







一、HDFS体系结构
HDFS作为分布式文件系统,使用的是master/slave体系结构,角色有三种:
NameNode:为HDFS提供元数据服务,NameNode可以控制所有文件的操作,它会把所有的文件元数据存储在文件系统树中,文件信息在硬盘上保存成两个文件:命名空间镜像文件(fsimage)和修改日志文件(edit log)。此外,NameNode还保存一个文件,用来存储数据块在数据节点的分布情况。系统启动之时,这些信息会加载到内存中。
DateNode:为HDFS提供存储,为系统提供存储服务,用于保存数据。
客户端Client:HDFS客户端节点。
还有一个Secondary NameNode,它并不是NameNode的备份,其职责是合并NameNode中的edit log和fsimage,协助NameNode工作,可以称为是检查节点。具体参考(Secondary NameNode:它究竟有什么作用?)
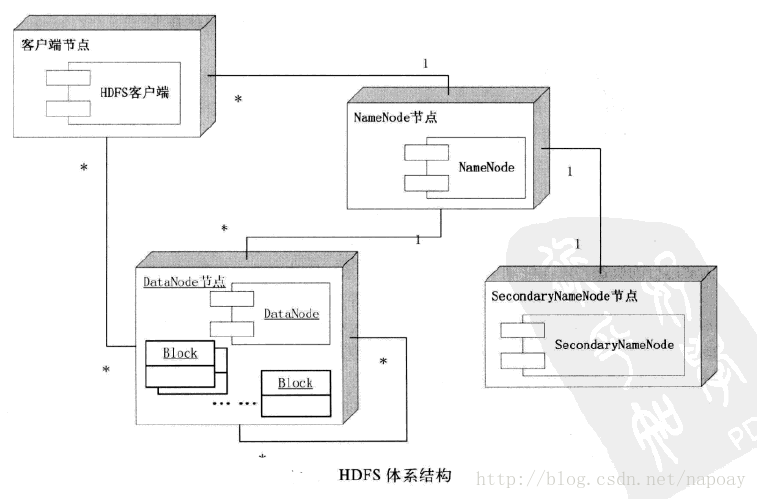
HDFS中的文件块:HDFS基本存储单位是64M的数据块,每个文件被分成64M大小的数据块来存储。小于数据块大小的文件,不会占用整个数据块存储空间。
二、客户端文件读取流程
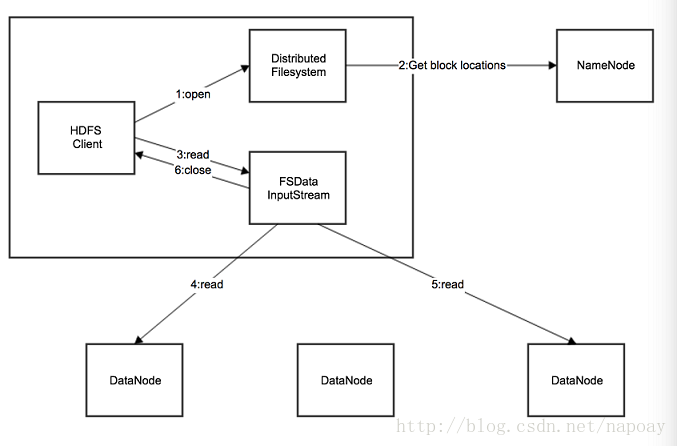
HDFS客户端文件读取过程如下:
- 应用程序通过HDFS客户端向NameNode发生远程调用请求。
- NameNode收到请求之后,返回文件的块列表信息。块列表信息中包含每个block拷贝的datanode地址。
- HDFS 客户端会选择离自己最近的那个拷贝所在的datanode来读取数据。
- 数据读取完成以后,HDFS客户端关闭与当前的datanode的链接。
如果文件没有读完,HDFS客户端会继续从NameNode获取后续的block信息,每读完一个块都需要进行校验和验证,如果读取出错,HDFS客户端会通知NameNode,重新选择一个该block拷贝的datanode读数据。
三、客户端文件写入流程
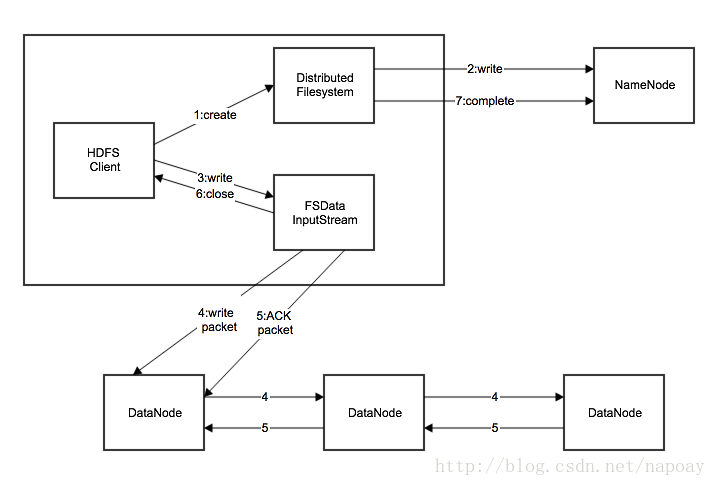
1.应用程序通过HDFS客户端向NameNode发起远程过程调用请求。
2.NameNode检查要创建的文件是否存在以及是否有足够的权限。
3.如果检测成功,NameNode会返回一个该文件的记录,否则让客户端抛出异常。
4.HDFS客户端把文件切分为若干个packets,然后向NameNode申请新的blocks存储新增数据。
5.NameNode返回用来存储副本的数据节点列表。
6.HDFS客户端把packets中的数据写入所有的副本中。
7.最后一个节点数据写入完成以后,客户端关闭。















 6065
6065











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











