






这又是我学习的《linux内核实战》一篇笔记吧,做了些补充,为了便于自己的记忆,理解和整理下。一直对Linux的内存分配过程算是充满好奇,也看了些相关文章,不过有些和实际比较脱离,这两天学的这篇文章刚好是实例分析,值得好好总结下。先看一张图:
一 linux内存分配的过程
linux在进行分配内存的时候,是按照内存页进行分配的,程序开始申请的内存是虚拟内存,真正使用的时候,如果发现此虚拟内存对应的物理内存页不存在,就会发生缺页中断,系统就会查看是否有空闲的物理内存页,如果有,就直接分配;
如果没有就唤醒后台回收内存页进程(kswapd,实际进程名可能是kswapd0等后面0是对应的回收相关Node节点),kswapd是异步回收,满足一定条件就回收,所以对程序性能影响小. 再次获取空闲页,如果存在则直接分配,如果仍然没有释放出来空闲内存,则需要进入到直接回收阶段,直接回收内存需要判断下内存也是不是脏页,如果是脏页则需要回写数据到磁盘等存储设备中,然后再释放,这个过程是同步的过程对系统的性能影响较大.
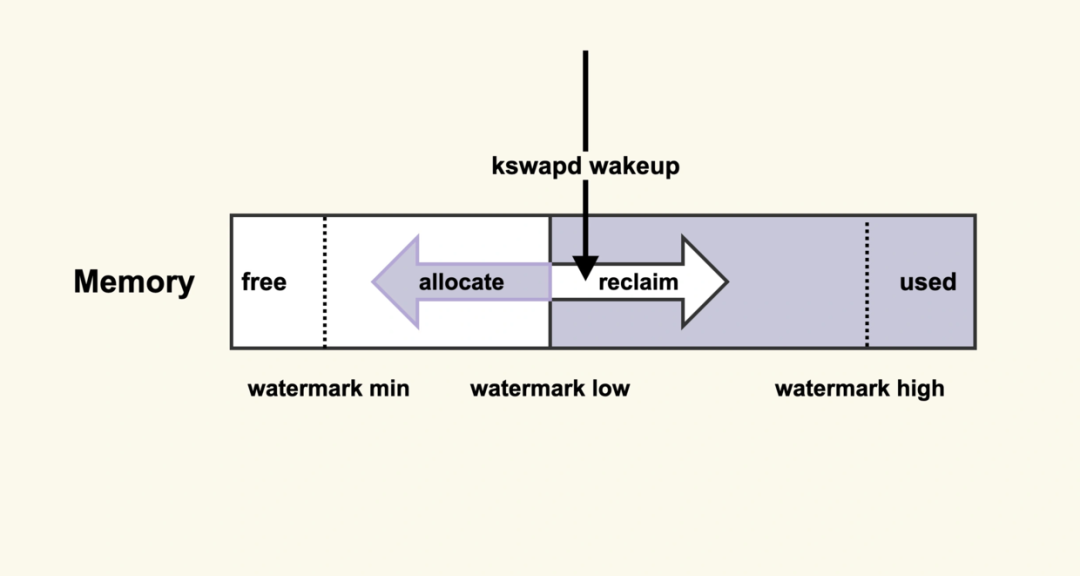
整个过程如下图所示:
kswapd把系统内存使用情况通过水位线定义分为四个部分:
当可用内存小于watermark.min时候,表示内存基本耗光,只有内核才可以分配内存.
当可用内存大于watermark.min且小于watermark.low的时候,说明内存的压力比较大, kswapd会被唤醒执行内存回收,直到可用内存大于watermark.high.
当可用内存大于watermark.low 且小于watermark.high的时候,说明内存分配正常.
当可用内存大于watermark.high说明可用内存还很充足
二 直接内存回收引起的load 高
了解了内存分配的过程,我们可以看到,我们应该尽量避免直接内存回收,直接内存回收这种同步操作,会影响内存的分配速度,直接拉低业务的性能,如何避免直接内存回收,通过调高min_free_kbytes参数
cat /proc/sys/vm/min_free_kbytes 系统 在这里查看
修改 vi /etc/sysctl.conf
vm.min_free_kbytes=524288
sysctl -p 生效
一般128GB的内存情况下,min_free_kbytes 设置为4G,low和high的值是自动根据min的值调整的,所以其他的不用设置:
pages_low = pages_min*5/4
pages_high = pages_min*3/2
这个min_free_kbytes 调整多大合适那,可以通过:
[root@iZwz90jb8mqajkli0ttrcbZ ~]# sar -B
Linux 4.18.0-193.28.1.el8_2.x86_64 (iZwz90jb8mqajkli0ttrcbZ) 2021年07月09日 _x86_64_ (2 CPU)
00时00分07秒 pgpgin/s pgpgout/s fault/s majflt/s pgfree/s pgscank/s pgscand/s pgsteal/s %vmeff
00时10分07秒 4.16 4.12 22.22 0.02 28.57 0.00 0.00 0.00 0.00
00时20分07秒 0.00 2.75 33.58 0.00 34.82 0.00 0.00 0.00 0.00
查看直接内存扫描pgscand,如果这个为0,则min_free_kbytes 就合适了.min_free_kbytes 也不是越大越好, 如果这个值提高了,应用可以直接使用的内存就减少了,如果更关心系统的延迟,则可以增大,如果想更多的使用内存,可以调小这个值.
调整后查看:
egrep "min|low|high" /proc/zoneinfo
三 脏页过多引起的load高
在直接内存回收过程中,回收过程是同步阻塞的,如果遇到脏页需要进行数据的回写,如果回写遇到慢速的设备,就会降低内存分配的效率,造成系统中大量D状态(即不可中断)状态的进程,可以通过下面命令查看脏页个数(kbdirty).
# sar -r 1
Linux 4.18.0-193.28.1.el8_2.x86_64 (iZwz90jb8mqajkli0ttrcbZ) 2021年07月09日 _x86_64_ (2 CPU)
09时32分10秒 kbmemfree kbavail kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
09时32分11秒 409388 3328592 7312612 94.70 1044 3046320 4352256 56.36 2387304 2140536 8
09时32分12秒 409360 3328564 7312640 94.70 1044 3046320 4352256 56.36 2387308 2140536 8
可以通过以下参数的调整,降低脏页的数量和比例,从而提升回写的速度:
vm.dirty_background_bytes = 0
vm.dirty_background_ratio = 10
vm.dirty_bytes = 0
vm.dirty_expire_centisecs = 3000
vm.dirty_ratio = 20
同样降低脏页个数,就会导致IO次数多,每次的时间相对就小,这样的缺点就是IO的效率就变低了;脏页个数多那,IO次数就少了,IO整体效率就高,但是每次IO的总体时间就长了,影响了分配内存的速度
调整脏页比例结果查看
[root@eureka7001 ~]# grep "nr_dirty_" /proc/vmstat
nr_dirty_threshold 2362828
nr_dirty_background_threshold 1181414
四 NUMA配置策略不当引起load高.
NUMA架构下内存是分开的,如果从CPU所在的Node上分配内存,速度较快,如果跨了Node节点分配内存,速度会变慢,NUMA 架构如下图: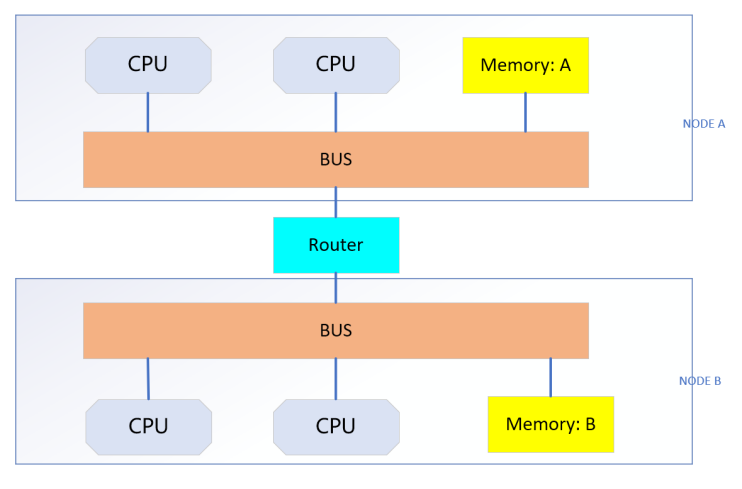
针对这种Numa架构,linux通过zone_reclaim_mode 参数可以用来管理当一个内存区域(zone)内部的内存耗尽时,是从其内部进行内存回收还是可以从其他zone进行回收的选项. zone_reclaim_mode 一般是设置为0或1,两种情况适用的场景不同,如果为0,则系统倾向于从其他Node节点分配内存,内存使用的性能会稍微差一些,但是可以保证系统有空余内存时候可以使用; 设置为1,系统倾向于从本地的Node上回收cache,本地回收不够使用的话,会使用swap,从而造成系统性能下降;好处是访问本地Node内存,性能更好些,一些对于性能要求极高的场景,比如抓包等可以设置.最好还是使用默认值0更合适.
a、当某个节点可用内存不足时:
1、如果为0的话,那么系统会倾向于从其他节点分配内存
2、如果为1的话,那么系统会倾向于从本地节点回收Cache内存多数时候
也可以通过在应用程序前面加上:
numactl --interleave=all mysqld ...
来启动程序,也可以突破node节点的内存分配的限制.
查看Numa架构相关命令:
[root@eureka7001 ~]# numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 40 42 44 46 48 50 52 54
node 0 size: 63786 MB
node 0 free: 361 MB
node 1 cpus: 1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45 47 49 51 53 55
node 1 size: 64490 MB
node 1 free: 146 MB
node distances:
node 0 1
0: 10 21
1: 21 10
五 诗词欣赏
《登高》 ---杜甫
风急天高猿啸哀,渚清沙白鸟飞回。
无边落木萧萧下,不尽长江滚滚来。
万里悲秋常作客,百年多病独登台。
艰难苦恨繁霜鬓,潦倒新停浊酒杯。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









