






1.选取最优特征
··classList=[example[-1] for example in dataSet] # 类别
··if classList.count(classList[0])==len(classList):
·· return classList[0]
··if len(dataSet[0])==1:
·· return majorityCnt(classList)
··bestFeat=chooseBestFeatureToSplit(dataSet) #选择最优特征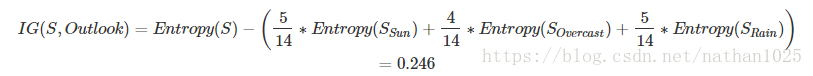
def chooseBestFeatureToSplit(dataSet): # 选择最优的分类特征
numFeatures = len(dataSet[0])-1
baseEntropy = calcShannonEnt(dataSet) # 原始的熵
bestInfoGain = 0
bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet,i,value)
prob =len(subDataSet)/float(len(dataSet))
newEntropy +=prob*calcShannonEnt(subDataSet) # 按特征分类后的熵
infoGain = baseEntropy - newEntropy # 原始熵与按特征分类后的熵的差值
if (infoGain>bestInfoGain): # 若按某特征划分后,熵值减少的最大,则次特征为最优分类特征
bestInfoGain=infoGain
bestFeature = i
return bestFeature即 有该特征的某一值的条路/总条数 * 该具体特征的香农熵
2. 然后分叉构建子树
featValues=[example[bestFeat] for example in dataSet]
uniqueVals=set(featValues)
for value in uniqueVals:
subLabels=labels[:]
myTree[bestFeatLabel][value]=createTree(splitDataSet\
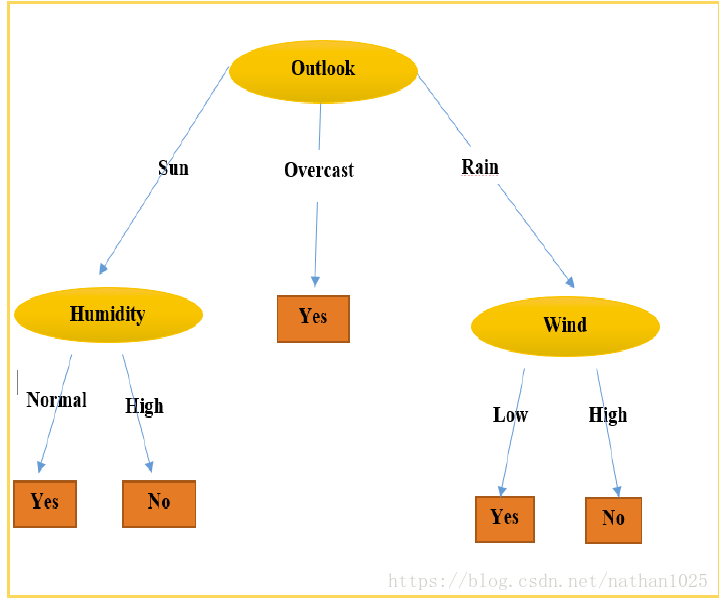
(dataSet,bestFeat,value),subLabels)类似于第一次下图天气为最佳特征,然后有三value,分别构造子树。














 2392
2392











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









