







文章目录
所谓“共识机制”,是通过特殊节点的投票,在很短的时间内完成对交易的验证和确认;对一笔交易,如果利益不相干的若干个节点能够达成共识,我们就可以认为全网对此也能够达成共识。再通俗一点来讲,如果中国一名微博大V、美国一名虚拟币玩家、一名非洲留学生和一名欧洲旅行者互不相识,但他们都一致认为你是个好人,那么基本上就可以断定你这人还不坏。
百度百科
Consensus
当谈及分布式环境中的共识时,一般涉及到两种类型的节点:
- Legitimate nodes:诚实节点,觉得你是好人,就投票你为好人
- Malicious nodes:恶意节点,行为“恶劣”,颠倒黑白
此外,即使发生任何故障,我们的系统也必须正常运行。有两种类型的故障会发生:
- Crash failure:诚实节点发生的故障(消息延迟、不可送达)
- Byzantine failure:恶意节点造成的故障(篡改消息、不按套路执行协议)
因此,区块链共识协议的主要责任有:
- 保持账本(区块链)中的数据的有序性、安全性
- 在区块链网络中的节点之间达成协议,即提供拜占庭协议(即使出现拜占庭式的失败,也不会造成太大影响)
拜占庭协议(Byzantine Agreement)采用的方法是确保可以通过分布式的方法达成共识,即使出现了拜占庭式的失败也不会影响。“拜占庭失败”可以理解为恶意节点造成的故障。
下面列出一些著名的 DLT(分布式账本)以及它们所使用的共识算法:
| DLT | Consensus Algorithm Used | Description |
|---|---|---|
| Bitcoin | PoW | 应用 PoW 来生产新的货币 |
| Ethereum | PoW | |
| Hyperledger | PBFT | 如果 2/3 的成员对新的区块达成共识,那么该区块就成为区块链的一部分 |
| Parity | PoS | 要求矿工提供一定数量加密货币的所有权,而不要求其算力 |
| Hashgraph | Virtual voting-based consensus algorithm | |
| Tezos | PoS |
Proof of Work(PoW)
比特币区块链的共识机制,PoW 是为公共区块链设计的。在 PoW 中,共识能否最终达成是不被保证的。在 PoW 中,矿工既是 leader node 又是 validator node。
节点通过计算随机哈希散列的数值解争夺记账权,求得正确的数值解以生成区块的能力是节点算力的具体表现,算力越高,就越有可能解得数值。计算出哈希值的节点才能够向区块链中添加区块,并获得奖励。某个节点获胜的概率为
P w i = φ i ∑ j = 1 N φ j P_{w_i}=\frac{\varphi_i}{\sum_{j=1}^N \varphi_j} Pwi=∑j=1Nφjφi
其中, i i i 代表每个参与节点, N N N 是节点的总数量, φ i \varphi_i φi 代表节点 i i i 的算力。
PoW 存在的问题:
- 如果某两个矿工同时解出了 PoW puzzle,就会造成所谓的 fork
- 达成共识所需周期长
- 耗费大量计算资源
- 双花问题(double spending)
假如我们微信钱包里有 100 块钱的庞大资产,我们先去饭店吃了顿饭,结果微信出了 bug,这一笔钱并没有被银行同步,还留在钱包里,于是我们又能拿着同样的 100 块钱去看场电影,这就属于双花问题。在区块链系统中,由于共识机制导致区块确认时间长,用一个数字货币去进行一次交易,可以在这笔交易还未被确认完成前,进行第二笔交易,这就会造成双花问题。
PoW 的容错能力:
- PoW 可能会遭到 51% 算力攻击。当系统中有合作关系的恶意节点所控制的算力,超过诚实节点所控制的算力,系统就有被攻击的风险。
- 可以容忍拜占庭失败
- 可以有效抵御“女巫攻击”(Sybil Attack),即少数恶意节点构造多个虚假身份,并利用这些身份控制或影响网络的大量正常节点。
Proof of Stake(PoS)
在权益证明(PoS)类共识协议中,矿工的选择取决于每个节点携带的“权益”(如加密货币)数量,而不是其计算能力。
PoS 相比 PoW 会消耗更少的资源,缩短达成共识所需的时间。当然,PoS 也存在自己的一些问题,例如,在 PoS 中,奖励的授予方式应该是使所有节点都有平等的机会参与到采矿过程中。 否则,每次获胜的都为权益较高的矿工,每次得到奖励的也是它。而且如果有任何延迟或链接的连接问题,节点可能没有账本的最新副本,因此会导致同步问题。
下面这张图总结了 PoS 相比 PoW 的一些区别:

PAXOS
最基本的分布式共识(一致性)算法,允许在不可靠的通信条件下(信息可以延迟、丢失或者重复,但没有出错)对一个值达成共识。
PAXOS 的核心 idea 是,如果有一半以上的进程选择了一个值,那么依据多数人代表整体的原则,这个值就是共识。
PAXOS 中的节点:
- Proposer:提出要达成一致的值。某个选取的 Proposer 作为一个单的的 leader,提出一个新的决议,它处理客户的请求。
- Acceptor:Acceptor 根据若干规则和条件对决议进行评估,并决定接受还是拒绝 Proposer 提出的建议。
- Learner:获取 Acceptor 达成一致的值
Phases in PAXOS
Prepare Phase
- Proposer 收到客户提出的就某个值达成共识的请求;
- Proposer 向大多数或所有 Acceptor 发送一个消息
prepare(n); - Acceptor 接收到
prepare(n)消息,并进行回应。
在第二步中, n n n 代表 proposal number,它必须是全局唯一的,且要大于该 Proposer 之前使用过的 proposal number。如果 Proposer 没有收到来自大多数 Acceptor 的响应,那么它需要增大 n n n,重新发送。
在第三步中,如果 Acceptor 之前没有做出过任何响应,那么它会回复 promise(n) 消息,并承诺会忽略之后任何小于
n
n
n 的 proposal number。而如果 Acceptor 之前有做出过回应,即对某个小于
n
n
n 的 proposal number 回复了 promise(n) 消息,那么进一步可分为两种情况:
- 如果它还没有收到来自之前 Proposer 的
accept消息,那么它会存储现在更高的 proposal number n n n,回复promise(n)消息; - 如果它已经收到了来自之前 Proposer 的
accept消息,那么它一定已经相应的回复了accepted消息,在这种情况下,它会把之前这个 full proposal 连同promise(n)消息一起回复,表明我之前已经接收过值了。
Accept Phase
- Proposer 等待,直到得到大多数 Acceptor 对该 proposal number n n n 的回应;
- 评估应该在
accept消息中发送什么 v v v 值; - 给 Acceptor 发送
accept(n, v)消息, v v v 值是实际要达成一致的值; - Acceptor 接收到
accept(n, v)消息后,要么回复accepted(n, v)消息并将该消息发给所有 learners,要么直接忽略; - 如果大多数 Acceptor 都接受了 v v v 值这个提议,那么就达成共识了。
第二步细节:如果 Proposer 收到的 promise 消息中有带有 full proposal 的,那么它会将
v
v
v 值增大 (比所有 full proposal 中一致值都大),如果都没有 full proposal 的话,
v
v
v 值可以随便选取。
第四步细节:Acceptor 接收到 accept(n, v) 消息后:
- 如果它之前已经承诺过不接受这个 proposal number,它就会忽略这个消息;
- 如果它之前回复过
promise(n)了,那么它就回复accepted(n, v)消息,并将该消息发给所有 learners。
Replicated And Fault Tolerant(RAFT)
RAFT 允许集群的重新配置,这使得集群成员的改变不需要中断服务。它还允许日志压缩,以缓解节点崩溃后缓慢重建的问题并减少消耗的存储。
一个 RAFT 集群中的节点可分为以下三种:
- Leader:接收客户请求,组织日志复制给其它节点,并管理与 Follower 的通信
- Follower:节点在本质上是被动的,只对远程过程调用(RPC)做出响应。它们从不主动发起任何通信,只会接受 leader 的复制日志,对 leader 言听计从
- Candidate:尝试成为 leader 的节点,会发起投票请求
RAFT 主要包括两个阶段:
- leader election
- log replication
这里先将三个节点之间的状态转换图给出,具体过程可以往下看。

Leader Election
Leader Election 会基于一个心跳(heartbeat)机制来触发 leader 的选举过程:
- 所有的节点一开始都是 Follower;
- 如果 Follower 持续收到来自 leader 或者 candidate 的远程过程调用,那么它们只会保持自己 Followe 的身份;
- 如果特定时间内某个 Follower 没有收到来自 leader 的心跳包,表明 leader 可能已经失效了,那么该 Follower 就会变为 Candidate,发起新的选举,尝试变为 leader;
- 如果 Candidate 收到了大多数的选票,那么它就“竞选”成功,成为 leader。但如果多个 Follower 同时变为 Candidate,且它们的选票不相上下,那么此时就无法决出胜者,RAFT 为每轮选举都设置了超时时间,如果在这段时间内还没有选出新的 leader(election timeout),那么就会开启新一轮的选举过程。
不管是在 Follower 变为 Candidate 时的等待时间,还是选举时的 timeout 时间,都可能会发送这样的情况:不同 Follower 设置的等待时间或者不同 Candidate 的 timeout 时间相同,那么这一轮选举超时了,下一轮同样的 Follower 又变为了 Candidate,相同的 timeout 时间内还是没有从这些 Candidate 中还是没有选出 leader,又进入下一轮…
因此我们在实际中会将 Candidate 的 timeout 时间以及 Follower 的等待时间随机化,每轮选举后,每个 Candidate 都会让自己的任期号 += 1,这样我们每轮就可以选择任期号最大的那个 Candidate,减小冲突的概率。此外,发生冲突的选举后,Candidate 间隔下一次选举的时间也要随机化。
上图中还缺少一点,如果 candidate 收到了来自 leader 的心跳包,那么说明选举结束了,它会变为 follower。
Log Replication
- 客户给 leader 发送请求;
- leader 会给该请求添加一个任期号(term)以及索引(index),使得该请求或命令在日志中能够被唯一识别,然后将该请求添加到自己的日志中;
- 并行地给 follower 发送
AppendEntriesRPC,将新的日志项传递给 follower。 - 当集群中的大多数 follower 都追加了该请求后,leader 会提交该日志, 并执行指令改变状态机的状态,并返回结果给客户。它也会通过
AppendEntriesRPC 告诉 follower 日志已经被提交,以便让 follower 也开始执行指令改变它们自己状态机的状态
上述过程的日志追加可看下图:

Practical Byzantine Fault Tolerance (PBFT)
从名字中也可以看出,PBFT 被设计用来在有拜占庭错误的情况下提供共识。
PBFT 包含三个子协议:
- normal operation:该协议在一切正常,无错发生的情况下运行
- view change:在 leader 节点出错的情况下运行
- checkpointing:丢弃系统中的旧数据
PBFT 同样也有三种节点:
- replicas:每个 PBFT 协议中的参与者(包括 leader 和 backup)
- leader:也叫 primary,每个轮次都会有一个 leader 来与客户通信,leader 不变,则一直为同一个 view
- backup:除去 leader 外的其它所有节点
如果想要容忍拜占庭错误,那么节点的最小数量应为 n = 3 f + 1 n=3f+1 n=3f+1,也就是说,如果要容忍 f f f 个故障,那么这个系统必须要有 n n n 个节点。只要系统中的节点数量保持 n ≥ 3 f + 1 n\ge3f+1 n≥3f+1,PBFT 就可以提供拜占庭容错。
PBFT 协议的执行分为 3 个阶段:
- Pre-prepare
- Prepare
- Commit
Pre-prepare Phases
- leader 从客户端接收一个请求;
- 为该请求分配对应的序列号,序列号代表着请求被执行的顺序;
- 将该请求信息(
pre-preparemessage)广播到所有 backups 备份。
Prepare Phase
- backups 只会接收之前未接收过的序列号或者不同 view 对应的
pre-prepare消息; - 将
prepare消息发给所有节点。
Commit Phases
- 收到
prepare消息的 replica 对消息进行验证(是否为相同的请求、view 以及序列号),直到集齐 2 f + 1 2f+1 2f+1 个验证好的消息; - 广播
commit消息给所有 replica; - 如果集齐
2
f
+
1
2f+1
2f+1 个到达的有效
commit消息,说明决议通过; - 执行该请求/决议
- 返回给客户
reply消息,包含处理结果
下图为一个在 normal operation 协议下运行的 PBFT 基本过程,这是最简单过程,因为为了达到 n ≥ 3 f + 1 n\ge3f+1 n≥3f+1 的要求,系统中至少需要 4 个节点。
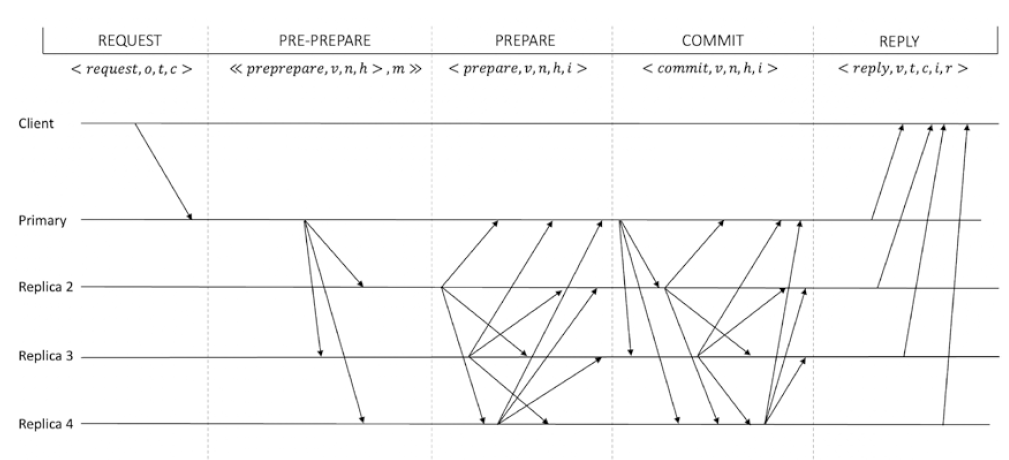
关于 RAFT 算法的最大容错节点数量是(n-1)/2,而 PBFT 算法的最大容错节点数量是(n-1)/3 的补充说明:(《深入剖析区块链的共识算法 Raft & PBFT》)
对于 RAFT 算法,它只支持容错故障节点,不支持容错作恶节点。故障节点就是节点因为系统繁忙、宕机或者网络问题等其它异常情况导致的无响应,出现这种情况的节点就是故障节点(也就是我们开头提到过的诚实节点的故障,Crash failure)。作恶节点除了可以故意对集群的其它节点的请求无响应之外,还可以故意发送错误的数据,或者给不同的其它节点发送不同的数据,使整个集群的节点最终无法达成共识,这种节点就是作恶节点(也就是我们开头提到过的恶意节点造成的故障,Byzantine failure)。
RAFT 算法只支持容错故障节点,假设集群总节点数为 n n n,故障节点数为 f f f,根据小数服从多数的原则,集群里正常节点只需要比 f f f 个节点再多一个节点,即 f + 1 f+1 f+1 个节点,正确节点的数量就会比故障节点数量多,那么集群就能达成共识。因此 RAFT 算法支持的最大容错节点数量是(n-1)/2。
对于 PBFT 算法,因为 PBFT 算法的除了需要支持容错故障节点之外,还需要支持容错作恶节点。假设集群节点数为 n n n,有问题的节点为 f f f。有问题的节点中,可以既是故障节点,也可以是作恶节点,或者只是故障节点或者只是作恶节点。如果故障节点和作恶节点都是不同的节点,那么就会有 f f f 个作恶节点和 f f f 个故障节点。当发现节点是作恶节点后,会被集群排除在外,剩下 f f f 个故障节点,那么根据小数服从多数的原则,集群里正常节点只需要比 f f f 个节点再多一个节点,即 f + 1 f+1 f+1 个节点,正确节点的数量就会比故障节点数量多,那么集群就能达成共识。所以,所有类型的节点数量加起来就是 f + 1 f+1 f+1 个正确节点, f f f 个故障节点和 f f f 个问题节点,即至少需要 3 f + 1 3f+1 3f+1 个节点。
Metrics of Consensus
IT 系统的性能和可扩展性一直是用来衡量区块链共识算法的关键非功能性指标。
Performance
Transaction Throughput:
交易吞吐量被定义为区块链网络每秒钟可以处理的交易(Tx)数量。它可以通过如下公式进行计算:
T
r
a
n
s
a
c
t
i
o
n
T
h
r
o
u
g
h
p
u
t
=
B
l
o
c
k
S
i
z
e
(
B
y
t
e
s
)
T
r
a
n
s
a
c
t
i
o
n
S
i
z
e
(
B
y
t
e
s
)
×
B
l
o
c
k
T
i
m
e
(
s
e
c
o
n
d
s
)
{\rm Transaction\ Throughput}=\frac{Block\ Size\ (Bytes)}{Transaction\ Size\ (Bytes) \times Block\ Time\ (seconds)}
Transaction Throughput=Transaction Size (Bytes)×Block Time (seconds)Block Size (Bytes)
其中,Block Time 为将一个区块添加到区块链中所花费的平均时间。
显然,区块尺寸越大,吞吐量就越高,而 Block Time 或者交易规模越大,吞吐量就越小。(固定其余两个量)
当交易大小为 500 Bytes,Block Time 为 10s 时,吞吐量随区块大小变化如下图所示:

















 4657
4657











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











