定条件组合起来。 -
OrderByOperator (ORDER):执行ORDER BY和LIMIT操作,用来排序结果集,并可限制返回的结果数量。 -
UnionAllOperator (UNION):实现UNION和UNION ALL操作,合并多个查询的结果。 -
SelectOperator (SEL):对应SELECT操作,选择要显示的列或计算表达式。
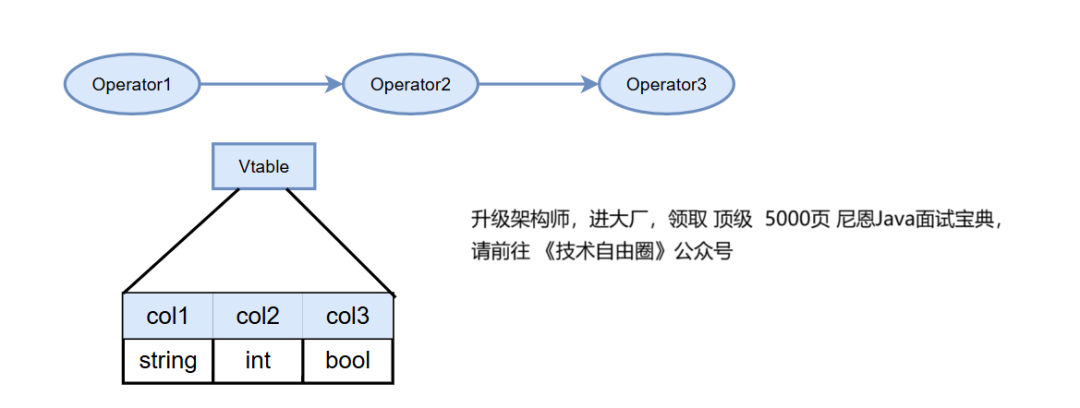
这些算子就像是构建块,通过它们可以构造出一个SQL查询的逻辑计划。
这个逻辑计划实际上是一个有向无环图(DAG),它展示了数据如何流动以及各个操作是如何连接在一起的。
每个算子通常都有输入和输出数据集,称之为“虚表”(vtable)。
这里的虚表不是实际存在的 数据表 ,而是逻辑上的概念,vtable 用于内部处理过程,帮助不同算子之间传递数据。
用户看不到这些 vtable 虚表,vtable 仅用于数据库系统内部管理数据流,vtable 作为算子之间的桥梁,确保数据能够按预期的方式被处理和传输。
上面的逻辑算子中,有两个 比较特殊,就是 JoinOperator (将两个或多个表的数据按照一定条件组合起来) 、 UnionAllOperator(合并多个查询的结果),这两个逻辑算子 需要处理两个或更多的输入数据集 vtable 来完成关联或合并的操作。
通过 vtable 虚表 ,整个查询就可以高效、有序地执行了。
表达式分析
在SQL中,很多子句都可以包含表达式。
例如:
SELECT SALARY + 1 FROM T_EMPLOYEE WHERE PRODUCT_NAME = 'CAT' GROUP BY SALARY + 1
这里SELECT、GROUP BY和WHERE子句都包含了表达式。
解析和计算这些表达式是SQL处理过程中的重要环节。
1、类型推导
分析表达式时,要对用户输入的常量进行类型推导并标记,规则简单,如:
| 输入 | 类型 |
| 100 | BIGINT |
| 100.1 | DOUBLE |
| 'HELLO' | STRING |
| TRUE | BOOLEAN |
2、隐式类型转换
有时,在函数调用时输入参数的类型可能不符合要求,这时就需要进行隐式类型转换。
例如,如果有一个函数fun(DOUBLE, DOUBLE),但你传入了一个整数和一个浮点数(如A—INT, B—DOUBLE),系统会尝试将整数转换成浮点数以便匹配函数签名。
比如1+2.5会被转换成double(1) + 2.5,先将整数转换为浮点数再进行加法运算。
3、布尔表达式分析
布尔表达式的分析有助于后续的SQL优化,如Join条件下推或分区裁剪等优化操作。
目的是简化复杂的布尔表达式,将其转化为最简合取范式(CNF),使表达式更易于理解和处理。
例如:
原始表达式 (T.A>10 AND P.B<100) OR T.B>10 可能被转换为 (T.A>10 OR T.B>10) AND (P.B<100 OR T.B>10)。
这个过程通常包括两步:- 使用Quine McCluskey算法生成CNF。- 利用Petrick's method算法找到最简合取范式。
4、CASE WHEN表达式分析
CASE WHEN是一个特殊的表达式,它可以像值函数一样使用,并且根据不同的条件返回不同的结果。
它有两种基本形式:
(1)、简单CASE函数:
CASE <expr>
WHEN <value> THEN <expr>
...
ELSE <expr>
END
(2)、搜索CASE函数:
CASE
WHEN <expr> THEN <expr>
...
ELSE <expr>
END
为了更好地在计算机中表示CASE WHEN表达式,把它抽象为一个三元组值函数:casewhen(condition, returnvalue1, returnvalue2)。
其中condition是判断条件,returnvalue1是满足条件时的返回值,returnvalue2是不满足条件时的返回值。这样就可以结构化地表达复杂的CASE WHEN逻辑,方便后续处理和优化。
例如:
CASE WHEN A>10 THEN (CASE WHEN B>10 THEN 10 ELSE NULL) ELSE 0
可以被转换成一个表达式树,便于计算机理解和处理。
逻辑查询计划生成
有了前面的基础,现在可以开始构建查询计划了。
根据SQL语句的执行顺序,遍历编译阶段生成的抽象语法树(AST),每当遇到特定操作时就生成相应的算子,并对表达式进行分析处理,这样就可以有序地生成整个查询计划。
举个简单的例子:
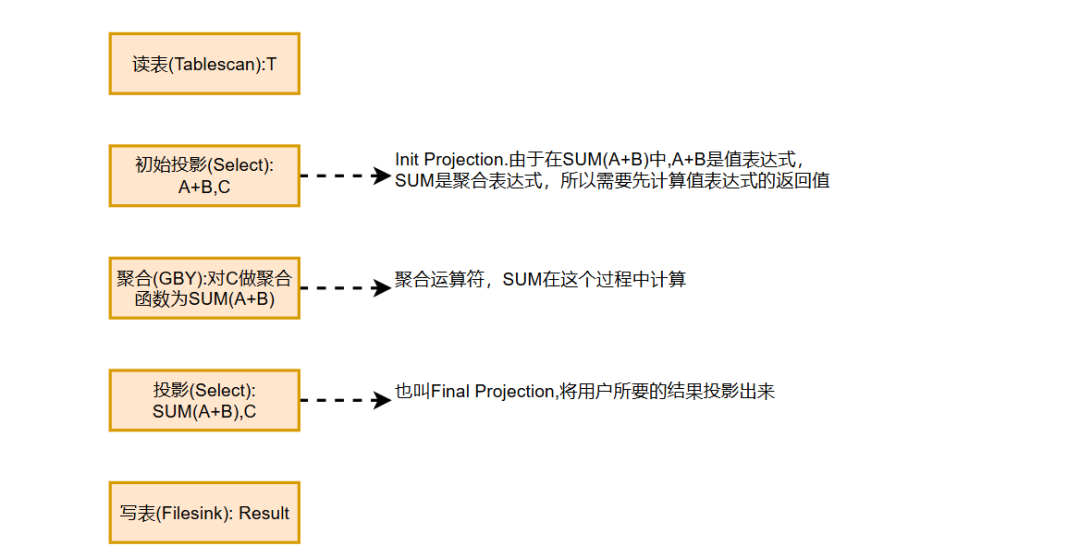
假设有如下SQL语句:
INSERT OVERWRITE TABLE Result
SELECT SUM(A + B), C
FROM T
GROUP BY C;
针对这条语句,需要构建一个查询计划,这个计划包含几个步骤:
-
首先,计算
A + B,这是为了聚合函数SUM做准备。 -
然后,从表
T中选取数据,并基于列C进行分组。 -
最后,对每个分组应用
SUM函数计算总和,并将结果插入到Result表中。
在这个过程中,有一个重要的概念叫做“初始投影”,它实际上是一个SelectOperator,用于预先计算那些在聚合函数或GROUP BY子句中使用的表达式。
比如,在上述例子中的A + B就需要通过初始投影来提前计算好,以便后续的聚合操作能够顺利进行。
早期的 SQL语法不支持在GROUP BY或聚合函数中直接使用表达式,用户如果想要实现类似的功能,只能借助子查询来完成。
随着SQL语法的扩展,现在可以直接在这些地方使用表达式,因此在解析SQL时需要判断是否需要添加初始投影步骤来确保表达式的正确计算。
此外,还有许多其他类型的SQL结构没有涵盖进来,例如JOIN、UNION ALL以及窗口函数等,它们各自有着不同的查询计划构建方式。
无论是 JOIN、UNION ALL以及窗口函数 还是 GROUP BY或聚合函数, 核心思想都是相同的:根据SQL语句的具体要求,合理安排操作顺序,确保每一步都能准确无误地执行。
子查询 的执行计划
SQL 的语法是支持嵌套的,也就是说可以在 FROM 后面写一个完整的子查询,把它当作一张临时表来使用。
这种结构也叫做“派生表”。
举个简单的例子:
SELECT COUNT(*)
FROM (
SELECT A.ID, B.NAME
FROM T_EMPLOYEE A
JOIN BEEF B
) S;
这个语句的意思是:先执行括号里的子查询,取出 T_EMPLOYEE 表和 BEEF 表连接后的结果,然后外层再统计行数。
在生成查询计划时,是这样处理的:
-
先为子查询部分生成它自己的逻辑计划,等它执行完后,会输出一个中间结果(虚表)
-
这个 中间结果(虚表) ,就作为外层查询的数据来源。整个过程就像是“先做小查询,再做大查询”。
这种结构虽然看起来嵌套复杂,但其实逻辑很清晰:从内到外,一层一层地执行。
这种方式让 SQL 更加灵活,也能帮助写出更清晰、更有层次感的查询语句。

逻辑执行计划 优化
生成逻辑查询计划后,需要对其进行一些基础的优化,以去除明显不必要的计算步骤,提升整体效率。
主要包含以下三种优化:
1、常量表达式的提前计算
比如在以下 SQL 语句中:
SELECT 1+2 FROM T_EMPLOYEE
"1+2"是一个常量表达式,可以在查询执行前就将这个结果(即3)计算出来,并直接使用该结果替换原表达式,这样在实际运行时就不需要重复计算了。
2、列裁剪
当从数据库表中读取数据时,默认情况下会读取所有列的数据。
然而,在很多情况下,用户只需要用到其中几列的数据。
例如,如果用户只关心某几列用于计算,那么其他列就是多余的,读取它们只会增加不必要的时间和资源消耗。
通过列裁剪,可以去掉这些不需要的列,减少数据处理量。
3、谓词下推(Predicate Pushdown)
在进行表连接(JOIN)操作时,有时还需要在连接后应用过滤条件(WHERE)。
这时,可以通过谓词下推技术,把某些过滤条件提前到连接之前执行。
谓词下推(Predicate Pushdown) 可以减少参与连接的数据量,从而提高效率。
例如,考虑以下 SQL 语句:
SELECT * FROM A JOIN B ON A.ID = B.ID WHERE A.AGE > 10 AND B.AGE > 5
下图左边优化前,右边优化后,
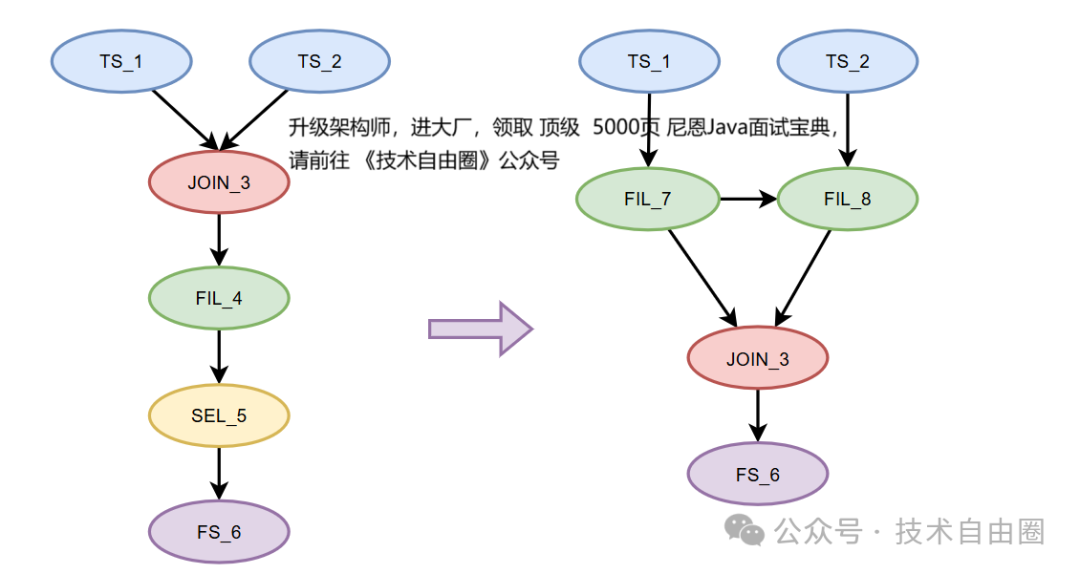
在优化前,可能会先完成两个表的连接,然后再应用过滤条件。
优化后,则是首先根据A.AGE > 10 和 B.AGE > 5 这些条件过滤掉不符合要求的数据,再进行连接操作。
这样一来,减少了需要连接的数据量,提高了执行效率。
通过上述优化措施,可以有效减少不必要的计算和数据传输,使查询更加高效。
比如,对于前面提到的例子,优化后的查询计划能够显著降低JOIN操作的数据量,从而加快整个查询过程的速度。
4.2 物理优化( 生成 物理执行计划)
在完成逻辑分析(验证SQL语义正确性并生成逻辑查询计划)后,MySQL进入物理分析阶段,其核心目标是将逻辑计划转化为可高效执行的物理查询计划。
物理分析 阶段是SQL优化器的核心战场,直接决定了查询的执行速度和资源消耗效率。
物理分析的核心目标
物理分析聚焦于以下三个关键维度:
1、 执行效率最大化
在保证结果正确的前提下,选择最优的物理执行路径(如索引扫描 vs 全表扫描)。
2、 资源消耗最小化
通过算法优化降低CPU、内存、磁盘I/O的使用量。
3、 执行稳定性保障
避免极端场景下的性能波动(如内存溢出或大量随机I/O)。
物理分析的关键步骤
1、 物理算子转换
将逻辑算子映射为具体的物理操作符,其选择依赖于存储引擎特性与统计信息:
| 逻辑算子 | 可能的物理实现方式 |
| TableScan | 全表扫描(Seq Scan) / 索引扫描(Index Scan) / 覆盖索引扫描(Covering Index Scan) |
| Filter | 条件提前过滤(Pushdown) / Bloom过滤器 / 位图扫描(Bitmap Scan) |
| Join | 嵌套循环连接(Nested Loop) / 哈希连接(Hash Join) / 排序合并连接(Merge Join) |
| GroupBy | 哈希聚合(Hash Aggregate) / 排序分组(Sort Group) |
| OrderBy | 内存排序(In-Memory Sort) / 外排序(External Merge Sort) |
示例转换策略
对于逻辑算子JOIN:
-
小表驱动大表 → 选择嵌套循环连接(Nested Loop)
-
等值连接且内存充足 → 选择哈希连接
-
数据已预排序 → 选择排序合并连接
2、 成本估算模型
MySQL优化器通过成本模型评估不同物理路径的代价,核心参数包括:
总成本 = (数据页读取成本 × 页数)
+ (记录处理成本 × 行数)
+ (内存排序成本 × 排序数据集大小)
+ (网络传输成本 × 结果集大小)
关键统计信息:
-
表级元数据:行数、数据页数量、平均行长度
-
索引元数据:B+树高度、不同键值数量(Cardinality)、索引覆盖率
-
系统参数:内存缓冲区大小、磁盘I/O速度、可用并发线程数
动态调整机制:
当发现WHERE product_id = 1005的选择性(Selectivity)实际为1%(而非统计信息预测的10%),优化器可能动态切换到全表扫描。
3、 高级优化策略
| 优化类型 | 实现方式 | 适用场景示例 |
| 索引跳跃扫描 | 对复合索引 |
|
| 批处理Key访问 | 对 |
|
| 自适应哈希 | 动态构建内存哈希表,将随机I/O转为顺序I/O | 高频重复访问热点数据 |
| 物化视图重写 | 自动用预计算的物化视图替换原始表查询 | 复杂聚合查询(如日报表统计) |
物理查询计划示例
以电商订单查询为例:
SELECT o.order_id, u.username
FROM orders o
JOIN users u ON o.user_id = u.id
WHERE o.amount > 1000
ORDER BY o.create_time DESC
LIMIT 100;
生成的物理计划可能包括:
1、 索引选择
对orders表使用idx_amount索引快速过滤amount>1000
对users表主键PRIMARY进行点查
2、 连接算法
采用块嵌套循环连接(BNLJ),利用Join Buffer批量处理
3、 排序优化
使用idx_create_time索引反向扫描,避免显式排序
4、资源控制
启用优先级队列(Priority Queue)快速获取TOP 100结果
物理分析的挑战
1、 统计信息滞后
当表数据频繁变更时,过时的统计信息可能导致优化器选择次优计划。
2、多目标权衡
需要平衡响应时间、资源消耗、执行稳定性等矛盾目标。
3、硬件特性适配
SSD与HDD的I/O特性差异需要不同的优化策略。
物理分析总结
物理分析是数据库系统的"执行指挥官",它通过:
-
将逻辑计划转化为可落地的物理操作
-
基于成本模型选择最优执行路径
-
动态适配数据特征与硬件环境
最终输出一个由物理操作符(如IndexScan、HashJoin等)组成的 物理执行计划,交由存储引擎执行。
这个过程体现了数据库系统在理论(关系代数)与实践(硬件约束)之间的精妙平衡。
第五:执行器
这里的执行器和操作系统的操作系统差不多,都是负责调用和分发的,在sql执行中,执行器扮演两个角色
-
执行器 调用存储引擎的 API (Headler API )处理执行计划
-
执行器 接收存储引擎返回的结果,并将它返回给服务器端
存储引擎(InnoDB)
大家常说的索引查询,遍历查询,临时表查询等等行为都是在存储引擎中完成的
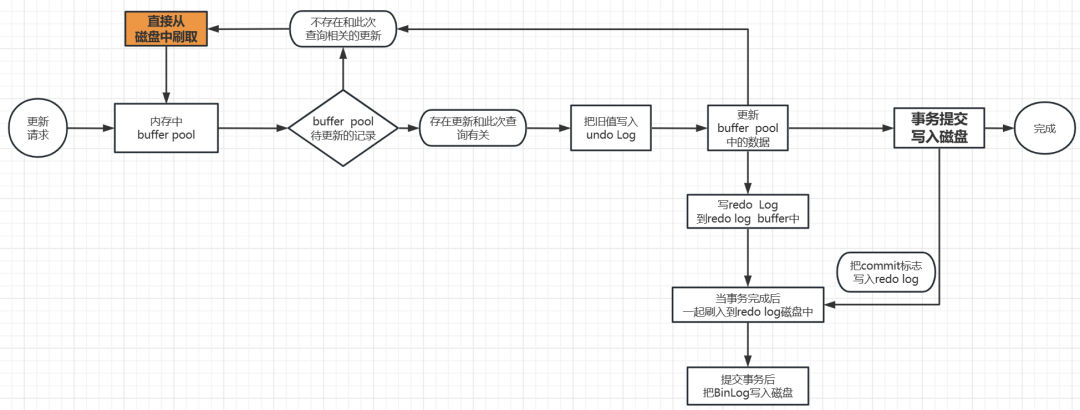
由于 内存的读写速度比硬盘的快,所以mysql 存储引擎(InnoDB) 有了Buffer Pool ,这里当一个查询计划来了以后,他首先会去Buffer Pool中查看是否有关这次查询的相关更新,
如果没有,就会直接去磁盘中刷出数据到Buffer Pool中,然后由存储引擎负责返回给MySQL执行器,最后返回给服务器端
当Buffer Pool中有关此次查询的更新时,需要等到存储引擎把旧的值放到undo Log(用于事务回滚的日志)中,然后就会更新Buffer Pool和把更新数据刷入到磁盘,此时就可以去根据查询条件,查询数据到Buffer Pool中。
执行器 接收存储引擎返回的结果, 然后返回给MySQL执行器


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









