







深度学习相关概念:过拟合与欠拟合
更多Ai资讯:公主号AiCharm

在神经网络中,我们常常听到过拟合与欠拟合这2个名词,他们到底是什么意思呢?
1.过拟合与欠拟合
过拟合:
是指学习时选择的模型所包含的参数过多,以至于出现这一模型对已知数据预测的很好,但对未知数据预测得很差的现象。这种情况下模型可能只是记住了训练集数据,而不是学习到了数据特征。
欠拟合:
模型描述能力太弱,以至于不能很好地学习到数据中的规律。产生欠拟合的原因通常是模型过于简单。
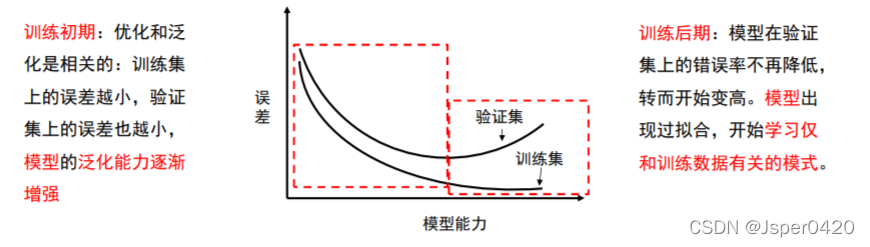
我们要知道机器学习的根本问题是解决优化和泛化的问题。
优化:
是指调节模型以在训练数据上得到最佳性能。
泛化:
是指训练好的模型在前所未见的数据(测试集)上的性能好坏。
2.应对过拟合
2.1最优方案
获取更多的训练数据。只要给足够多的数据,让模型学习尽可能多的情况,它就会不断修正自己,从而得到更好的结果。就类似于当初参加高考的你,训练数据就类比是你在刷题,当你刷了非常非常多的题,并学会他们的特征,那么你应对高考则是游刃有余了。
如何获取更多数据,可以有以下几个方法:
1. 从数据源头获取更多数据。
2. 根据当前数据集估计数据分布参数,使用该分布产生更多数据:这个一般不用,因为估计分布参数的过程也会代入抽样误差。
3. 数据增强(Data Augmentation):通过一定规则扩充数据。如在物体分类问题里,物体在图像中的位置、姿态、尺度,整体图片明暗度等都不会影响分类结果。我们就可以通过图像平移、翻转、缩放、切割等手段将数据库成倍扩充。
但是获取到有效的数据往往是非常困难的,代价很大(所以在多数情况下不使用此方案)。那么有没有代价适中,又可以解决过拟合的方案呢?
2.1次优方案
调节模型允许存储的信息量或者对模型允许存储的信息加以约束,该类方法也称为正则化。即:
1. 调节模型大小
2. 约束模型权重,即权重正则化(在机器学习中一般使用 L2正则化)
3. 随机失活(Dropout)
2.1.1L2正则化
总损失:
L
(
W
)
=
1
N
∑
i
L
i
(
f
(
x
i
,
W
)
,
y
i
)
⏟
+
λ
R
(
W
)
⏟
L(W)=\underbrace{\frac{1}{N} \sum_{i} L_{i}\left(f\left(x_{i}, W\right), y_{i}\right)}+\underbrace{\lambda R(W)}
L(W)=
N1i∑Li(f(xi,W),yi)+
λR(W)
数据损失 权重正则损失
L2正则损失 :
R
(
W
)
=
∑
k
∑
l
W
k
,
l
2
R(W)=\sum_{k} \sum_{l} W_{k, l}^{2}
R(W)=k∑l∑Wk,l2
L2正则损失对于大数值的权值向量进行严厉惩罚,鼓励更加分散的权重向量,使模型倾向于使用所有输入特征做决策,此时的模型泛化性能好!
2.1.2Dropout 随机失活
随机失活:让隐层的神经元以一定的概率不被激活。
实现方式:训练过程中,对某一层使用Dropout,就是随机将该层的一些输出舍弃(输出值设置为0),这些被舍弃的神经元就好像被网络删除了一样。
随机失活比率( Dropout ratio):是被设为 0 的特征所占的比例,通常在 0.2~0.5范
围内。
例:
假设某一层对给定输入样本的返回值应该是向量:[0.2, 0.5, 1.3, 0.8, 1.1]。
使用Dropout后,这个向量会有几个随机的元素变成:[0, 0.5, 1.3, 0, 1.1]
Dropout是通过遍历神经网络每一层的节点,然后通过对该层的神经网络设置一个 Dropout ratio(随机失活比率),即该层的节点有Dropout ratio的概率失活。以这种方式“dropped out”的神经元既不参与前向传播,也不参与反向传播。
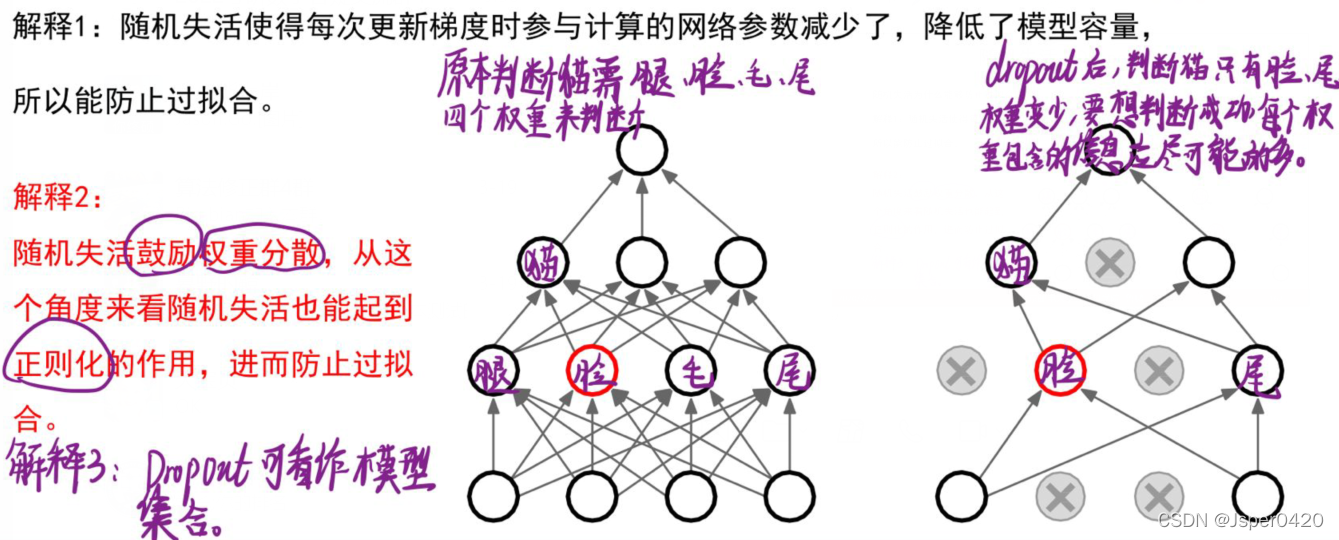
随机失活为什么能够防止过拟合呢?
解释1:
随机失活使得每次更新梯度时参与计算的网络参数减少了,降低了模型容量,所以能防止过拟合。
解释2:
随机失活鼓励权重分散,从这个角度来看随机失活也能起到正则化的作用,进而防止过拟合。
总的来说通过Dropout每次输入一个样本,就相当于该神经网络就尝试了一个新的结构,但是所有这些结构之间共享权重。因为神经元不能依赖于其他特定神经元而存在,所以这种技术降低了神经元复杂的互适应关系。正因如此,网络需要被迫学习更为鲁棒的特征(泛化性更强)。
训练时使用随机失活,测试时怎么办?
测试时不使用随机失活,而是计算所有权重,如下图所示

p=0.5 #p是神经元保持激话概率
def train(X):
H1 = np.maximum(0,np.dot(W1,X) + b1)
U1 = np.random.rand(*H1.shape) < p #第一层的mask
H1 *= U1 #第一层dropout操作
H2 = np.maximun(0,np.dot(W2,H1) + b2)
U2 = np.random.rand(*H2.shape) < p #第二层的mask
H2 *= U2#第二层dropout操作
out = np.dot(W3,H2) + b3
def predict(X):
H1 = np.maximum(0,np.dot(W1,X) + b1) * p
H2 = np.maximun(0,np.dot(W2,H1) + b2) * p
out = np.dot(W3,H2) + b3
3.应对欠拟合
3.1解决方案:
欠拟合的情况比较容易克服,解决方法有:
1. 增加新特征,可以考虑加入进特征组合、高次特征,来增大假设空间。
2. 添加多项式特征,这个在机器学习算法里面用的很普遍,例如将线性模型通过添加二次项或者三次项使模型泛化能力更强。
3. 减少正则化参数,正则化的目的是用来防止过拟合的,但是模型出现了欠拟合,则需要减少正则化参数。
4. 使用非线性模型,比如核SVM 、决策树、深度学习等模型 。
5. 调整模型的容量(capacity),通俗地,模型的容量是指其拟合各种函数的能力。
6. 容量低的模型可能很难拟合训练集;使用集成学习方法,如Bagging ,将多个弱学习器Bagging。
更多Ai资讯:公主号AiCharm
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











