






2.3.1.5修改hive-site.xml数据库相关的配置
4.1报错Unable toload native-hadoop library for your platform
4.2报错There are2 datanode(s) running and 2 node(s) are excluded in this operation
关键字:Linux Java CentOS Hadoop Hive
说明:安装hive前提是要先安装hadoop集群,并且hive只需要再hadoop的namenode节点集群里安装即可(需要再所有namenode上安装),可以不在datanode节点的机器上安装。另外还需要说明的是,虽然修改配置文件并不需要你已经把hadoop跑起来,但是本文中用到了hadoop命令,在执行这些命令前你必须确保hadoop是在正常跑着的,而且启动hive的前提也是需要hadoop在正常跑着,所以建议你先将hadoop跑起来在按照本文操作。
如何安装和启动hadoop集群,请参考:
http://blog.csdn.net/pucao_cug/article/details/71698903
1下载hive
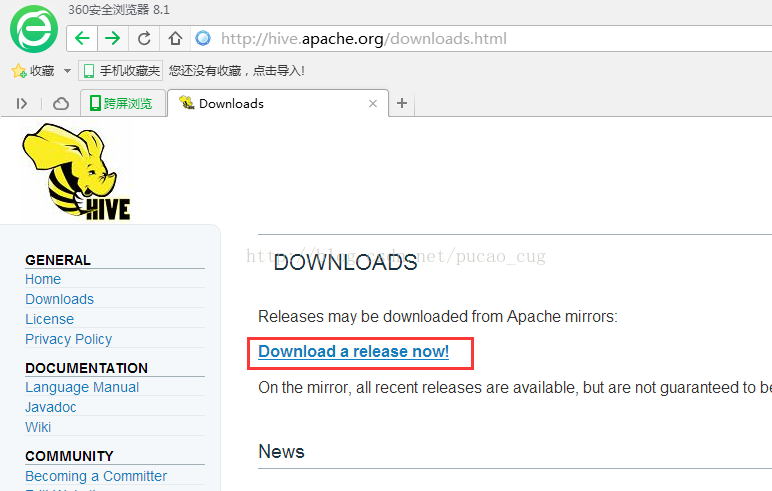
下载地址:http://hive.apache.org/downloads.html
点击上图的Download release now!
如图:
点击上图的某个下载地址,我点击的是国内的这个地址:http://mirror.bit.edu.cn/apache/hive/
如图:

点击进入:
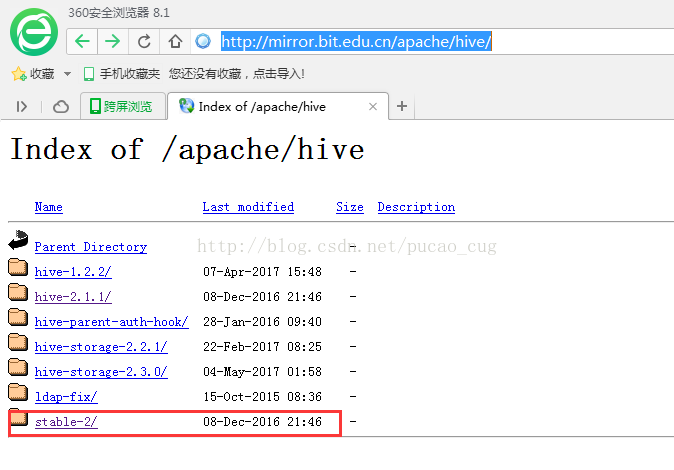
apache-hive-2.1.1-bin.tar.gz
2安装
2.1上载和解压缩
在opt目录下新建一个名为hive的目录,将apache-hive-2.1.1-bin.tar.gz拷贝上去
执行进入目录的命令:
cd /opt/hive
执行解压缩的命令:
tar -zxvf apache-hive-2.1.1-bin.tar.gz
2.2配置环境变量
编辑/etc/profile文件,增加hive相关的环境变量配置
如图:
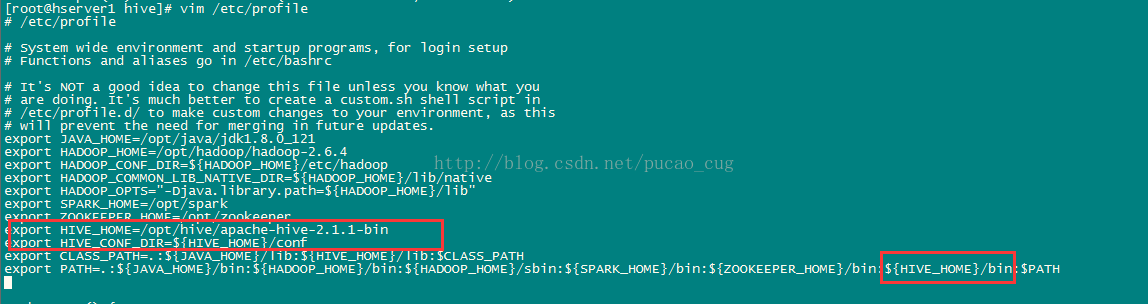
该文件中手工增加的内容是(橘黄色字体部分):
export JAVA_HOME=/opt/java/jdk1.8.0_121
export HADOOP_HOME=/opt/hadoop/hadoop-2.8.0
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib"
export HIVE_HOME=/opt/hive/apache-hive-2.1.1-bin
export HIVE_CONF_DIR=${HIVE_HOME}/conf
export CLASS_PATH=.:${JAVA_HOME}/lib:${HIVE_HOME}/lib:$CLASS_PATH
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${HIVE_HOME}/bin:$PATH
profile文件编辑完成后,执行下面命令,让配置生效,命令是;
source /etc/profile
说明:上面的环境变量中只有JAVA_HOME相关的、HADOOP相关的、HIVE相关的是必须的, 相关的路径必须要和你机器对应。
2.3对hive进行配置
2.3.1 hive-site.xml相关的配置
2.3.1.1新建hive-site.xml文件
进入到/opt/hive/apache-hive-2.1.1-bin/conf目录,命令是:
cd /opt/hive/apache-hive-2.1.1-bin/conf
将hive-default.xml.template文件复制一份,并且改名为hive-site.xml,命令是:
cp hive-default.xml.template hive-site.xml
2.3.1.2使用hadoop新建hdfs目录
因为在hive-site.xml中有这样的配置:
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<name>hive.exec.scratchdir</name>
<value>/tmp/hive</value>
所以要让hadoop新建/user/hive/warehouse目录,执行命令:
$HADOOP_HOME/bin/hadoop fs -mkdir -p /user/hive/warehouse
给刚才新建的目录赋予读写权限,执行命令:
$HADOOP_HOME/bin/hadoop fs -chmod 777 /user/hive/warehouse
如图:

让hadoop新建/tmp/hive/目录,执行命令:
$HADOOP_HOME/bin/hadoop fs -mkdir -p /tmp/hive/
如图:

给刚才新建的目录赋予读写权限,执行命令:
$HADOOP_HOME/bin/hadoop fs -chmod 777 /tmp/hive
如图:
2.3.1.3检查hdfs目录是否创建成功
检查/user/hive/warehouse目录是否创建成功,执行命令:
$HADOOP_HOME/bin/hadoop fs -ls /user/hive/
如图:

检查/tmp/hive是否创建成功,执行命令:
$HADOOP_HOME/bin/hadoop fs -ls /tmp/
如图:

2.3.1.4修改hive-site.xml中的临时目录
将hive-site.xml文件中的${system:java.io.tmpdir}替换为hive的临时目录,例如我替换为/opt/hive/tmp,该目录如果不存在则要自己手工创建,并且赋予读写权限。
如图:

被我替换为了
如图:

将${system:user.name}都替换为root
如图:

被替换为了
如图:

说明:截图并不完整,只是截取了几处以作举例,你在替换时候要认真仔细的全部替换掉。
2.3.1.5修改hive-site.xml数据库相关的配置
搜索javax.jdo.option.ConnectionURL,将该name对应的value修改为MySQL的地址,例如我修改后是:
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.27.138:3306/hive?createDatabaseIfNotExist=true</value>
搜索javax.jdo.option.ConnectionDriverName,将该name对应的value修改为MySQL驱动类路径,例如我的修改后是:
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
搜索javax.jdo.option.ConnectionUserName,将对应的value修改为MySQL数据库登录名:
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
搜索javax.jdo.option.ConnectionPassword,将对应的value修改为MySQL数据库的登录密码:
<name>javax.jdo.option.ConnectionPassword</name>
<value>cj</value>
搜索hive.metastore.schema.verification,将对应的value修改为false:
<name>hive.metastore.schema.verification</name>
<value>false</value>
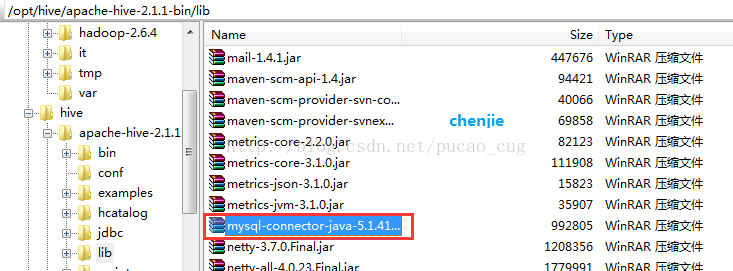
2.3.1.6将MySQL驱动包上载到lib目录
将MySQL驱动包上载到Hive的lib目录下,例如我是上载到/opt/hive/apache-hive-2.1.1-bin/lib目录下。
如图:
2.3.2新建hive-env.sh文件并进行修改
进入到/opt/hive/apache-hive-2.1.1-bin/conf目录,命令是:
cd /opt/hive/apache-hive-2.1.1-bin/conf
将hive-env.sh.template文件复制一份,并且改名为hive-env.sh,命令是:
cp hive-env.sh.template hive-env.sh
打开hive-env.sh配置并且添加以下内容:
export HADOOP_HOME=/opt/hadoop/hadoop-2.8.0
export HIVE_CONF_DIR=/opt/hive/apache-hive-2.1.1-bin/conf
export HIVE_AUX_JARS_PATH=/opt/hive/apache-hive-2.1.1-bin/lib
3启动和测试
3.1对MySQL数据库进行初始化
进入到hive的bin目录 执行命令:
cd /opt/hive/apache-hive-2.1.1-bin/bin
对数据库进行初始化,执行命令:
schematool -initSchema -dbType mysql
如图:
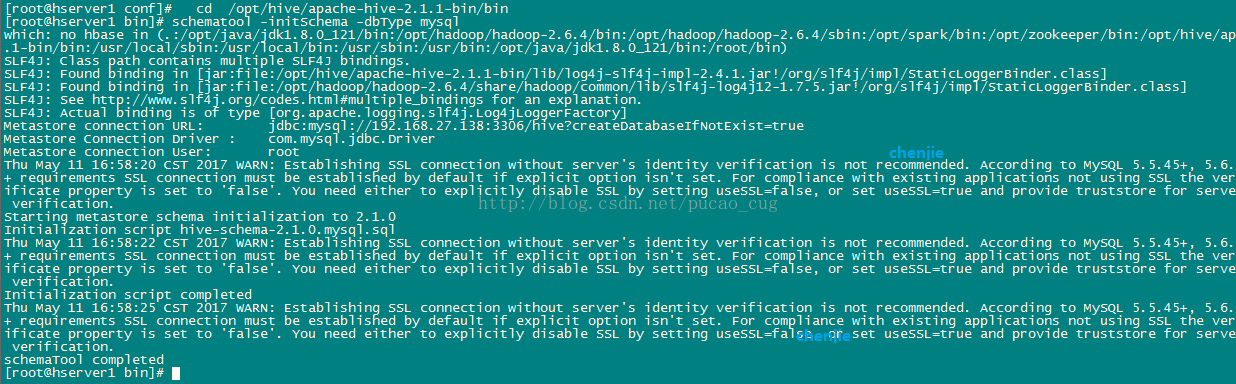
执行成功后,hive数据库里已经有一堆表创建好了
如图:
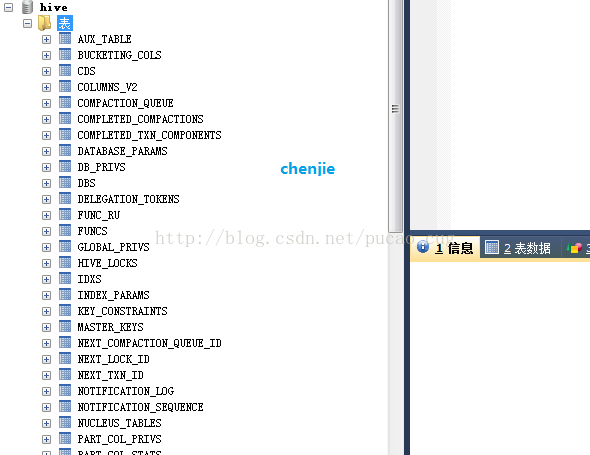
3.1启动hive
进入到hive的bin目录执行命令:
cd /opt/hive/apache-hive-2.1.1-bin/bin
执行hive脚本进行启动,执行命令:
./hive
如图:
3.3测试
3.3.1 执行简单测试命令
执行了3.2的hive脚本,启动成功后,就进入了hive的命令行模式。下面进行一系列简单测试:
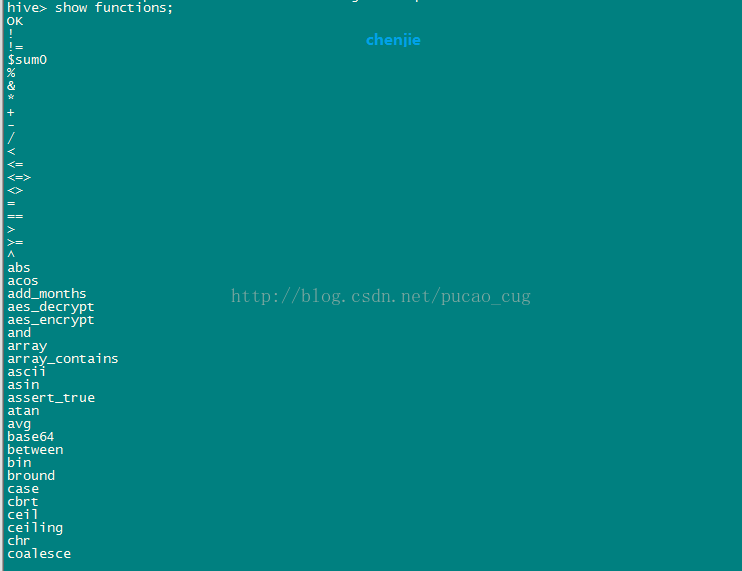
执行查看函数的命令:
show functions;
如图:
执行查看sum函数的详细信息的命令:
desc function sum;
如图:

3.3.2执行新建表以及导入数据的测试
3.3.2.1新建数据库
执行新建数据库的hive命令:
create database db_hive_edu;
如图:

3.2.2.2 创建数据表
在刚才创建的数据库中创建数据表,执行hive命令:
use db_hive_edu;
create table student(id int,name string) row format delimited fields terminated by '\t';
如图:

3.2.2.3将文件数据写入表中
(1)在/opt/hive目录内新建一个文件
执行Linux命令(最好是重新打开一个终端来执行):
touch /opt/hive/student.txt
如图:

往文件中添加以下内容:
001 zhangsan002 lisi
003 wangwu
004 zhaoliu
005 chenqi
如图:
说明:ID和name直接是TAB键,不是空格,因为在上面创建表的语句中用了terminated by '\t'所以这个文本里id和name的分割必须是用TAB键(复制粘贴如果有问题,手动敲TAB键吧),还有就是行与行之间不能有空行,否则下面执行load,会把NULL存入表内,该文件要使用unix格式,如果是在windows上用txt文本编辑器编辑后在上载到服务器上,需要用工具将windows格式转为unix格式,例如可以使用Notepad++来转换。
完成上面的步骤后,在磁盘上/opt/hive/student.txt文件已经创建成功,文件中也已经有了内容,在hive命令行中执行加载数据的hive命令:
load data local inpath '/opt/hive/student.txt' into table db_hive_edu.student;
如图:

3.2.2.4查看是否写入成功
执行命令,查看是否把刚才文件中的数据写入成功,hive命令是:
select * from student;
如图:
说明:因为什么的操作使用use db_hive_edu;指定了数据库,所以这里直接用表名student,如果没有指定数据库,请把这个语句换成
select * from db_hive_edu.student;
3.2.2.5在界面上查看刚才写入hdfs的数据
我的hadoop的namenode的IP地址是192.168.27.134,所以我要在浏览器里访问如下地址:
http://192.168.27.134:50070/explorer.html#/user/hive/warehouse/db_hive_edu.db
如图:
点击上图的student,相当于是直接访问该地址:
http://192.168.27.134:50070/explorer.html#/user/hive/warehouse/db_hive_edu.db/student
如图:
点击student.txt,会弹出一个框
如图:
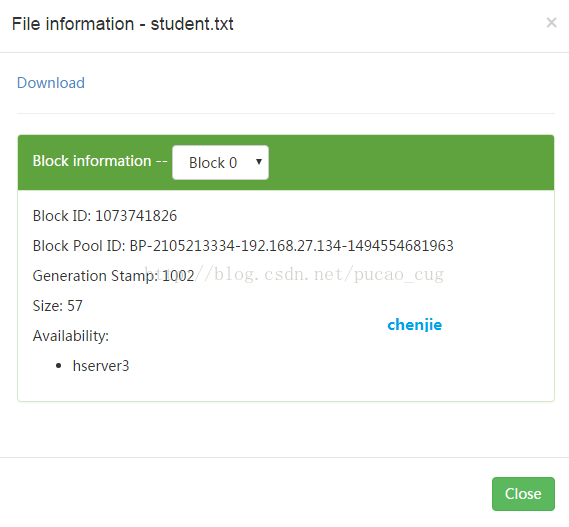
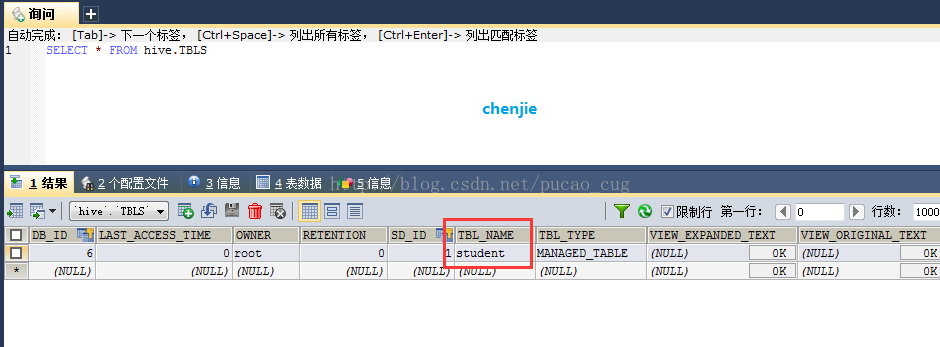
3.2.2.6在MySQL的hive数据库中查看
在MySQL数据库中执行select语句,查看hive创建的表,SQL是:
SELECT * FROM hive.TBLS
如图:
4错误和解决
4.1警告Unable to load native-hadoop library for yourplatform
实际上其实这个警告可以不予理会。
4.2报错There are 2 datanode(s) running and 2 node(s) areexcluded in this operation.
报错详情:
hive> load data local inpath '/opt/hive/student.txt' intotable db_hive_edu.student;
Loading data to table db_hive_edu.student
Failed with exceptionorg.apache.hadoop.ipc.RemoteException(java.io.IOException): File/user/hive/warehouse/db_hive_edu.db/student/student_copy_2.txt could only bereplicated to 0 nodes instead of minReplication (=1). There are 2 datanode(s) running and 2 node(s)are excluded in this operation.
atorg.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget4NewBlock(BlockManager.java:1559)
atorg.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:3245)
atorg.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:663)
atorg.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.addBlock(ClientNamenodeProtocolServerSideTranslatorPB.java:482)
atorg.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
atorg.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:619)
atorg.apache.hadoop.ipc.RPC$Server.call(RPC.java:975)
atorg.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2040)
atorg.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2036)
atjava.security.AccessController.doPrivileged(Native Method)
atjavax.security.auth.Subject.doAs(Subject.java:422)
atorg.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1656)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2034)
FAILED: Execution Error, return code 1 fromorg.apache.hadoop.hive.ql.exec.MoveTask.org.apache.hadoop.ipc.RemoteException(java.io.IOException): File/user/hive/warehouse/db_hive_edu.db/student/student_copy_2.txt could only bereplicated to 0 nodes instead of minReplication (=1). There are 2 datanode(s) running and 2 node(s)are excluded in this operation.
atorg.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget4NewBlock(BlockManager.java:1559)
atorg.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:3245)
atorg.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:663)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.addBlock(ClientNamenodeProtocolServerSideTranslatorPB.java:482)
atorg.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
atorg.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:619)
atorg.apache.hadoop.ipc.RPC$Server.call(RPC.java:975)
atorg.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2040)
atorg.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2036)
atjava.security.AccessController.doPrivileged(Native Method)
atjavax.security.auth.Subject.doAs(Subject.java:422)
atorg.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1656)
atorg.apache.hadoop.ipc.Server$Handler.run(Server.java:2034)
原因和解决:
原因是你的hadoop中的datanode有问题,没发写入数据,请检查你的hadoop是否正常运行,看是否能正常访问http://nodename的IP地址:50070
例如我的是http://192.168.27.134:50070
如果能正常访问,在看datanode状态是否正常,访问地址是:
http://192.168.27.134:50070/dfshealth.html#tab-datanode
如图:
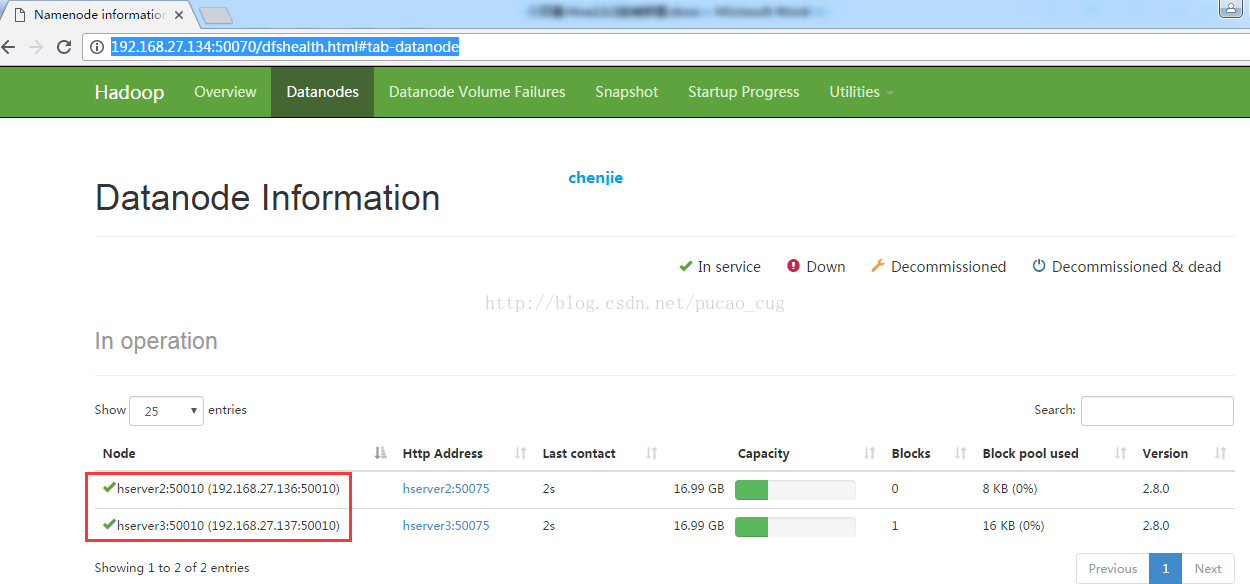
如果不正常,请回头检查自己hadoop的安装配置是否正确,hive的安装和配置是否正确。
2.3.1.5修改hive-site.xml数据库相关的配置
4.1报错Unable toload native-hadoop library for your platform
4.2报错There are2 datanode(s) running and 2 node(s) are excluded in this operation
关键字:Linux Java CentOS Hadoop Hive
说明:安装hive前提是要先安装hadoop集群,并且hive只需要再hadoop的namenode节点集群里安装即可(需要再所有namenode上安装),可以不在datanode节点的机器上安装。另外还需要说明的是,虽然修改配置文件并不需要你已经把hadoop跑起来,但是本文中用到了hadoop命令,在执行这些命令前你必须确保hadoop是在正常跑着的,而且启动hive的前提也是需要hadoop在正常跑着,所以建议你先将hadoop跑起来在按照本文操作。
如何安装和启动hadoop集群,请参考:
http://blog.csdn.net/pucao_cug/article/details/71698903
1下载hive
下载地址:http://hive.apache.org/downloads.html
点击上图的Download release now!
如图:
点击上图的某个下载地址,我点击的是国内的这个地址:http://mirror.bit.edu.cn/apache/hive/
如图:
点击进入:
apache-hive-2.1.1-bin.tar.gz
2安装
2.1上载和解压缩
在opt目录下新建一个名为hive的目录,将apache-hive-2.1.1-bin.tar.gz拷贝上去
执行进入目录的命令:
cd /opt/hive
执行解压缩的命令:
tar -zxvf apache-hive-2.1.1-bin.tar.gz
2.2配置环境变量
编辑/etc/profile文件,增加hive相关的环境变量配置
如图:
该文件中手工增加的内容是(橘黄色字体部分):
export JAVA_HOME=/opt/java/jdk1.8.0_121
export HADOOP_HOME=/opt/hadoop/hadoop-2.8.0
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib"
export HIVE_HOME=/opt/hive/apache-hive-2.1.1-bin
export HIVE_CONF_DIR=${HIVE_HOME}/conf
export CLASS_PATH=.:${JAVA_HOME}/lib:${HIVE_HOME}/lib:$CLASS_PATH
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${HIVE_HOME}/bin:$PATH
profile文件编辑完成后,执行下面命令,让配置生效,命令是;
source /etc/profile
说明:上面的环境变量中只有JAVA_HOME相关的、HADOOP相关的、HIVE相关的是必须的, 相关的路径必须要和你机器对应。
2.3对hive进行配置
2.3.1 hive-site.xml相关的配置
2.3.1.1新建hive-site.xml文件
进入到/opt/hive/apache-hive-2.1.1-bin/conf目录,命令是:
cd /opt/hive/apache-hive-2.1.1-bin/conf
将hive-default.xml.template文件复制一份,并且改名为hive-site.xml,命令是:
cp hive-default.xml.template hive-site.xml
2.3.1.2使用hadoop新建hdfs目录
因为在hive-site.xml中有这样的配置:
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<name>hive.exec.scratchdir</name>
<value>/tmp/hive</value>
所以要让hadoop新建/user/hive/warehouse目录,执行命令:
$HADOOP_HOME/bin/hadoop fs -mkdir -p /user/hive/warehouse
给刚才新建的目录赋予读写权限,执行命令:
$HADOOP_HOME/bin/hadoop fs -chmod 777 /user/hive/warehouse
如图:
让hadoop新建/tmp/hive/目录,执行命令:
$HADOOP_HOME/bin/hadoop fs -mkdir -p /tmp/hive/
如图:
给刚才新建的目录赋予读写权限,执行命令:
$HADOOP_HOME/bin/hadoop fs -chmod 777 /tmp/hive
如图:
2.3.1.3检查hdfs目录是否创建成功
检查/user/hive/warehouse目录是否创建成功,执行命令:
$HADOOP_HOME/bin/hadoop fs -ls /user/hive/
如图:
检查/tmp/hive是否创建成功,执行命令:
$HADOOP_HOME/bin/hadoop fs -ls /tmp/
如图:
2.3.1.4修改hive-site.xml中的临时目录
将hive-site.xml文件中的${system:java.io.tmpdir}替换为hive的临时目录,例如我替换为/opt/hive/tmp,该目录如果不存在则要自己手工创建,并且赋予读写权限。
如图:
被我替换为了
如图:
将${system:user.name}都替换为root
如图:
被替换为了
如图:
说明:截图并不完整,只是截取了几处以作举例,你在替换时候要认真仔细的全部替换掉。
2.3.1.5修改hive-site.xml数据库相关的配置
搜索javax.jdo.option.ConnectionURL,将该name对应的value修改为MySQL的地址,例如我修改后是:
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.27.138:3306/hive?createDatabaseIfNotExist=true</value>
搜索javax.jdo.option.ConnectionDriverName,将该name对应的value修改为MySQL驱动类路径,例如我的修改后是:
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
搜索javax.jdo.option.ConnectionUserName,将对应的value修改为MySQL数据库登录名:
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
搜索javax.jdo.option.ConnectionPassword,将对应的value修改为MySQL数据库的登录密码:
<name>javax.jdo.option.ConnectionPassword</name>
<value>cj</value>
搜索hive.metastore.schema.verification,将对应的value修改为false:
<name>hive.metastore.schema.verification</name>
<value>false</value>
2.3.1.6将MySQL驱动包上载到lib目录
将MySQL驱动包上载到Hive的lib目录下,例如我是上载到/opt/hive/apache-hive-2.1.1-bin/lib目录下。
如图:
2.3.2新建hive-env.sh文件并进行修改
进入到/opt/hive/apache-hive-2.1.1-bin/conf目录,命令是:
cd /opt/hive/apache-hive-2.1.1-bin/conf
将hive-env.sh.template文件复制一份,并且改名为hive-env.sh,命令是:
cp hive-env.sh.template hive-env.sh
打开hive-env.sh配置并且添加以下内容:
export HADOOP_HOME=/opt/hadoop/hadoop-2.8.0
export HIVE_CONF_DIR=/opt/hive/apache-hive-2.1.1-bin/conf
export HIVE_AUX_JARS_PATH=/opt/hive/apache-hive-2.1.1-bin/lib
3启动和测试
3.1对MySQL数据库进行初始化
进入到hive的bin目录 执行命令:
cd /opt/hive/apache-hive-2.1.1-bin/bin
对数据库进行初始化,执行命令:
schematool -initSchema -dbType mysql
如图:
执行成功后,hive数据库里已经有一堆表创建好了
如图:
3.1启动hive
进入到hive的bin目录执行命令:
cd /opt/hive/apache-hive-2.1.1-bin/bin
执行hive脚本进行启动,执行命令:
./hive
如图:
3.3测试
3.3.1 执行简单测试命令
执行了3.2的hive脚本,启动成功后,就进入了hive的命令行模式。下面进行一系列简单测试:
执行查看函数的命令:
show functions;
如图:
执行查看sum函数的详细信息的命令:
desc function sum;
如图:
3.3.2执行新建表以及导入数据的测试
3.3.2.1新建数据库
执行新建数据库的hive命令:
create database db_hive_edu;
如图:
3.2.2.2 创建数据表
在刚才创建的数据库中创建数据表,执行hive命令:
use db_hive_edu;
create table student(id int,name string) row format delimited fields terminated by '\t';
如图:
3.2.2.3将文件数据写入表中
(1)在/opt/hive目录内新建一个文件
执行Linux命令(最好是重新打开一个终端来执行):
touch /opt/hive/student.txt
如图:
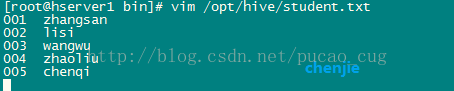
往文件中添加以下内容:
001 zhangsan002 lisi
003 wangwu
004 zhaoliu
005 chenqi
如图:
说明:ID和name直接是TAB键,不是空格,因为在上面创建表的语句中用了terminated by '\t'所以这个文本里id和name的分割必须是用TAB键(复制粘贴如果有问题,手动敲TAB键吧),还有就是行与行之间不能有空行,否则下面执行load,会把NULL存入表内,该文件要使用unix格式,如果是在windows上用txt文本编辑器编辑后在上载到服务器上,需要用工具将windows格式转为unix格式,例如可以使用Notepad++来转换。
完成上面的步骤后,在磁盘上/opt/hive/student.txt文件已经创建成功,文件中也已经有了内容,在hive命令行中执行加载数据的hive命令:
load data local inpath '/opt/hive/student.txt' into table db_hive_edu.student;
如图:
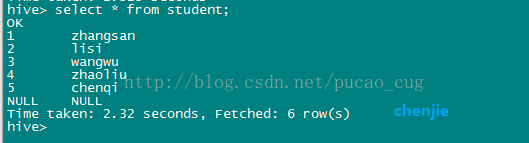
3.2.2.4查看是否写入成功
执行命令,查看是否把刚才文件中的数据写入成功,hive命令是:
select * from student;
如图:
说明:因为什么的操作使用use db_hive_edu;指定了数据库,所以这里直接用表名student,如果没有指定数据库,请把这个语句换成
select * from db_hive_edu.student;
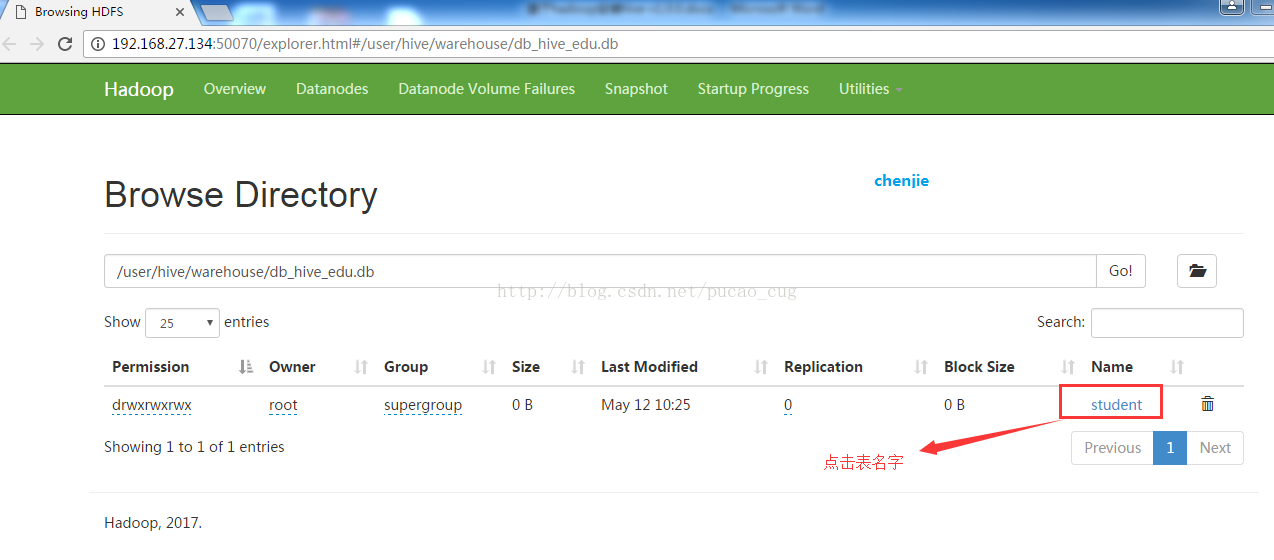
3.2.2.5在界面上查看刚才写入hdfs的数据
我的hadoop的namenode的IP地址是192.168.27.134,所以我要在浏览器里访问如下地址:
http://192.168.27.134:50070/explorer.html#/user/hive/warehouse/db_hive_edu.db
如图:
点击上图的student,相当于是直接访问该地址:
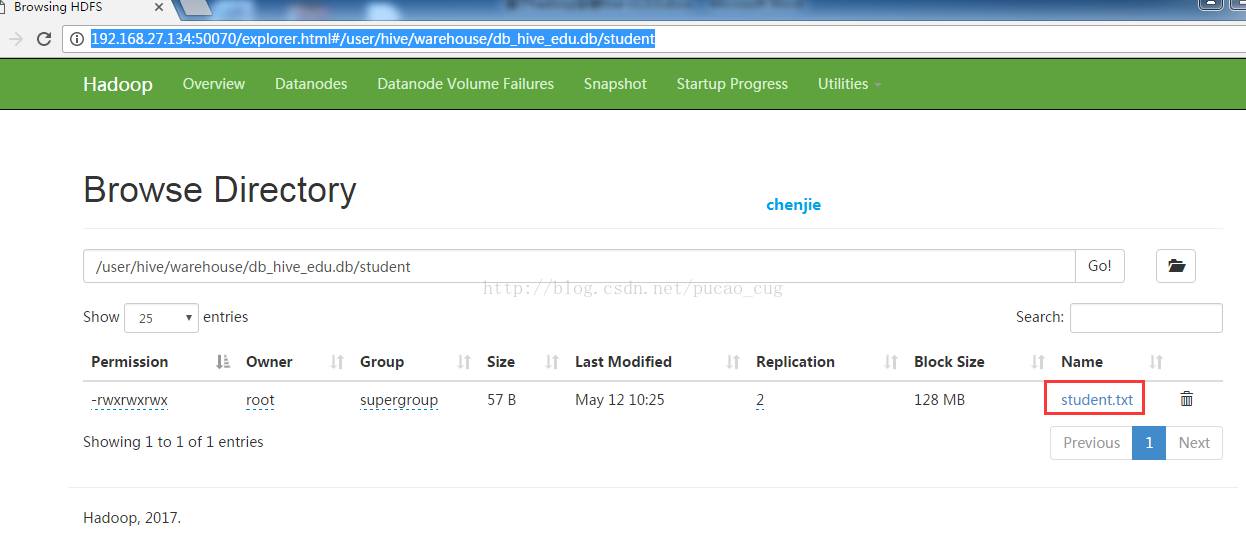
http://192.168.27.134:50070/explorer.html#/user/hive/warehouse/db_hive_edu.db/student
如图:
点击student.txt,会弹出一个框
如图:
3.2.2.6在MySQL的hive数据库中查看
在MySQL数据库中执行select语句,查看hive创建的表,SQL是:
SELECT * FROM hive.TBLS
如图:
4错误和解决
4.1警告Unable to load native-hadoop library for yourplatform
实际上其实这个警告可以不予理会。
4.2报错There are 2 datanode(s) running and 2 node(s) areexcluded in this operation.
报错详情:
hive> load data local inpath '/opt/hive/student.txt' intotable db_hive_edu.student;
Loading data to table db_hive_edu.student
Failed with exceptionorg.apache.hadoop.ipc.RemoteException(java.io.IOException): File/user/hive/warehouse/db_hive_edu.db/student/student_copy_2.txt could only bereplicated to 0 nodes instead of minReplication (=1). There are 2 datanode(s) running and 2 node(s)are excluded in this operation.
atorg.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget4NewBlock(BlockManager.java:1559)
atorg.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:3245)
atorg.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:663)
atorg.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.addBlock(ClientNamenodeProtocolServerSideTranslatorPB.java:482)
atorg.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
atorg.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:619)
atorg.apache.hadoop.ipc.RPC$Server.call(RPC.java:975)
atorg.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2040)
atorg.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2036)
atjava.security.AccessController.doPrivileged(Native Method)
atjavax.security.auth.Subject.doAs(Subject.java:422)
atorg.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1656)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2034)
FAILED: Execution Error, return code 1 fromorg.apache.hadoop.hive.ql.exec.MoveTask.org.apache.hadoop.ipc.RemoteException(java.io.IOException): File/user/hive/warehouse/db_hive_edu.db/student/student_copy_2.txt could only bereplicated to 0 nodes instead of minReplication (=1). There are 2 datanode(s) running and 2 node(s)are excluded in this operation.
atorg.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget4NewBlock(BlockManager.java:1559)
atorg.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:3245)
atorg.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.addBlock(NameNodeRpcServer.java:663)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.addBlock(ClientNamenodeProtocolServerSideTranslatorPB.java:482)
atorg.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
atorg.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:619)
atorg.apache.hadoop.ipc.RPC$Server.call(RPC.java:975)
atorg.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2040)
atorg.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2036)
atjava.security.AccessController.doPrivileged(Native Method)
atjavax.security.auth.Subject.doAs(Subject.java:422)
atorg.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1656)
atorg.apache.hadoop.ipc.Server$Handler.run(Server.java:2034)
原因和解决:
原因是你的hadoop中的datanode有问题,没发写入数据,请检查你的hadoop是否正常运行,看是否能正常访问http://nodename的IP地址:50070
例如我的是http://192.168.27.134:50070
如果能正常访问,在看datanode状态是否正常,访问地址是:
http://192.168.27.134:50070/dfshealth.html#tab-datanode
如图:
如果不正常,请回头检查自己hadoop的安装配置是否正确,hive的安装和配置是否正确。

















 514
514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









