







Druid 是一个为在大数据集之上做实时统计分析而设计的开源数据存储。这个系统集合了一个面向列存储的层,一个分布式、shared-nothing的架构,和一个索引结构,来达成在秒级以内对十亿行级别的表进行任意的探索分析。
由于Druid保存的是时间序列数据,按列的类型,上述数据可以分为以下三类:
首先根据时间段定位到segment,然后根据Appkey=’appkey2’ and area=’北京’查到各自的bitmap:
2)group by 查询:
该查询与上面的查询不同之处在于将符合条件的列
取出来,然后在内存中做分组聚合。结果为:北京:26, 上海:13.
由于Druid保存的是时间序列数据,按列的类型,上述数据可以分为以下三类:
- 时间序列(timestamp):Druid中所有的查询以及索引过程都和时间维度息息相关。Druid底层使用绝对毫秒数保存时间戳,默认使用ISO-8601格式展示时间。(如:yyyy-MM-ddThh:mm:sss.SSSZ,其中“Z”代表零时区,中国所在的东八区可表示为+08:00)
- 维度列(dimensions):Druid中的维度与Olap中的维度一致,一条记录中的字符类型(String)数据可以看作是维度列,维度列被用于过滤筛选,分组数据。
- 度量列(Metrics):Druid中的Metric也与Olap中的Metric一致。度量列被用于聚合和计算操作。
我们用下面一组数据来演示整个的索引和查询原理:
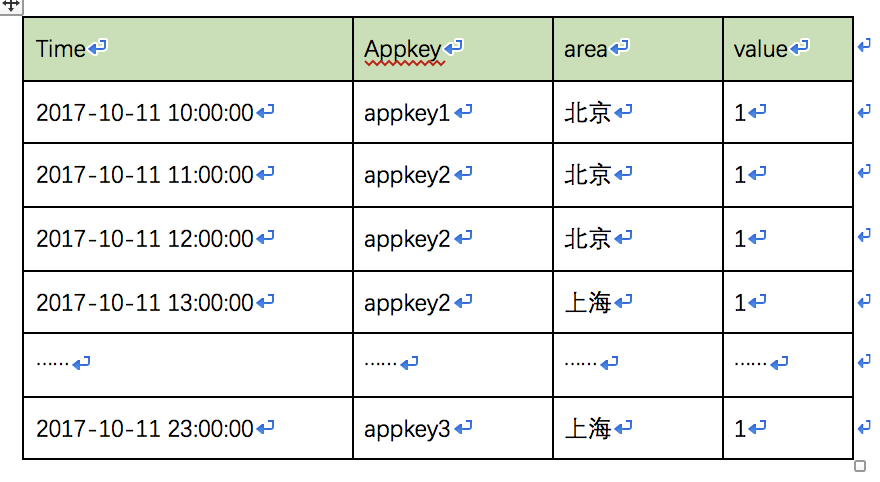
这也是Druid要求的格式,第一列为时间。Appkey和area都是维度列。value为metric列。
Druid会在导入阶段对数据进行Rollup,将维度相同组合的数据进行聚合处理。Rollup会使用其设定的聚合器进行聚合。
按天聚合后的数据如下(聚合后的DataSource为AD_areauser):
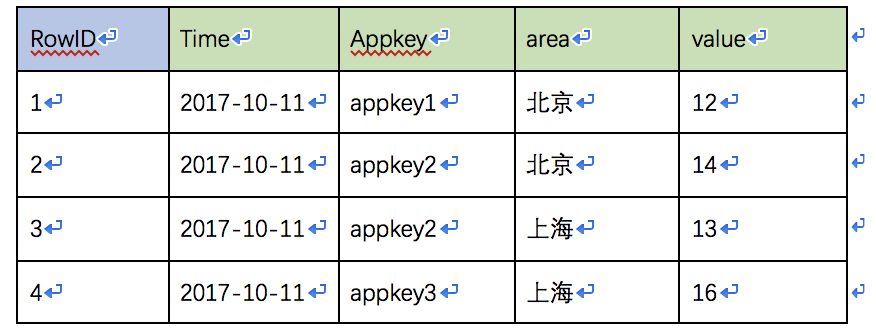
对于聚合后的数据,如何对表建立索引,快速的进行查找?
我们知道数据库常用的索引是利用B+树建立联合索引,但是在以上数据中,比如按area进行查找,由于该列的基数非常低,这样无论该表有多少行,B+数的叶子结点都比较少,所以查找索引的效率很低,并不一定比得上全表扫描。
那么如何通过建立索引来解决这类问题呢?答案是建立位图索引。
索引如下所示:
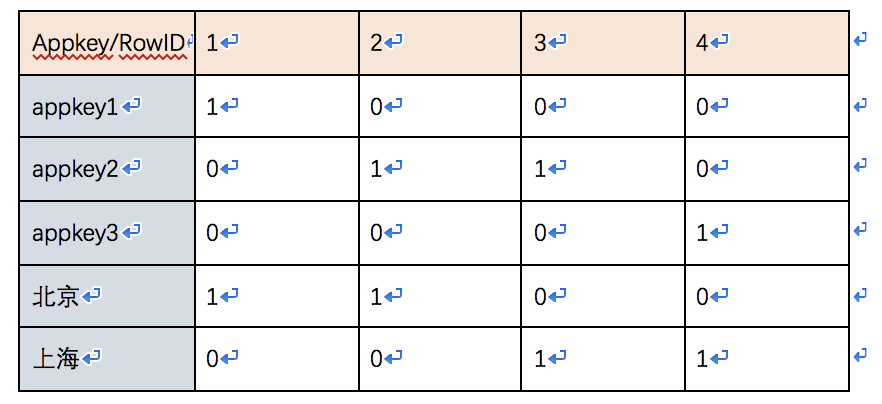
其实索引位图可以看作是HashMap<String, Bitmap>。该map中的key就是维度的取值,value就是该表中对应的行是否有该维度的值。
以SQL查询为例:
1)boolean条件查询:
Select sum(value) from AD_areauser where time=’2017-10-11’and Appkey in (‘appkey1’,’appkey2’) and area=’北京’
首先根据时间段定位到segment,然后根据Appkey=’appkey2’ and area=’北京’查到各自的bitmap:
(appkey1(1000) or appkey2(0110)) and 北京(1100) = (1100)也就是说,符合条件的列是第一行和第二行,这两行的metric(value)的和为26.
2)group by 查询:
select area, sum(value) from AD_areauser where time=’2017-10-11’and Appkey in (‘appkey1’,’appkey2’) group by area
该查询与上面的查询不同之处在于将符合条件的列
appkey1(1000) or appkey2(0110) = (1110)
取出来,然后在内存中做分组聚合。结果为:北京:26, 上海:13.














 428
428











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









