








目录

这是解释如何创建和使用PyTorch二进制分类器的两篇文章中的第二篇。了解本文内容的一个好方法是查看图1 中演示程序的屏幕截图。
演示程序预测一个人的性别(男性、女性)。本系列的第一篇文章介绍了如何准备训练和测试数据,以及如何定义神经网络分类器。本文介绍如何训练网络、计算已训练网络的精度、使用网络进行预测以及保存网络以供其他程序使用。
了解本文内容的一个好方法是查看图1 中演示程序的屏幕截图。该演示首先加载一个包含200项的训练数据文件和一组包含40项的测试数据。每个制表符分隔的行代表一个人。这些字段是性别(男性= 0,女性= 1)、年龄、居住州、年收入和政治类型。目标是从年龄,州,收入和政治类型预测性别。
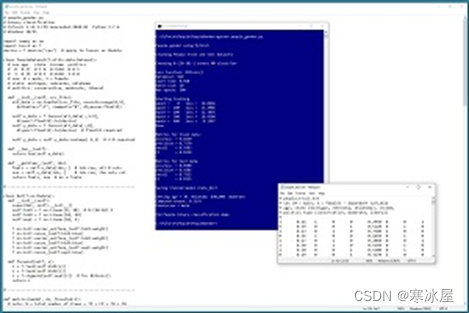
图1:使用PyTorch演示运行的二进制分类
将训练数据加载到内存中后,演示将创建一个8-(10-10)-1神经网络。这意味着有八个输入节点,两个隐藏的神经层,每个10个节点和一个输出节点。
该演示准备通过设置批大小10、随机梯度下降(SGD)优化(学习率为0.01)以及通过训练数据的最大训练周期500来训练网络。稍后将解释这些值的含义以及如何确定它们。
演示程序通过计算和显示损失值来监控训练。损失值缓慢减小,表明训练可能成功。损失值的大小无法直接解释;重要的是损失减少了。
经过500个训练周期后,演示程序将训练模型在训练数据上的准确率计算为82.50%(200个正确点中有165个)。测试数据的模型准确率为85%(40个正确数据中有34个)。对于二元分类模型,除了准确性之外,计算其他指标是标准做法:精度、召回率和F1分数。
评估经过训练的网络后,演示会将训练好的模型保存到文件中,以便无需从头开始重新训练网络即可使用。有两种主要方法可以保存PyTorch模型。该演示使用保存状态方法。
保存模型后,演示预测了一个来自俄克拉荷马州的30岁人的性别,他每年赚40,000美元,是政治温和派。原始预测为0.3193。此值是伪概率,其中小于0.5的值表示类0(男性),大于0.5的值表示类1(女性)。因此,预测是男性。
本文假设你对Python有基本的熟悉,并且对C族语言有中级或更好的经验,但并不假设你对PyTorch或神经网络了解很多。完整的演示程序源代码和数据可以在这里找到。
总体程序结构
演示程序的整体结构如清单1 所示。演示程序名为people_gender.py。该程序导入NumPy(数字Python)库并为其分配np的别名。程序导入PyTorch并为其分配T的别名。大多数PyTorch程序不使用T别名,但我和我的同事经常这样做以节省空间。演示程序使用两个空格而不是更常见的四个空格缩进,再次节省空间。
清单1:总体程序结构
# people_gender.py
# binary classification
# PyTorch 1.12.1-CPU Anaconda3-2020.02 Python 3.7.6
# Windows 10/11
import numpy as np
import torch as T
device = T.device('cpu')
class PeopleDataset(T.utils.data.Dataset): . . .
class Net(T.nn.Module): . . .
def metrics(model, ds, thresh=0.5): . . .
def main():
# 0. get started
print("People gender using PyTorch ")
T.manual_seed(1)
np.random.seed(1)
# 1. create Dataset objects
# 2. create network
# 3. train model
# 4. evaluate model accuracy
# 5. save model (state_dict approach)
# 6. make a prediction
print("End People binary classification demo ")
if __name__ == "__main__":
main()演示程序将所有控制逻辑放在main()函数中。我的一些同事更喜欢实现程序定义的train()函数来处理执行训练的代码。
演示程序首先设置NumPy随机数生成器和PyTorch生成器的种子值。设置种子值很有帮助,因此演示运行大多是可重现的。但是,在使用复杂的神经网络(如Transformer网络)时,由于执行线程不同,因此无法始终保证精确的可重复性。
准备训练网络
训练神经网络是查找权重和偏差值的过程,以便网络生成与训练数据匹配的输出。大多数演示程序代码都与训练网络相关联。术语网络和模型通常可以互换使用。在某些开发环境中,网络用于在训练神经网络之前引用神经网络,而模型用于在训练网络之后引用网络。
规范化和编码的训练数据如下所示:
1 0.24 1 0 0 0.2950 0 0 1
0 0.39 0 0 1 0.5120 0 1 0
1 0.63 0 1 0 0.7580 1 0 0
0 0.36 1 0 0 0.4450 0 1 0
. . .这些字段是性别(0 =男性,1 =女性)、年龄(除以100)、州(密歇根州=100,内布拉克斯加州=010,俄克拉荷马州=001)、收入(除以100,000)和政治倾向(保守派=100,温和派=010,自由派=001)。
在main()函数中,训练和测试数据作为Dataset对象加载到内存中,然后将训练数据集传递给DataLoader对象:
# 1. create Dataset and DataLoader objects
print("Creating People train and test Datasets ")
train_file = ".\\Data\\people_train.txt"
test_file = ".\\Data\\people_test.txt"
train_ds = PeopleDataset(train_file) # 200 rows
test_ds = PeopleDataset(test_file) # 40 rows
bat_size = 10
train_ldr = T.utils.data.DataLoader(train_ds,
batch_size=bat_size, shuffle=True)与必须为每个特定二元分类问题定义的数据集对象不同,DataLoader对象可以按原样使用。批大小10是一个超参数。批量大小设置为1的特殊情况有时称为在线训练。
尽管不是必需的,但通常最好设置一个将训练项总数平均划分的批大小,以便所有批的训练数据具有相同的大小。在演示中,批量大小为10和200个训练项目,每个批次将有20个项目。当批大小不能均匀划分训练项数时,最后一个批将小于所有其他批。类有一个可选的drop_last参数,默认值为False。如果设置为True,则数据加载程序将忽略较小的最后一批。
将随机参数显式设置为True非常重要。默认值为False。当shuffle设置为True时,训练数据将以随机顺序提供,这是您在训练期间所需的顺序。如果随机播放设置为False,则按顺序提供训练数据。这几乎总是导致训练失败,因为网络权重和偏差的更新会振荡,并且没有取得进展。
创建网络
演示程序创建神经网络,如下所示:
# 2. create neural network
print("Creating 8-(10-10)-1 binary NN classifier ")
net = Net().to(device)
net.train()神经网络使用普通的Python语法进行实例化,但附加了.to(device)以明确地将存储放置在“cpu”或“cuda”内存中。回想一下,设备是演示中设置为“cpu”的全局范围值。
网络被设置为训练模式,并带有一些误导性的语句net.train()。PyTorch神经网络可以处于两种模式之一,train()或eval()。网络在训练期间应处于train()模式,在所有其他时间应处于eval()模式。
train()vs. eval()模式经常让刚接触PyTorch的人感到困惑,部分原因是在许多情况下,网络处于什么模式并不重要。简而言之,如果神经网络使用dropout或批量归一化,那么在计算输出值时会得到不同的结果,具体取决于网络是处于train()还是eval()模式。但是,如果网络不使用dropout或批量规范化,则train()和eval()模式的结果相同。
由于演示网络不使用dropout或批量规范化,因此无需在train()和eval()模式之间切换。但是,在我看来,在训练期间始终将网络显式设置为train()模式并在所有其他时间将eval()模式显式设置为是一种很好的做法。默认情况下,网络处于train()模式。
net.train()这个语句相当具有误导性,因为它表明正在进行某种训练。如果我是实现train()方法的人,我会将其命名为set_train_mode()。此外,train()方法通过引用操作,因此语句net.train()修改了net对象。如果你是函数式编程的粉丝,你可以写net = net.train()。
训练网络
训练网络的代码如清单2 所示。训练神经网络涉及两个嵌套循环。外环循环迭代固定数量的周期(可能出现短路退出)。周期是一次完整的训练数据传递。内部循环循环遍历所有训练数据项。
清单2:训练网络
# 3. train network
lrn_rate = 0.01
loss_func = T.nn.BCELoss() # binary cross entropy
optimizer = T.optim.SGD(net.parameters(),
lr=lrn_rate)
max_epochs = 500
ep_log_interval = 100
print("Loss function: " + str(loss_func))
print("Optimizer: " + str(optimizer.__class__.__name__))
print("Learn rate: " + "%0.3f" % lrn_rate)
print("Batch size: " + str(bat_size))
print("Max epochs: " + str(max_epochs))
print("Starting training")
for epoch in range(0, max_epochs):
epoch_loss = 0.0 # for one full epoch
for (batch_idx, batch) in enumerate(train_ldr):
X = batch[0] # [bs,8] inputs
Y = batch[1] # [bs,1] targets
oupt = net(X) # [bs,1] computeds
loss_val = loss_func(oupt, Y) # a tensor
epoch_loss += loss_val.item() # accumulate
optimizer.zero_grad() # reset all gradients
loss_val.backward() # compute new gradients
optimizer.step() # update all weights
if epoch % ep_log_interval == 0:
print("epoch = %4d loss = %8.4f" % \
(epoch, epoch_loss))
print("Done ")准备训练的五个语句是:
lrn_rate = 0.01
loss_func = T.nn.BCELoss() # binary cross entropy
optimizer = T.optim.SGD(net.parameters(),
lr=lrn_rate)
max_epochs = 500
ep_log_interval = 100要训练的周期数是一个超参数,必须通过反复试验来确定。ep_log_interval指定显示进度消息的频率。
损失函数设置为BCELoss(),它假定输出节点应用了sigmoid()激活。损失函数和输出节点激活之间存在很强的耦合性。在神经网络的早期,经常使用MSELoss()(均方误差),但BCELoss()现在更为常见。
该演示使用随机梯度下降优化(SGD),固定学习率为0.01,用于控制每次更新时权重和偏差的变化程度。PyTorch支持13种不同的优化算法。最常见的两种是SGD和Adam(自适应矩估计)。SGD通常适用于简单网络,包括二进制分类器。对于深度神经网络,Adam通常比SGD工作得更好。
PyTorch初学者有时会陷入一个陷阱,试图学习每个优化算法的所有内容。我大多数有经验的同事只使用两三种算法并调整学习率。我的建议是使用SGD和Adam,并且仅在这两种算法失败时才尝试其他算法。
监视训练进度很重要,因为训练失败是常态而不是例外。有几种方法可以监视训练进度。演示程序使用最简单的方法,即累积一个周期的总损失,然后每隔一段时间显示累积的损失值(演示中ep_log_interval = 100)。
内部训练循环是完成所有工作的地方:
for (batch_idx, batch) in enumerate(train_ldr):
X = batch[0] # inputs
Y = batch[1] # correct class/label/politics
optimizer.zero_grad()
oupt = net(X)
loss_val = loss_func(oupt, Y) # a tensor
epoch_loss += loss_val.item() # accumulate
loss_val.backward()
optimizer.step()enumerate()函数返回当前批处理索引(0到19)和一批输入值(年龄、州、收入、政治)以及关联的正确目标值(0或1)。使用enumerate()是可选的,您可以通过编写“for batch in train_ldr”来跳过获取批处理索引。
BCELoss()损失函数返回一个保存单个数值的PyTorch张量。该值是使用 item()方法提取的,因此可以累积为普通的非张量数值。在早期版本的PyTorch中,需要使用item()方法,但较新版本的PyTorch执行隐式类型转换,因此不需要调用item()。在我看来,显式使用item()方法是更好的编码风格。
back()方法计算梯度。每个权重和偏差都有一个相关的梯度。梯度是指示应如何调整相关权重或偏差的数值,以便减少计算输出和目标输出之间的误差/损失。请务必记住在调用back()方法之前调用zero_grad()方法。step()方法使用新计算的梯度来更新网络权重和偏差。
大多数神经二元分类器可以在相对较短的时间内进行训练。在训练需要几个小时或更长时间的情况下,您应该定期保存权重和偏差的值,以便在机器出现故障(断电、网络连接断开等)时,您可以重新加载保存的检查点,避免从头开始。
保存训练检查点不在本文的讨论范围之内。有关保存训练检查点的示例和说明,请参阅此博客文章。
计算模型的准确性、精度、召回率
该演示使用程序定义的metrics()函数来计算模型分类准确性、精度、召回率和F1分数。该函数如清单3 所示。计算分类精度在原理上相对简单。准确度只是正确预测的数量除以所做的预测总数。
在许多情况下,普通分类准确性不是一个好的指标。例如,如果数据集有950个类0的数据项和50个类1的数据项,则预测任何输入的类0的模型的准确度将达到95%。精度和召回率提供了对偏斜数据不那么敏感的备用指标。F1分数是精度和召回率的平均值。
在二元分类中,“真阳性”(TP)是正确预测的1类项目的数量。“误报”(FP)是错误预测的1类项目的数量。“真阴性”(TN)是正确预测的0类项目的数量。“假阴性”(FN)是错误预测的0类项目的数量。
使用这些定义,如果N是数据项的总数,则准确性、精度、召回率和F1分数为:
accuracy = (TP + TN) / N
precision = TP / (TP + FP)
recall = TP / (TP + FN)
F1 = 2 / [(1 / precision) + (1 / recall)]F1分数是精度和召回率的调和平均值,而不是常规平均值/平均值,因为精度和召回率是比率。例如,一个伟大的酒吧赌注询问一辆以每小时30英里的速度从A到B的汽车的平均速度,然后以60英里/小时的速度从B返回A到A。平均速度为2/(1/30 + 1/60)= 2/90/1800 = 40.0英里/小时,而不是(30 + 60)/2 = 45.0英里/小时。
清单3:计算模型分类指标
def metrics(model, ds, thresh=0.5):
tp = 0; tn = 0; fp = 0; fn = 0
for i in range(len(ds)):
inpts = ds[i][0] # Tuple style
target = ds[i][1] # float32 [0.0] or [1.0]
with T.no_grad():
p = model(inpts) # between 0.0 and 1.0
# should really avoid 'target == 1.0'
if target > 0.5 and p >= thresh: # TP
tp += 1
elif target > 0.5 and p < thresh: # FP
fp += 1
elif target < 0.5 and p < thresh: # TN
tn += 1
elif target < 0.5 and p >= thresh: # FN
fn += 1
N = tp + fp + tn + fn
if N != len(ds):
print("FATAL LOGIC ERROR in metrics()")
accuracy = (tp + tn) / (N * 1.0)
precision = (1.0 * tp) / (tp + fp)
recall = (1.0 * tp) / (tp + fn)
f1 = 2.0 / ((1.0 / precision) + (1.0 / recall))
return (accuracy, precision, recall, f1) # as a Tuplemetrics()函数在torch.no_grad()块中计算预测输出,以便不会更新网络梯度。网络的输出是介于0.0和1.0之间的值,正确的目标值是0.0或1.0,因为类型为float32,而不是整数类型。从概念上讲,真阳性的计算公式为:如果目标== 1.0且p >= 0.5。但是,比较两个float32 以获得完全相等是一种不好的做法,因此演示代码为:如果目标> 0.5且p >= 0.5。
metrics()函数不是使用标准的固定0.5值作为确定类0或类1的预测的阈值,而是接受thresh参数。改变阈值的值将更改准确性、精度、召回率和F1分数的结果。如果创建在x轴上具有各种阈值,在y轴上具有真阳性率的图形,则该图形称为ROC(接收器工作特性)曲线。
演示程序在使用以下语句训练后调用metrics()函数:
# 4. evaluate model
net.eval()
metrics_train = metrics(net, train_ds, thresh=0.5)
print("\nMetrics for train data: ")
print("accuracy = %0.4f " % metrics_train[0])
print("precision = %0.4f " % metrics_train[1])
print("recall = %0.4f " % metrics_train[2])
print("F1 = %0.4f " % metrics_train[3])
# similarly for test data请注意,在调用metrics()函数之前,网络已设置为eval()模式。在这个例子中,设置eval()模式不是必需的,但在我看来这样做是很好的风格。
人们很容易过度考虑准确性、精确度、召回率和F1分数。它们都只是模型有效性的衡量标准。只有当其中一个指标与其他指标明显不同时,您才应该关注,例如,精度= 0.93但召回率=0.08。
保存已训练的模型
演示程序使用以下语句保存训练的模型:
# 5. save model
print("Saving trained model state_dict ")
net.eval()
path = ".\\Models\\people_gender_model.pt"
T.save(net.state_dict(), path)该代码假定有一个名为Model的目录。有两种主要方法可以保存PyTorch模型。您可以仅保存定义网络的权重和偏差,也可以保存整个网络定义,包括权重和偏差。该演示使用第一种方法。
模型权重和偏差以及其他一些信息保存在state_dict()字典对象中。torch.save()方法接受字典和指示保存位置的文件名。您可以使用任何您想要的文件扩展名,但.pt和.pth是两个常见的选择。
要使用其他程序中保存的模型,该程序必须包含网络类定义。然后权重和偏差可以像这样加载:
model = Net() # requires class definition
model.eval()
fn = ".\\Models\\people_gender_model.pt"
model.load_state_dict(T.load(fn))
# use model to make prediction(s)保存或加载经过训练的模型时,模型应处于eval()模式而不是train()模式。保存PyTorch模型的另一种方法是使用ONNX(开放神经网络交换)。这允许跨平台使用。
使用模型
训练网络分类器后,演示程序使用该模型对以前未见过的新人进行性别预测:
# 6. make a prediction
print("Setting age = 30 Oklahoma $40,000 moderate ")
inpt = np.array([[0.30, 0,0,1, 0.4000, 0,1,0]],
dtype=np.float32)
inpt = T.tensor(inpt, dtype=T.float32).to(device)
net.eval()
with T.no_grad():
oupt = net(inpt) # a Tensor
pred_prob = oupt.item() # scalar, [0.0, 1.0]
print("Computed output: ", end="")
print("%0.4f" % pred_prob)输入是一个30岁,住在俄克拉荷马州,年收入40,000美元并且是政治温和派的人。由于网络是在规范化和编码数据上进行训练的,因此必须以相同的方式对输入进行规范化和编码。
请注意方括号的双集。PyTorch网络希望输入采用批处理的形式。额外的括号集创建批大小为1的数据项。像这样的细节可能需要很多时间来调试。
由于神经网络在输出节点上具有sigmoid()激活,因此预测的输出采用伪概率的形式。演示程序最后以友好的格式显示预测的性别:
. . .
if pred_prob < 0.5:
print("Prediction = male")
else:
print("Prediction = female")
print("End People binary classification demo ")
if __name__== "__main__":
main()总结
本文介绍的二元分类技术在训练期间使用具有sigmoid()激活和BCELoss()的单个输出节点。可以将二元分类问题视为多类分类的特例。在训练期间,您将使用两个具有log_softmax()激活和NLLLoss()的输出节点。但是,本文中介绍的技术更为常见。
有许多二元分类技术。使用神经网络通常会产生良好的结果,但神经网络通常比其他不太复杂的技术需要更多的训练数据。替代的二元分类技术包括:
- 逻辑回归(仅适用于线性可分数据)
- 朴素贝叶斯(假设预测变量是独立的)
- k最近邻(仅适用于严格的数值预测变量)
- 决策树(往往脆弱且敏感)
- XGBoost(难以定制的复杂决策树)
- SVM支持向量机(难以调优,难以定制,不会自然扩展到多类分类)
https://visualstudiomagazine.com/articles/2022/10/14/binary-classification-using-pytorch-2.aspx
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









