









目录

最近,人工智能 (AI) 以惊人的速度越来越受欢迎。
OpenAI 的 ChatGPT 是人工智能的突破,热情高涨。
ChatGPT 引发了许多公司效仿的 AI 应用趋势。
你到处都在阅读和听到关于人工智能的信息。名人表演奇怪舞蹈动作的视频和图像出现,或者您听到“实际上”已经死了几年的艺术家的采访和歌曲。
下面将解释人工智能的确切功能。作为开发人员,我们习惯于分类思考并将问题分解为小步骤,这正是所有人工智能的工作方式。它们基于所谓的模型,这些模型已经针对各自的应用领域进行了训练。
示例:
如果您向 ChatGPT 索要图片,则必须使用 DALL-E 等单独的模型。
如果你要求一首诗,ChatGPT 使用语言模型。
ChatGPT 只不过是一个使用不同模型来完成手头任务的聊天机器人。
这就是我想开始并编写一个小型人工智能的地方,该人工智能将客户评论(以自由文本形式提供)分类为正面或负面。
作为 .NET 开发人员,Microsoft 提供了一个低门槛的机器学习入门 ML.NET。这个免费的开源框架可以轻松地将 ML 模型集成到新的和现有的 .NET 应用程序中,而无需了解 Python、R 或其他 ML 库。ML.NET 已包含许多用于常见用例的现成模型,并且可以轻松集成到现有的 .NET 应用生命周期中。
机器学习的基础知识
术语“机器学习”描述了教计算机从数据中学习模式和关系的方法,而不是使用规则和程序逻辑对它们进行显式编程。其目的是使机器能够独立于样本数据进行“学习”,并应用这些知识来解决类似的问题。
基本上有三种类型的学习:
监督学习
监督学习是一种机器学习方法,其中为模型提供训练数据,包括输入数据(例如文本)和相应的所需输出(例如“正”或“负”等分类)。使用这些示例,系统可以学习识别将输入与输出相关的模式。这使它能够在以后预测新的、看不见的输入的正确输出。一个经典的应用示例是图像中的对象识别。
例:
使用 ML.NET 进行监督学习的一个应用示例是将产品评论分类为“正面”或“负面”。程序如下:
// Loading the training data with reviews and labels
var data = mlContext.Data.LoadFromTextFile<ReviewData>(pathToFile);
// Creating the processing pipeline
var pipeline = mlContext.Transforms.Text.FeaturizeText("ReviewText", "Features")
.Append(mlContext.BinaryClassification.Trainers.SdcaLogisticRegression("Label"));
// Training the model
var model = pipeline.Fit(data);
在这一点上,我们有一个经过训练的模型,可以对新评论进行分类。
无监督学习
无监督学习是一种机器学习方法,其中模型仅提供未标记的输入数据,例如文本或图像,而没有任何相关的目标变量或分类。系统必须独立识别此原始数据中的结构、模式和相关性。一个典型的应用领域是聚类,其中相似的输入数据被汇总到组中。可能的示例是基于营销数据识别客户群,或者在分析文本时根据主题领域对新闻文章进行分组。
例:
无监督学习可以与文本聚类 ML.NET 一起使用,例如:
// Loading the text data
var data = mlContext.Data.LoadFromTextFile<ArticleData>(pathToFile);
// Create the text featurisation pipeline
var pipeline = mlContext.Transforms.Text.FeaturizeText("ArticleText", "Features");
// Train the clustering model
var model = mlContext.Clustering.Trainers.KMeans(pipeline, numberOfClusters: 5).Fit(data);
// Predict the cluster membership for new articles
var predictions = model.Transform(data);
例如,通过这种方式,新闻文章可以自动分类为政治、商业、体育等主题集群。
ML.NET 主要侧重于监督和部分无监督学习。ML.NET 目前没有为强化学习提供任何特定的支持,在强化学习中,人工智能在模拟环境中通过奖励进行训练。这种学习范式特别用于战略发现任务,例如游戏或流程优化。
强化学习
强化学习是一种学习范式,其中人工智能在模拟环境中通过反复试验进行训练。与监督学习相比,没有具有输入输出对的完整训练示例。相反,系统会收到每个操作的分数(奖励),这表明该操作有多“好”。通过最大化累积的奖励,人工智能学会了为任务找到最佳策略。这种强化学习原理特别用于需要找到复杂策略的任务。例子包括棋盘游戏,如国际象棋或围棋,还有机器人控制、流程优化或自动驾驶的应用。
示例:
一个经典的应用程序示例是国际象棋玩家代理。这里的环境可能是一个棋盘,可能的动作是移动动作。然后,代理会收到每步棋的评估,例如,+1 表示确定的棋子获胜,-5 表示即将输掉棋子。通过许多训练游戏,人工智能可以学习哪些动作可以带来长期的胜利,从而最大限度地提高其累积奖励。
设置开发环境
若要开始使用 ML.NET,我们需要版本 4.6.1 或更高版本的 .NET Core 或 .NET Framework 环境。ML.NET 可以在 Visual Studio、Visual Studio Code 或命令行中使用。
第一步是安装所需的 NuGet 包 ML.NET:The first step is to install the required NuGet packages of :
Install-Package Microsoft.ML
此主包包含基本功能,例如 ML.NET 上下文、数据转换以及包含模型和任务的目录。对于其他功能,可以添加其他包,例如用于图像处理的 Microsoft.ML.Vision 或用于推荐系统的 Microsoft.ML.Recommender。
安装后,我们可以在 Visual Studio 中创建 .NET Core 或 .NET Framework 控制台应用程序并开始开发。
(可选)集成工具(如 Visual Studio 中的模型生成器界面或 ML.NET CLI )可用于可视化数据和创建模型。我稍后再谈这个问题。
创建第一个 ML 模型
下面,通过示例逐步解释 ML.NET 的基本概念:
客户评论的分类基于自由文本。
结果应该是将这些评级归类为正面或负面。
这是一个经典的监督学习问题。
我们创建新的 C# 控制台应用程序并导入 ML.NET NuGet 包。
接下来,我们将数据集加载到工作内存中。在我们的示例中,我们需要一个 TSV(制表符分隔文件)文件。这由控制台应用程序中的简单类表示:
此类代表 TSV 文件中的每一行。
public class ReciewData
{
}
现在,我们为 TSV 数据的每一列添加属性:
public class ReviewData
{
public string ReviewText { get; set; }
public bool Label { get; set; }
}
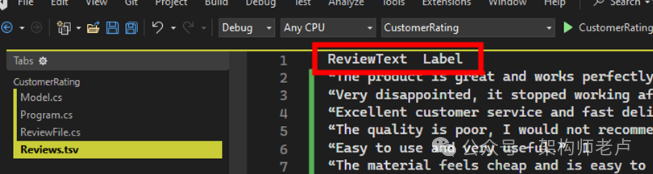
不幸的是,这还不足以加载此 TSV 文件并教 ML.Net 如何引用此文件。
为此,我们需要属性:LoadColumn 加上列的索引。
public class ReviewData
{
[LoadColumn(0)]
public string ReviewText { get; set; }
[LoadColumn(1)]
public bool Label { get; set; }
}
这是从 ReviewText 属性到 TSV 文件 ReviewText 列的简单映射。
现在,让我们处理文件的存储路径,并将它们保存在我们的应用程序中:
首先,我们创建训练文件的路径,即 TSV 文件 (Review.tsv)。
string baseDirectory = @"..\\..\\AI";
string subDirectory = "TrainingData";
string trainingDataFilePath = Path.Combine(baseDirectory, subDirectory, "Reviews.tsv");
我们将使用此文件来训练要用于分类的模型。
现在,我们定义要训练的模型的路径。此模型保存为 ZIP 文件。
string modelPath = Path.Combine(AppDomain.CurrentDomain.BaseDirectory, "model.zip");
现在我们需要一个 MLContext 变量。MLContext 可与 EF DbContext 相媲美。因此,每当要使用机器学习时,都必须与 MLContext 进行交互,类似于 EF Core 中的 DBContext。
现在我们已准备好加载数据。我们可以根据需要操作它来根据我们的要求训练模型。
现在我们构建模型:
为此,我们需要 ML.NET 的特定类型。The IDataView:
var trainingDataView = mlContext.Data.LoadFromTextFile<ReviewData>(trainingDataFilePath, separatorChar: '\t', hasHeader: true);
现在,我可以使用 MLContext 中名为 LoadFromTextFile 的函数。<ReviewData>' 现在用于将数据投影到我们最初创建的类中。现在必须将训练文件的路径传递给此函数。作为奖励,我们可以在这里指定更多选项,例如 TSV 文件的分隔符以及我们的训练文件是否有标头(我们有一个标头,所以我将此参数设置为 true)。
现在我们已经将数据加载到 DataView 中,我们可以开始预处理了。预处理是创建所谓的管道的一种方法。这以后可用于在我们有传入数据(例如我们的客户分数)时执行预测。为此,我们需要从创建的数据视图 (IDataView) 中提取数据,然后对其进行转换,以便将其用作机器学习过程的一部分。
现在,让我们创建管道。这具有特定的返回类型:IEstimator<ITransformer>:
/// <summary>
/// Creates the machine learning pipeline for review classification.
/// </summary>
/// <param name="context">The ML context.</param>
/// <returns>The machine learning pipeline.</returns>
public static IEstimator<ITransformer> CreatePipeline(MLContext context)
{
return context.Transforms.Text.FeaturizeText("Features", "ReviewText")
.Append(context.BinaryClassification.Trainers.SdcaLogisticRegression(labelColumnName: "Label"))
.AppendCacheCheckpoint(context);
}
**Context.Transforms.Text。**FeaturizeText 是 ML.NET 中的文本转换组件,用于将文本数据转换为数值要素。
“特征”是包含生成的数值特征的新列名称。
**“ReviewText”**是 TSV 文件中包含要转换为数字特征的文本的列的名称。
现在开始训练模型:
**'。Append“将下一步添加到管道中。使用“Context.BinaryClassification.Trainers.SdcaLogisticRegression”**训练模型,该算法定义了要训练模型的算法,在本例中为 SdcaLogisticRegression 算法。“标签”是表示要预测的目标变量的列或列的名称。在我们的示例中,它是对这种评估是积极的还是消极的分类。
让我们再次总结一下:
此命令生成执行以下步骤的管道:
-
文本特征化:“ReviewText”列中的文本将转换为数字要素,并存储在新的“要素”列中。
-
模型训练:“特征”列中的数值特征用于训练具有“标签”列中目标变量的二元分类模型。
现在,我们已经创建了管道,可以开始训练模型了。
var pipeline = CreatePipeline(mlContext);
var model = pipeline.Fit(trainingDataView);
我们使用“管道。适合(...)' 命令根据 TSV 文件中的数据训练模型。然后将模型存储在内存中。
但是,为了保存模型而不必每次都创建和重新训练它,我们可以使用“Save()”方法。这使我们能够将训练好的模型保存在特定的文件路径中。通过这种方式,我们可以在需要时简单地加载和使用模型,而不必每次都重新训练它。
MlContext 中有一个选项,我们可以在其中找到 Save() 函数:
context.Model.Save(model, schema, modelPath);
首先,我们从 TSV 文件的 IDataView 传输经过训练的模型和架构,然后传输要保存模型的路径。
我们现在已经训练了我们的模型并将其保存到硬盘中。
现在我们需要另一个表示训练的 DataSet 的类,即模型的结果(预测类)。为此,我们从 TSV 文件 (ReviewData) 创建另一个与 DataSet 类具有类似结构的类。
public class ReviewPrediction
{
[ColumnName("PredictedLabel")]
public bool PredictedLabel { get; set; }
}
该属性定义在 MLContext 中使用“PredictedLabel”列的名称来读取其中的预测值。
为了将模型连接到预测类,我们现在需要一个 PipelineEngine。我们从 MLContext 再次创建此引擎。
var predictionEngine = mlContext.Model.CreatePredictionEngine<ReviewData, ReviewPrediction>(model);

我们将泛型类型 TSrc(源)和 TDst(目标)用于输入和输出类,“ReviewData”和“ReviewPrediction”(“Good rating”、“Positiv”)。
各个组件及其交互现在应该是可以理解的:为什么我们需要将文本转换为数字特征,为什么我们需要准备数据以便计算机能够理解它,以及我们的“ReviewData”类是我们的源类,“ReviewDataPrediction”是我们的目标类。
现在我们已经完成了准备步骤,我们可以进入预测阶段。
现在,让我们来处理执行预测并返回预期目标变量的代码。
在我们的示例中,预测结果是一个布尔值。
第一步是输入一个分数,然后我们将其写入“ReviewData”输入类。
var input = new ReviewData { ReviewText = inputReviewText };
变量“ReviewText”是一个字符串变量,包含我们的审阅。
现在,我们将“ReviewData”类型的输入变量传递到我们刚刚创建的管道。
因此,我们收到“ReviewPrediction”输出类,现在可以通过该变量从模型访问目标变量。
// Classify the new rating and display the result
var prediction = predictionEngine.Predict(input);
Console.WriteLine($"The classification for the rating ‘{ input.ReviewText}’ is: { (prediction.PredictedLabel ? "Positiv" : "Negativ")}");
如果模型具有良好的训练数据,我们现在应该得到正确的预测结果。
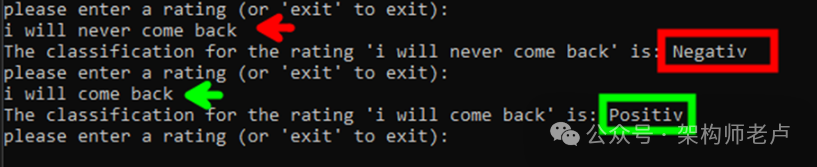
它似乎有效。
当然,这只是一个小例子,模型并不完美,但如果你训练得好,理想情况下它应该总是返回正确的结果。
以下扩展已添加到示例中,用于在输入不正确或未知时重新训练模型。
启动应用程序时,您可以选择向模型添加新数据和直接训练,也可以创建新注释。
在下面的文章中,我将仔细研究图像识别和预测。
总结:
尽管本文仅限于文本分类,但仔细观察并带有一点创造力,所描述的方法开辟了许多可能性。例如,对某个分类的识别可用于自动触发进一步的过程。
总的来说,可以说人工智能具有巨大的潜力,可以在日常生活的许多领域为我们提供支持并优化流程。文本分类只是众多可能应用中的一个例子。可以假设,未来越来越多的领域将受益于人工智能的可能性,这将为公司和个人开辟新的机会。















 1808
1808











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









