







premature optimization is the root of all evil
python 性能分析主要是时间和空间(内存)的分析
这里主要对运行时间进行分析
1. 在代码中加入各种log,print:
import time
start_time = time.time()
myfunction() # 待测试的函数
end_time = time.time()
print 'time cost:' + str(end_time - start_time)这种方式比较灵活可控,可以自己控制粒度,可以测试单个语句,也可以测试多个函数。
2.或者用装饰器:
def fn_timer(function):
"""这个代码来源于 http://www.marinamele.com/7-tips-to-time-python-scripts-and-control-memory-and-cpu-usage"""
@wraps(function)
def function_timer(*args, **kwargs):
t0 = time.time()
result = function(*args, **kwargs)
t1 = time.time()
print ("Total time running %s: %s seconds" %
(function.func_name, str(t1 - t0))
)
return result
return function_timer
@fn_timer
def myfunction(...):
pass这种方式需要在函数定义的时候就加上,但是可以保持函数的”整洁”。
但是上面的这两种方式有一定的局限性:
1. 侵入了原有的功能代码。当然有其他方式可以处理,比如在生产中禁用记录时间的log,但记录程序的运行时间并不总是需要的。
2. 不够灵活。假如项目比较大,核心的函数比较多,我不可能在每个函数上都做上面的操作,这样是个巨大的工程,同时代码也会变的丑陋。
3. 使用python的timeit模块
python提供了timeit模块,这个可以在python console中直接使用
$ python -m timeit -n 4 -r 5 -s "import timing_functions" "timing_functions.random_sort(2000000)"输出为:
4 loops, best of 5: 2.08 sec per loop不过个人不是太喜欢这种方式,自己要敲的东西太多了,而且输出信息简陋。这个模块在ipython中使用起来相对简洁很多,直接在前面加%timeit即可。
4. 使用Unix命令
在shell中输入下面的命令
$ time -p python timing_functions.py得到输出:
Total time running random_sort: 1.3931210041 seconds
real 1.49
user 1.40
sys 0.08- real 表示的是执行脚本的总时间,等于 user + sys
- user 表示的是执行脚本消耗的CPU时间
- sys 表示的是执行内核函数(操作系统)消耗的时间
5. 使用cProfile模块
上面的方法其实还是比较简单粗暴。profile模块是个更好的cProfile是profile的C实现,速度会更快。类似的包有pickle,也有个对应的Cpickle版本。
这个包可嵌入的代码中,类似下面这种:
import cProfile
cProfile.run("myfunction()")我个人最喜欢的还是下面这种(下面的代码可能需要加一下PYTHONPATH):
$python -m cProfile -o output.pkl my_main_file.py首先无需更改现有代码结构,其次可以将结果保存到output.pkl中。强烈建议将profile的结果保存起来,因为生产中有些profile可能耗时很长,而且控制台输出的内容有限,当你想从结果里面提取点重要信息,又要重新来过,特别耗时。
当获取上面的output.pkl的时候,可以进入python console,使用pstats得到结果:
import pstats
p = pstats.Stats('output.pkl') # 文件名
p.sort_stats('time') # 按照时间排序
p.print_stats(10) # 最耗时的前10个,如果没有参数,默认输出全部输出的效果如下:
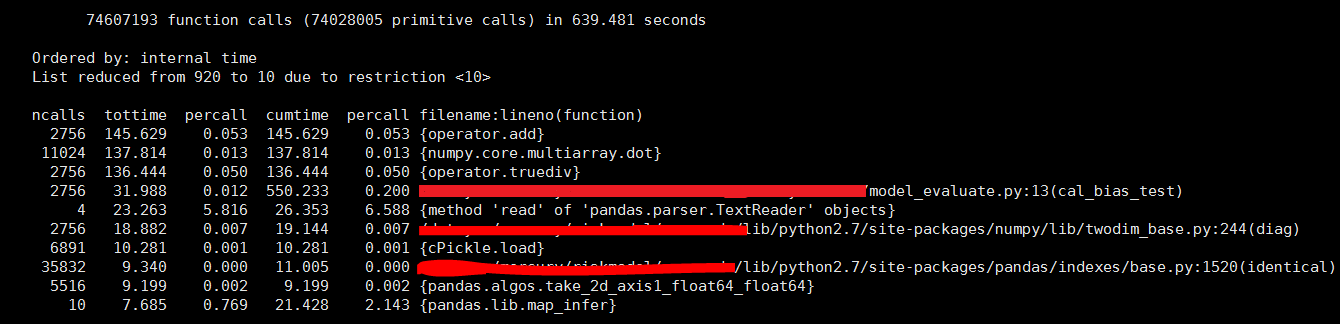
ncalls: 函数被call的次数
tottime:函数总的耗时,但是不包括其子函数的耗时
percall:tottime平均到每次调用的耗时
cumtime:函数总的耗时,包括了其子函数的耗时(递归函数也不例外)
percall:cumtime平均到每次调用的耗时
filename:lineno(function) :每个函数各自的信息
6. 其他的工具
- line_profiler 可以统计每行代码的花费的CPU时间
- memory_profiler 内存分析工具
- objgraph 可以快速发现内存泄漏的工具
另外还有图形化的方式:
1. gprof2dot.py
2. vprof
7. 记录一次自己python性能分析历程
- 有个项目第一次上线,在上生产的过程中,我发现程序在生产环境的速度比在QA环境的要慢很多。首先猜测:我的生产环境是台物理机,QA是台虚机,应该不是CPU的问题。
- 我检查了两个环境依赖python包的版本是否一致,其中有个numpy的小版本不一样,虽然可能性不大,但是还是调整到小版本号也一致,发现生产的速度还是慢,所以版本不一致不是原因。
- 这个时候不能做无头苍蝇了,赶紧cprofile跑一下,得到上面的截图。可以看到,大部分的时间都在底层运算上面。因为大量依赖numpy和pandas两个包做运算,所以我猜测问题还是在这两个包上。
- 突然想到,包安装的方式有可能造成这个情况(以前有同事遇到过这个问题)。因为conda默认安装的是已经编译好的包,而pip默认从源编译安装。使用pip这个编译的过程,能更好的跟系统兼容,提升性能。于是生产上改用pip安装了numpy,但是然并卵~~
- 上面的可能也排除后,有点捉急。我在想既然大概率是numpy的问题,那我先不用numpy做复杂的事情,直接做简单的除法。于是写了下面的脚本,分别在QA和生产跑一下,时间还是差距很大!!! 这个时候我有点动摇我在刚开始的认知了,我觉得有可能是CPU性能的差距!
import numpy as np
import time
t = time.time()
for _ in range(1000):
a = np.random.random((100, 1000))
b = np.random.random((100, 1000))
c = a / b
print time.time() - t为了验证是否是CPU的问题,我进一步写了一个小脚本,剔除numpy的影响:
import time
import random
t = time.time()
for _ in xrange(10000000):
a = random.random()
b = random.random()
c = a / b
print time.time() - t上面这个脚本使用纯python,没有第三方的包。对比两个环境后,我进一步确认了问题所在,是CPU的问题。
Last: 对比了两个环境的CPU型号,终于确认。虽然我的QA是虚机,但是虚机底层的物理机是最近刚采购的新机器,性能特别好,而且现在虚机资源比较充裕,没人跟我争夺资源,这个虚机基本上可以发挥物理机单核CPU的性能。反观生产环境虽然是物理机,型号却是3年前的旧机器,高下立判。我的代码是高密集的运算,在大量的循环计算后,单次计算性能的差距被放大了,导致某些函数慢了将近一倍!















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









