






1.Specify and Edit: Overcoming Ambiguity in Text-Based Image Editing

标题:指定和编辑:克服基于文本的图像编辑中的歧义
作者: Ekaterina Iakovleva, Fabio Pizzati, Philip Torr, Stéphane Lathuilière
文章链接:https://arxiv.org/abs/2407.20232
项目代码:https://github.com/fabvio/SANE

摘要:
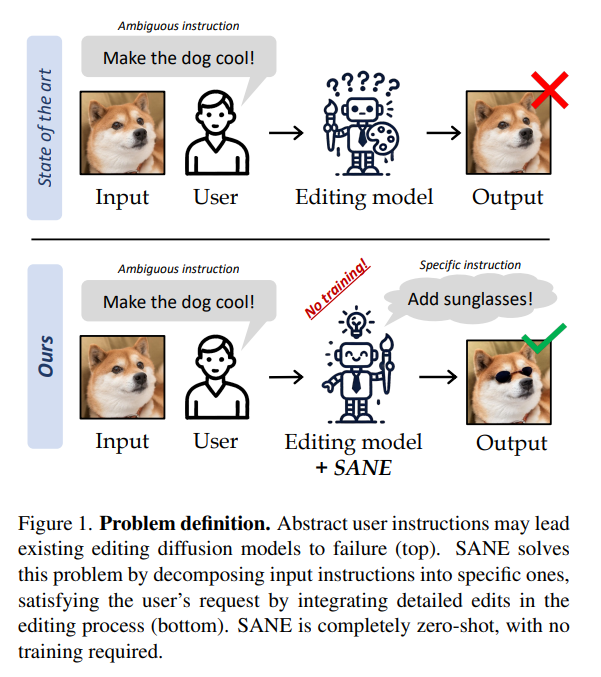
当用户的输入指令不明确时,基于文本的编辑扩散模型表现出有限的性能。为了解决这个问题,我们建议 Specify ANd Edit (SANE),用于基于扩散的编辑系统的零样本推理管道。我们使用大型语言模型(LLM )将输入指令分解为特定指令,即应用到输入图像的明确定义的干预措施以满足用户的请求。我们受益于LLM-得益于专门为该任务设计的新颖的去噪指导策略,沿着原始指令导出指令。我们使用三个基线和两个数据集进行的实验证明了 SANE 在所有设置中的优势。此外,我们的管道提高了编辑模型的可解释性,并提高了输出的多样性。我们还证明我们的方法可以应用于任何编辑,无论是否模糊。
这篇论文试图解决什么问题?
这篇论文试图解决的问题是文本基础图像编辑中用户输入指令的歧义性问题。具体来说,当用户给出的编辑指令不明确时,现有的基于文本的图像编辑扩散模型(text-based editing diffusion models)往往无法成功地编辑图像。为了解决这个问题,论文提出了一种名为Specify ANd Edit (SANE) 的零样本推理流程,用于提高在面对歧义性输入指令时的图像编辑性能。
以下是论文中提到的一些关键点:
-
歧义性问题:用户输入的文本指令可能含糊不清,导致编辑模型难以理解确切的编辑意图。
-
SANE方法:通过使用大型语言模型(LLM)将输入的歧义指令分解为具体的编辑指令,这些指令可以明确地应用于输入图像以满足用户的请求。
-
零样本学习:SANE方法不需要训练,可以应用于任何预训练的基于指令的扩散模型。
-
性能提升:通过实验,SANE在多个基线和数据集上展示了其在所有设置中的优势,提高了编辑模型的可解释性,并增加了输出的多样性。
论文的核心贡献包括:
-
提出了一种专门针对歧义指令的编辑方法。
-
引入了基于LLM的指令分解流程和结合歧义和具体指令的编辑扩散模型的条件机制。
-
在两个数据集上进行了广泛的实验,并与三种最先进的方法进行了比较,证明了SANE的有效性。
论文如何解决这个问题?
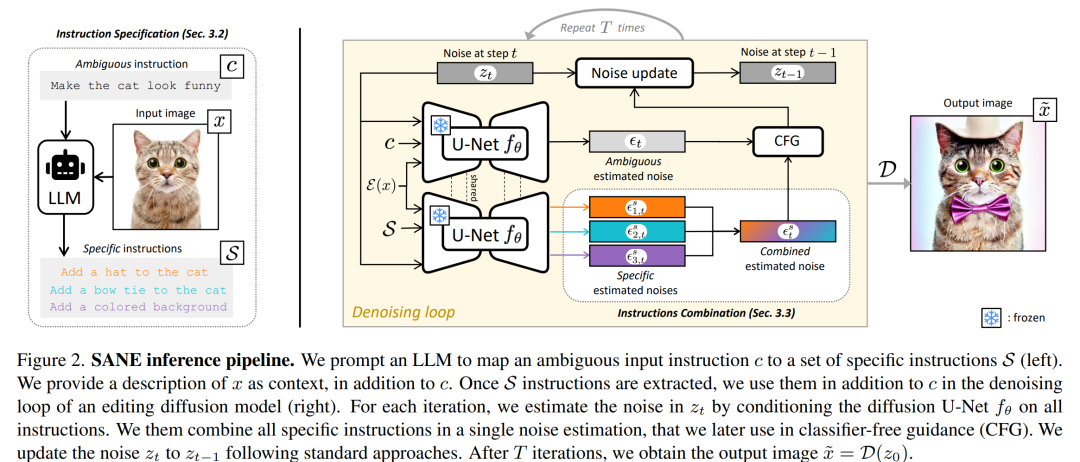
论文通过提出Specify ANd Edit (SANE) 方法来解决文本基础图像编辑中的歧义性问题。以下是SANE方法的关键步骤和解决方案:
-
指令分解(Instruction Specification):
-
使用大型语言模型(LLM)将用户的歧义性编辑指令分解为一系列具体的编辑指令。这些具体的指令更明确地描述了如何修改输入图像以满足用户的需求。
-
通过提供输入图像的描述作为上下文,LLM能够生成与原始指令一致的详细编辑步骤。
-
-
指令组合(Instructions Combination):
-
将分解得到的特定指令与原始歧义指令结合,用于指导图像编辑过程。这样做可以确保编辑过程既考虑了用户的整体意图,也关注了具体的修改细节。
-
在每次去噪步骤中,对每个特定指令进行条件去噪,以估计每个指令对图像的影响。
-
-
去噪引导策略(Denoising Guidance Strategy):
-
为了整合特定指令和原始歧义指令,论文提出了一种新的去噪引导策略。这种策略通过计算每个特定指令对去噪过程的影响,并将其与原始指令的影响结合起来,生成一个综合的噪声估计。
-
使用分类器自由引导(Classifier-free Guidance, CFG)来平衡特定指令和原始指令的影响,确保生成的图像既忠实于用户的整体意图,也体现了具体的编辑细节。
-
-
零样本学习(Zero-shot Learning):
-
SANE方法不需要额外的训练,可以直接应用于任何预训练的基于指令的扩散模型。这使得SANE具有很高的灵活性和通用性。
-
-
性能提升和可解释性:
-
通过实验,SANE在多个基线和数据集上展示了其在所有设置中的优势,提高了编辑模型的可解释性,并增加了输出的多样性。
-
-
代码开源:
-
为了促进研究和应用,论文提供了SANE方法的开源代码,方便其他研究者和开发者使用和进一步改进。
-
通过这些步骤,SANE方法能够有效地解决文本基础图像编辑中的歧义性问题,提高编辑的准确性和用户满意度。
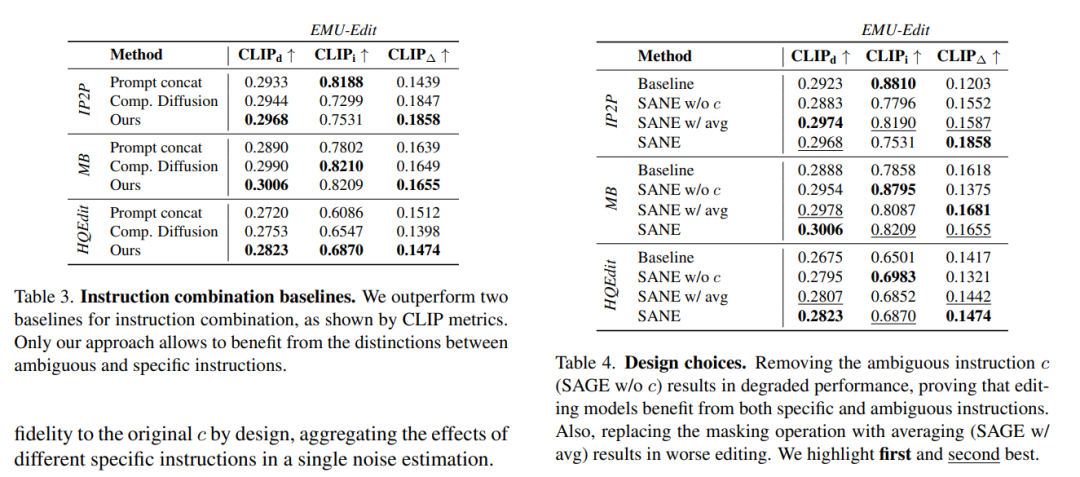
论文做了哪些实验?
论文中进行了多项实验来评估和展示SANE方法的性能和效果。以下是实验的主要内容:
-
基线比较:
-
将SANE应用于三种不同的编辑扩散模型(InstructPix2Pix, MB, HQEdit)上,并与各自的基线版本进行比较。
-
-
数据集:
-
在两个数据集上进行测试:EMU-Edit数据集和IP2P数据集。这些数据集包含了真实的图像以及与之相关的歧义性编辑指令。
-
-
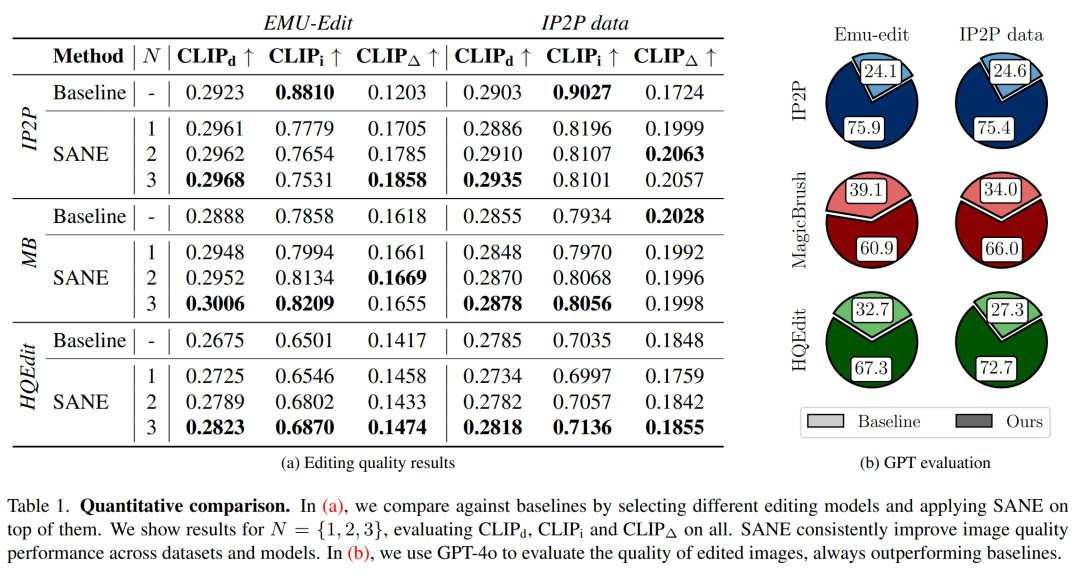
性能指标:
-
使用基于CLIP的度量(如CLIPd、CLIPi、CLIP∆)来评估编辑图像的质量,包括对原始图像的保留程度、编辑强度和对编辑指令的遵循程度。
-
-
GPT评估:
-
使用GPT-4o模型对编辑后的图像质量进行评估,通过比较用户对SANE和基线方法编辑结果的偏好。
-
-
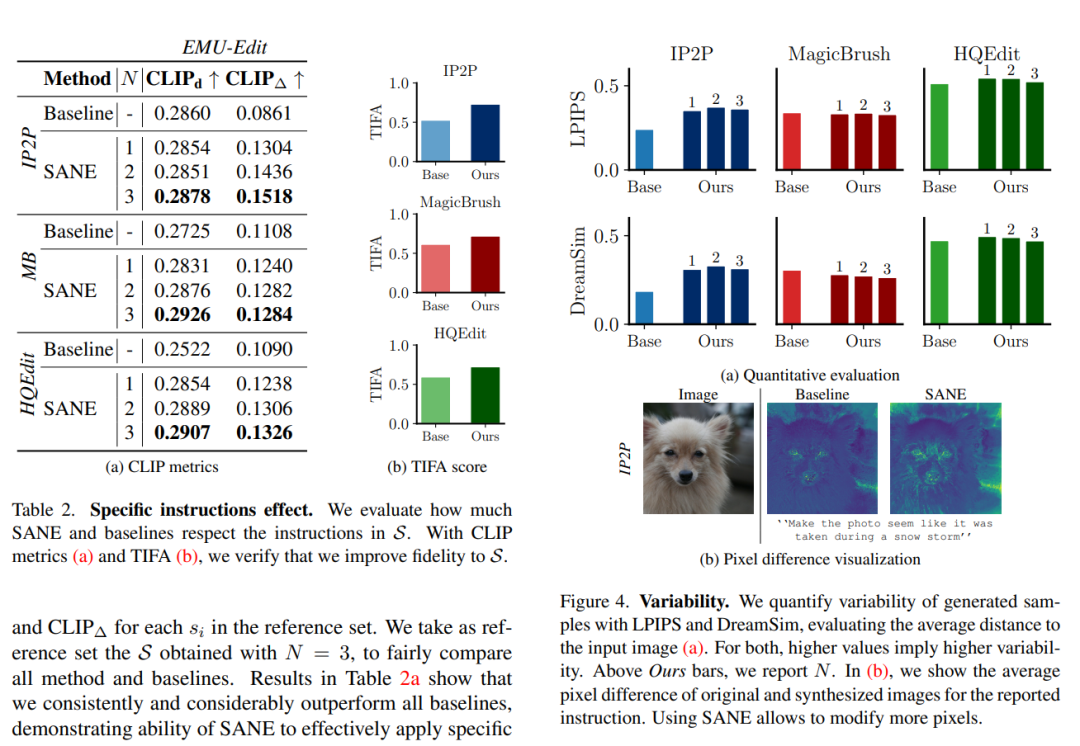
特定指令的影响:
-
分析SANE方法对特定指令集的遵循程度,确保每个特定指令在编辑过程中都被考虑到。
-
-
图像多样性:
-
通过LPIPS和DreamSim度量评估编辑图像的多样性,确保SANE生成的图像在视觉和语义上都具有多样性。
-
-
设计选择的影响:
-
进行消融研究,分析不同的设计选择(如是否使用歧义指令、不同的指令组合策略)对SANE性能的影响。
-
-
非歧义指令的评估:
-
对非歧义性指令进行评估,以证明SANE不仅适用于歧义性指令,也可以提高对明确指令的编辑性能。
-
-
计算成本:
-
分析SANE方法的计算成本,包括处理时间和对计算资源的需求。
-
-
附加的可视化和案例研究:
-
提供额外的可视化结果和案例研究,展示SANE在不同场景下的应用效果。
-
这些实验结果表明,SANE方法能够在不同情况下提高图像编辑的性能,增强模型对用户指令的解释能力,并增加输出结果的多样性。同时,实验也验证了SANE的通用性和灵活性,证明了它可以作为一个有效的工具来解决文本基础图像编辑中的歧义性问题。
论文的主要内容:
这篇论文的主要内容可以概括为以下几个要点:
-
问题识别:论文指出现有的基于文本的图像编辑扩散模型在处理用户输入的歧义性指令时性能有限。
-
方法提出:为了解决这个问题,论文提出了Specify ANd Edit (SANE),一个零样本推理流程,利用大型语言模型(LLM)将歧义性输入指令分解为更具体的子指令。
-
技术策略:
-
指令分解:通过LLM将抽象的编辑指令转换为一系列具体的编辑操作。
-
去噪引导策略:结合原始歧义指令和分解得到的特定指令,通过特定的去噪引导策略来指导图像编辑过程。
-
-
实验验证:论文通过在两个数据集上的实验,展示了SANE方法在不同设置下相对于现有基线方法的性能提升。
-
性能提升:SANE在图像编辑的质量、多样性和可解释性方面均显示出改进。
-
零样本学习:SANE方法不需要额外的训练,能够直接应用于预训练的基于指令的扩散模型。
-
开源代码:论文提供了SANE方法的开源代码,以促进研究和应用。
-
贡献总结:
-
提出了首个专门针对歧义指令的编辑方法。
-
引入了基于LLM的指令分解流程和为特定任务设计的编辑扩散模型的条件机制。
-
-
未来工作:论文讨论了SANE的局限性,并提出了未来可能的研究方向。
-
相关工作:论文还回顾了与文本到图像生成、图像编辑、LLMs以及多指令编辑等相关的研究工作。
总的来说,这篇论文通过提出SANE方法,有效地解决了文本基础图像编辑中的歧义性问题,并在实验中证明了其有效性,同时为未来的研究提供了新的方向和思路。
2.Improving 2D Feature Representations by 3D-Aware Fine-Tuning
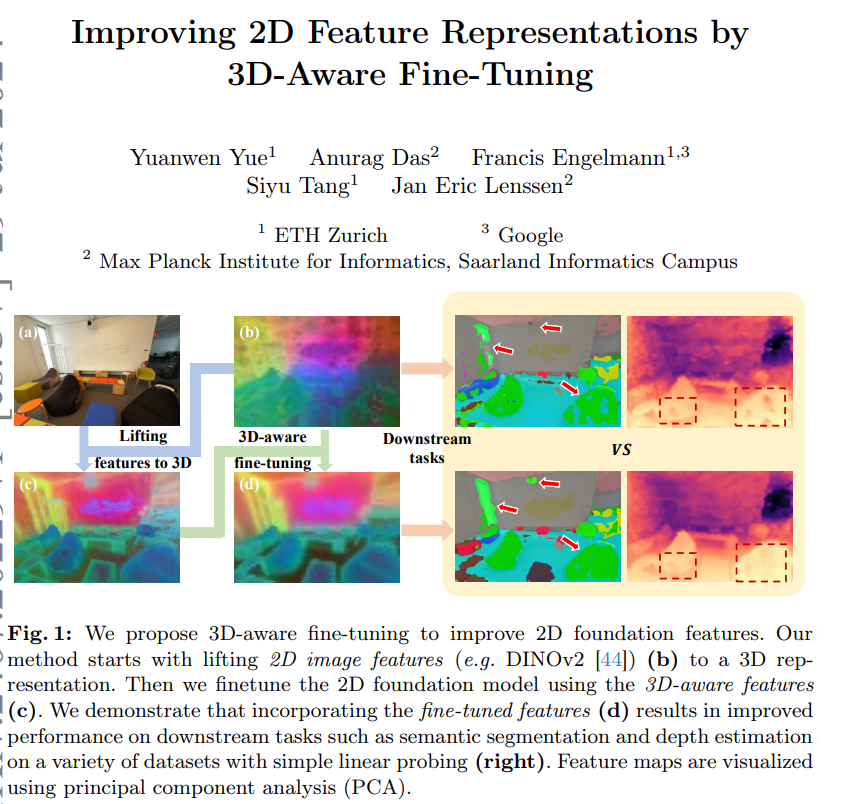
标题: 通过 3D 感知微调改进 2D 特征表示
作者:Yuanwen Yue, Anurag Das, Francis Engelmann, Siyu Tang, Jan Eric Lenssen
文章链接:https://arxiv.org/abs/2407.20229
项目代码:https://ywyue.github.io/FiT3D/




摘要:
当前的视觉基础模型纯粹基于非结构化 2D 数据进行训练,限制了它们对对象和场景的 3D 结构的理解。在这项工作中,我们表明对 3D 感知数据进行微调可以提高新兴语义特征的质量。我们设计了一种方法,将语义 2D 特征提升为高效的 3D 高斯表示,这使我们能够为任意视图重新渲染它们。使用渲染的 3D 感知功能,我们设计了一种微调策略,将这种 3D 感知转移到 2D 基础模型中。我们证明,以这种方式微调的模型产生的特征可以通过简单的线性探测轻松提高语义分割和深度估计中的下游任务性能。值得注意的是,尽管在单个室内数据集上进行了微调,但这种改进可以转移到各种室内数据集和域外数据集。我们希望我们的研究能够鼓励社区在训练 2D 基础模型时考虑注入 3D 意识。
这篇论文试图解决什么问题?
这篇论文试图解决的问题是如何改善当前视觉基础模型(visual foundation models)对3D结构理解不足的问题。这些模型通常仅在未结构化的2D数据上进行训练,因此它们在理解物体和场景的3D结构方面存在限制。具体来说,论文中提到的关键问题包括:
-
2D数据的局限性:当前的视觉模型主要在2D图像数据上训练,这些数据作为我们3D世界的简单投影,虽然容易获得,但丢失了明确的3D几何信息。
-
缺乏3D结构理解:由于训练设置没有充分利用多视角或视频对应关系,这些模型不能充分理解观察到的物体的3D结构,导致从不同视角观察到的特征不一致。
-
提升下游任务性能:作者提出,如果能够将3D意识(3D awareness)注入到2D基础模型中,可能会提高模型在下游任务(如语义分割和深度估计)中的表现。
为了解决这些问题,论文提出了一种新颖的两阶段方法,首先将2D特征提升到3D表示,然后使用这些3D感知特征来微调2D基础模型,以提高其对3D结构的理解能力,并在多个数据集上验证了该方法的有效性。
论文如何解决这个问题?
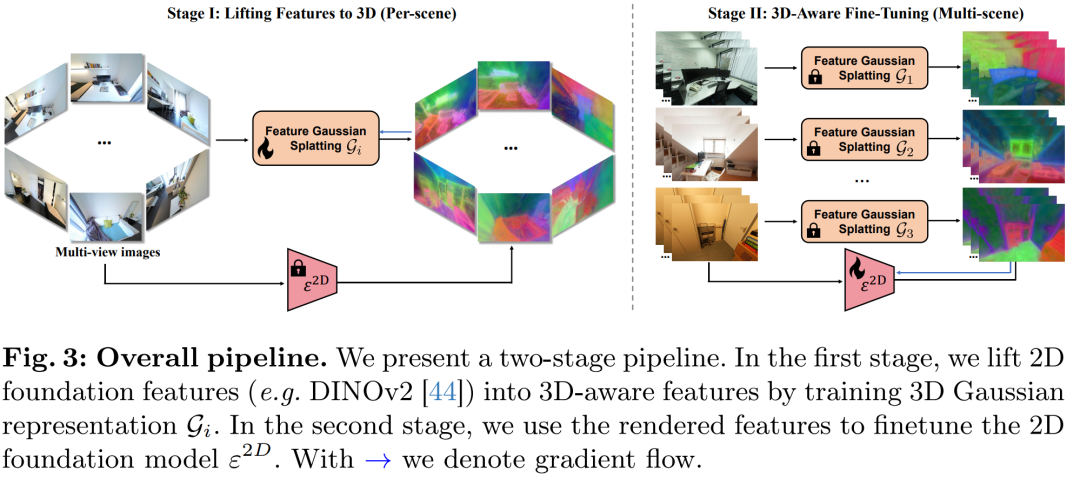
论文通过提出一个两阶段的方法来解决2D特征表示对3D结构理解不足的问题。具体步骤如下:
-
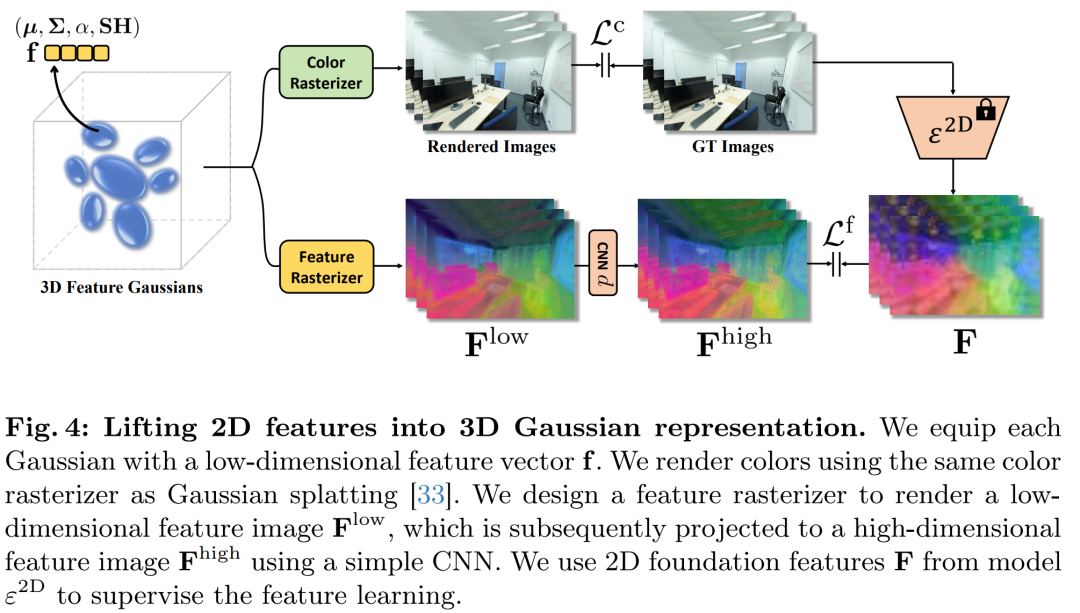
将2D特征提升到3D表示(Lifting Features to 3D):
-
利用多视图2D基础特征,通过3D高斯散射(Gaussian Splatting)技术,将它们提升为3D表示。这一步骤利用了多视图一致性,允许不同视图的2D特征相互补充。
-
通过训练3D高斯模型,可以将特征融合并渲染出具有高分辨率和细节的3D感知特征。
-
-
3D感知微调(3D-Aware Fine-Tuning):
-
使用第一阶段生成的3D感知特征作为训练数据,微调2D基础模型。这一步骤设计了一个高效的微调策略,将3D感知能力转移到2D模型中。
-
微调过程不需要对2D特征提取器进行大量的修改或增加额外的网络组件,只需简单的线性探测即可。
-
-
线性探测(Linear Probing):
-
在微调后,通过在标准基准测试上的线性探测方法评估特征质量,特别是在可能从更好的3D理解中受益的下游任务,如语义分割和深度估计。
-
-
特征融合:
-
将原始2D特征与微调后的特征进行融合,以保留原始2D特征提取器的泛化能力,同时结合3D感知特征。
-
-
实验验证:
-
在多个数据集上进行广泛的实验,验证微调后的特征在不同领域(包括室内、室外和跨领域数据集)的语义分割和深度估计任务中的性能提升。
-
通过这种方法,论文展示了即使是在单一室内数据集上进行3D感知微调,所学习到的3D意识也能够在多种数据集和不同领域中转移和应用,从而提高了2D基础模型在相关下游任务中的表现。
论文做了哪些实验?
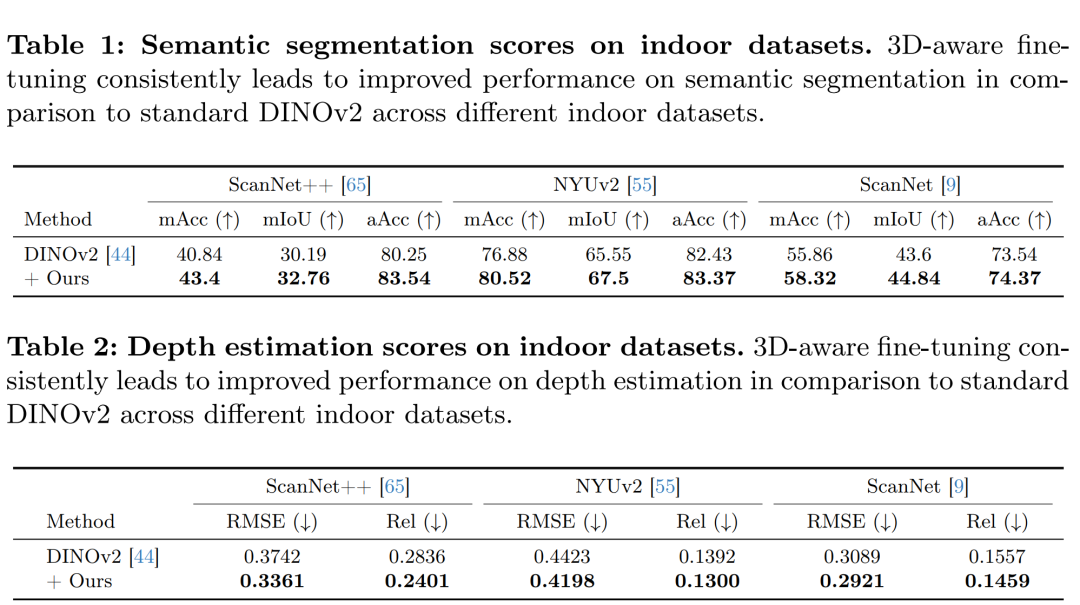
论文中进行了一系列的实验来验证所提出方法的有效性。以下是实验的主要部分和它们的目的:
-
数据集:
-
训练:使用ScanNet++数据集,这是一个大规模的3D室内场景数据集,包含亚毫米级分辨率的激光扫描、注册的DSLR图像和iPhone的商用RGB-D流。
-
评估:在ScanNet++验证集、ScanNet、NYUv2以及ADE20k、Pascal VOC和KITTI等数据集上进行语义分割和深度估计的评估。
-
-
实现细节:
-
描述了特征高斯的自定义CUDA内核实现和特征光栅化的细节。
-
微调DINOv2小型模型的参数设置,包括批量大小、学习率和训练周期。
-
-
领域内评估(Within-domain Evaluation):
-
对比了3D感知特征在语义分割和深度估计任务上的性能,与标准DINOv2特征进行了比较。
-
展示了在不同室内数据集上,3D感知微调特征如何一致地提高性能。
-
-
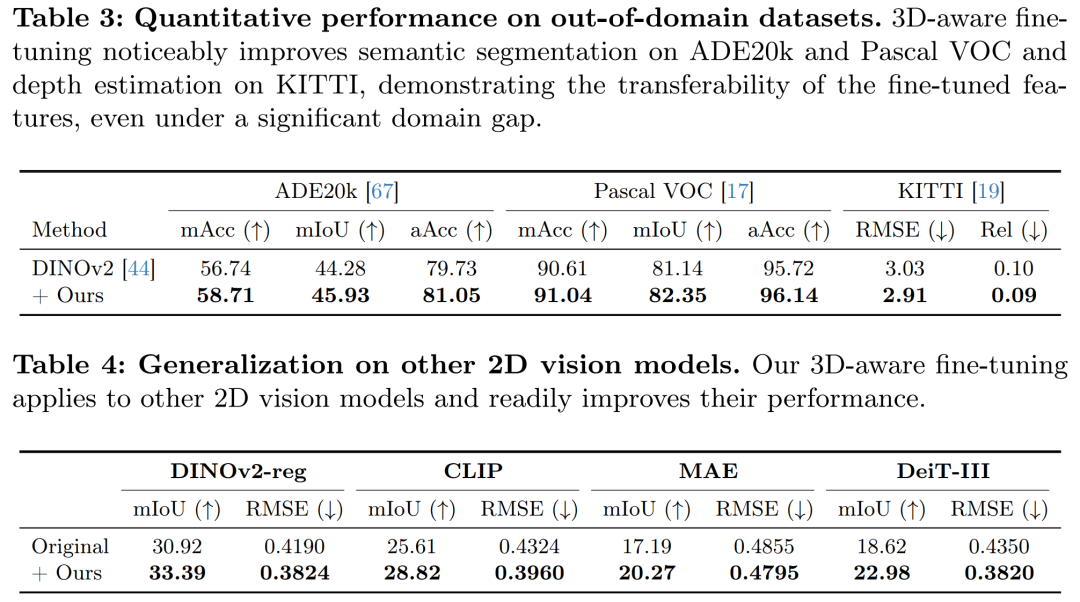
跨领域评估(Out-of-domain Evaluation):
-
研究了在ScanNet++上训练的3D感知特征在其他领域(如ADE20k、Pascal VOC和KITTI)的泛化能力。
-
证明了3D感知特征在语义分割和深度估计任务上的改进是可转移的。
-
-
其他视觉模型的泛化性(Generalization to Other Vision Models):
-
在DINOv2-reg、CLIP、MAE和DeiT-III等其他2D视觉模型上验证了3D感知微调方法的通用性。
-
-
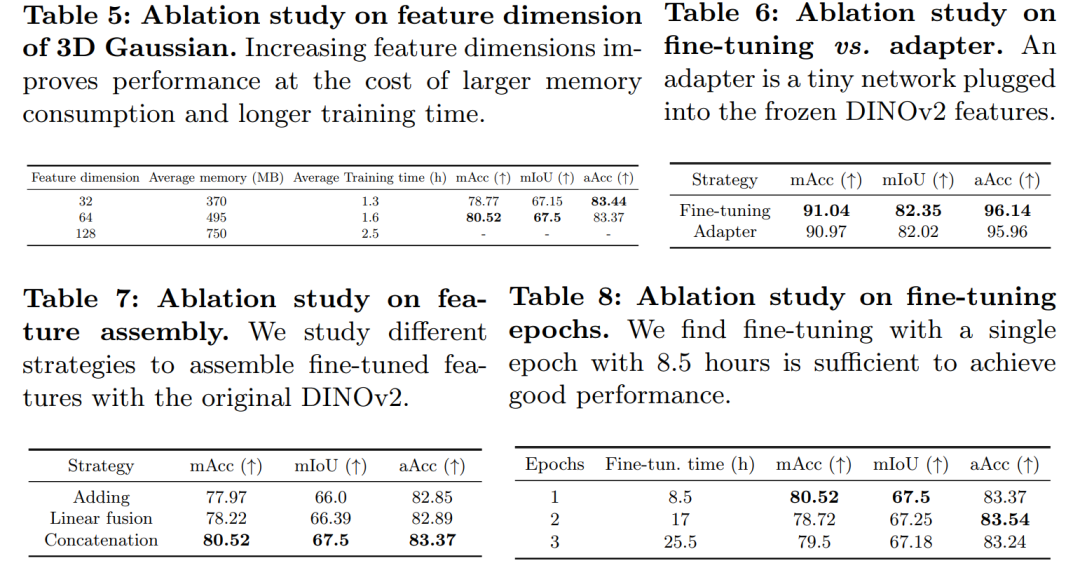
消融研究和分析(Ablation Studies and Analysis):
-
研究了3D高斯的特征维度对模型性能的影响。
-
探讨了不同的特征融合策略,如简单相加、线性融合和拼接。
-
分析了微调周期对模型性能的影响。
-
-
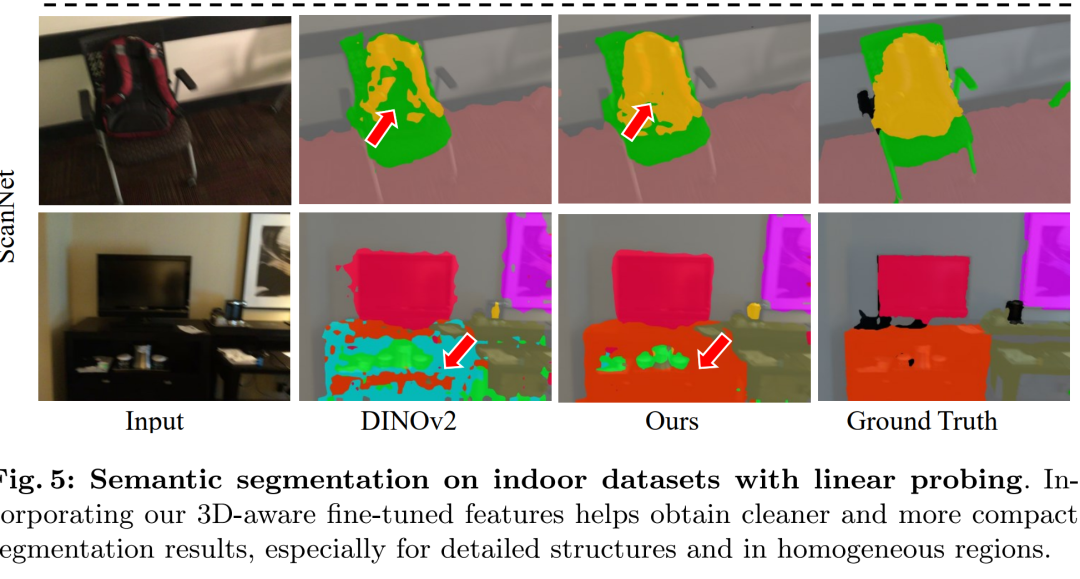
特征可视化和聚类(Visual Analysis of Features):
-
通过主成分分析(PCA)和K-Means聚类展示了3D感知微调特征的可视化效果,以及它们在不同数据集上的表现。
-
-
附加实验(Appendix Experiments):
-
在附录中,作者还提供了使用不同DINOv2 ViT变体的实验结果,以及在更多任务和头部上的实验结果。
-
这些实验全面地展示了3D感知微调方法在提升2D特征表示方面的效果,并验证了其在不同任务和数据集上的泛化能力。
论文的主要内容:
这篇论文的主要内容可以概括为以下几个要点:
-
问题识别:论文指出当前的视觉基础模型主要在2D数据上训练,这限制了它们对3D结构的理解能力。
-
方法提出:为了解决这个问题,作者提出了一种3D感知微调方法,通过将2D特征提升到3D表示,然后利用这些3D感知特征来微调2D模型。
-
两阶段流程:
-
第一阶段:将2D图像特征通过3D高斯散射技术提升为3D特征表示。
-
第二阶段:使用这些3D特征来微调2D基础模型,使其获得更好的3D结构理解能力。
-
-
技术细节:
-
利用多视图一致性来提升特征。
-
设计了特征光栅化和上投影CNN解码器来处理特征的降维和升维。
-
通过优化3D高斯参数来拟合多视图图像和特征。
-
-
实验验证:
-
在多个室内和室外数据集上进行实验,验证了微调后的特征在语义分割和深度估计任务中的性能提升。
-
证明了3D感知微调的通用性和跨领域泛化能力。
-
-
消融研究:
-
对特征维度、微调周期和特征融合策略进行了消融研究,以分析不同因素对性能的影响。
-
-
可视化分析:
-
通过特征可视化和K-Means聚类展示了3D感知微调如何改善特征的质量和结构。
-
-
结论:
-
论文得出结论,通过3D感知微调可以显著提升2D特征表示的性能,并且这种提升是可转移的,即使在训练数据有限的情况下也能有效。
-
-
未来工作:
-
论文讨论了未来可能的研究方向,包括多尺度3D特征融合、更广泛的数据集应用、不同任务的适应性研究等。
-
整体而言,论文的核心贡献在于提出了一种有效的方法来增强2D视觉模型对3D世界的理解,并通过一系列实验验证了该方法的有效性和泛化能力。
3.FlexAttention for Efficient High-Resolution Vision-Language Models

标题: FlexAttention 用于高效的高分辨率视觉语言模型
作者:Junyan Li, Delin Chen, Tianle Cai, Peihao Chen, Yining Hong, Zhenfang Chen, Yikang Shen, Chuang Gan
文章链接:https://arxiv.org/abs/2407.20228
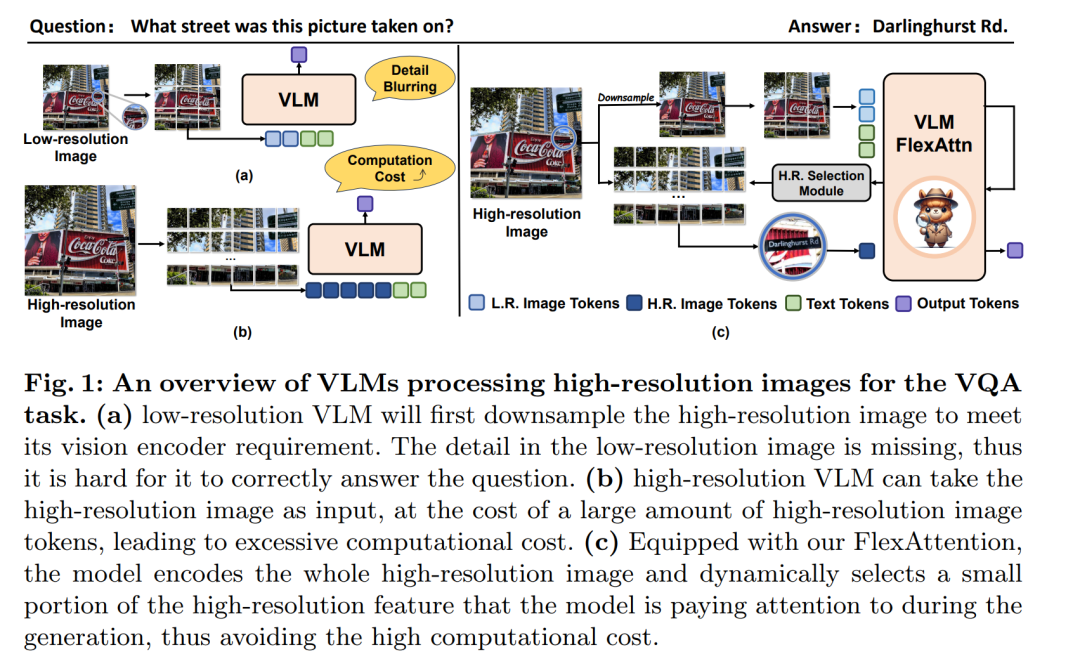
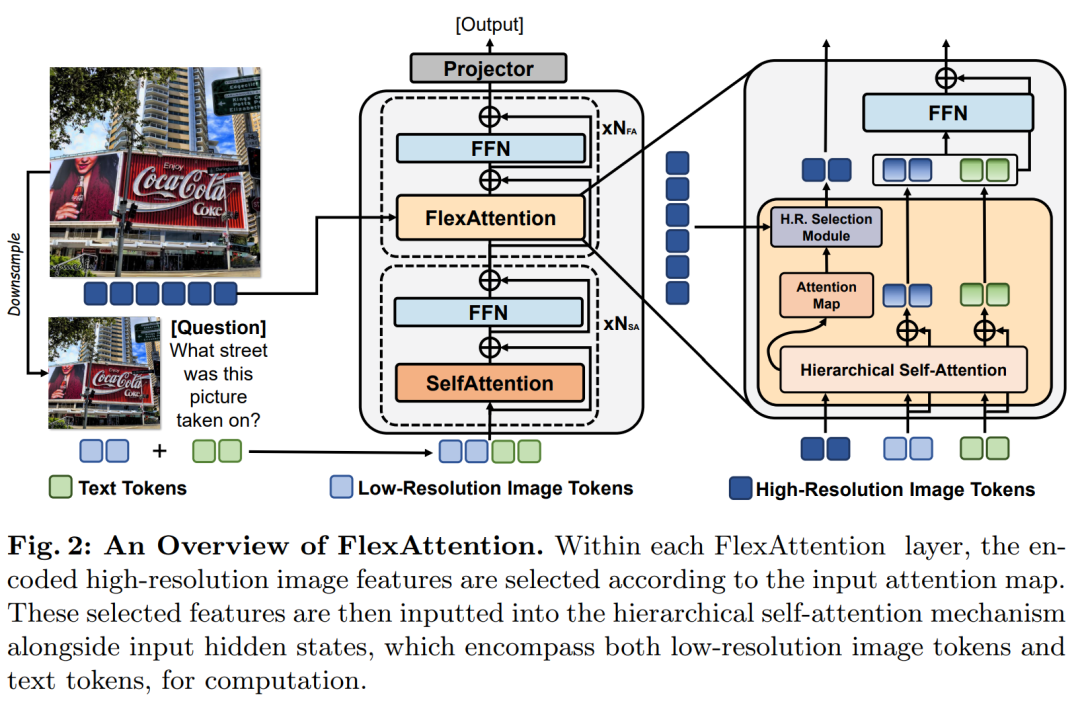
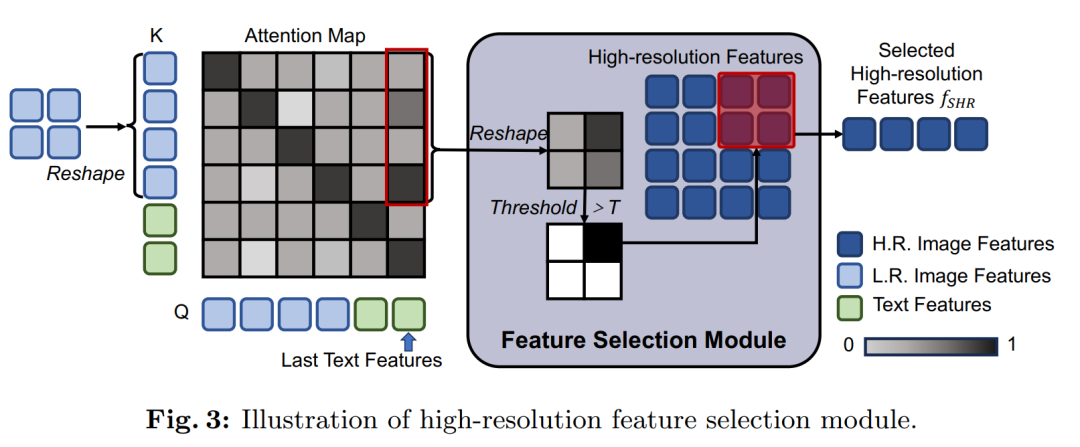

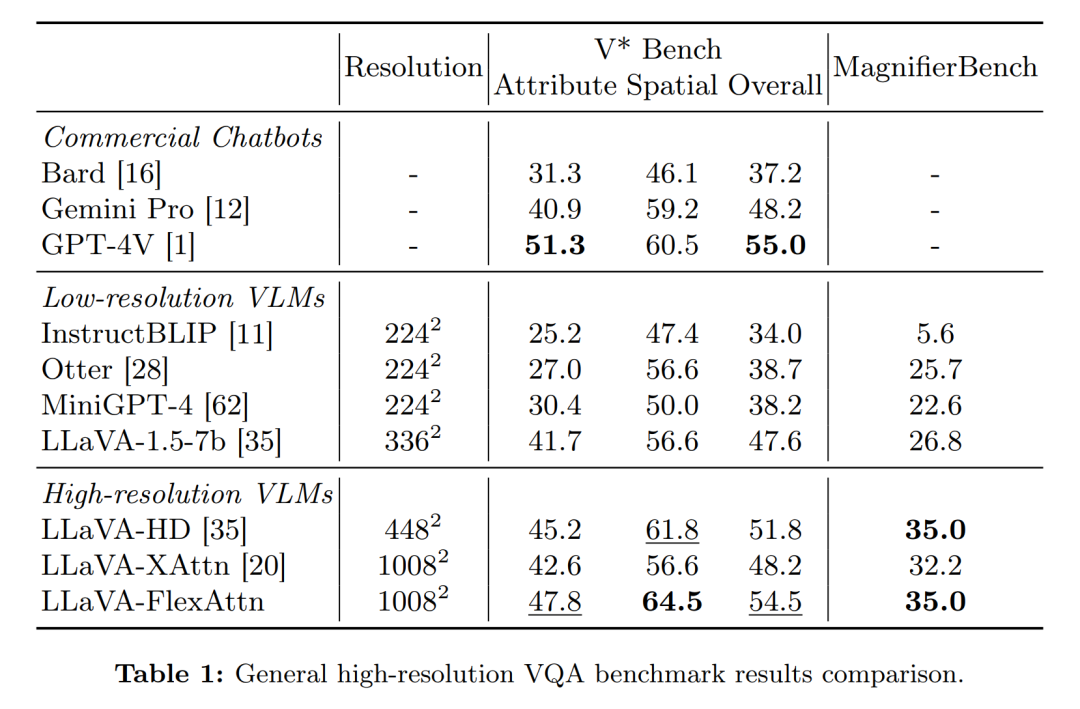
摘要:
当前的高分辨率视觉语言模型将图像编码为高分辨率图像标记,并详尽地采用所有这些标记来计算注意力,这显着增加了计算成本。为了解决这个问题,我们提出了 FlexAttention,一种用于高效高分辨率视觉语言模型的灵活注意机制。具体来说,高分辨率图像被编码为高分辨率标记和低分辨率标记,其中仅利用低分辨率标记和少数选定的高分辨率标记来计算注意力图,这大大降低了计算成本。高分辨率标记是通过高分辨率选择模块选择的,该模块可以基于输入注意图检索相关区域的标记。然后将所选的高分辨率标记连接到低分辨率标记和文本标记,并输入到分层自注意力层,该层会生成可用于下一步高分辨率标记选择的注意力图。对于每个注意层迭代地执行分层自注意过程和高分辨率标记选择过程。多模态基准实验证明,我们的 FlexAttention 优于现有的高分辨率 VLM(例如,V* Bench 中相对约 9%,TextVQA 中约 7%),同时还显着降低了近 40% 的计算成本。
这篇论文试图解决什么问题?
这篇论文试图解决的问题是当前高分辨率视觉-语言模型(Vision-Language Models, VLMs)在处理高分辨率图像时面临的计算成本显著增加的问题。具体来说,现有的高分辨率VLMs在编码图像时,会将图像编码为高分辨率的图像tokens,并在计算注意力(attention)时穷尽地使用所有这些tokens,这导致计算成本大幅增加。为了解决这一问题,论文提出了一种名为FlexAttention的灵活注意力机制,旨在提高高分辨率视觉-语言模型的效率。
FlexAttention的核心思想是:
-
对高分辨率图像进行编码时,同时生成高分辨率tokens和低分辨率tokens。
-
在计算注意力图时,只使用低分辨率tokens和根据输入注意力图选择的少量高分辨率tokens,从而大幅减少计算成本。
-
通过一个高分辨率选择模块(high-resolution selection module),基于输入的注意力图检索相关区域的高分辨率tokens。
-
所选的高分辨率tokens与低分辨率tokens和文本tokens一起输入到一个分层自注意力层(hierarchical self-attention layer),该层产生可用于下一步高分辨率token选择的注意力图。
-
这种分层自注意力过程和高分辨率token选择过程在每个注意力层迭代执行。
通过这种方法,FlexAttention能够在保持高分辨率图像细节的同时,显著降低计算成本,并在多模态基准测试中取得了优于现有高分辨率VLMs的性能。
论文如何解决这个问题?
论文通过提出FlexAttention机制来解决高分辨率视觉-语言模型在处理高分辨率图像时计算成本增加的问题。具体解决方案如下:
-
双分辨率图像编码:将高分辨率图像同时编码为高分辨率tokens和低分辨率tokens。
-
分层自注意力模块:在模型的前几层使用低分辨率tokens和文本tokens进行计算,以大致理解整个图像。在后续的解码器层中,引入FlexAttention模块,该模块只使用低分辨率tokens和少量选择的高分辨率tokens来计算注意力,从而减少计算成本。
-
高分辨率特征选择模块:基于输入的注意力图,动态选择与当前任务相关的高分辨率区域的tokens。这一模块通过分析注意力图中的值来确定哪些高分辨率tokens是重要的,并仅将这些tokens传递给注意力模块。
-
迭代处理:在每个解码器层中,高分辨率特征选择模块和分层自注意力模块迭代地处理,直到最后一层。这样可以在不同层次上逐步细化对图像细节的理解。
-
计算复杂度优化:通过上述方法,FlexAttention的计算复杂度为(O((M + N)ND)),其中(M)是选择的高分辨率特征的长度,(N)是原始隐藏状态的长度,(D)是隐藏状态大小。这与直接添加高分辨率图像的原始自注意力计算复杂度(O((M + N)^2D))相比,显著降低了计算负担。
-
实验验证:在多模态基准测试中,论文通过实验验证了FlexAttention在性能和效率上均优于现有的高分辨率方法。实验结果表明,FlexAttention在减少约40%的计算成本的同时,还能在多个基准测试中取得更好的性能。
通过这些方法,论文成功地提高了高分辨率视觉-语言模型的效率,同时保持了对图像细节的感知能力。
论文做了哪些实验?
论文中进行了多项实验来评估FlexAttention的性能和效率,实验主要包括以下几个方面:
-
集成实现:将FlexAttention集成到LLaVA-1.5-7b模型中,创建了一个变体称为LLaVAFlexAttn,并将其与原始的LLaVA-1.5-7b模型进行比较,以展示使用高分辨率图像输入的优势。
-
训练设置:所有模型(包括高分辨率基线模型和LLaVAFlexAttn)都使用LLaVA-1.5-7b的预训练权重进行初始化,并在相同的微调数据集上进行微调。
-
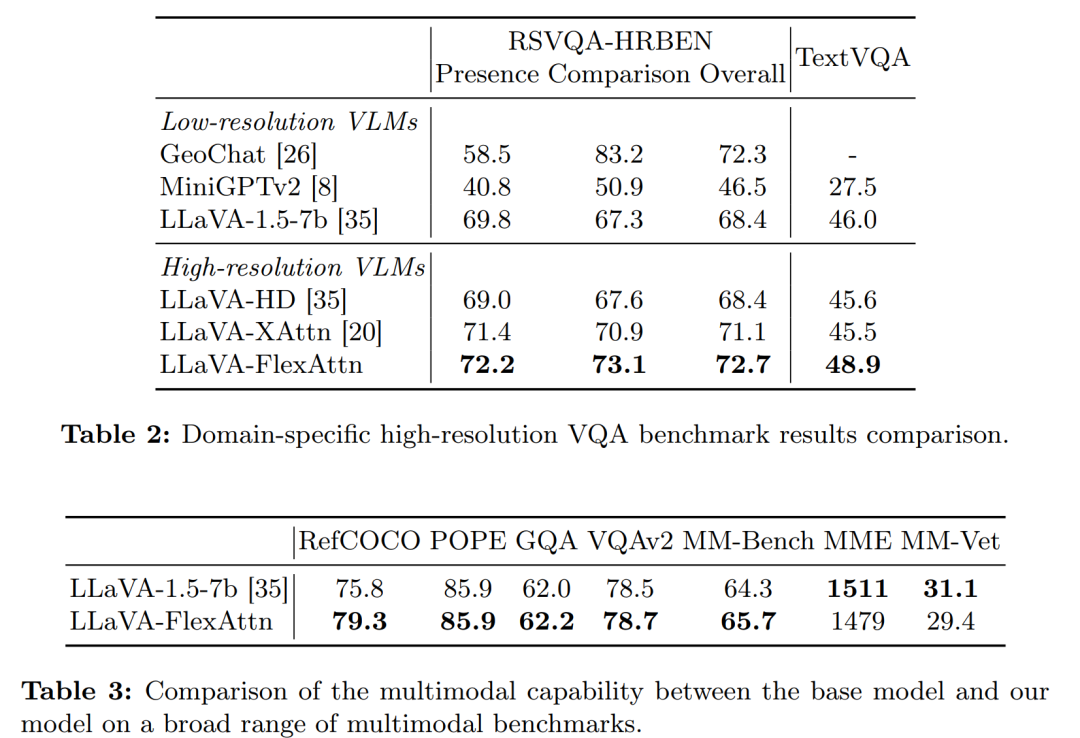
高分辨率多模态基准测试:在四个高分辨率基准测试上进行实验,包括V* Bench、MagnifierBench、TextVQA和RSVQA-HRBEN,以评估模型在一般高分辨率视觉问答(VQA)和特定领域高分辨率VQA(如文本理解和遥感)上的性能。
-
一般多模态基准测试:在多个多模态任务上评估模型的一般性能,包括GQA、VQAv2、POPE、RefCOCO、MM-Bench、MME和MM-Vet等基准测试。
-
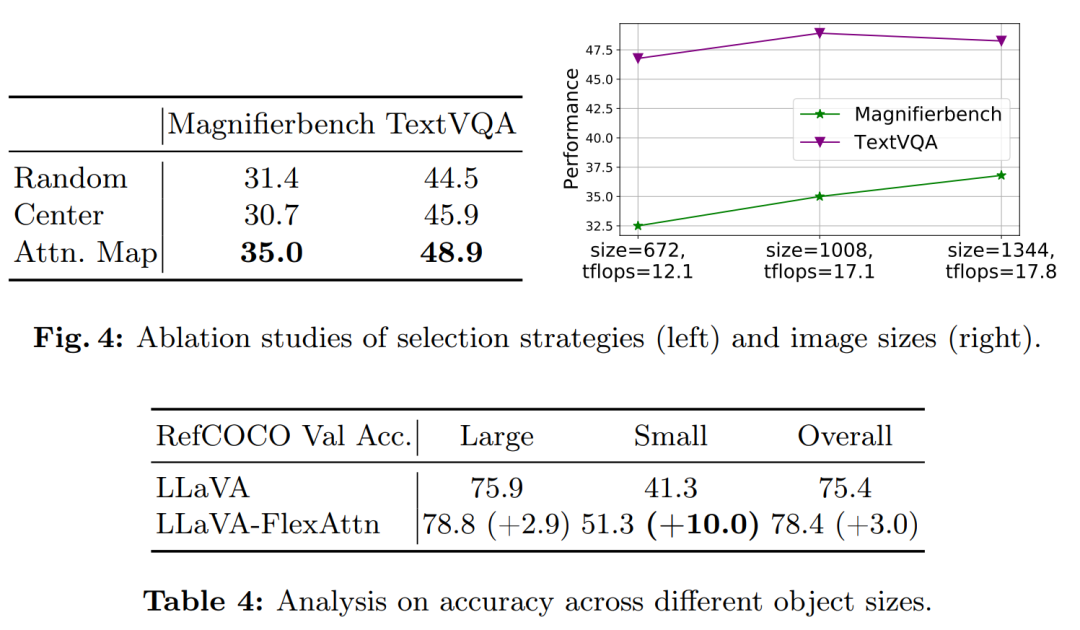
消融研究:
-
验证了使用注意力图选择高分辨率特征的策略的有效性,与随机选择和中心选择两种简单策略进行了比较。
-
探索了不同分辨率图像大小对模型性能的影响。
-
分析了不同对象大小对模型在一般基准测试上性能的影响。
-
-
硬件推理时间测试:在NVIDIA V100 GPU上测量了模型的推理时间,以评估FlexAttention的效率。
-
性能比较:将LLaVAFlexAttn与其他低分辨率和高分辨率的视觉-语言模型(包括商业聊天机器人和专家VLM)进行了比较,以评估高分辨率图像输入能力的重要性。
这些实验结果表明,FlexAttention在保持高分辨率图像细节的同时,显著降低了计算成本,并在多个基准测试中取得了优于现有高分辨率VLMs的性能。
论文的主要内容:
这篇论文的主要内容包括以下几个方面:
-
问题识别:论文指出了现有高分辨率视觉-语言模型(VLMs)在处理高分辨率图像时面临的主要问题,即计算成本过高。
-
FlexAttention机制:为了解决上述问题,论文提出了一种新的注意力机制——FlexAttention。这种机制通过同时使用高分辨率和低分辨率图像tokens,并动态选择重要的高分辨率tokens来计算注意力,从而显著降低了计算成本。
-
模型架构:论文详细介绍了FlexAttention的架构,包括高分辨率特征选择模块和分层自注意力模块,以及它们是如何与现有的视觉-语言模型集成的。
-
实验验证:论文通过一系列实验验证了FlexAttention的有效性。实验包括在多个高分辨率多模态基准测试上的评估,以及与现有方法的比较。
-
性能提升:实验结果表明,FlexAttention在减少计算成本的同时,能够在多个基准测试中取得优于现有高分辨率VLMs的性能。
-
消融研究:论文还进行了消融研究,以评估FlexAttention中不同组件的影响,包括特征选择策略、图像分辨率的影响以及对象大小对模型性能的影响。
-
硬件推理时间测试:论文测量了模型在实际硬件上的推理时间,进一步证明了FlexAttention的效率。
-
未来方向:论文讨论了FlexAttention可能的扩展方向,如将其应用于视频或音频等其他长序列模态。
-
结论:论文总结了FlexAttention的主要贡献,并指出了其在提高大型视觉-语言模型处理高分辨率图像能力方面的潜力。
整体而言,这篇论文提出了一种创新的注意力机制,有效地解决了高分辨率视觉-语言模型中的效率问题,并在多个方面展示了其优势和潜在的应用前景。

















 1625
1625

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











