







在大数据和数据库的很多地方都会用到hash方法,hash方法由hash表,hash函数,冲突处理几大“硬件”组成。
这是july的博客,但是内容很多很杂,所以想结合书本中的内容做些简单的总结,供自己和大家随时复习一下!
一般我们查找都是通过二分查找,二叉排序树查找等等,这些查找都是要通过比较的,而且有些算法还是要比较很多次的,非常好的情况就是通过某种映射,直接找到要查找东西的地址。这听起来很诱人啊,无需多次比较,直接找到,省了多少事啊!这就是hash方法产生的动机。但是天下没有免费的午餐,hash也是要付出一定代价,但是这不妨碍它的广阔用途,比如说数据库中就用了很多hash。
1.什么是hash表?
hash表的实质就是一个数组,为什么要使用数组呢?因为数组有其他数据结构一个没有的优势,它可以立即寻址。只有立即寻址,才能体现hash的速度。这个数组里存的是什么呢?可以是要查找的内容(当然这种情况一般很少出现),还有一种就是该键值对应的数据的地址,简单的可以理解为数组中存的就是一个指针。
2.hash函数的构造方法
hash函数的意义就是通过key找到hash地址,再通过hash地址找到我们要的数据。
2.1直接定址法
取关键字或关键字的某个线性函数值为hash地址。即
H(key)= key 或 H(key) = a*key + b;
其中a和b为常数。
2.2数字分析法
书中举的例子就是,假如我们的Key是个长数字,分析哪些是重复的,选取不重复的位置作为hash地址。
2.3 平方取中法
就是取关键字平方后的中间几位为hash地址。
2.4 折叠法
将关键字分割成位数相同的几部分(最后一部分的位数可以不同),然后取这几部分的叠加和作为hash地址。这种方法适合于key的位数很多,而且key中每一位上数字分布大致相同。书中的例子是图书编号。
2.5 除留余数法
取关键字被某个不大于hash表表长m的数p除后所得余数为hash地址。即
H(key) = key MOD p , p<= m
这是一种最简单,也最常用的构造hash函数的方法。这里的p的取法很有讲究,一般选p为质数或不包含小于20的质因子的合数。《算法导论》中提到p不能为2的n次方,这样会带来很多问题。但是有些人好像对这个提出了反对意见。知道的欢迎留言啊。
3处理冲突的方法
3.1开放地址法:
这是书里面的东西,懒得敲了。

3.2再hash法
就是要是遇到了冲突,用另外一个hash重新选择地址。
3.3链地址法
将所有关键字为同义词的记录存储在同一线性表中。
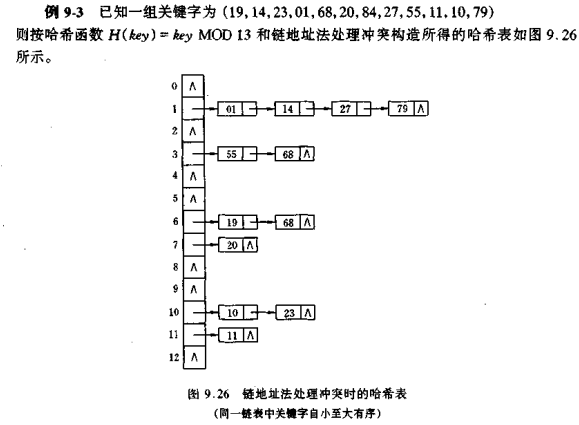
3.4建立一个公共溢出区
将所有冲突的都填入公共的溢出区。这种貌似没见用过。
4 hash的性能取决于:设计良好的hash函数,处理冲突的方法,装填因子。
装填因子 = 表中填入的记录数/hash表长度















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









