









 本文详细介绍了如何在本地和Azure上部署机器学习模型,使用Azure Arc支持的托管在线端点。首先,确保满足先决条件,包括Azure订阅、AzureCLI、参与者权限的资源组和AML工作区。接着,创建模型、评分文件和部署环境。然后,本地部署模型并在Azure上创建端点和部署。最后,通过调用端点进行推理,展示了模型的预测能力。整个过程强调了Azure Arc在跨不同环境无缝部署模型的优势。
本文详细介绍了如何在本地和Azure上部署机器学习模型,使用Azure Arc支持的托管在线端点。首先,确保满足先决条件,包括Azure订阅、AzureCLI、参与者权限的资源组和AML工作区。接着,创建模型、评分文件和部署环境。然后,本地部署模型并在Azure上创建端点和部署。最后,通过调用端点进行推理,展示了模型的预测能力。整个过程强调了Azure Arc在跨不同环境无缝部署模型的优势。
目录
在本系列的上一篇文章中,我们学习了如何在支持Arc的Kubernetes集群上训练机器学习(ML)模型。模型完成训练后,理想情况下,我们应该能够在对我们的用例最有意义的地方部署和运行它。
我们可能会在本地运行它,但也可能在Azure上运行它。使用支持Arc的ML的显着优势之一是它不会强迫我们选择其中一个。相反,它允许我们在任何地方运行我们的模型并启用推理,无论是在边缘、本地还是在Azure中。
在本文中,我们将演示在本地部署模型,然后在Azure中部署。您可以在GitHub上查看完整的项目代码。
使用托管在线端点部署ML模型
在线端点使我们能够以可扩展和托管的方式部署和运行我们的ML模型。它们与Azure中支持CPU和GPU的强大机器一起工作,使我们能够服务、扩展、保护和监控我们的模型,而无需设置和管理底层基础架构的开销。端点快速处理小请求并提供近乎实时的响应。
先决条件
要使用托管在线端点部署我们的模型,我们必须确保我们拥有:
- 有效的Azure订阅。使用200美元的信用额度可免费注册和访问一年的流行服务。
- 安装并配置Azure CLI
- 通过执行以下命令将ML扩展安装到Azure CLI:$ az extension add -n ml -y
- 具有参与者访问权限的Azure资源组
- Azure机器学习(AML)工作区
- Docker安装在我们的本地系统上,因为我们需要它来进行本地部署
- 设置Azure CLI的默认设置
我们使用以下命令设置Azure CLI的默认设置,以避免传入订阅工作区和资源组的值:
$ az account set --subscription <subscription ID>
$ az configure --defaults workspace=<Azure Machine Learning workspace name> group=<resource group>注意:如果您一直在关注文章系列,您应该已经拥有一个资源组和AML工作区。使用先前创建的资源来设置您的系统以进行模型部署。
一旦我们完成了上述步骤,我们的系统就可以部署了。要使用在线端点部署我们的模型,我们需要以下内容:
- 经过训练的模型文件或在我们的工作区中注册的模型的名称和版本
- 为模型评分的评分文件
- 我们的模型运行的部署环境
让我们从在Azure上创建一个模型开始。
在Azure上创建模型
在Azure上创建ML资源的方法有很多。我们可以选择在AML上训练和注册我们的ML模型,或者使用CLI命令注册一些先前训练过的模型。在本系列的上一篇文章中,我们使用Azure训练并注册了模型,但我们可以使用CLI命令。
要在Azure上注册模型,我们需要一个包含模型规范的YAML文件。我们可以使用以下YAML模板文件来创建特定于资源的YAML文件。
$schema: https://azuremlschemas.azureedge.net/latest/model.schema.json
name: {model name}
version: 1
local_path: {path to local model}上面的YAML文件首先指定模型的模式。它还指定Azure模型的属性,例如名称、版本和模型本地位置的路径。我们可以更改属性以匹配特定模型。
获得包含模型规范的YAML文件后,我们执行以下命令在Azure上创建模型。
$az ml model create -f {path to YAML file}在Azure上注册模型后,我们应该能够在AML工作室的Models下看到它。
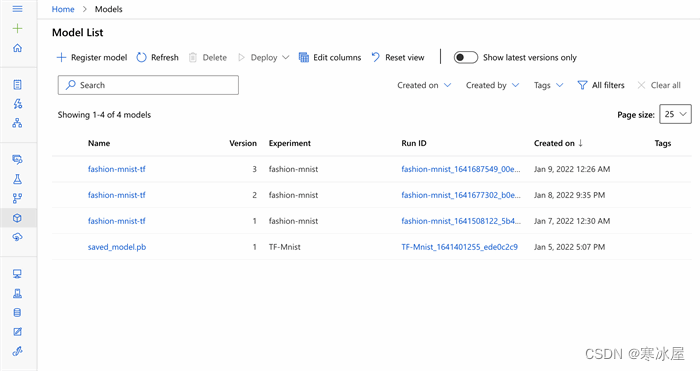
创建评分文件
端点在调用时调用评分文件进行实际评分和预测。该评分文件遵循规定的结构,必须具有init函数和运行函数。端点在每次创建或更新端点时调用该init函数,而端点在调用run函数时调用它。
让我们创建一个评分文件,并通过在本地系统上创建一个score.py文件并输入以下代码来对fashion-mnist-tf模型进行评分,从而更深入地了解这些方法。
import keras as K
import os
import sys
import numpy as np
import json
import tensorflow as tf
import logging
labels_map = {
0: 'T-Shirt',
1: 'Trouser',
2: 'Pullover',
3: 'Dress',
4: 'Coat',
5: 'Sandal',
6: 'Shirt',
7: 'Sneaker',
8: 'Bag',
9: 'Ankle Boot',
}
def predict(model: tf.keras.Model, x: np.ndarray) -> tf.Tensor:
y_prime = model(x, training=False)
probabilities = tf.nn.softmax(y_prime, axis=1)
predicted_indices = tf.math.argmax(input=probabilities, axis=1)
return predicted_indices
def init():
global model
print("Executing init() method...")
if 'AZUREML_MODEL_DIR' in os.environ:
model_path = os.path.join(os.getenv('AZUREML_MODEL_DIR'), './outputs/model/model.h5')
else:
model_path = './outputs/model/model.h5'
model = K.models.load_model(model_path)
print("loaded model...")
def run(raw_data):
print("Executing run(raw_data) method...")
data = np.array(json.loads(raw_data)['data'])
data = np.reshape(data, (1,28,28,1))
predicted_index = predict(model, data).numpy()[0]
predicted_name = labels_map[predicted_index]
logging.info('Predicted name: %s', predicted_name)
logging.info('Run completed')
return predicted_name在上面的代码中,predict函数获取数据并返回概率最高的标签索引。该init函数负责加载模型。AZUREML_MODEL_DIR环境变量为我们提供了模型在Azure中的根文件夹的路径。如果环境变量不可用,它会从本地机器加载模型。
该run函数负责预测。它以raw_data作为一个参数,包含我们在调用端点时传递的数据。该run函数加载JSON数据,对其进行转换,在数据上调用predict函数,返回预测结果,并通过将结果映射到我们定义的标签将它们转换为人类可读的形式。
有了我们的评分文件,让我们创建部署环境。
创建部署环境
AML环境为Azure中的训练和预测作业指定运行时和其他配置。Azure提供各种推理选项,包括预构建的Docker镜像或自定义环境的基础镜像。在这里,我们使用Microsoft提供的基本镜像,并使用Azure上推理所需的所有包手动扩展它。
在我们创建部署环境之前,我们必须使用以下命令设置端点名称:
$ export ENDPOINT_NAME="azure-arc-demo"我们还必须创建一个包含端点规范的YML文件,例如模式和名称。我们创建一个endpoint.yml文件,如下所示:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: azure-arc-demo
auth_mode: key下一步是定义我们的部署环境依赖项。由于我们使用基础镜像,我们必须使用包含所有依赖项的Conda YAML文件来扩展镜像。我们创建一个conda.yml文件并向其中添加以下代码:
name: test
channels:
- conda-forge
dependencies:
- python
- numpy
- pip
- tensorflow
- scikit-learn
- keras
- pip:
- azureml-defaults
- inference-schema[numpy-support]该文件包含推理所需的所有依赖项。请注意,我们还添加了一个azureml-defaults包,我们需要在Azure上进行推理。到位后,我们创建一个deployment.yml文件,如下所示:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: fashion-mnist
type: kubernetes
endpoint_name: azure-arc-demo
app_insights_enabled: true
model:
name: fashion-mnist-tf
version: 1
local_path: "./outputs/model/model.h5"
code_configuration:
code:
local_path: .
scoring_script: score.py
instance_type: defaultinstancetype
environment:
conda_file: ./conda.yml
image: mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04:latest在上面的代码中,我们设置了一些变量,如endpoint_name、model、scoring script和conda_file,确保路径指向我们的文件所在的目录。
一旦我们创建了上述所有文件,就可以部署模型了。
在本地部署模型
在部署模型之前,我们首先通过执行以下命令来创建端点:
$ az ml online-endpoint create --local -n azure-arc-demo -f ./fashion-mnist-deployment/endpoint.yml接下来,我们按如下方式部署模型:
$ az ml online-deployment create --local -n fashion-mnist --endpoint azure-arc-demo -f ./fashion-mnist-deployment/deployment.yml上面的命令在端点fashion-mnist下创建了一个本地部署。azure-arc-demo我们使用以下命令验证部署:
$ az ml online-endpoint show -n azure-arc-demo --local
我们的部署是成功的,我们现在可以调用它进行推理。
调用端点进行推理
一旦部署成功,我们可以通过传递我们的请求来调用端点进行推理。但在此之前,我们必须创建一个包含用于预测的输入数据的文件。我们可以从测试数据集中快速获取图像文件,将其转换为JSON,并将其传递给端点进行预测。我们使用以下代码创建一个示例请求。
import json
import tensorflow as tf
#Fashion MNIST Dataset CNN model development: https://github.com/zalandoresearch/fashion-mnist
from keras.datasets import fashion_mnist
from tensorflow.keras.utils import to_categorical
# load the data
(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()
#no. of classes
num_classes = 10
x_test = x_test.astype('float32')
x_test /= 255
y_test = to_categorical(y_test, num_classes)
with open('mydata.json', 'w') as f:
json.dump({"data": x_test[10].tolist()}, f)上面的代码加载单个图像文件,创建一个包含图像像素值的矩阵,将其与关键数据一起添加到JSON字典中,并将其保存在mydata.json文件中。
现在我们有了示例请求,我们调用端点如下:
$ az ml online-endpoint invoke --local --name azure-arc-demo --request-file ./fashion-mnist-deployment/mydata.json端点以近乎实时的预测响应。

将在线终结点部署到Azure
将我们的端点部署到Azure就像将其部署到本地环境一样简单。在本地部署模型时,我们使用了--local标志,它指示CLI在本地Docker环境中部署端点。只需删除此标志,我们就可以在Azure上部署我们的模型。
我们执行以下命令在云中创建端点:
az ml online-endpoint create --name $ENDPOINT_NAME -f endpoints/online/managed/sample/endpoint.yml
$ az ml online-endpoint create --name azure-arc-demo -f ./fashion-mnist-deployment/endpoint.yml创建端点后,我们可以在AML studio中的Endpoints下看到它。
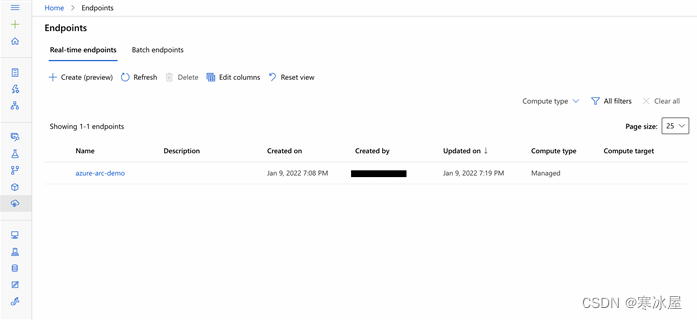
接下来,我们在端点下创建一个名为fashion-mnist的部署。
$ az ml online-deployment create --name fashion-mnist --endpoint azure-arc-demo –f ./fashion-mnist-deployment/deployment.yml --all-traffic部署可能需要一些时间,具体取决于底层环境。部署成功后,我们可以调用模型进行推理,如下所示:
$ az ml online-endpoint invoke --name azure-arc-demo --request-file ./fashion-mnist-deployment/mydata.json上面的命令返回与我们本地部署的模型相同的输出。
概括
在本文中,我们学习了在本地和Azure上部署模型。即使我们在另一个云提供商或边缘有一个启用Arc的Kubernetes集群,模型部署过程也是一样的。支持Arc的机器学习使我们能够无缝地部署和运行我们的模型,而不管硬件和位置如何。
本系列文章是有关启用Arc的机器学习的入门指南。毫无疑问,Kubernetes为优化机器学习过程打开了许多大门。同时,Arc使整个过程顺利进行,让我们可以自由地在我们选择的硬件上训练和运行我们的机器学习模型。
要追求强大、可扩展的机器学习,请注册一个免费的Azure Arc帐户。
若要详细了解如何配置Azure Kubernetes服务(AKS)和启用Azure Arc的 Kubernetes 集群以训练和推理机器学习工作负载,请查看配置Kubernetes集群以进行机器学习。
https://www.codeproject.com/Articles/5323951/Azure-Arc-Machine-Learning-Part-3-Inference-Anywhe


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









