





初读Faster R-CNN
背景
目标检测的学习模型可分为两大块:
- one-stage,不生成候选区域,直接产生物体的类别与方位。例如:SSD与YOLO等。
- two-stage,先生成候选区域,再对候选进行分类。例如:R_CNN系列。
摘要
论文:《Faster R-CNN: Towards Real-Time ObjectDetection with Region Proposal Networks》
论文地址:https://arxiv.org/abs/1506.01497
代码开源:https://github.com/endernewton/tf-faster-rcnn
论文概况:
- 提出区域建议网络RPN(Region Proposal Network),快速生成候选区域。
- 在Fast R-CNN基础上,结合区域建议网络RPN。
目标检测相关发展线:
R-cnn->fastt R-cnn->faster R-cnn
| 使用方法 | 缺点 | 改进 | |
|---|---|---|---|
| R-CNN | 1.CNN提取特征; 2.SS提取RP; 3.SVM分类; 4.Bbox回归; | 1.训练步骤繁琐(微调网络+训练SVM+训练B box); 2.训练、测试均速度慢; 3.训练占空间; | 1.从DPM HSC的34.4%直接提升到了66%(mAP); |
| Fast R-CNN | 1.CNN提取特征; 2.SS提取RP;3.softmax分类; 4.多任务损失函数边框回归; | 1、.依旧用SS提取RP(耗时2-3s,特征提取耗时0.32s); 2.无法满足实时应用,没有真正实现端到端训练测试; 3. 利用了GPU,但是区域建议方法是在CPU上实现的。 | 1. 由66.9%提升到70%; 2.每张图像耗时约为3s。 |
| Faster R-CNN | 1.CNN提取特征; 2.RPN提取RP;3.softmax分类; 4.多任务损失函数边框回归。 | 1. 还是无法达到实时检测目标; 2. 获取region proposal,再对每个proposal分类计算量还是比较大。 | 1. 提高了检测精度和速度; 2.真正实现端到端的目标检测框架; 3. 生成建议框仅需约10ms。 |
(表格借鉴于:https://blog.csdn.net/qq_17448289/article/details/52871461)
R-CNN:
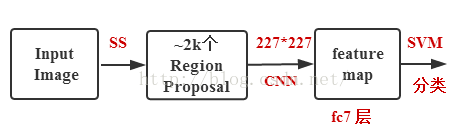
Fast R-CNN
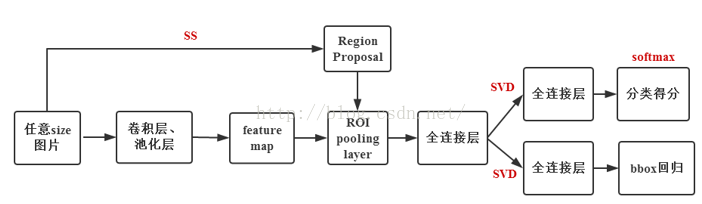
Faster R-cnn

引言
作者引入anchor作为多种尺度和长宽比的参考。与使用图像金字塔或滤波器金字塔相比,作者提出的方案可以认为是回归参考金字塔。避免了枚举多种比例或长宽比的图像或滤波器。有利于运行速度的提升。
解决多尺度与尺寸不同的情况有以下几种不同的方案:(a)构建图像和特征图的金字塔,分类器以多种尺度运行;(b)在特征图上运行多个比例(大小)的滤波器金字塔;©在回归函数中使用参考边界框金字塔。

Faster R-CNN组成

一、RPN
该模块为提议区域的深度全卷积网络,RPN模块告诉另一模块(Fast R-CNN)目标去那里寻找。
区域提议网络(RPN)以任意大小的图像作为输入,输出一组矩形的目标提议,每个提议都有一个目标得分。
为了使两个网络共享一组共同的卷积层,作者研究了具有五个共享卷积层的Zeiler和Fergus模型(ZF)和具有13个共享卷积层的Simonyan和Zisserman模型(VGG-16)。
为了生成区域提议,作者在共享卷积层最后输出的卷积特征映射上滑动一个小网络。这个小网络将输入卷积特征映射的n×n空间窗口作为输入。每个滑动窗口映射到一个低维特征(ZF为256维,VGG为512维,后面是ReLU)。这个特征被输入到两个子全连接层:一个边界框回归层(reg)和一个边界框分类层(cls)。作者采用n=3,对应到输入图像上的有效感受野是较大的(ZF和VGG分别为171和228个像素)。

图左展示了该小网络的一个位置,由于小网络以滑动窗口方式运行,所有空间位置共享全连接层。这种架构通过一个n×n卷积层,后面是两个1×1卷积层(分别用于reg和cls)来实现。
- 该网络是对VGG-16最后一层输出的卷积特征图(conv feature map)进行处理。
- 滑窗(sliding window):亦可看为卷积核,对图片所有区域进行处理。
- Intermediate layer(256-d):中间层括号中的为其维度(ZF为256维,VGG为512维)。
- Cls layer:边界框分类层,该层包含2k scores,输出2k个分数,对应是目标或不是目标的概率(下文中的Pi)。
- Reg layer:边界框回归层,包含4k coordinates即K个边界框的中心坐标与宽高(x,y,w,h)(下文中的Ti).
- K anchors boxes,相对于当前滑动窗口中心(anchors)的K个参考边界框,文中提及K为9。
二、Anchors
在每个滑动窗口位置,我们同时预测多个区域提议,其中每个位置可能提议的最大数目表示为K。因此,reg层具有4K个输出编码K个边界框的坐标,cls层输出2K个分数,估计每个提议是目标或不是目标的概率。相对于Anchors的K个参考边界框,K个提议是参数化的。Anchors位于所讨论的滑动窗口的中心,并与一个尺度和长宽比相关。默认情况下,我们使用3个尺度和3个长宽比,在每个滑动位置产生K=9个Anchors。对于大小为W×H(通常约为2400)的卷积特征映射,总共有W×H×K个Anchors。
Faster R-CNN中,有一个特性,即Anchors的平移不变性(当我们平移Anchors时,相对于Anchors的K个参考边界框也随之平移)。

Anchors可以根据目标特点做出不同的设计,经试验Faster R-CNN采用了Anchors scale(规模)={128×128,256×256,512×512},aspect ratios(横纵比)={2:1,1:1,1:2}。下图显示了Anchors在不同尺度和长宽比的能力。但是由于Anchors是固定大小的,所以,对于一些特殊物体需要制定不同的Anchors。
Anchors如下所示:

下表为ZF网络的每个锚点学习到的平均提议大小(短边s=600),作者将所有跨界的Anchor进行忽略处理。

为了减少RPN中的提议区域高度重叠,在提议区域根据cls分数采取非极大值抑制(NMS),作者将IOU阈值定为0.7,则图片留下大约2000个提议区域。采用这些RPN建议对Fast R-CNN进行训练。
三、损失函数
为了训练RPN,作者为每个Anchor分配一个二值类别标签(是目标或不是目标)。并给两种锚点分配一个正标签:(i)具有与实际边界框的重叠最高交并比(IoU)的Anchor,或者(ii)具有与实际边界框的重叠超过0.7 IoU的Anchor。单个真实边界框可以为多个Anchor分配正标签。通常第二个条件足以确定正样本;但我们仍然采用第一个条件,因为在一些极少数情况下,第二个条件可能找不到正样本。对于所有的真实边界框,如果一个Anchor的IoU比率低于0.3,我们给非正样本的Anchor分配一个负标签。既不正面也不负面的锚点不会有助于训练目标函数。
损失函数定义为:
L
(
{
p
i
}
,
{
t
i
}
)
=
1
N
c
l
s
∑
i
L
c
l
s
(
p
i
,
p
i
∗
)
+
λ
1
N
r
e
g
∑
i
p
i
∗
L
r
e
g
(
t
i
,
t
i
∗
)
\begin{array}{c}{L\left(\left\{p_{i}\right\},\left\{t_{i}\right\}\right)=\frac{1}{N_{c l s}} \sum_{i} L_{c l s}\left(p_{i}, p_{i}^{*}\right)}{+\lambda \frac{1}{N_{r e g}} \sum_{i} p_{i}^{*} L_{r e g}\left(t_{i}, t_{i}^{*}\right)}\end{array}
L({pi},{ti})=Ncls1∑iLcls(pi,pi∗)+λNreg1∑ipi∗Lreg(ti,ti∗)
i : 小 批 量 数 据 中 A n c h o r 的 索 引 p i : A n c h o r i 对 应 是 否 为 目 标 的 概 率 p i ∗ : 真 实 标 签 , 如 果 A c n c h o r 为 正 , p i ∗ 为 1 , 为 负 , p i ∗ 为 0 t i : 预 测 边 界 框 四 个 参 数 坐 标 的 向 量 ( x , y , w , h ) t i ∗ : 真 实 边 界 框 四 个 参 数 坐 标 的 向 量 ( x , y , w , h ) i:小批量数据中Anchor的索引\\ p_i:Anchor i对应是否为目标的概率\\ p_i^*:真实标签,如果Acnchor为正,p_i^*为1,为负,p_i^*为0\\ t_i:预测边界框四个参数坐标的向量(x,y,w,h)\\ t_i^*:真实边界框四个参数坐标的向量(x,y,w,h)\\ i:小批量数据中Anchor的索引pi:Anchori对应是否为目标的概率pi∗:真实标签,如果Acnchor为正,pi∗为1,为负,pi∗为0ti:预测边界框四个参数坐标的向量(x,y,w,h)ti∗:真实边界框四个参数坐标的向量(x,y,w,h)
L c l s : 对 于 两 个 类 别 ( 目 标 与 不 是 目 标 ) 的 对 数 损 失 如 下 : L c l s ( p i , p i ∗ ) = − log [ p i ∗ p i + ( 1 − p i ∗ ) ( 1 − p i ) ] L_{cls}:对于两个类别(目标与不是目标)的对数损失如下:\\ L_{c l s}\left(p_{i}, p_{i}^{*}\right)=-\log \left[p_{i}^{*} p_{i}+\left(1-p_{i}^{*}\right)\left(1-p_{i}\right)\right]\\ Lcls:对于两个类别(目标与不是目标)的对数损失如下:Lcls(pi,pi∗)=−log[pi∗pi+(1−pi∗)(1−pi)]
L r e g ( t i , t i ∗ ) : 边 界 框 回 归 损 失 , 采 用 L r e g ( t i , t i ∗ ) = R ( t i − t i ∗ ) ; R 为 r o b u s t l o s s f u n c t i o n ( s m o o t h L 1 ) : smooth L 1 ( x ) = { 0.5 x 2 if ∣ x ∣ < 1 ∣ x ∣ − 0.5 otherwise L_{reg}(t_i,t_i^*):边界框回归损失,采用L_{r e g}\left(t_{i}, t_{i}^{*}\right)=R\left(t_{i}-t_{i}^{*}\right);R为robust loss function(smooth L_1):\\ \operatorname{smooth}_{L_{1}}(x)=\left\{\begin{array}{ll}{0.5 x^{2}} & {\text { if }|x|<1} \\ {|x|-0.5} & {\text { otherwise }}\end{array}\right.\\ Lreg(ti,ti∗):边界框回归损失,采用Lreg(ti,ti∗)=R(ti−ti∗);R为robustlossfunction(smoothL1):smoothL1(x)={0.5x2∣x∣−0.5 if ∣x∣<1 otherwise
p i ∗ L r e g : 回 归 损 失 仅 在 A n c h o r 为 正 时 激 活 , 否 则 不 对 其 进 行 考 虑 。 p_{i}^{*}L_{reg}:回归损失仅在Anchor为正时激活,否则不对其进行考虑。 pi∗Lreg:回归损失仅在Anchor为正时激活,否则不对其进行考虑。
该 公 式 中 c l s 项 由 m i n i − b a t c h 大 小 ( N c l s = 256 ) 进 行 归 一 化 , r e g 项 由 A n c h o r s 数 量 ( N r e g 24000 ) 进 行 归 一 化 默 认 情 况 下 采 用 λ = 10 的 情 况 。 此 时 c l s 与 r e g 的 权 重 大 致 相 同 。 该公式中cls项由mini-batch大小(N_{cls}=256)进行归一化,reg项由Anchors数量(N_{reg}~24000)进行归一化\\默认情况下采用\lambda=10的情况。此时cls与reg的权重大致相同。 该公式中cls项由mini−batch大小(Ncls=256)进行归一化,reg项由Anchors数量(Nreg 24000)进行归一化默认情况下采用λ=10的情况。此时cls与reg的权重大致相同。
作 者 经 实 验 , 发 现 对 宽 范 围 的 λ 值 不 敏 感 ( 如 下 表 ) , 且 上 述 归 一 化 过 程 非 必 需 , 可 以 进 行 简 化 。 作者经实验,发现对宽范围的\lambda值不敏感(如下表),且上述归一化过程非必需,可以进行简化。 作者经实验,发现对宽范围的λ值不敏感(如下表),且上述归一化过程非必需,可以进行简化。

对于边界框回归,可采用下述公式进行:
t
x
=
(
x
−
x
a
)
/
w
a
,
t
y
=
(
y
−
y
a
)
/
h
a
t
w
=
log
(
w
/
w
a
)
,
t
h
=
log
(
h
/
h
a
)
t
x
∗
=
(
x
∗
−
x
a
)
/
w
a
,
t
y
∗
=
(
y
∗
−
y
a
)
/
h
a
t
w
∗
=
log
(
w
∗
/
w
a
)
,
t
h
∗
=
log
(
h
∗
/
h
a
)
\begin{array}{cl}{t_{\mathrm{x}}=\left(x-x_{\mathrm{a}}\right) / w_{\mathrm{a}},} & {t_{\mathrm{y}}=\left(y-y_{\mathrm{a}}\right) / h_{\mathrm{a}}} \\ {t_{\mathrm{w}}=\log \left(w / w_{\mathrm{a}}\right),} & {t_{\mathrm{h}}=\log \left(h / h_{\mathrm{a}}\right)} \\ {t_{\mathrm{x}}^{*}=\left(x^{*}-x_{\mathrm{a}}\right) / w_{\mathrm{a}},} & {t_{\mathrm{y}}^{*}=\left(y^{*}-y_{\mathrm{a}}\right) / h_{\mathrm{a}}} \\ {t_{\mathrm{w}}^{*}=\log \left(w^{*} / w_{\mathrm{a}}\right),} & {t_{\mathrm{h}}^{*}=\log \left(h^{*} / h_{\mathrm{a}}\right)}\end{array}
tx=(x−xa)/wa,tw=log(w/wa),tx∗=(x∗−xa)/wa,tw∗=log(w∗/wa),ty=(y−ya)/hath=log(h/ha)ty∗=(y∗−ya)/hath∗=log(h∗/ha)
x , y , w , h 分 别 表 示 边 界 框 的 中 心 坐 标 及 其 宽 和 高 x , x a , x ∗ 分 别 代 表 预 测 边 界 框 , A n c h o r 与 实 际 边 界 框 ( y , w , h 与 此 类 似 ) x,y,w,h分别表示边界框的中心坐标及其宽和高\\ x,x_a,x^*分别代表预测边界框,Anchor与实际边界框(y,w,h与此类似) x,y,w,h分别表示边界框的中心坐标及其宽和高x,xa,x∗分别代表预测边界框,Anchor与实际边界框(y,w,h与此类似)
四、RPN和Fast R-CNN共享特征
由于独立训练的RPN与Fast R-CNN是通过不同的方式对卷积层进行修改,所以作者讨论三种方法来训练具有共享特征的网络:
4.1交替训练
训练RPN,并采用它的proposals去训练Fast R-CNN。由Fast R-CNN微调后再用以初始化RPN,并且重复该过程。
4.2近似联合训练
RPN和Fast R-CNN网络在训练期间合并成一个网络,每次SGD迭代中,前向传播生成Region proposals,在训练Fast R-CNN时,将这些建议看做固定的,提前计算好的建议。反向传播不变。对于共享的部分,组合来自RPN损失和Fast R-CNN损失的反向传播信号。
4.3非近似的联合训练
由于RPN预测的边界框也是输入的函数,Fast R-CNN中的RoI池化层接受卷积特征以及预测的边界框作为输入,所以在反向传播中应该包含边界框的坐标的梯度,但是在近似联合训练中,该梯度被忽略。在非近似的联合训练中,需要加一个关于边界框坐标可微分的ROI pooling。
在该论文中,作者采用四步训练算法,通过交替优化学习共享特征。
- 通过反向传播与随机梯度下降(SGD)进行端对端的训练,遵循“image-centric“(以图像为中心)的采样策略来训练这个网络。在图像中随机采样256个Anchors,计算一个小批量数据的损失函数,其中采样的positive Anchor和negative Anchor的比率可达1:1。如果图像中的正样本少于128个,使用负样本填充小批量数据。该网络使用lmageNet的预训练模型进行初始化,并针对区域提议进行端到端的微调。
- 使用1中RPN生成的提议,由Fast R-CNN训练单独的检测网络。,该检测网络也用ImageNet的预训练模型进行初始化,此时两个网络不共享卷积层。
- 使用检测器网络来初始化RPN训练,此时将这两个网络卷积层共享,保持共享部分不变,只微调RPN的独有层。
- 保持两个网络共享卷积层共享部分不变,只微调Fast R-CNN的独有层。
五、细节
作者在单尺度图像上训练和测试区域提议(RPN)与目标检测网络.作者对图像进行缩放到短边为s=600的像素,使用图像金字塔可以提升精度,但是时间损耗也相对较高。
实验
1.PASCAL VOC
这个数据集包含大约5000张训练评估图像和在20个目标类别上的5000张测试图像。
对于ImageNet预训练网络,作者使用具有5个卷积层和3个全连接层的ZF网络的Fast R-CNN以及具有13个卷积层和3个全连接层的公开的VGG-16模型
下表上表格是使用各种区域提议方法进行训练和测试的Fast R-CNN的结果。下表格为消融实验结果。
ss:选择性搜索
EB:EdgeBoxes

下表为各网络的运行时间:(ss是在CPU上进行评估,其他是在GPU上进行)

PASCAL VOC 2007测试集的检测结果。检测器是Fast R-CNN和VGG-16:
07:VOC 2007 trainval
07+12:VOC 2007 trainval和VOC 2012 trainval的联合训练集

PASCAL VOC 2012测试集的检测结果。检测器是Fast R-CNN和VGG-16:
07:VOC 2007 trainval
07+12:VOC 2007 trainval和VOC 2012 trainval的联合训练集

使用Fast R-CNN检测器和VGG-16在PASCAL VOC 2007测试集上的结果:
R P N ∗ 表 示 没 有 共 享 特 征 的 版 本 RPN^*表示没有共享特征的版本 RPN∗表示没有共享特征的版本

使用Fast R-CNN检测器和VGG-16在PASCAL VOC 2012测试集上的结果:

IOU召回率
通过实际边界框来计算不同IoU比率的提议召回率以及IOU重叠率如下:(基于PASCAL VOC 2007测试集)

2.在MS COCO上的实验
这个数据集包含80个目标类别。作者用训练集上的8万张图像,验证集上的4万张图像以及测试开发集上的2万张图像进行实验。
作者的系统对该数据集进行了一些改动,将8 GPU上训练模型,每个GPU上一个RPN,两个Fast R-CNN,该情况下的有效最小批量大小为8个。RPN步骤和Fast R-CNN步骤都以24万次迭代进行训练。learning rate采用0.003,然后再用0.0003的learning rate进行8万次迭代。Anchor采用3个长宽比和4个尺度(加上64×64为了处理小目标),负样本定义为与实际边界框的最大IOU在[0,0.5)区间内的样本。其余的实现细节与PASCAL VOC相同。
在MS COCO数据集上的目标检测结果(%)。模型是VGG-16。

注释:
-
Rol(Regions of interest)感兴趣区域
-
SS(Selective Search)选择性搜索
-
SVD(Singular Value Decomposition)奇异值分解
-
RPN(Region Proposal Network)区域建议网络
详情可入群询问283266234。
若本人对文章解读有所误解与不足处,还望斧正。














 13万+
13万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









