






在这篇文章里,我们将了解什么时候和为什么软件开发要使用SOLID原则。
首先,我们会了解在软件设计中,为什么要考虑设计原则。然后,我们将列出使用每条设计原则随之而来的问题和解决办法。
请注意文中的例子都是经过简化的。他们的作用只是简单示范当违反设计原则时相关的问题。
介绍
SOLID是马丁(Robert·Martin)提出的五条设计原则的首字母缩写。我强烈推荐阅读他的书《架构整洁之道》(CLean Architecture)。
这里列出5条原则:
- 单一职责原则(SRP)
- 开闭原则(OCP)
- 里氏替换原则(LSP)
- 接口隔离原则(ISP)
- 依赖反转原则(DIP)
这些原则的主要目的是使软件修改更灵活,扩展和维护更容易。
软件变更需要花费时间,这是最昂贵的资源。业务需要对市场变更快速响应,所以开发时间是非常宝贵的。你能越快的修改代码完成新的需求,你的业务也会更容易发展壮大。
单一职责原则(SRP)
每个模块有且仅有一个修改的理由。
SRP原则是最难理解的原则,因为很多开发者认为,它的意思是每个模块只负责完成一件事情。这在我们设计函数时是适用的。例如:我们把一个函数拆分成多个更小的函数,我们要确保每个函数只做一件事。
但是SRP原则的本质不是这样。为了更清楚一点,我们可以将原理解释如下:
每个模块仅对有且只有的一个用户或利益相关者负责。
修改软件是为了满足用户或利益相关者的需求。因此,这些用户和利益相关者是改变的原因。在这种情况下,模块是一个相关函数和数据结构的集合。
问题
在下面的示例中,我们有一个违反SRP原理的类 AdsAccount 。
class AdsAccount {
public startCampaign() { ... }
public calculateCampaignStats() { ... }
public save() { ... }
}
此模块有多个原因会导致更改:
- 由营销团队定义的 startCampaign 方法的实现
- 由分析团队定义的 calculateCampaignStats 方法的实现
- 由开发团队定义的 save 方法的实现
如果将这些方法的实现放在一个类中,则营销团队的新需求很可能会影响分析团队的业务逻辑。
假设 startCampaign 和 calculateCampaignStats 方法使用通用方法 getCampaignImpressions。
营销团队改进了印象计算逻辑,他们希望将其应用于新的广告系列。
开发人员更新并测试了 startCampaign 和 getCampaignImpressions 方法。
市场营销团队批准了更改,并部署了新版本。
一段时间后,出现了广告统计信息的使用了新的计算方式,分析团队使用了不一致的数据。
解决方案
解决方案非常简单。我们只需要将我们的逻辑拆分为单独的类。
class AdsAccount {
constructor() {
this.statsCalculator = new StatsCalculator()
this.campaignLauncher = new CampainLauncher()
this.campaignSaver = new CampaignSaver()
}
public startCampaign() {
this.campaignLauncher.startCampaign(...)
}
public calculateCampaignStats() {
this.statsCalculator.calculateCampaignStats(...)
}
public save() {
this.campaignSaver.save(...)
}
}
class StatsCalculator {
public calculateCampaignStats() { ... }
private getCampaignImpressions() { ... }
}
class CampaignLauncher {
public startCampaign() { ... }
private getCampaignImpressions() { ... }
}
class CampaignSaver {
public save() { ... }
}
现在我们有了遵守SRP原则的三个类:StatsCalculator ,CampaignLauncher,和 CampaignSaver。每个新类都不依赖于其他类。我们有单独的私有方法来获取广告印象——每个团队有自己的逻辑。
AdsAccount 现在起着门面作用。它负责创建几个新类的实例和委托方法调用。
开闭原则(OCP)
每个模块都应该对扩展开发,对修改关闭。
对扩展开放意味着可以仅通过提供新模块就可以向应用程序添加新功能。
对修改关闭意味着扩展现有模块不应导致你需要对依赖的模块进行修改。
该原则的目标是使系统易于扩展并免受更改的影响。
如果对应用程序逻辑的简单扩展导致其他模块中的一系列更改,则你可能违反了OCP原则。
将此原则与单一职责原则和依赖反转原理一起应用,可以防止出现对其中一个类进行更改时,还需要修改它所有依赖的模块。
让我们深入研究该示例。
问题
假设,您正在创建一个送餐应用程序。您有一个移动应用程序,您的用户可以在其中创建和查看订单。
常见的解决方案是你创建一个模块(即控制器),该模块从数据库中加载模型数据,将其转换为HTTP响应负载,然后将其发送给客户端。
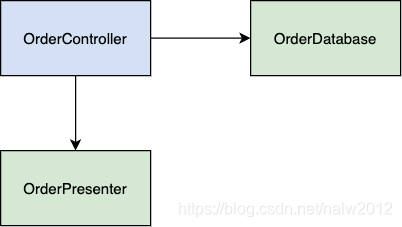
在上图中,我们有一个 OrderController,其持有 OrderDatabase 和 OrderPresenter。OrderDatabase 负责加载和保留订单模型。OrderPresenter 负责将订单模型映射到HTTP响应。
假设利益相关者要求实现通过电子邮件发送订单。我们会快速更新控制器代码,以便在创建新订单时向用户发送电子邮件。
让我们看看下面的伪代码:
class OrderController {
constructor() {
this.mailServer = new MailServer()
this.orderPresenter = new OrderPresenter()
}
public createOrder(): Promise<OrderView> {
const order = new Order(...)
await order.save()
const orderView = this.orderPresenter.present(order)
this.mailServer.send(orderView)
return orderView
}
}
过了一段时间,出现了新的需求。我们需要在电子邮件中显示订单总金额。换句话说,我们需要更新订单视图。
要了解的重要一点是,订单是通过两种不同的视图呈现的:通过手机屏幕和通过电子邮件。对于新需求,每个视图以不同的方式显示订单详情。
我们可以通过多种方式来解决这个问题。我们可以扩展 OrderPresenter ,增加一个用于创建电子邮件视图的新方法。我们也可以为电子邮件创建另一个表现层模块。在这两种情况下,我们都必须更新控制器以匹配新的表现层API。
看起来我们违反了OCP原则了吗?每次引入新需求时,我们如何避免我们的控制器和表现层更改?
解决方案
让我们将演示逻辑分为两个模块。每个模块将负责将订单模型转换为特定视图所需的数据。
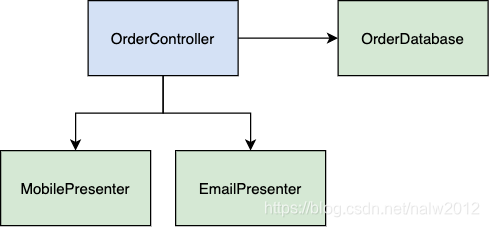
这样好多了。电子邮件表现层的更改,如添加新字段等不会影响移动表现层。但是,控制器的问题仍然存在。更改演示者API后,我们如何组织代码以避免影响到控制器?
为此,我们需要通过反转依赖使控制器独立于表现层。我们的控制器模块应为表现层定义一个接口。所有的表现层都应该实现此接口。
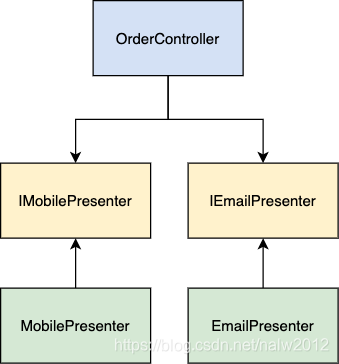
使用这种架构,控制器对表现层的实际实现一无所知。所有表现层都必须遵守接口定义的协议。让我们看一下更新的代码示例:
export interface IEmailPresenter {
present(order: Order): EmailView
}
export interface IMobilePresenter {
present(order: Order): MobileView
}
class OrderController {
constructor(emailPresenter: IEmailPresenter, mobilePresenter: IMobilePresenter) {
this.emailPresenter = orderPresenter
this.mobilePresenter = mobilePresenter
this.mailServer = new MailServer()
}
public createOrder(): Promise<MobileView> {
const order = new Order(...)
await order.save()
const emailView = this.emailPresenter.present(order)
this.mailServer.send(emailView)
const mobileView = this.mobilePresenter.present(order)
return mobileView
}
}
结果,我们使用接口避免了 OrderController 被修改。此外,我们可以说我们的表现层可以扩展。当我们需要添加另一种类型的功能时,我们提供了一个新模块。
这就是OCP如何起作用。您拆分应用程序,考虑如何,何时以及为什么需要对其进行更改。之后,将所有内容组织到组件层次结构中。需要防止更改的那些组件定义了频繁更改的组件所使用的接口。
里氏替换原则(LSP)
子类应以不会破坏对外暴露的功能的方式覆盖父类方法。
换句话说,软件模块使用父类的地方应该能够使用子类替换,而无需更改代码。
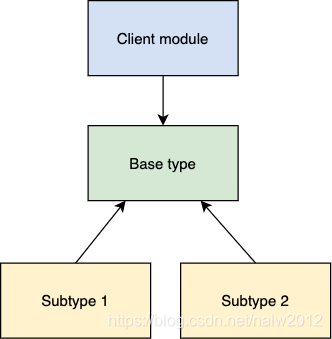
这种父类可以被两个子类替换的设计就是LSP。
但是什么是父类和子类?父类可以是具有继类子类的类,也可以是带有作为实现的子类的接口。
为了更好地理解LSP背后的思想,让我们看一下示例。
问题
假设我们需要实现一个电子钱包应用程序,在这里我们可以将钱从一张卡转移到另一张卡。一个抽象的解决方案可能像这样:
class BankCard {
topup() { ... }
withdraw() { ... }
}
class Wallet {
transfer(amount: number, sender: BankCard, receiver: BankCard) {
// ...
}
}
const wallet = new Wallet()
const senderBankCard = new BankCard()
const receiverBankCard = new BankCard()
wallet.transfer(1000, senderBankCard, receiverBankCard)
在这里,我们有一个 Wallet 实例,该实例使用 BankCard 实例进行转账。
一段时间后,我们的电子钱包应用程序被加了新的需求。我们的钱包用户必须能够从储蓄卡转账。这些卡是虚拟的。它们无法手动充钱,因此没有 topup 方法。
现在,我们的转账者可以是银行卡或储蓄卡。
class BankCard {
topup() { ... }
withdraw() { ... }
}
class SavingsCard {
withdraw() { ... }
}
class Wallet {
transfer(amount: number, sender: BankCard | SavingsCard, receiver: BankCard) {
if (sender instanceof BankCard) {
// ...
}
if (sender instanceof SavingsCard) {
// ...
}
}
}
const wallet = new Wallet()
const senderSavingsCard = new SavingsCard()
const receiverBankCard = new BankCard()
wallet.transfer(1000, senderSavingsCard, receiverBankCard)
这样可以工作,但是无论何时引入新卡,我们都必须在参数中添加新类型和新的 if 语句。我们无法将替换 BankCard 为 SavingsCard,因此我们违反了LSP。
解决方案
要遵循LSP,我们需要为卡添加一个父类以支持交互性。这种方法保证了我们将始终拥有 withdraw 方法。
interface IWithdrawable {
withdraw(): void
}
interface IRechargeable {
topup(): void
}
class BankCard implements IRechargable, IWithdrawable {
topup() { ... }
withdraw() { ... }
}
class SavingsCard implements IWithdrawable {
withdraw() { ... }
}
class Wallet {
transfer(amount: number, sender: IWithdrawable, receiver: IRechargable) {
// ...
}
}
const wallet = new Wallet()
const senderSavingsCard = new SavingsCard()
const receiverBankCard = new BankCard()
wallet.transfer(1000, senderSavingsCard, receiverBankCard)
现在我们可以说上述解决方案遵循了LSP。我们有一个父类:IWithdrawable,它可以用子类 BankCard 和 SavingsCard 替换。我们的方法使用了父类,因此无需在每次引入新卡时都对其进行修改。新卡的唯一要求是它是我们父类的子类。
接口隔离原则(ISP)
不应强迫软件模块依赖不使用的接口。
ISP表明,我们应该编写可以被子类实现的一系列更小、更具体的接口。每个接口都提供单个行为。换句话说,许多特定的接口比一个通用的接口要好。
违反该原则时,软件模块将被迫实现其不使用的方法。此外,接口中方法签名的任何更改都会导致相关类的更改。这不利于模块之间的解耦。
问题
例如,您正在创建一个博客。您有不同类型的用户。
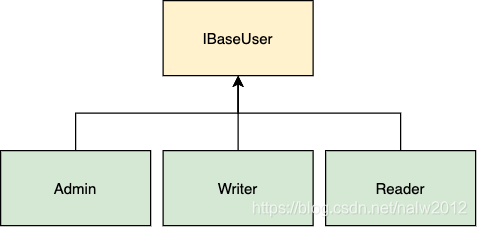
IBaseUser 是我们的通用接口。对于每种继承类,它都有一组通用方法。在我们的示例中,Admin 和 Writer 具有编辑博客文章的通用方法。但是读者不能————他们只能阅读帖子。另外,只有管理员可以屏蔽帖子。
interface IBaseUser {
viewPost(): void
editPost(): void
blockPost(): void
}
class Admin implements IBaseUser {
public viewPost() { ... }
public editPost() { ... }
public blockPost() { ... }
}
class Writer implements IBaseUser {
public viewPost() { ... }
public editPost() { ... }
public blockPost() {
throw new Error('writer can not block posts')
}
}
class Reader implements IBaseUser {
public viewPost() { ... }
public editPost() {
throw new Error('reader can not edit post!')
}
public blockPost() {
throw new Error('reader can not block posts')
}
}
Reader 和 Writer 类必须实现他们不使用的方法————因此,他们违反了ISP。
当业务发展时,其功能也会发展。新种类的用户添加后,也会带来与之相关的一组方法。我们的 IBaseUser 接口变得越来越复杂。实现 IBaseUser 的所有子类代码都相应增长。那么我们如何解决这个问题呢?
解决方案
我们可以通过接口拆分为独立的小接口来解决此问题。
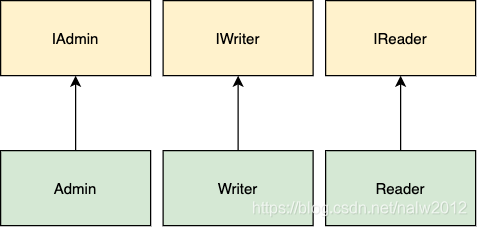
如果某个客户想要这两种行为,那么他们可以实现这两种接口。让我们看一下代码示例:
interface IReader {
readPost(): void
}
interface IWriter {
editPost(): void
}
interface IAdmin {
blockPost(): void
}
class Admin implements IReader, IWriter, IAdmin {
public viewPost() { ... }
public editPost() { ... }
public blockPost() { ... }
}
class Writer implements IReader, IWriter {
public viewPost() { ... }
public editPost() { ... }
}
class Reader extends IReader {
public viewPost() { ... }
}
遵循ISP可以降低开发和维护应用程序的复杂性。使用的接口越小越简单,它的实现子类消耗的资源就越少。
依赖反转原则(DIP)
上层模块不应该依赖于底层模块。两者都应该依赖抽象。抽象不应依赖细节。细节应取决于抽象。
提供具体功能的底层模块修改时,应不影响提供业务逻辑的上层模块。为此,我们需要引入一种抽象例如接口,使模块彼此分离。
DIP是严格遵循开闭原则和里氏替换原则的结果。
问题
例如,我们需要创建一个模块来接收用户,对用户的密码进行编码,然后将其保存在数据库中。让我们看一下图。
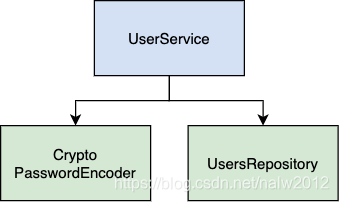
UserService 是我们的上层模块。它包含业务逻辑。它直接依赖于 CryptoPasswordEncoder 和 UsersRepository 这两个底层模块。
class UserService {
constructor() {
this.repository = new UsersRepository()
this.passwordEncoder = new CryptoPasswordEncoder()
}
public registerUser(data: RawUser): void {
const userEntity = new UserEntity({
email: data.email,
passwordHash: this.passwordEncoder.encode(data.password)
})
this.repository.save(userEntity)
}
}
class CryptoPasswordEncoder {
public encode(password: string): string { ... }
}
class UsersRepository {
public save(userEntity: UserEntity): void { ... }
}
但是这种设计看起来并不灵活。假设在安全审核之后,我们被要求使用更安全的库,例如crypto。
考虑到这一点,我们创建 BcryptPasswordEncoder 类并更改 UserService 构造方法。如果方法签名也被更改,我们还需要修改使用该模块的所有位置。
此外, 由于与 CryptoPasswordEncoder 和 UsersRepository 高度耦合,很难对 UserService 进行测试。
解决方案
正如DIP所说,我们的模块应该依赖抽象。一种好方法就是添加一个接口作为抽象。
interface IPasswordEncoder {
encode(password: string): string
}
interface IUsersRepository {
save(userEntity: UserEntity): void
}
class UserService {
constructor(repository: IUsersRepository, passwordEncoder: IPasswordEncoder) {
this.repository = repository
this.passwordEncoder = passwordEncoder
}
public registerUser(data: RawUser): void {
const userEntity = new UserEntity({
email: data.email,
passwordHash: this.passwordEncoder.encode(data.password)
})
this.repository.save(userEntity)
}
}
class BcryptPasswordEncoder implements IPasswordEncoder {
public encode(password: string): string { ... }
}
class UsersRepository implements IUsersRepository {
public save(userEntity: UserEntity): void { ... }
}
现在,我们的高级模块 UserService 依赖于两个抽象———— IPasswordEncoder 和 IUsersRepository。我们的 BcryptPasswordEncoder 和 UsersRepository 类实现了这些接口。
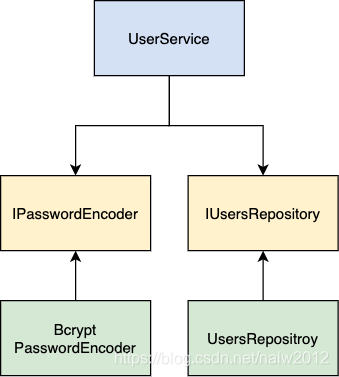
我们实现的最重要的事情就是依赖关系的倒置。我们底层模块的箭头指向另一个方向。因此,我们将 UserService 从 CryptoPasswordEncoder 和 UsersRepository 解耦。
每次我们需要更改第三方库或修改底层模块中的现有逻辑时,我们只需要遵循在接口中定义的约定即可。该接口必须由上层模块提供。
除此之外,遵循DIP会迫使我们注入依赖关系。在代码示例中,我们传递 repository 和 passwordEncoder 作为参数,通过 constructor 方法实现。这种方法简化了单元测试。
应用DIP可以使上层模块免受修改影响。因为这些模块包含业务逻辑,即应用程序的核心功能,因此避免在那里进行任何更改对我们非常有益。
结论
如您所见,所有这些原则均旨在简化软件维护和扩展。通过提供更精细的抽象,我们提高了应用程序的灵活性。
有了灵活性,我们就可以成功地应对可能改变需求的业务。
因个人能力和时间有限,文章难免有纰漏之处,如有发现,欢迎指正。














 475
475











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









