









目录
2. OpenVINO™ .CSharp.API.Extensions.PaddleOCR NuGet Package
❝PP-OCR是PaddleOCR自研的实用的超轻量OCR系统,可以实现端到端的图像文本检测。为了在C#平台实现使用OpenVINO™部署PP-OCR模型实现文本识别,让更多开发者快速上手PP-OCR项目,基于此,封装了OpenVINO.CSharp.API.Extensions.PaddleOCR NuGet Package,方便开发者快速安装使用。在本文中,我们将结合OpenVINO.CSharp.API.Extensions.PaddleOCR NuGet Package向大家展示该程序集的使用方式:
OpenVINO™ C# API项目链接:
https://github.com/guojin-yan/OpenVINO-CSharp-API.git
OpenVINO.CSharp.API.Extensions.PaddleOCR NuGet Package:
https://www.nuget.org/packages/OpenVINO.CSharp.API.Extensions/
使用 OpenVINO™ C# API 部署 PaddleOCR 全部源码:
https://github.com/guojin-yan/PaddleOCR-OpenVINO-CSharp.git
1. 前言
1.1 OpenVINO™ C# API
英特尔发行版 OpenVINO™ 工具套件基于 oneAPI 而开发,可以加快高性能计算机视觉和深度学习视觉应用开发速度工具套件,适用于从边缘到云的各种英特尔平台上,帮助用户更快地将更准确的真实世界结果部署到生产系统中。通过简化的开发工作流程,OpenVINO™ 可赋能开发者在现实世界中部署高性能应用程序和算法。

2024年4月25日,英特尔发布了开源 OpenVINO™ 2024.1 工具包,用于在各种硬件上优化和部署人工智能推理。更新了更多的 Gen AI 覆盖范围和框架集成,以最大限度地减少代码更改。同时提供了更广泛的 LLM 模型支持和更多的模型压缩技术。通过压缩嵌入的额外优化减少了 LLM 编译时间,改进了采用英特尔®高级矩阵扩展 (Intel® AMX) 的第 4 代和第 5 代英特尔®至强®处理器上 LLM 的第 1 令牌性能。通过对英特尔®锐炫™ GPU 的 oneDNN、INT4 和 INT8 支持,实现更好的 LLM 压缩和改进的性能。最后实现了更高的可移植性和性能,可在边缘、云端或本地运行 AI。
OpenVINO™ C# API 是一个 OpenVINO™ 的 .Net wrapper,应用最新的 OpenVINO™ 库开发,通过 OpenVINO™ C API 实现 .Net 对 OpenVINO™ Runtime 调用,使用习惯与 OpenVINO™ C++ API 一致。OpenVINO™ C# API 由于是基于 OpenVINO™ 开发,所支持的平台与 OpenVINO™ 完全一致,具体信息可以参考 OpenVINO™。通过使用 OpenVINO™ C# API,可以在 .NET、.NET Framework等框架下使用 C# 语言实现深度学习模型在指定平台推理加速。
1.2 Paddle OCR
PP-OCR是PaddleOCR自研的实用的超轻量OCR系统。在实现前沿算法的基础上,考虑精度与速度的平衡,进行模型瘦身和深度优化,使其尽可能满足产业落地需求。PP-OCR是一个两阶段的OCR系统,其中文本检测算法选用DB,文本识别算法选用CRNN,并在检测和识别模块之间添加文本方向分类器,以应对不同方向的文本识别。
PP-OCR系统在持续迭代优化,目前已发布PP-OCR、PP-OCRv2、PP-OCRv3和PP-OCRv4两个版本:
-
PP-OCR从骨干网络选择和调整、预测头部的设计、数据增强、学习率变换策略、正则化参数选择、预训练模型使用以及模型自动裁剪量化8个方面,采用19个有效策略,对各个模块的模型进行效果调优和瘦身(如绿框所示),最终得到整体大小为3.5M的超轻量中英文OCR和2.8M的英文数字OCR。
-
PP-OCRv2在PP-OCR的基础上,进一步在5个方面重点优化,检测模型采用CML协同互学习知识蒸馏策略和CopyPaste数据增广策略;识别模型采用LCNet轻量级骨干网络、UDML 改进知识蒸馏策略和Enhanced CTC loss损失函数改进,进一步在推理速度和预测效果上取得明显提升。
-
PP-OCRv3在PP-OCRv2的基础上,针对检测模型和识别模型,进行了升级:
-
PP-OCRv3检测模型对PP-OCRv2中的CML协同互学习文本检测蒸馏策略进行了升级,分别针对教师模型和学生模型进行进一步效果优化。其中,在对教师模型优化时,提出了大感受野的PAN结构LK-PAN和引入了DML蒸馏策略;在对学生模型优化时,提出了残差注意力机制的FPN结构RSE-FPN。
-
PP-OCRv3的识别模块是基于文本识别算法SVTR优化。SVTR不再采用RNN结构,通过引入Transformers结构更加有效地挖掘文本行图像的上下文信息,从而提升文本识别能力。PP-OCRv3通过轻量级文本识别网络SVTR_LCNet、Attention损失指导CTC损失训练策略、挖掘文字上下文信息的数据增广策略TextConAug、TextRotNet自监督预训练模型、UDML联合互学习策略、UIM无标注数据挖掘方案,6个方面进行模型加速和效果提升。
-
-
PP-OCRv4在PP-OCRv3的基础上进一步升级。整体的框架图保持了与PP-OCRv3相同的pipeline,针对检测模型和识别模型进行了数据、网络结构、训练策略等多个模块的优化。PP-OCRv4系统框图如下所示:
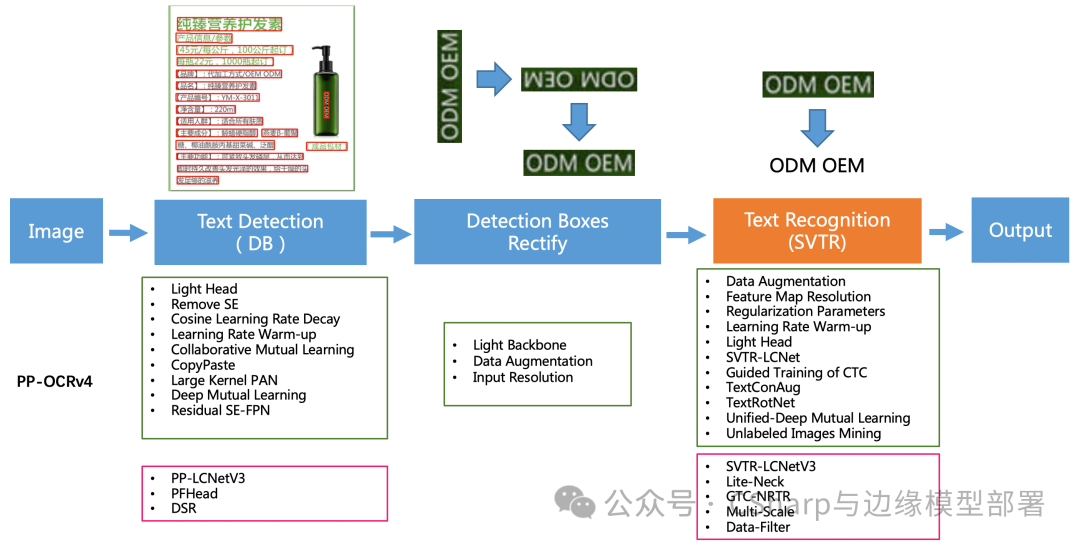
img
2. OpenVINO™ .CSharp.API.Extensions.PaddleOCR NuGet Package
2.1 NuGet Package 程序集
OpenVINO.CSharp.API.Extensions.PaddleOCR是基于先前开发的OpenVINO™ C# API项目,结合 PaddleOCR 文本识别模型,推出的基于C#平台的文本识别程序包。该项目主要是基于先前开发的OpenVINO™.CSharp.API项目,在C#平台部署PP-OCR文本识别模型,实现模型的推理加速。
该项目使用纯C#开发,并且将该项目封装成了 NuGet Package,发布到了 NuGet Gallery | Home,程序集情况如下图所示:
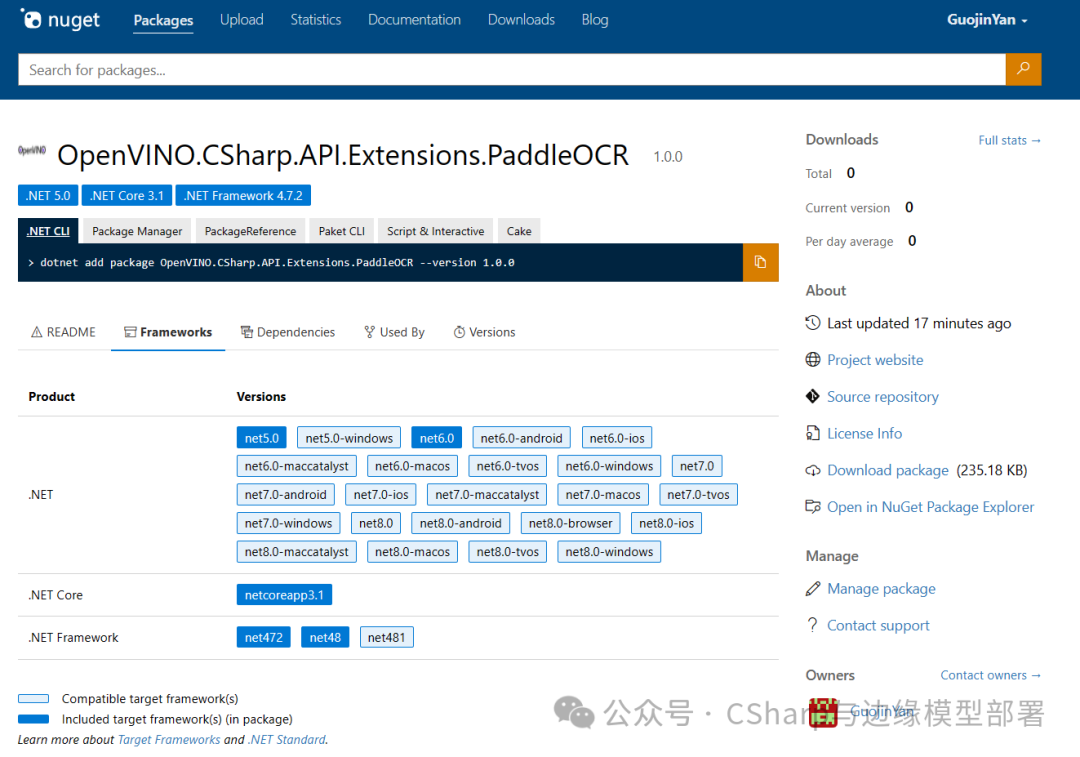
image-20240429221719496
OpenVINO™ .CSharp.API.Extensions.PaddleOCR NuGet Package 支持多个框架,在发布时,已经实现了对NET6.0、NET5.0 NET coreapp3.1 、NET Framework 4.8以及NET Framework 4.7框架的支持,提供给开发者更多的选择。
2.2 使用介绍
NuGet Package 是.NET生态系统中用于分发库和工具的包,是一个开源的包管理器,它使得开发者能够轻松地添加、更新和删除项目中的库和工具。因此如果想使用该程序集,我们可以使用Visual Studio的NuGet Package或者使用命令行的dotnet add package添加。
下面根据该程序集的使用情况,介绍一下一般情况下该程序集的使用方法:
首先是安装必要的程序集,主要包括本文的OpenVINO™ .CSharp.API.Extensions.PaddleOCR程序集,同时还包括图像处理库OpenCvSharp程序集,通过dotnet add package安装方式安装输入以下指令即可:
dotnet add package OpenCvSharp4
dotnet add package OpenVINO.CSharp.API.Extensions.PaddleOCR
同时,我们还需要安装必要的Runtime库,主要是OpenCv和OpenVINO,通过dotnet add package安装方式安装输入以下指令即可:
dotnet add package OpenCvSharp4.runtime.win
dotnet add package OpenVINO.runtime.win
此外,如果使用Visual Studio 的NuGet Package安装,只需要安装以上是个程序集即可。
3. 应用案例演示
3.1OnlineOcr:在线模型识别
OnlineOcr是封装的一个简单的在线模型识别方法,可以下载官方的PP-OCR文本识别模型到本地,然后使用OpenVINO加载模型创建推理器,此处为了方便测试,提供了一个ocr_test()接口,可以下载在线图片进行检测,检验项目是否安装成功。
下面是一个十分简单的测试代码,通过Pipeline.GetOnlineOCR()获取在线模型,然后调用ocr_test()进行预测,如下所示:
using OpenCvSharp;
using OpenVinoSharp.Extensions.model.PaddleOCR;
namespace OcrConsole
{
internal class Program
{
static async Task Main(string[] args)
{
Console.WriteLine("Hello, World!");
OnlineOcr ocr = await Pipeline.GetOnlineOCR(Language.ch_PP_OCRv4);
Tuple<List<OCRPredictResult>, Mat> ocr_result = ocr.ocr_test();
PaddleOcrUtility.print_result(ocr_result.Item1);
Mat image = PaddleOcrUtility.visualize_bboxes(ocr_result.Item2, ocr_result.Item1);
Cv2.ImShow("Result", image);
Cv2.WaitKey(0);
}
}
}
下图为上述程序运行后输出,首先会下载相应的模型文件以及标签文件,在推理时会下载测试图片,然后完成推理,实现文本检测:

image-20240430163802704
为了方便开发者使用,此处同时也提供了其他模型的下载方式,目前已经包含了PP-OCR所有模型,可以通过设置Language来实现不同语言模型的下载,同时还可以使用OCRDetModels.Get()、OCRRecModels.Get()、OCRClsModels.Get()等接口下载其他的模型。
3.2OCRPredictor:本地模型预测
OCRPredictor是该程序集中主要封装的预测模块,该模块可以实现本地模型的加载,并调用模型进行OCR识别,同时支持单一过程识别,开发者可以根据自己的需求,设置或者使用单一或其中几个过程进行推理,进行自己的项目开发和配置。
下面代码演示了两种OCRPredictor初始化方式:
-
第一种使用模型文件路径进行初始化,此处需要提前设置
RuntimeOption.RecOption.label_path识别模型key文件路径,RuntimeOption是该程序集中封装的常规配置参数,用户可以根据自己的使用需求进行修改;然后设置指定的模型路径初始化OCRPredictor即可;初始化完成后,调用ocr()方法进行图片预测。
using OpenCvSharp;
using OpenVinoSharp.Extensions.model.PaddleOCR;
namespace OcrConsole
{
internal class Program
{
static void Main(string[] args)
{
string det_model = "./ch_PP-OCRv4_det_infer/inference.pdmodel";
string cls_model = "./ch_ppocr_mobile_v2.0_cls_infer/inference.pdmodel";
string rec_model = "./ch_PP-OCRv4_rec_infer/inference.pdmodel";
string key_path = "ppocr_keys_v1.txt";
RuntimeOption.RecOption.label_path = key_path;
OCRPredictor ocr = new OCRPredictor(det_model, cls_model, rec_model);
string img_path = "demo_1.jpg";
Mat img = Cv2.ImRead(img_path);
List<OCRPredictResult> ocr_result = ocr.ocr(img, true, true, true);
PaddleOcrUtility.print_result(ocr_result);
Mat new_image = PaddleOcrUtility.visualize_bboxes(img, ocr_result);
Cv2.ImShow("result", new_image);
Cv2.WaitKey(0);
}
}
}
-
第二种使用
OcrConfig进行初始化,OcrConfig是该程序集中定义的配置类,里面定义了OCR预测时常用的一些配置参数,包括模型路径、key文件路径等,初始化OcrConfig后,便可以设置预测模型路径以及其它参数,最后将初始化的OcrConfig带入到OCRPredictor即可;初始化完成后,调用ocr()方法进行图片预测。
using OpenCvSharp;
using OpenVinoSharp.Extensions.model.PaddleOCR;
namespace OcrConsole
{
internal class Program
{
static void Main(string[] args)
{
string det_model = "./ch_PP-OCRv4_det_infer/inference.pdmodel";
string cls_model = "./ch_ppocr_mobile_v2.0_cls_infer/inference.pdmodel";
string rec_model = "./ch_PP-OCRv4_rec_infer/inference.pdmodel";
string key_path = "ppocr_keys_v1.txt";
OcrConfig config = new OcrConfig();
config.set_det_model_path(det_model);
config.set_cls_model_path(cls_model);
config.set_rec_model_path(rec_model);
config.set_rec_dict_path(key_path);
OCRPredictor ocr = new OCRPredictor(config);
string img_path = "demo_1.jpg";
Mat img = Cv2.ImRead(img_path);
List<OCRPredictResult> ocr_result = ocr.ocr(img, true, true, true);
PaddleOcrUtility.print_result(ocr_result);
Mat new_image = PaddleOcrUtility.visualize_bboxes(img, ocr_result);
Cv2.ImShow("result", new_image);
Cv2.WaitKey(0);
}
}
}
下图为使用本地模型以及图片预测后的输出情况:
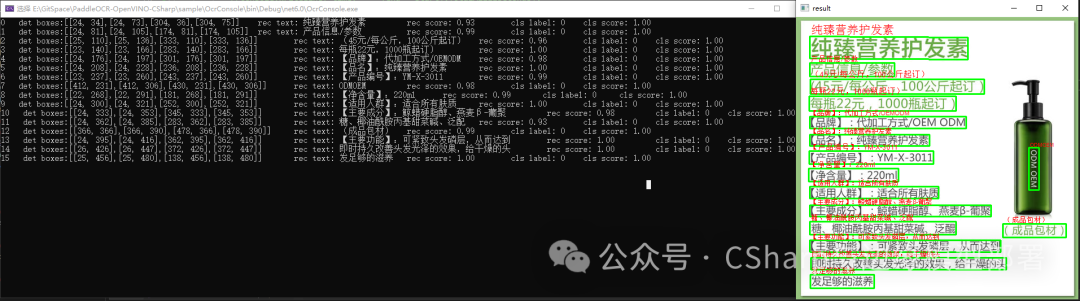
image-20240430193805438
在使用ocr()方法预测时,从我们可以通过指定标志位来定义本次预测流程,如下所示:
List<OCRPredictResult> ocr_result = ocr.ocr(img, det: true, rec: true, cls: true);
其中后面标志位det、rec、cls分别指示本次推理是否开启该流程,如果本次不需要文本区域识别,只进行文字方向判断以及文本识别,则需要设置为:
List<OCRPredictResult> ocr_result = ocr.ocr(img, det: false, rec: true, cls: true);
当然,OCRPredictor也同时提供了单一推理方式的接口,使用方式为:
List<OCRPredictResult> result = ocr.det(img);
List<Mat> img_list = new List<Mat>();
for (int j = 0; j < result.Count; j++)
{
Mat crop_img = new Mat();
crop_img = PaddleOcrUtility.get_rotate_crop_image(img, result[j].box);
img_list.Add(crop_img);
}
result = ocr.cls(img_list, result);
result = ocr.rec(img_list, result);
以上就是对OpenVINO™ .CSharp.API.Extensions.PaddleOCR NuGet Package简单的使用介绍,更多的使用信息可以访问源码进行查看。
4. 时间测试
目前PP-OCR模型可以使用OpenVINO™ CPU 设备进行推理加速,同时支持多Bathsize推理,所以当前开发的OpenVINO™ .CSharp.API.Extensions.PaddleOCR 程序集中已经实现了多Bathsize推理,只需要在推理器初始化时设置即可,如下所示:
OcrConfig config = new OcrConfig();
config.set_det_model_path(det_model);
config.set_cls_model_path(cls_model);
config.set_rec_model_path(rec_model);
config.set_rec_dict_path(key_path);
config.cls_option.batch_num = 16;
config.rec_option.batch_num = 16;
config.det_option.device = "AUTO";
config.cls_option.device = "AUTO";
config.rec_option.device = "AUTO";
OCRPredictor ocr = new OCRPredictor(config);
最后,对比了不同Bathsize情况下模型推理时间,测试电脑使用的是:11th Intel Core i7-1165G7,测试结果如下表所示:
| BathSize | 1 | 4 | 8 | 16 |
|---|---|---|---|---|
| CPU | 161 ms | 112 ms | 103 ms | 93 ms |
| AUTO | 122 ms | 111 ms | 101 ms | 91 ms |
通过该测试结果可以看出,多Bathsize推理在一定程度上可以提升模型的推理速度,最大会有42%的速度提升。
5. 总结
在该项目中,我们结合开发的OpenVINO™.CSharp.API.Extensions.PaddleOCR NuGet Package向大家展示了其简单的使用方法,方便大家快速上手该项目,并结合自己的应用需求进行DIY开发。最后如果各位开发者在使用中有任何问题,以及对该接口开发有任何建议,欢迎大家与我联系。
















 418
418

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









