







文章目录
一、PyTorch 简介


1.1、PyTorch 模块
| Component | Description |
|---|---|
| torch | A Tensor library like NumPy, with strong GPU support |
| torch.utils | DataLoader and other utility functions for convenience |
| torch.nn | A neural networks library deeply integrated with autograd designed for maximum flexibility |
| torch.autograd | A tape-based automatic differentiation library that supports all differentiable Tensor operations in torch |
| torch.multiprocessing | Python multiprocessing, but with magical memory sharing of torch Tensors across processes. Useful for data loading and Hogwild training |
| torch.jit | A compilation stack (TorchScript) to create serializable and optimizable models from PyTorch code |
1.2、PyTorch 计算图
1.2.1、静态计算图
老版的TensorFlow 使用静态图(提前创建好) 来表示计算任务,由节点和边组成,节点表示 Tensor 或者 op(运算符),边表示 Tensor 和 op 之间的依赖关系;
Tensor在图中通过运算(op, eg:ADD)进行传递和变换, 一个op可以获得 0 个或多个张量(Tensor), 通过创建会话(Session)对象来执行计算,产生 0 个或多个Tensor。所以,TensorFlow 的工作模式分为以下两步:
- Define the
computation graph- Run the graph (with data) in
Session为什么需要提前定义好计算图,然后再去执行运算?
Save computation:only run subgraphs that lead to the values you want to fetchFacilitate distributed computation: spread the work across multiple CPUs, GPUs, or devicesFacilitates auto-differentiation:break computation into small, differential pieces
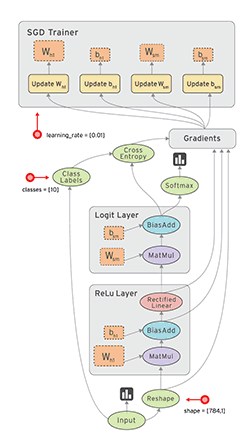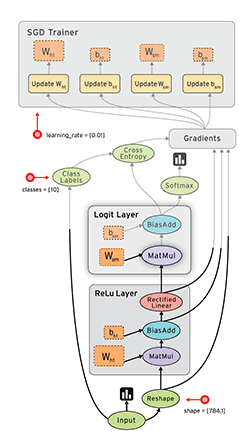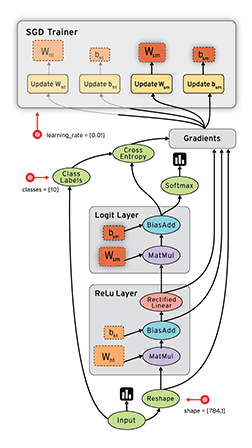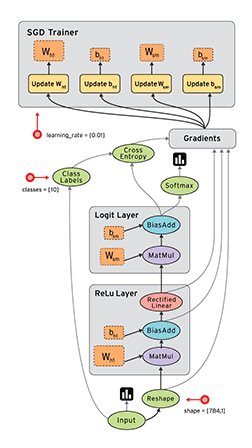
1.2.2、动态计算图
Pytorch 中的计算图是动态图,由节点和边组成,节点表示 Tensor 或者 op(运算符),边表示 Tensor 和 op 之间的依赖关系
Tensor在图中通过运算(op, eg:ADD)进行传递和变换, 一个op可以获得 0 个或多个张量(Tensor),通过op运算,产生 0 个或多个Tensor,一般 op 可继承于torch.autograd.Function,同时支持正向传播和反向传播- 动态图的正向传播是立即执行得出结果的(
方便 Debug),无需等待完整的计算图创建完毕- 动态图在反向传播后立即销毁,释放存储空间,下次调用需要重新构建计算图
- 如果程序中使用了
torch.autograd.backward方法执行了反向传播,那么创建的计算图会被立即销毁,下次调用需要重新创建- 如果程序中使用了
torch.autograd.grad方法计算了梯度,那么创建的计算图会被立即销毁,下次调用需要重新创建- 若不想立即销毁,则需指明
retain_graph参数为True来保留计算图

二、PyTorch 张量系统:torch
- 参考此 blog: Pytorch 张量系统:Tensor
三、PyTorch 自动求导机制:torch.autograd
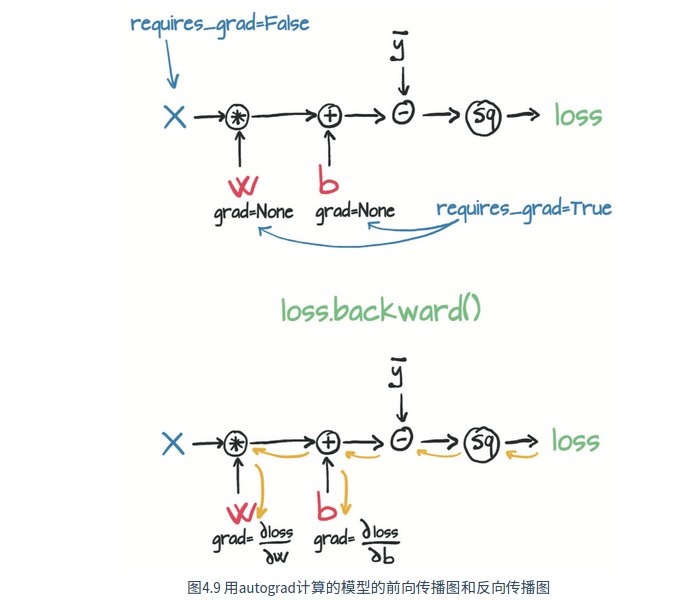
torch.autograd能够根据输入和前向传播过程 自动构建计算图,并自动计算梯度用于反向传播:
- 每个 Tensor 都有一个
requires_grad标志,默认为False,可用于冻结某些层的参数- 如果一个节点
requires_grad被设置为True,那么计算图中所有依赖它的节点都需要求解梯度- 优化器使用
autograd来计算每个参数的梯度(存储在tensor的.grad属性中)并进行更新
# requires_grad=False by default
>>> x = torch.randn(5, 5)
>>> y = torch.randn(5, 5)
>>> z = torch.randn((5, 5), requires_grad=True)
>>> a = x + y
>>> a.requires_grad
False
>>> b = a + z
# 依赖于叶子结点的结点,requires_grad 默认为 True,叶子节点(z)不可执行 in-place 操作
>>> b.requires_grad
True
2.1、torch.autograd.backward:自动求取梯度
torch.autograd.backward(tensors, grad_tensors=None, retain_graph=None, create_graph=False, grad_variables=None, inputs=None)
tensors(Sequence[Tensor] or Tensor): 用于求导的张量,如 lossgrad_tensors(Sequence[Tensor or None] or Tensor, optional):与根节点 loss 形状相同的张量,最终梯度为 loss 求出梯度与 grad_tensors 张量的点积;在 Tensor 的方法中是gradient参数- 若调用的 loss 是标量(或者 loss 张量通过
loss.sum()转成标量),则可以不提供此参数,默认为 1;有多个 loss 时,若提供该参数则可以看做是各个 loss 的权重 - 若调用的 loss 是张量,则必须提供与 loss
相同形状的参数
- 若调用的 loss 是标量(或者 loss 张量通过
retain_graph(bool, optional):- 保持计算图,如果需要多次调用 backward 可设置为 True,但梯度会累加
- 当有多个输出需要同时进行梯度反传时,需要将其设置为
True,从而保证在计算多个输出的梯度时互不影响
create_graph(bool, optional): 创建导数计算图,用于高阶求导inputs (Sequence[Tensor] or Tensor, optional):输入数据Note: 调用 backward() 方法后,叶子节点的梯度(grad)会在反向传播的过程中累加。所以在梯度进行参数更新后(下一次反向传播前)需要把梯度清零x.grad.zero_() or optimizer.zero_grad()
########################## 0、Tensor 中 backward 方法的定义 ##########################
def backward(self, gradient=None, retain_graph=None, create_graph=False, inputs=None):
if has_torch_function_unary(self):
return handle_torch_function(
Tensor.backward,
(self,),
self,
gradient=gradient,
retain_graph=retain_graph,
create_graph=create_graph,
inputs=inputs,
)
torch.autograd.backward(
self, gradient, retain_graph, create_graph, inputs=inputs
)
########################## 1、gradient 与 retain_graph 的用法 ##########################
import torch
x = torch.tensor([[0.0, 0.0], [1.0, 2.0]], requires_grad=True) # x 需要被求导
a = torch.tensor(1.0)
b = torch.tensor(-2.0)
c = torch.tensor(1.0)
y = a * torch.pow(x, 2) + b * x + c # f(x) = a*x**2 + b*x + c
gradient = torch.tensor([[1.0, 1.0], [1.0, 2.0]])
y.backward(gradient=gradient, retain_graph=True) # 转换成标量来进行反向传播:torch.sum(y*gradient).backward()
print("y_grad:\n", y.grad) # None, 为了节约存储空间,非叶子节点的梯度均为 None,只在计算过程中被用到,不会最终存储到 grad 属性中
print("x_grad:\n", x.grad)
y.backward(gradient=gradient)
print("x_grad:\n", x.grad) # retain_graph=True 会出现梯度累积,可在 backward 前执行 x.grad.zero_() 进行梯度清零
# 输出如下
y_grad:
None
x_grad:
tensor([[-2., -2.],
[ 0., 4.]])
x_grad: # 梯度未清零造成梯度累积
tensor([[-4., -4.],
[ 0., 8.]])
########################## 2、非叶子节点梯度显示 ##########################
import torch
# 正向传播
x = torch.tensor(3.0, requires_grad=True)
y1 = x + 1
y2 = 2 * x
loss = (y1 - y2) ** 2
# 非叶子节点梯度显示控制
# 1、利用 retain_grad 可以保留非叶子节点的梯度值
# 2、利用 register_hook 可以查看非叶子节点的梯度值(需要定义在 backward 前面),但不会保留其值
y1.register_hook(lambda grad: print('y1.register_hook grad: ', grad))
y2.register_hook(lambda grad: print('y2.register_hook grad: ', grad))
y1.retain_grad()
y2.retain_grad()
loss.retain_grad()
# 反向传播
loss.backward() # 通过 register_hook 可以查看非叶子节点的梯度值
print("loss.grad:", loss.grad)
print("y1.grad:", y1.grad)
print("y2.grad:", y2.grad)
print("x.grad:", x.grad)
# 输出如下
y2.register_hook grad: tensor(4.)
y1.register_hook grad: tensor(-4.)
loss.grad: tensor(1.) # 若 loss 为高维张量,则输出高维张量
y1.grad: tensor(-4.)
y2.grad: tensor(4.)
x.grad: tensor(4.)
########################## 3、网络前向传播和反向传播求解梯度,更新参数示例 ##########################
import torch
import torchvision
# 生成数据
data = torch.rand(1, 3, 64, 64)
labels = torch.rand(1, 1000)
# 构建模型
model = torchvision.models.resnet18(weights="ResNet18_Weights.DEFAULT")
# 指定参数学习算法
optimizer = torch.optim.SGD(model.parameters(), lr=1e-2, momentum=0.9)
# 模型训练
for i in range(500):
# 前向传播 [1, 1000]
prediction = model(data)
# 计算 loss:使用 .sum() 方法求和,loss 是一个标量
loss = (prediction - labels).sum() # 通常使用 loss = criterion(outputs, labels),返回标量
# 反向传播 loss:实际调用 torch.autograd.backward 为每个模型参数计算梯度并将其存储在参数的.grad 属性中
loss.backward()
# 参数更新:调用 .step() 启动梯度下降,优化器通过.grad 中存储的梯度来调整每个参数
optimizer.step()
# 清空梯度:调用 backward 会导致导数值在叶节点处累积,所以将其用于参数更新后,需要将梯度显式清零
optimizer.zero_grad()
print("iter {}".format(i))
########################## 4、网络微调示例 ##########################
import torch
import torchvision
# 生成数据
data = torch.rand(1, 3, 64, 64)
labels = torch.rand(1, 10)
# 构建模型
model = torchvision.models.resnet18(weights="ResNet18_Weights.DEFAULT")
for param in model.parameters():
param.requires_grad = False
# Replace the last fully-connected layer
# Parameters of newly constructed modules have requires_grad=True by default
model.fc = torch.nn.Linear(512, 10) # 1000-->10 类
# 指定参数学习算法:Optimize only the classifier
optimizer = torch.optim.SGD(model.fc.parameters(), lr=1e-2, momentum=0.9) # 只更新 fc 层进行 finetune
# 模型训练
for i in range(500):
# 前向传播 [1, 10]
prediction = model(data)
# 计算 loss:使用 .sum() 方法求和,loss 是一个标量
loss = (prediction - labels).sum()
# 反向传播 loss:实际调用 torch.autograd.backward 为每个模型参数计算梯度并将其存储在参数的.grad 属性中
loss.backward()
# 参数更新:调用 .step() 启动梯度下降,优化器通过.grad 中存储的梯度来调整每个参数
optimizer.step()
print("iter {}".format(i))
2.2、torch.autograd.grad:求取梯度
torch.autograd.grad(outputs, inputs, grad_outputs = None, retain_graph = None, create_graph = False)
outputs: 用于求导的张量,如 loss,如果有多个因变量,相当于把多个因变量的梯度结果求和inputs: 需要求解梯度的张量,允许同时对多个自变量求导数create_graph: 创建导数计算图,用于高阶求导retain_graph: 保持计算图grad_outputs:多梯度权重
import torch
x = torch.tensor(0.0, requires_grad=True) # x 需要被求导
a = torch.tensor(1.0)
b = torch.tensor(-2.0)
c = torch.tensor(1.0)
y = a * torch.pow(x, 2) + b * x + c # f(x) = ax**2 + bx + c
# create_graph 设置为 True 将允许创建更高阶的导数
dy_dx = torch.autograd.grad(y, x, create_graph=True)[0] # f(x)‘ = 2ax+b
print(dy_dx.data) # tensor(-2.)
# 求二阶导数
dy2_dx2 = torch.autograd.grad(dy_dx, x)[0] # f(x)" = 2
print(dy2_dx2.data) # tensor(2.)
2.3、使用梯度上下文管理器控制自动求导
# torch.no_grad()/torch.set_grad_enabled()/torch.enable_grad() 的上下文管理器可用于控制是否需要自动求导
>>> x = torch.zeros(1, requires_grad=True)
>>> with torch.no_grad():
... y = x * 2
>>> y.requires_grad
False
>>> is_train = False
>>> with torch.set_grad_enabled(is_train):
... y = x * 2
>>> y.requires_grad
False
四、PyTorch 层级结构: torch.nn
- 参考此 blog:Pytorch 层级结构
五、PyTorch 并行:torch.multiprocessing
- 参考此 blog: PyTorch 分布式训练
六、PyTorch 常用工具:torch.utils
- 参考如下 blog:
七、参考资料
1、https://pytorch.org/
2、https://github.com/pytorch
3、https://github.com/pytorch/pytorch
4、https://pytorch.org/docs/stable/index.html
5、PyTorch 中文文档
6、https://pytorch.apachecn.org/
7、https://github.com/awfssv/pytorch-cn
8、pytorch 多 gpu并行训练
9、Pytorch多机多卡分布式训练
10、https://download.pytorch.org/whl/torch_stable.html














 5560
5560











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









