









自从 ChatGPT 的出现引爆了人工智能的炒作之后,检索增强生成 (RAG) 就一直主导着关于如何让 Gen AI 应用程序变得有用的讨论。这个想法很简单。一旦我们将 LLM 与我们的私人数据联系起来,它就会变得特别有用。每个人都可以访问的基础模型,与我们特定领域的数据相结合,作为秘密武器,就会产生一种强大而独特的工具。就像在人类世界一样,人工智能系统似乎发展成一个专家经济。一般知识是一个有用的基础,但专业知识将制定出你的人工智能系统的独特卖点。
回顾:RAG 本身尚未描述任何特定的架构或方法。它仅描述了使用任意检索方法对给定生成任务进行增强。原始 RAG 论文(Lewis 等人撰写的《知识密集型 NLP 任务的检索增强生成》)将双塔嵌入方法与词袋检索进行了比较。
本地和全球问题
基于文本嵌入的检索已多次被描述。它已经允许我们的 LLM 应用程序非常可靠地根据给定知识库的内容回答问题。Text2Vec 检索的核心优势依然是:提取嵌入知识库中表示的给定事实,并根据提取的事实制定对用户查询的答案。然而,文本嵌入搜索也面临着重大挑战。通常,每个文本嵌入都代表非结构化数据集中的一个特定块。最近邻搜索会找到表示与传入用户查询在语义上相似的块的嵌入。这也意味着搜索是语义的,但仍然非常具体。因此,候选质量高度依赖于查询质量。此外,嵌入代表知识库中提到的内容。这并不代表您希望回答需要跨文档或知识库中文档内概念进行抽象的问题的情况。
例如,想象一个包含所有过去诺贝尔和平奖获得者简历的知识库。向 Text2Vec-RAG 系统询问“谁获得了 2023 年诺贝尔和平奖?”将是一个很容易回答的问题。这一事实在嵌入的文档块中得到了很好的体现。因此,最终答案可以基于正确的上下文。另一方面,RAG 系统可能会在询问“谁是过去十年最著名的诺贝尔和平奖获得者?”时遇到困难。在添加更多背景信息(例如“谁是对抗中东冲突的最著名的诺贝尔和平奖获得者?”)后,我们可能会成功,但即使如此,仅基于文本嵌入也很难解决这个问题(考虑到嵌入模型的当前质量)。另一个例子是整个数据集推理。例如,您的用户可能有兴趣询问您的 LLM 应用程序“最近的诺贝尔和平奖获得者支持的三大主题是什么?”。嵌入的块不允许跨文档推理。我们的最近邻搜索是在知识库中寻找对“最近诺贝尔和平奖获得者支持的三大主题”的具体提及。如果知识库中没有包含这一点,任何纯基于文本嵌入的 LLM 应用程序都会遇到困难,并且很可能无法正确、特别是详尽地回答这个问题。
我们需要一种替代的检索方法,让我们除了能够回答“局部”提取问题之外,还能回答这些“全局”、聚合问题。欢迎来到 Graph RAG!
知识图谱是一种半结构化、分层的信息组织方法。将信息组织成图谱后,我们就可以推断出有关特定节点的信息,以及它们之间的关系和邻居。图谱结构允许在全局数据集级别进行推理,因为节点及其之间的连接可以跨越文档。根据此图谱,我们还可以分析相邻节点和节点社区,这些节点之间的连接比它们与其他节点之间的连接更紧密。可以预期,一个节点社区大致涵盖一个感兴趣的主题。对社区节点及其连接的抽象可以让我们对该主题中的概念有一个抽象的理解。Graph RAG 使用对知识图谱中社区的这种理解来为给定的用户查询提出上下文。
Graph RAG 管道通常遵循以下步骤:
- 图提取
- 图存储
- 社区检测
- 社区报告生成
- 用于最终上下文构建的 Map Reduce
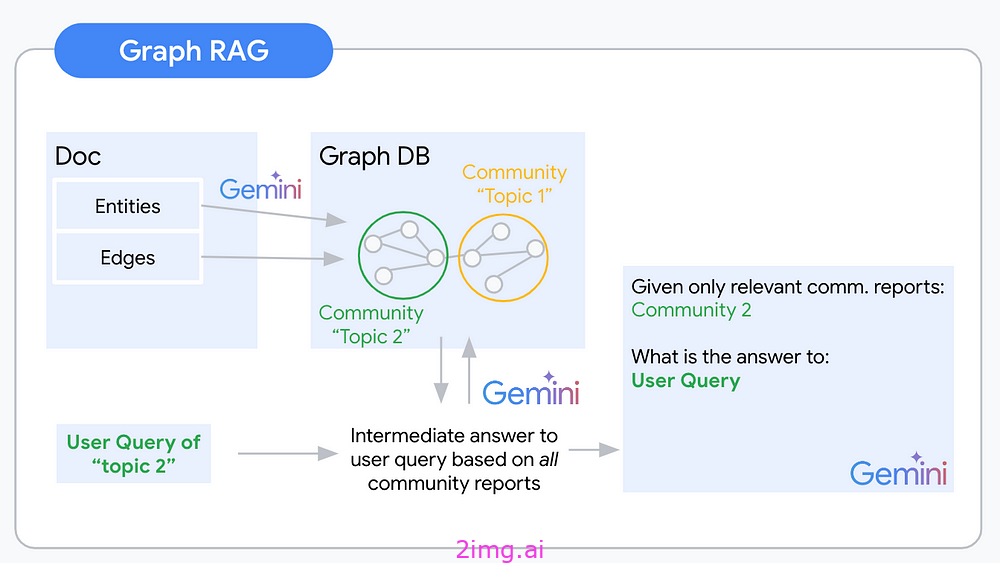
GraphRAG 逻辑可视化——来源:作者提供的图片
图提取
为我们的非结构化知识库构建抽象理解的过程始于提取将构建知识图谱的节点和边。您可以通过 LLM 自动执行此提取。此步骤的最大挑战是决定包含哪些相关概念和关系。举一个高度模糊的任务的例子:假设您正在从有关沃伦·巴菲特的文档中提取知识图谱。您可以将他的持股、出生地和许多其他事实提取为具有相应边的实体。这些信息很可能与您的用户高度相关。(使用正确的文档)您还可以提取他在上次董事会会议上领带的颜色。这(很可能)与您的用户无关。为应用程序用例和域指定提取提示至关重要。这是因为提示将决定从非结构化数据中提取哪些信息。例如,如果您有兴趣提取有关人员的信息,则需要使用与提取有关公司的信息不同的提示。
指定提取提示的最简单方法是通过多重提示。这涉及为 LLM 提供所需输入和输出的多个示例。例如,您可以为 LLM 提供一系列有关人员的文档,并要求其提取每个人的姓名、年龄和职业。然后,LLM 将学习从新文档中提取这些信息。指定提取提示的更高级方法是通过 LLM 微调。这涉及在所需输入和输出的示例数据集上训练 LLM。这可以带来比多重提示更好的性能,但也更耗时。
图存储
您设计了一个可靠的提取提示并调整了您的 LLM。您的提取管道可以正常工作。接下来,您必须考虑存储这些结果。图形数据库 (DB)(例如 Neo4j 和 Arango DB)是直接的选择。但是,通过另一种数据库类型扩展您的技术堆栈并学习一种新的查询语言(例如 Cypher/Gremlin)可能会很耗时。从我的高级研究来看,也没有很好的无服务器选项可用。如果处理大多数图形数据库的复杂性还不够的话,那么最后一个对于像我这样的无服务器爱好者来说就是杀手锏。不过还有其他选择。只要对正确的数据模型稍加创意,图形数据就可以格式化为半结构化甚至严格结构化的数据。为了激发您的灵感,我编写了 graph2nosql 作为一个简单的 Python 接口,用于在您最喜欢的 NoSQL 数据库中存储和访问图形数据集。
数据模型定义了节点、边和社区的格式。将这三者存储在单独的集合中。每个节点、边和社区最终通过唯一标识符 (UID) 进行识别。然后,Graph2nosql 实现了处理知识图谱时所需的几个基本操作,例如添加/删除节点/边、可视化图谱、检测社区等。
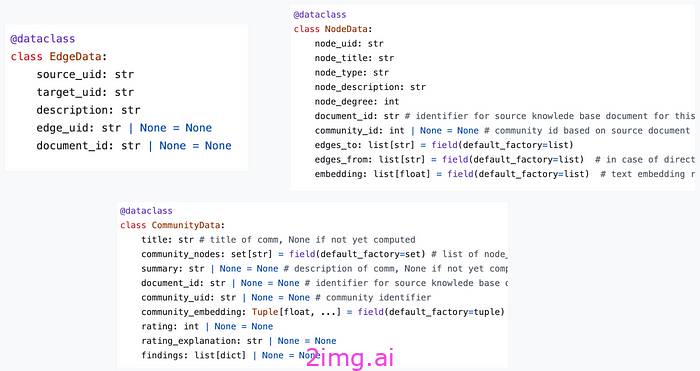
graph2nosql 数据模型 — 来源:作者提供的图片
社区检测
提取并存储图谱后,下一步就是识别图中的社区。社区是节点的集群,这些节点与图中其他节点的连接比它们更紧密。这可以使用各种社区检测算法来实现。
一种流行的社区检测算法是 Louvain 算法。Louvain 算法通过迭代将节点合并到社区中,直到满足某个停止标准。停止标准通常基于图的模块性。模块性是衡量图划分社区程度的指标。
其他流行的社区检测算法包括:
- Girvan-Newman 算法
- 快速展开算法
- Infomap算法
社区报告生成
现在使用生成的社区作为基础来生成社区报告。社区报告是每个社区内节点和边的摘要。这些报告可用于了解图结构并识别知识库中的关键主题和概念。在知识图中,每个社区都可以理解为代表一个“主题”。因此,每个社区都可能是回答不同类型问题的有用背景。
除了汇总多个节点的信息之外,社区报告是跨概念和文档的第一个抽象级别。一个社区可以跨越多个文档添加的节点。这样,您就可以构建对索引知识库的“全局”理解。例如,从您的诺贝尔和平奖获奖者数据集中,您可能提取了一个社区,该社区代表所有类型为“人”的节点,这些节点与节点“诺贝尔和平奖”相连,边缘描述为“获奖者”。
Microsoft Graph RAG 实现的一个绝妙想法是“发现”。除了一般的社区摘要之外,这些发现是对社区的更详细洞察。例如,对于包含所有过去诺贝尔和平奖获得者的社区,一项发现可能是将他们的大部分活动联系起来的一些主题。
与图提取一样,社区报告生成质量高度依赖于领域和用例适配的水平。要创建更准确的社区报告,请使用多镜头提示或 LLM 微调。
这里是 Microsoft graphrag 社区报告生成提示。
用于最终上下文构建的 Map Reduce
在查询时,您使用 map-reduce 模式首先生成中间响应和最终响应。
在映射步骤中,您将组合每个社区-用户查询对,并使用给定的社区报告生成对用户查询的答案。除了对用户问题的中间响应之外,您还要求 LLM 评估给定社区报告作为用户查询上下文的相关性。
在简化步骤中,您对生成的中间响应的相关性得分进行排序。前 k 个相关性得分代表对回答用户查询感兴趣的社区。相应的社区报告可能与节点和边缘信息相结合,构成您最终 LLM 提示的上下文。
结束语:这是要去哪里?
Text2vec RAG 在知识库问答任务方面存在明显缺陷。Graph RAG 可以弥补这些缺陷,而且效果非常好!通过社区报告生成附加的抽象层可以为您的知识库提供重要见解,并建立对其语义内容的全局理解。这将为团队节省大量筛选文档以获取特定信息的时间。如果您正在构建 LLM 应用程序,它将使您的用户能够提出重要的问题。您的 LLM 应用程序将突然能够思考并了解用户数据中发生的事情,而不是“仅仅”引用它。
另一方面,Graph RAG 管道(此处描述的原始形式)需要的 LLM 调用明显多于 text2vec RAG 管道。尤其是社区报告和中间答案的生成是潜在的弱点,在金钱和延迟方面会花费很多。
正如在搜索中经常出现的情况一样,您可以预期围绕高级 RAG 系统的行业将转向混合方法。在扩展 RAG 应用程序时,使用正确的工具来处理特定查询至关重要。例如,可以想象一个分类层来分离传入的本地和全局查询。也许社区报告和调查结果生成就足够了,将这些报告作为抽象知识添加到您的索引中作为上下文候选就足够了。
幸运的是,完美的 RAG 管道尚未解决,您的实验将成为解决方案的一部分。我很想听听您的进展如何!
















 189
189

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











