






前言
前段时间忙双11忙到废寝忘食,这期间又被各种奇奇怪怪的小病折腾了半个多月,整个人状态不是很好,博客也连续吃灰到现在,请看官勿怪。好在今天感觉还不错,可以继续写点东西了。
为了应对业务数据的爆炸性增长以及MySQL业务库分库分表现状的各种不便,笔者的团队近期用一周时间突击调研TiDB,并部署了由16个节点组成的TiDB集群,同时开始逐渐探索利用它替代MySQL的可能性。在调研过程中,我们了解到TiDB能够100%支持ACID事务。并且不同于传统的XA,TiDB采用的是Google提出的Percolator分布式事务协议。本文聊一聊Percolator的部分细节,之后的文章再说它在TiDB事务(包括乐观事务和悲观事务)中的具体应用。
从Bigtable跨行事务到Percolator
Bigtable是Google实现的分布式结构化大数据存储系统,我们耳熟能详的HBase就是Bigtable的开源版本实现。其数据模型可以视为多维的、支持MVCC的K-V Map,即:
(row:string, column:string, timestamp:int64) -> data:string
Bigtable原生支持单行事务,即能够保证一行内一个或多个列族上的多个操作的ACID特性。但是,很多情况下用户都需要在单个事务中更改多行数据,只有单行事务显然不够用。而基于Bigtable的分布式特性,跨行事务与单行事务相比更加复杂,需要注意的三个要点列举如下:
- 必须有精准的全局授时服务,消除服务器之间时钟无法严格同步的影响,从而保证事务的顺序不会错乱;
- 必须有高效的全局锁机制,保证两个并发的事务不能同时修改一行数据,并且避免事务出现死锁;
- 必须高效,在实现ACID语义的基础上不能影响原有系统的吞吐量与并发度。
在这三个要点的基础上,Google的大佬们又设计了Percolator分布式事务协议,借助Bigtable原生的单行事务实现了跨行事务。Percolator的设计理念集中体现在OSDI 2010的一篇论文《Large-scale Incremental Processing Using Distributed Transactions and Notifications》中。下图示出启用Percolator之后的Bigtable服务架构。
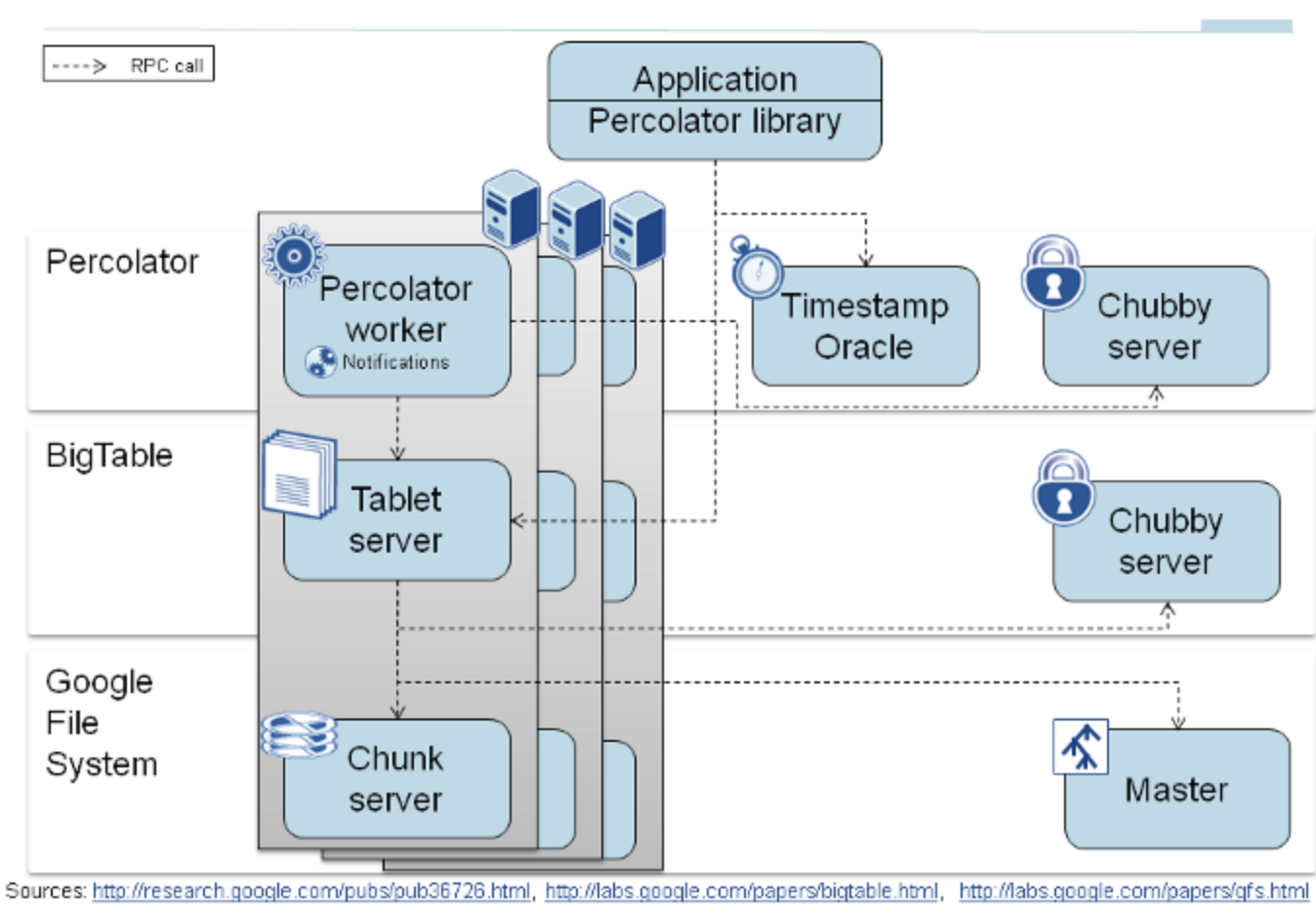
Bigtable依靠Chubby(等同于ZooKeeper)提供分布式协调服务。图中的每一个大矩形表示一台服务器,其上运行的服务包括Tablet Server(等同于HBase RegionServer)、Chunk Server(等同于HDFS DataNode),以及新加入的Percolator Worker。另外,还引入了Timestamp Oracle(简称TSO)作为全局授时服务。也就是说,Percolator的实现仅需要增加2个服务,以及在客户端提供与Percolator协议兼容的库。
Percolator事务流程
Percolator事务分为两个阶段:预写(Pre-write)和提交(Commit),本质上相当于一个加强的2PC。另外,所有启用了Percolator事务的表中,每一个列族都会预先增加两个列,分别是:
- lock:存储事务过程中的锁信息;
- write:存储当前行可见(最近一次提交)的版本号。为了避免混淆,在这里不将其称为时间戳。
另外,为了简化场景,假设存储用户数据的列只有一个,名为data。
预写阶段
- 客户端启动事务,从TSO获取时间戳,记为start_ts,并向Percolator Worker发起Pre-write请求。
- 在该事务包含的所有写操作中选取一个作为主(primary)操作,其余的作为次(secondary)操作。主操作将作为整个事务的互斥点,标记事务的状态。
- 先预写主操作,成功后再预写次操作。
在预写过程中,对每一个写操作都要执行检查:
- 检查写入的行对应的write列版本号是否晚于start_ts,如果是,说明有版本冲突,直接取消整个事务;
- 检查写入的行对应的lock列是否有锁,如果有,说明其他事务正在写,直接取消整个事务。
- 检查通过后,以start_ts作为版本号将数据写入data列,但不更新write列,亦即此时写入的数据仍然不可见。
- 对操作行加锁,即更新lock列的锁信息:主操作行的lock直接标为primary,次操作行的lock则标为主操作行的行键和列名。
注意:处理每一行时,上述步骤3、4、5每次都会在同一个Bigtable单行事务中进行,保证原子性。
提交阶段
- 客户端从TSO获取时间戳,记为commit_ts,并向Percolator Worker发起Commit请求。
- 检查主操作行对应的lock列所在的primary标记是否存在,如果不存在(可能已经被清理,见后文所述)则失败,取消事务;如果存在则继续。
- 以commit_ts作为版本号,将start_ts更新到write列中。也就是说在本阶段完成后,预写阶段写入的数据将会可见。
- 对该行解锁,即删除lock列的锁信息。
- 若步骤1~4均成功,说明主操作行成功,代表整个事务实际上已经提交。接下来只需异步地提交每个次操作即可,即重复步骤3、4的更新write列和清除lock列操作。
注意:上述步骤2、3、4会在同一个Bigtable单行事务中进行,保证原子性。另外,如果次操作的提交失败,则仍然要回滚事务。
示例:经典转账流程
下图来自原始论文,描述了Percolator协议下的一次转账流程(Bob向Joe转账$7)。注意每一列中冒号之前的是版本号,冒号之后的则是该列存储的数据。附带的说明清楚易懂,笔者就不多废话了。

要点简析
快照隔离级别
传统关系型数据库中定义的隔离级别有4种(RU、RC、RR、S),而Percolator提供的隔离级别是快照隔离(Snapshot Isolation, SI),它也是与MVCC相辅相成的。SI的优点是:
- 对于读操作,保证能够从时间戳/版本号指定的稳定快照获取,不会发生幻读;
- 对于写操作,保证在多个事务并发写同一条记录时,不会有多于一个事务提交成功。
SI下的事务都会带有两个时间戳,即上文讲解Percolator流程时提到的start_ts(下图中空心方块)与commit_ts(下图中实心圆点)。SI硬性要求一个事务提交时的commit_ts大于所有之前产生的start_ts和commit_ts,当然这已经由TSO来保证了。
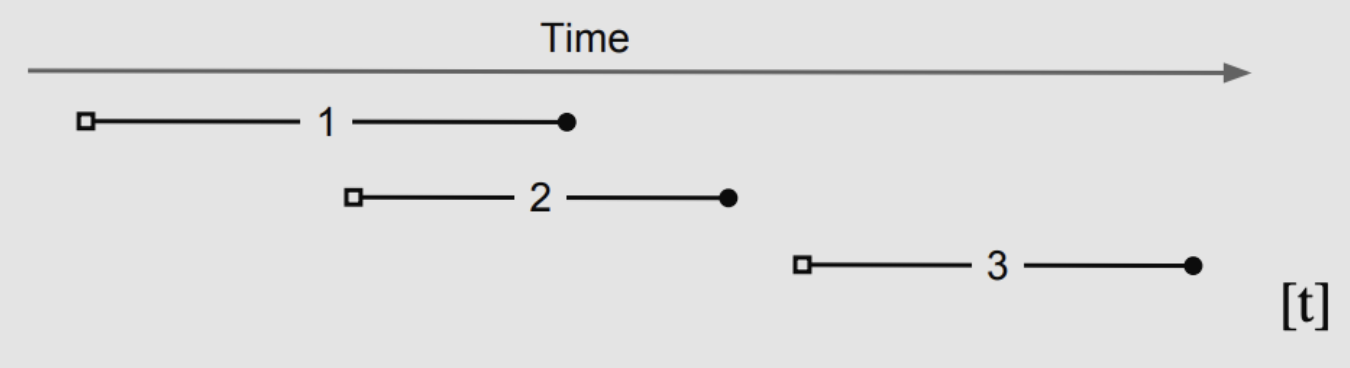
看图说话:
- 因为start_ts[2] < commit_ts[1],所以事务1的结果对事务2不可见;
- 因为start_ts[3] > commit_ts[2] > commit_ts[1],所以事务1和2的结果都对事务3可见;
- 如果事务1和2写了同一条记录,那么1和2中至少有一个会失败。
SI存在的主要问题是写偏斜(Write-skew),看官可自行查找资料去了解,不再赘述。
分散的锁机制
由上文的描述可以看出,Percolator巧妙地反其道而行之,把事务相关的锁信息分散到了每一行中,并通过将主操作作为互斥点,免去了重新设计一套全局锁机制的麻烦。另外,预写阶段的步骤3中检查到任意锁冲突都会取消事务,简单粗暴地避免了死锁的发生。最后,Percolator构建在带冗余的分布式文件系统(论文的语境中是GFS)之上,所以不必担心锁信息会丢失。
快照读与锁清理
相对于写流程,读流程就简单很多了:从TSO获取当前start_ts,然后检查lock列,判断早于当前start_ts的区间内是否有锁。如果没有,则从write列中根据commit_ts获取到最新提交的start_ts,再根据获取到的start_ts从data列中获取数据。如果有锁,则意味着存在未提交的事务,需要等待持锁的事务提交,才能读取最新的数据。读流程也是在Bigtable单行事务中进行的。
这里会产生两个问题:
- 第一,为什么不能在有冲突时直接返回版本号小于当前start_ts的最新版本数据?
很显然,基于持锁事务结果的不确定性(可能提交也可能回滚),这样会打破SI对读操作的保证,亦即产生幻读。看官稍稍思考一下即可理解。
- 第二,如果客户端崩溃或者失联,导致它发起的事务的锁遗留下来,读操作一直不能成功,该怎么办?
答案是由读操作来自主完成,即不会无限等待下去,而是在一定时长的延迟之后直接将卡住的主操作锁信息清理掉,并读取最新版本的数据。
分两种情况讨论:其一,读操作直接读到了原事务中具有primary锁信息的行,说明原事务未提交成功,需要回滚(即清理锁);其二,读操作读到了原事务中具有secondary锁信息的行,此时仍然要去对应的primary行上查找锁是否存在,如果存在,说明原事务未提交成功,将其回滚;如果不存在,说明已提交成功,将其前滚(即清理锁的同时更新对应的write列)。
可见,主操作锁和从操作锁存在的紧密关联能够有效保证Percolator事务的安全性与活性,即:同一事务中的任意两个写操作结果肯定一致,且所有操作的结果要么是提交成功,要么是提交失败。
客户端的作用
如果套用2PC的概念,客户端(在TiDB内部是tikv-client)显然扮演了协调者(Coordinator)的角色。传统2PC的协调者存在单点问题,但是Percolator中的客户端并没有此问题——就算客户端失败,事务也只会有成功与失败两种状态,不会破坏一致性。
有缺点么?
当然有。
- 网络I/O和RPC的负载较大,事务预写成本较高;
- 依靠读操作清理锁,如果清理不及时,会增加其他正常事务写冲突的概率;
- Percolator锁的本质为乐观锁,如果大量事务并发写热点数据,则根本无法阻塞,造成回滚风暴。
- 考虑另一个场景:有一个大事务和很多小事务,且它们的热点overlap,那么大事务可能受小事务的影响进入饥饿状态(即很长时间内无法执行)。为了克服该问题,TiDB提出了悲观事务模型,不过这就是后话了。
The End
写了这么多,似乎找回一点手感了,2020年剩下的这二十多天慢慢恢复更新吧。
民那晚安晚安。














 264
264











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









