








**DeepLearning: Pytorch基础**
什么是Pytorch
Pytorch是一个基于python的库,用它可以方便地构建深度学习模型并应用在不同的领域。但是它不仅仅是另一个深度学习库那么简单,他也是一个科学计算软件包。作为一款基于python的科学计算软件包,主要有两大特色:
- 代替Numpy使用GPUs的能力;
- 一个拥有很大灵活度和速度的深度学习研究平台;
Pytorch使用 Tensor 作为他的核心数据结构,这一结构与Numpy数组是很类似的。为何要使用这种特殊的数据结构?是因为在合适的软件和硬件环境下,Tensor可以为各种数学运算提供加速。在深度学习中有大量的数学操作存在,所以这种加速会带来显著的优势。
Pytorch, 与python类似,重点在它的易用性,让即使是仅有基本编程知识的人也可以应用深度学习在他们的项目中。所以对于从未用过深度学习库的人来说,Pytorch可以作为第一个深度学习库来入门。
为什么学习Pytorch
有大量的深度学习库可供使用:keras,Tensorflow,caffe,Theano等等,那么为何选择Pytorch入门?
一个理想的深度学习库应该是容易学习和使用的、足够灵活使其能应用在各种场景、效率高以便我们可以处理大浪的真实数据集、并且足够精确,即使在输入数据存在不确定性的情况下也能够提供正确的结果。Pytorch在这些方面都有足够的优势。“pythonic”编程风格使其易学易用、GPU加速、支持分布式计算和自动梯度计算有助于从正向表达
式开始自动执行反向传递。
当然,由于Python,它面临着运行速度慢的固有问题,但是高性能的C++ API可以一定程度抵消这一问题。这使得从研发到生产的过渡非常顺利。
Pytorch库总览
既然我们已经讨论了pytorch及其独特之处,那么让我们来看一下pytorch项目的基本流程:
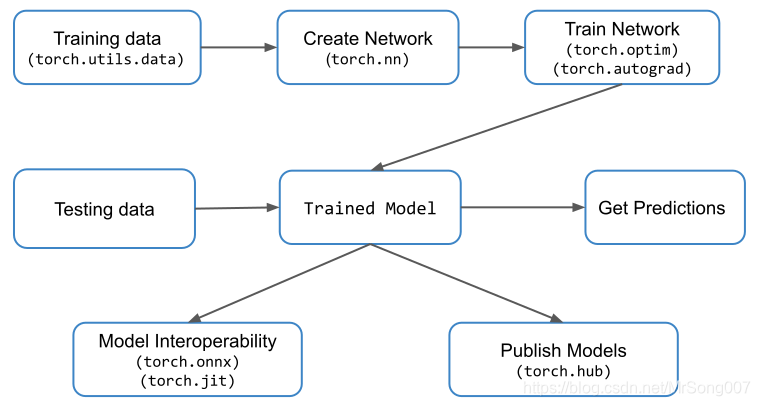
重要的pytorch模块可以分为以下几个:torch.nn, torch.optim, torch.utils 、torch.autograd
数据加载和处理
在任何深度学习项目中,第一步都是数据加载和处理,pytorch也在 torch.utils.data 中提供相同的实用程序。这个模块中的两个重要类是 Dataset 和 DataLoader:
- Dataset 建立在Tensor 数据类型的基础上,主要用于自定义数据集;
- 当有一个大的 Dataset,并且希望在后台从 Dataset加载数据,以便准备好数据并等待训练循环时,这时我们需要使用 Dataloader;
如果我们可以访问多台机器或GPU,我们还可以使用torch.nn.dataparallel 和 torch.distributed。
构建神经网络
torch.nn 模块 用于创建神经网络。它提供了所有常见的神经网络层,如全连接层、卷积层、激活和消耗函数等。
一旦网络体系结构被创建,数据准备好被送入网络,我们就需要技术来更新权重和偏差,以便网络开始学习。这些实用程序在 torch.optim 模块中被提供。同样,对于后向传播所需的自动微分,我们使用 torch.autograd 模块。
模型预测与兼容性
模型经过训练后,可以用来预测测试用例的输出,或者是新的数据集的输出。这个过程被称为模型预测。
pytorch还提供了 torchscript,可用于独立于Python运行时运行模型。这可以被认为是一个虚拟机,其中的指令主要针对张量。
您还可以将使用pytorch训练的模型转换为 onnx等格式,这样您就可以在其他DL框架(如mxnet、cntk、caffe2)中使用这些模型。您还可以将ONNX模型转换为TensorFlow模型。
Tensors教程
到目前为止,在这篇文章中,我们已经讨论了pytorch以及它的各项特点。现在,我们将开始学习Tensor(pytorch中使用的核心数据结构)。
以下是Tensors 的维度示意图:
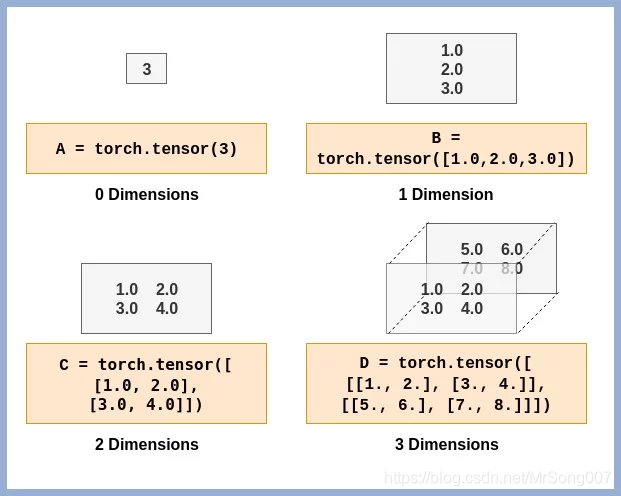
在开始介绍Tensors之前,首先安装PyTroch(安装教程近期会补上,或者目前可以使用 Google Colab进行以下学习,这是一个免费的 Jupyter 笔记本环境,不需要进行任何设置就可以使用,并且完全在云端运行 )
生成第一个 Tensor(张量)
import torch
# 创建一个元素值全是1的张量
a = torch.ones(5)
# 输出张量
print(a)
# 输出是:tensor([1., 1., 1., 1., 1.])
# 创建一个元素值全是0的张量
b = torch.zeros(5)
print(b)
# 输出是:tensor([0., 0., 0., 0., 0.])
# 创建自定义张量
c = torch.tensor([1.,2.,3.,4.,5.])
print(c)
# 输出是:tensor([1., 2., 3., 4., 5.])
# 创建二维张量
d = torch.zeros(3,2)
print(d)
#输出是: tensor([[0., 0.],
# [0., 0.],
# [0., 0.]])
e = torch.tensor([[1.,2.], [3.,4.], [3.,4.]])
print(e)
# 输出是:tensor([[1.,2.],
# [3.,4.]])
# [3.,4.]])
# 创建三维张量
f=torch.tensor([[1.,2.,2.],[3.,4.,2.]],[[5.,6.,2.][7.,8.,1.]])
print(f)
# 输出是:tensor([[1.,2.,2.],
# [3.,4.,2.]],
# [[5.,6.,2.],
# [7.,8.,1.]])
# 输出tensor的结构
print(f.shape)
#输出是:torch.Size(2,2,3) 输出是tensor的层级结构
获取张量的一个元素
print(f[0][0][1])
#输出是:tensor(2.0)
#输出所有元素
print(e[:])
# 输出是:tensor([[1.,2.],
# [3.,4.]])
# [3.,4.]])
#输出从索引0到1的所有元素
print(e[0:2])
输出是:tensor([[1.,2.],
# [3.,4.]])
#输出索引一直到2的所有元素(不包含索引为2的元素)
print(e[:2])
输出是:tensor([[1.,2.],
# [3.,4.]])
#输出第一行的所有元素
print(e[0,:])
输出是:tensor([[1.,2.]
用张量进行算术操作
# 创建张量
tensor1 = torch.tensor([[1,2,3],[4,5,6]])
tensor2 = torch.tensor([[-1,2,-3],[4,-5,6]])
# 相加
print(tensor1+tensor2)
# 或采用以下方式相加
print(torch.add(tensor1,tensor2))
# 输出是:tensor([[ 0, 4, 0],
# [ 8, 0, 12]])
# 相减
print(tensor1-tensor2)
# 或采用以下方式相减
print(torch.sub(tensor1,tensor2))
# 输出是: tensor([[ 2, 0, 6],
# [ 0, 10, 0]])
# 乘法
# Tensor with Scalar
print(tensor1 * 2)
# tensor([[ 2, 4, 6],
# [ 8, 10, 12]])
# 元素间相乘
print(tensor1 * tensor2)
# tensor([[ -1, 4, -9],
# [ 16, -25, 36]])
# 矩阵相乘
tensor3 = torch.tensor([[1,2],[3,4],[5,6]])
print(torch.mm(tensor1,tensor3))
# tensor([[22, 28],
# [49, 64]])
# 除法
# Tensor with scalar
print(tensor1/2)
# tensor([[0, 1, 1],
# [2, 2, 3]])
# 矩阵相除
print(tensor1/tensor2)
# tensor([[-1, 1, -1],
# [ 1, -1, 1]])
pytorch可以通过CPU和GPU来实现,每个张量都可以转换成GPU,以便进行大规模的并行、快速的计算。
# 创建 CPU 张量
# This will occupy CPU RAM
tensor_cpu = torch.tensor([[1.0, 2.0], [3.0, 4.0], [5.0, 6.0]], device='cpu')
# 创建 GPU 张量
# This will occupy GPU RAM
tensor_gpu = torch.tensor([[1.0, 2.0], [3.0, 4.0], [5.0, 6.0]], device='cuda')
# 转换 GPU 张量到 CPU
tensor_gpu_cpu = tensor_gpu.to(device='cpu')
# 转换 CPU 张量到 GPU
tensor_cpu_gpu = tensor_cpu.to(device='cuda')
下一节介绍:Pytorch 之用预训练模型做图像分类














 5378
5378











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









