







谷歌娘上不去是一个永远挥之不去的痛,有很多可以FQ的方法,其中之一就是修改/etc/hosts文件,通过域名重定向的方法,访问Google(以及其他的网站你懂的……),感谢乱炖给我们提供了一个保持更新的可靠的hosts源:http://levi.cg.am/test/hosts/rander/?d=11.18.2,笔者常用的是第一个360kb的hosts源,除了google基本上不太有其他的需求。为什么hosts不能只修改一次呢,这种非技术问题就不在这里讨论了。
恰巧笔者又是一个非常懒的人,就连打开Chromium–>点击书签页–>点击中间硕大的“选择并复制所有hosts”–>F1–>sudo gedit /etc/hosts–>Ctrl+V,这么短短几步,都不愿意操作,于是就萌生了利用网络爬虫工具,提取360kb的hosts源,并自动替换系统hosts的想法。往事具备,只差coding了!
准备工具:scrapy,参考http://www.linuxidc.com/Linux/2015-03/115306.htm这篇文章,装好网络爬虫工具Scrapy:
a)
pippackage :sudo apt-get install python-pip
b)python dev:sudo apt-get install python-dev
c)SCRAPY:sudo pip install scrapy
d)Twisted支持:sudo apt-get install python-twisted
关于scrapy的介绍就不在这赘言了,仔细分析了一下乱炖网站的特性,发现hosts的文本内容存在于textarea标签中,且360kb的源是第一个textarea,那么就在spiders中创建了hostsSpider.py文件:
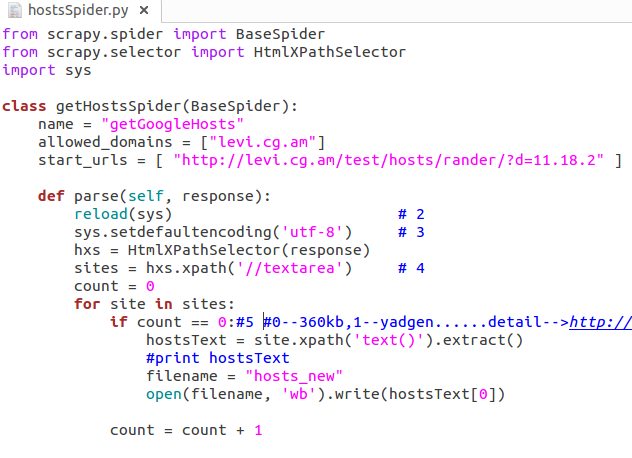
其中#4处的含义是提取response中所有标签为textarea的sites,之后进行一个循环,第一个textarea即为我需要的360kb源。
到这一步其实就已经可以出结果了,在terminal中工程目录下运行:scrapy crawl getGoogleHosts(对应name中设置的),就可以将网站中的hosts到出到hosts_new文件中,由于其中包含有中文,所以需要修改默认编码方式为UTF-8,如上,利用scrapy进行爬虫的步骤就算是结束了。
光有自动爬虫,导出到本地文件还不够,笔者不想每次都移到工程目录下,输入scrapy的指令,那么此时,linux下的shell命令编程就要发光发热了:
新建文件updateHosts.sh,和getHosts放在同一级目录下。
光是把网上的hosts源替换掉系统的/etc/hosts是不行的,对于127.0.0.1的解析也是要加进去的,一个是localhost,一个是hostname,脚本文件如下:
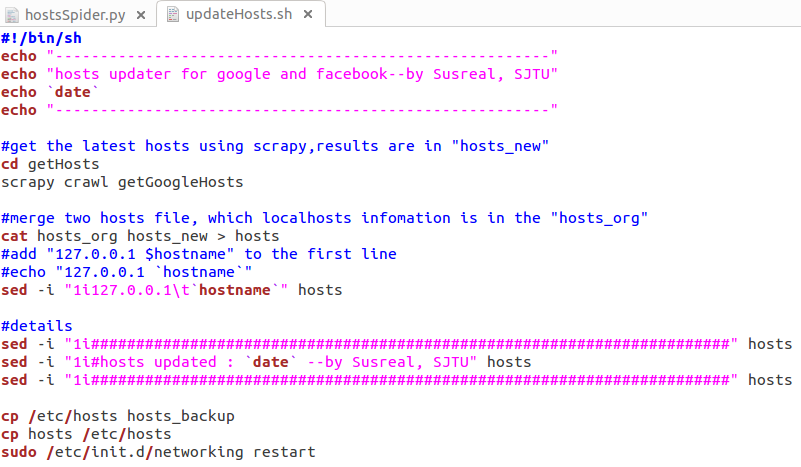
查看脚本文件很容易看出,先是通过scrapy将网站上的hosts提取出来,放在hosts_new文件中,利用cat指令将含有127.0.0.1信息的hosts_org进行合并。将完整的hosts文件,通过cp指令替换掉系统中的hosts,并重启网络,完成更新!
这样的话,每次只要在terminal中输入如下指令即可完成对hosts的更新!
sudo bash updateHosts.sh
源码:https://github.com/Susreal/getHosts/。
由于笔者也是近期才开始接触ubuntu,很多东西都是现学现卖,但是也希望能通过博客记录的方式,记录下自己的学习进程,大家不嫌弃的话,也可以对我进行纠正指导,我万分感谢。
Susreal














 3746
3746











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









