









欢迎转载,转载请注明出处:
第二部分总结
这一部分主要讲了四个对NLP方面效果比较好的模型:1.GRUs(Gated Feedback Recurrent Neural Networks) 2.LSTMs(Long Short-Term Memory]) 3.Recurrent neural network 4.Recursive neural network
语言模型就是计算一串单词是否是“合理”、“正确”的一串单词的概率。
这个东东很有用哦。1.在机器翻译方面,我们都知道不同语言的语序可能会不一样,日本人说中文常常会说成“你的什么的干活”这种形式。这就犯了一个使用日语语法,但是使用中文单词的错误。2.在单词的选择方面也很有用处,还是上一个例子“你的什么的干活”如果地道的中国人说应该是“你是做什么的”。如果语言模型合理的话P("你的什么的干活")会小于P(“你是做什么的”),以上两个就是LM的最广泛的用处。
以上四个models是近些年才被人广泛引起重视的models,在广泛重视这四个models之前还有使用过其他的language models如果学过PGM(概率图模型)的朋友一定知道,之前使用的语言模型现今大多被称作Traditional language models而在TLM里最著名的就是基于Markov assumption的models。
这种模型常用的是unigrams和bigrams也就是只基于之前的一个或者两个单词。
Recurrent neural network
Recurrent NN很符合人们对语言的简单认识,人们不论是说话还是写作都是顺序的(sequence)把一串文字说出来,Recurrent NN就试图模拟这个过程。
而且和传统语言模型不同的是理论上Recurrent NN中某一个单词出现的概率是会基于之前所有单词的概率的。
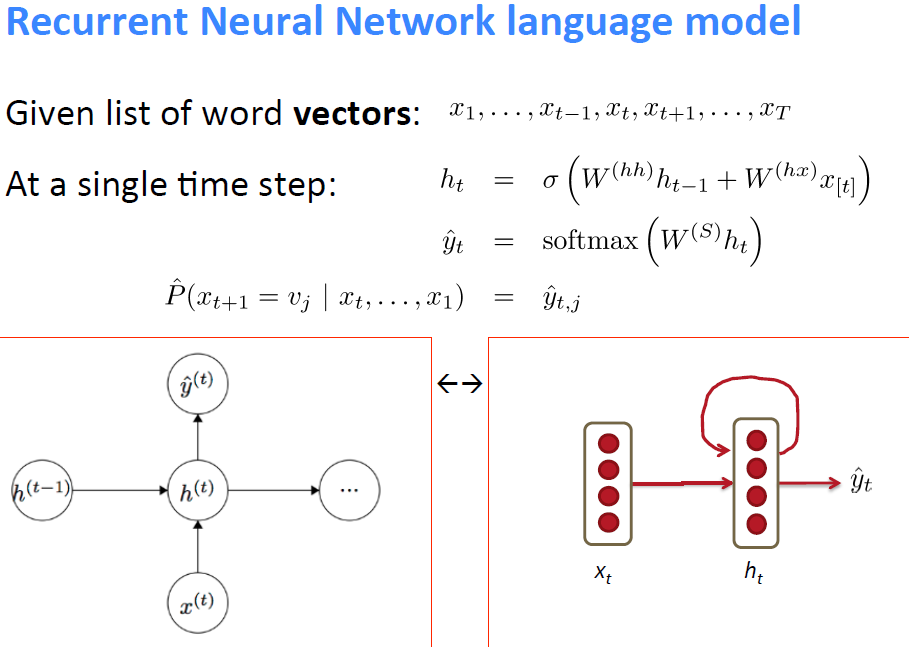
上图就是Recurrent NN的一个通用的(temporal)模块,把这么一个模块向左或者向右可以无限延伸,也就构成了一个language model
Recurrent NN的调优
NN存在两个固有的问题,一个是vanishing,另一个是exploding。
这两个问题其实在很小的NN中也存在只是Recurrent NN非常的长这两个问题也就凸显的比较明显罢了。
下面说说对于这两种问题的处理方法:
vanishing
vanishing顾名思义就是error rate从之前的node传下来的越来越小以至于之前的node的更新速度非常慢,理论上这个model在无限长的时间内肯定能够调优,但是我们有可能没有那么多的数据,也没有那么多的时间。
1.解决方法就是从问题的症结处入手。error从上一node传下来如果本node的|weight| < 1的话那么下一层得到的error就会比这一层的小,鉴于此我们在初始化weight的时候先把所有的weight都初始化为identity matrix
2.error从上一node传下来如果本node的|non-linear| < 1的话那么下一层得到的error也会比这一层的小,鉴于此我们使用Relu unit作为non-linear unit这样error在通过non-linear unit的时候就不会衰减。
exploding
之前介绍的是vanishing的情况,vanishing出现的机率要大一些,但是有时候也会出现error exploding的情况。
这样的话就会使得node里的weight在调优的时候幅度(scale)过大适得其反了。
我们使用clipping trick来处理这种情况。

一旦超过threshold就clip,以此来防止gradient的步幅过大
threshold一般选择范围是3~5。
Recurrent NN的一种改进措施
在softmax处改进
在Basic图里我们计算y_hat的时候用到了softmax,softmax在词库(vocabulary)很大的时候计算的cost是很大的。由此在这方面入手提出改进措施。
可以在word和预测的history之间增添一个class。class的数目肯定就比vocabulary的数目小很多了。然后在算p(w_t | c_t)这样就能在不显著降低performance的情况下大幅度提高运算速度。
在模型本身改进
这里讲讲在模型本身改进model的方法,前面的recurrent NN是最简单最原始的recurrent NN显然它所能达到的精确度不能达到人们的要求。追究其原因就是因为它所能提取出的信息太少了。于是我们把模型改造的复杂一些使它能提取出更多的信息。
有两种改良的措施第一种是Bidirectional RNNs就是你当前的单词是什么不仅仅取决于你之前的单词,还取决于你之后的单词。第二种是Deep Bidirectional RNNs就是能够更多的提取出信息。测试结果是使用Deep Bidirectional RNNs效果更好。
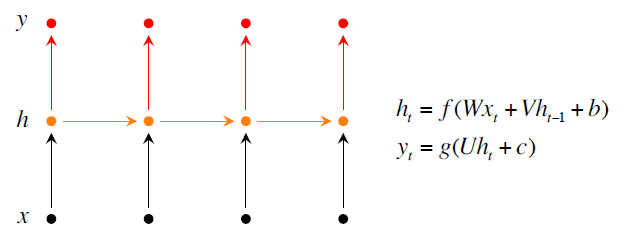
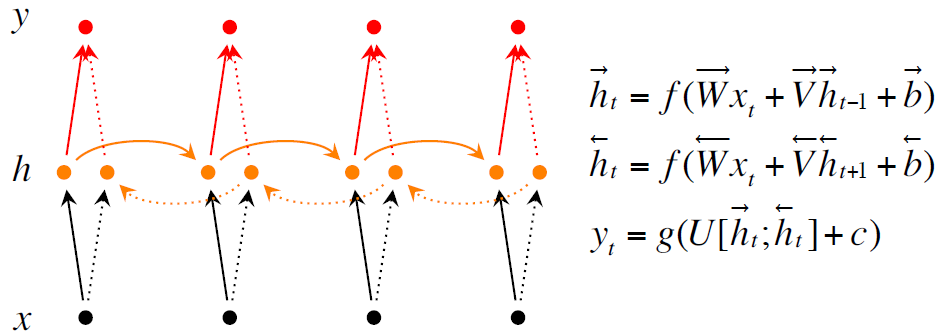
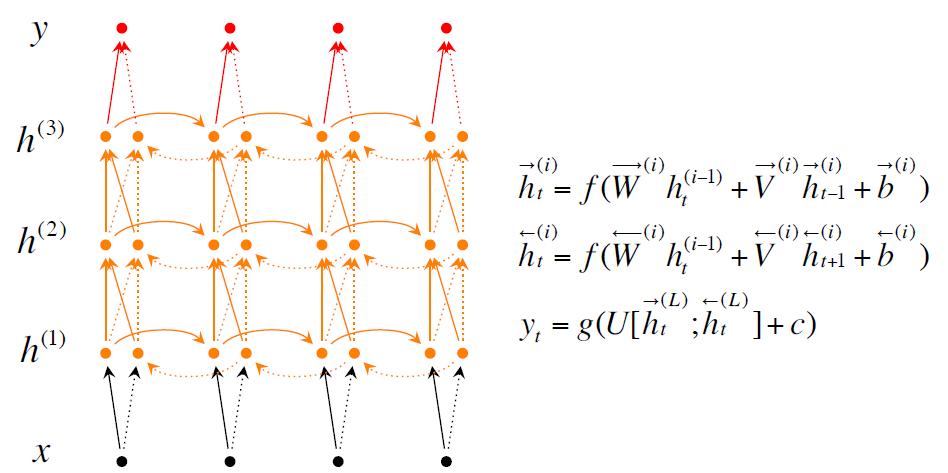
上面三张图分别是普通的Recurrent NN, Bidirectional RNNs, Deep Bidirectional RNNs
Recurrent NN在MT方面的应用
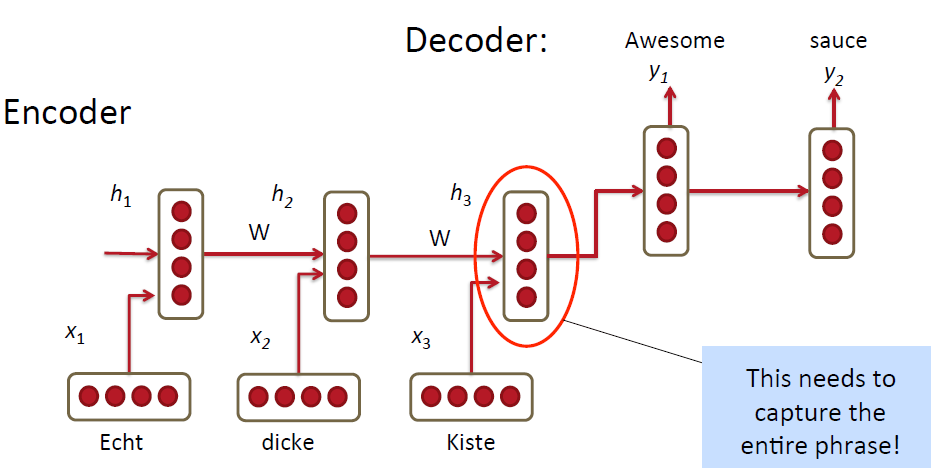
上图是屌丝版本,也就是最原始的处理方法。使用RNN把source language的单词一个一个的输入到model里,最终把这一整句话用一个vector表示出来,也就是encoder的过程;然后得到最终的vector之后再decoder将原始的句子用target language表示出来。看起来挺诱人挺高效的有木有!但是其实米有这么简单呀!
改良版
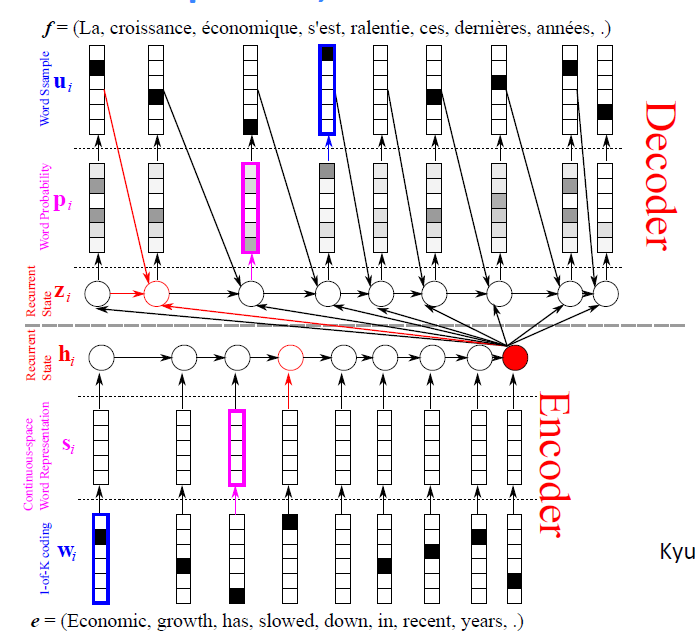
decoder的过程不仅仅是从最后一个hidden node(以下简写为C)中提取信息,还从前一个decoder出来的单词及前一个hidden node里提取信息。
还有几个改良方法就和上一讲讲得类似了一是改良方法是使用stacked/deep RNNs;二是使用bidirectional encoder,而不是使用最简单的一层的encoder。
还有一个改良方法是把单词的顺序倒个个,原因说的是第一个单词的信息能很容易保留下来,然后target language就能很容易从中提取出信息,做出有效的翻译。
GRU
GRU其实也可以认为是Recurrent NN一种改良版,他是针对Recurrent NN的两个问题进行了改进。一个问题是越靠前的单词对当然hidden node的影响会越小,第二个问题是产生error的时候这个error可能是有某一位或者某几位单词诱发的,所以应当仅仅对某一位或者某几位单词的weight进行update。
main ideas: 1.keep around memories to capture long distance dependencies
2.allow error messages to flow at different strengths depending on the inputs
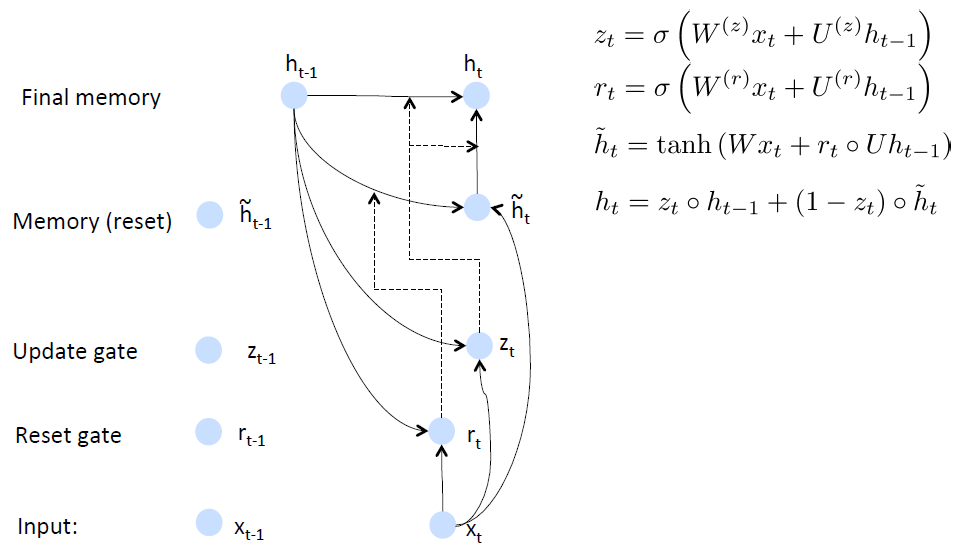
GRU的思路是首先根据当前word vector及前一个hidden state计算出update gate和reset gate;再根据reset gate、当前word vector及前一个hidden state计算出new memory content。
reset gate的用处很明确了,就是当reset gate为1的时候,new memory content忽略之前所有的memory。最终的memory是之前的hidden node及new memory content的综合体
LSTMs
LSTMs所针对的问题其实也是上面说的两个问题。

GRUs和LSTMs的区别
说实话GRU和LSTMs其实是很像的先上个对比图吧:
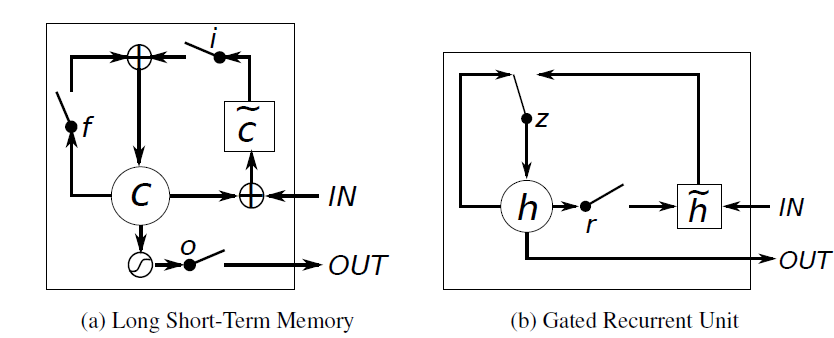
以下说说他们之间的相同与不同:
1.new memory的计算方法都是根据之前的state及input计算,但是GRU有一个R gate控制之前state的进入量,在LSTM里没有这个gate
2.产生新的state的方式不同,LSTM有两个不同的gate分别是f gate和i gate;GRU只有一个gate就是z gate
3.LSTM对新产生的state有一个o gate可以调节大小;GRU直接输出无任何调节。
Recursive NN
Parsing
在一定程度上可以认为Recurrent NN是Recursive NN的一种变体。Recursive NN更general。
一个句子的意思是基于1.这个句子所包含的单词的意思;2.这个句子的构建方式。
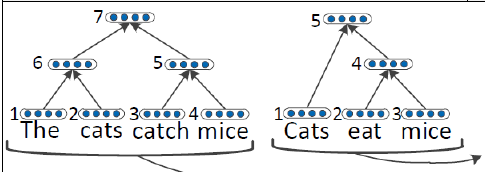
这样我们就知道了首先得学出来某一个句子的Parsing Tree。下图就是Parsing tree的例子。上面的是recursive NN的parsing tree,下面的是recurrent NN的parsing tree
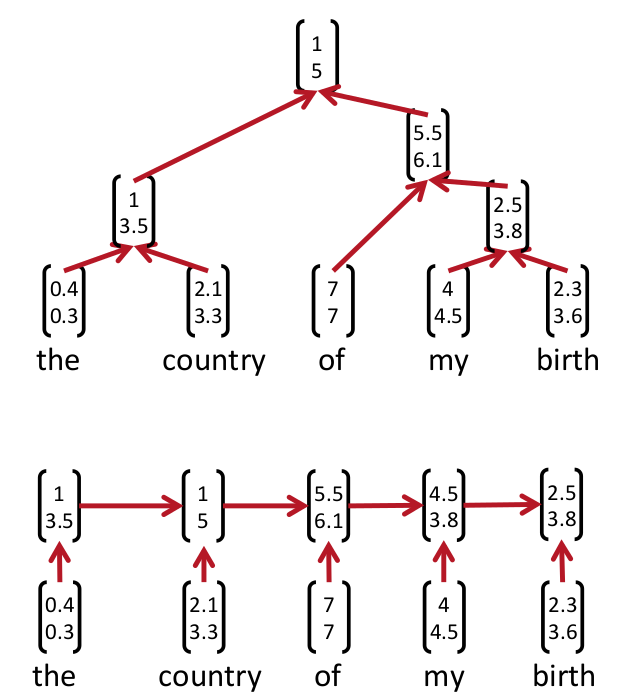
学习出这个parsing tree的方法叫beam search就是bottom-up的方法,从最低下开始,计算哪两个成为好基友的score最大,然后取出来最大的score的俩个node然后他俩就merge了(好邪恶)。最后一直到最上面全部都merge起来了就形成了一个parsing tree。
models
在学出来parsing tree之后下一步就要对parsing tree建立model了
有四个比较出名的recursive NN

standard RNNs
RNNs for Paraphrase Detection主要包含两个方面。第一方面是Recursive Autoencoder,第二方面是Neural Network for Variable-Sized Input
这个模型在第二篇paper里讲得很详细。
首先我们已经有了一个parse tree,有一个可信的parse tree对于paraphrase detection很重要。
Recursive Autoencoder有两种Autoencoder的方法。
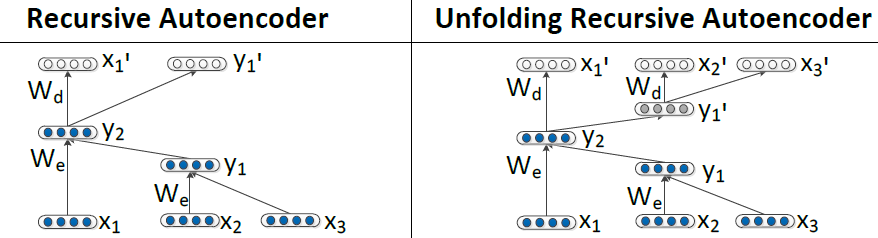
第一种是左边的这种,每次decoder只decoder出一层,然后求所有non-terminal nodes的error的和作为loss function。non-terminal nodes的error是其两个children的vectors先连接出来,然后再求欧式距离得到的。
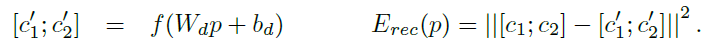
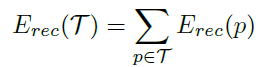
上面两式中,其中下面的式子中的T集合是所有non-terminal nodes,上面的式子中的c1, c2分别是p的两个children
由于non-terminal nodes的值可以通过无限shrinking the norms of the hidden layers来实现,所以必须对non-terminal nodes的值p进行normalization
第二种是上面图片里右边的那种reconstruct the entire spanned subtree underneath each nodes
就是把所有的leaf nodes全部decode出来,然后把所有leaf nodes连接起来,求欧式距离作为loss function
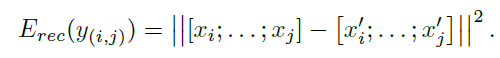
上面的model tune好了,然后进行下一个阶段。
以上是tune好的tree
首先先建立一个similarity matrix,其中column和row分别按照单词的从左到右的顺序以及上面的hidden nodes从下到上从右到左的顺序排列
第二步是pooling,其中pooling layer的是一个square matrix先对#col及#row取一个fixed值,设为n_p。论文里是使用的非over-lapping的方法,就是不重叠行或者列。
如果#col > n_p, #row > n_p,每#col/n_p及#row/n_p作为一个pool最后会剩下一个比较小的pool行或者列都小于n_p。
如果#col < n_p,#row < n_p,先duplicating pixels小于n_p的那一边,然后直到那一边的pixels大于n_p为止。
在每个pool里取其最小值,然后在pool之后normalize每个entry使其mean = 0及variance = 1
paper里提到了一个对于数字的改进方法:第一如果两个句子里的数字完全一样或没有数字,设为1,反之设为0;第二如果两个句子里包含一样的数字,设为1;第三一个句子里的数字严格的是另一个句子里数字的子集,设为1
这种方法有两个缺点:第一是仅仅比较单词或者phrase的相似性遗失了语法结构;第二是计算similarity matrix也遗漏了部分信息。
最后把得到的similarity matrix输入到一个NN里或者softmax classifier里再建立loss function就能进行优化计算了。
Matrix-Vector RNNs
Matrix-Vector RNNs这个模型比较简单就是在表示一个word的时候不仅仅只用vector的形式表示,用matrix加vector结合起来的方式表示一个word
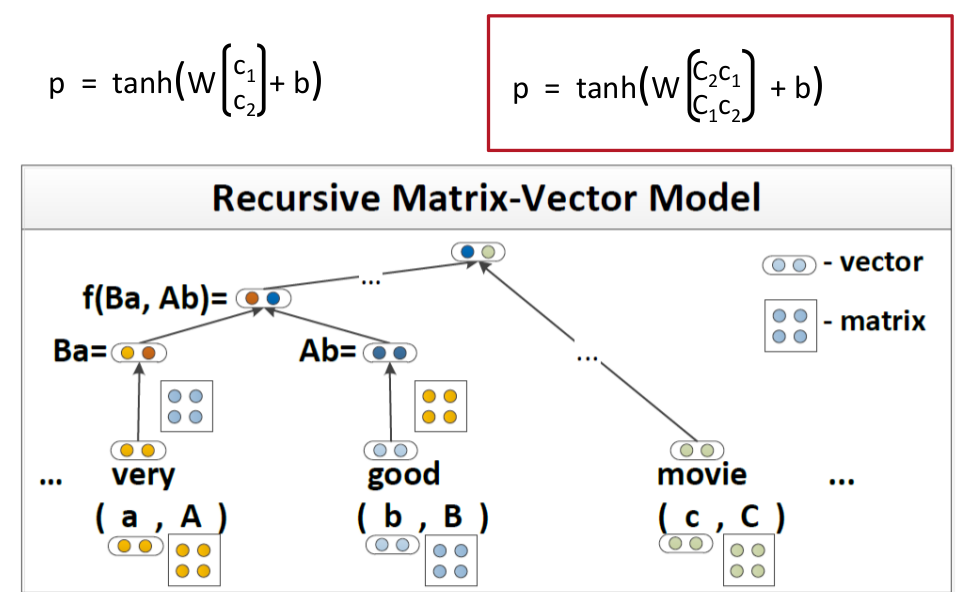
以上就是Matrix-Vector的表示方法,和stardard的差异比较小。
课上说这个模型对Relationship Classification的效果比较好。
Relationship Classification简单的说就像以前中学从一句话里提取出关键词。
RNTN
Bag-of-words的方式进行sentiment detection比较不靠谱,因为bag-of-words不能capture一个句子的parse tree还有linguistic features
使用好的corpus也会提高精确度,很诱人哦!
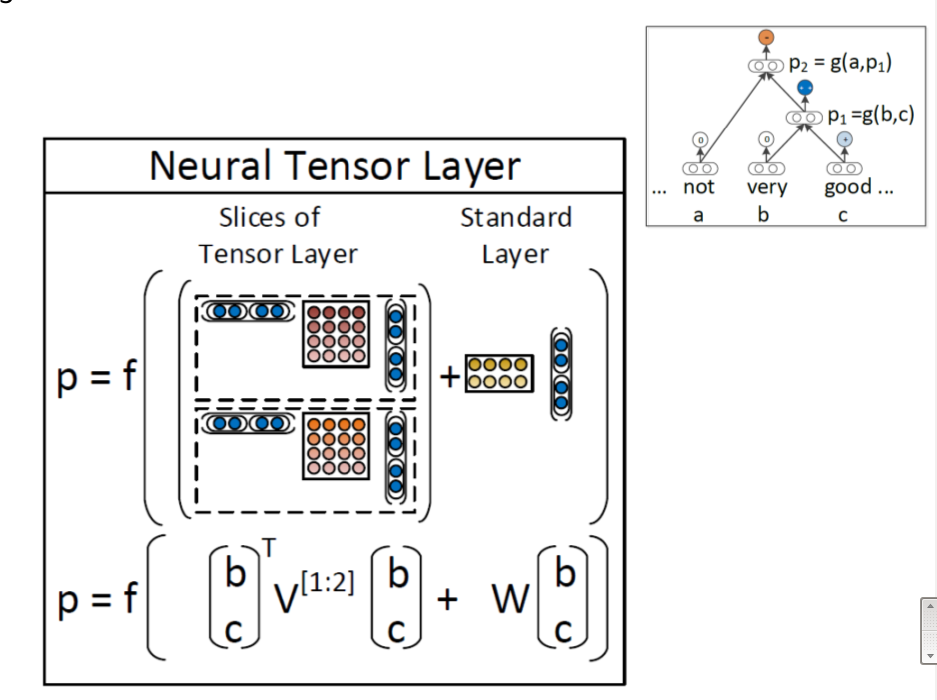
其实整体模型改动也不太大,也很好理解,这样就能很好的捕捉到句子的sentiment
这个模型的优化和之前的略有不同:

这个模型据说是现今唯一能够capture negation及其scope的模型。
Tree LSTMs
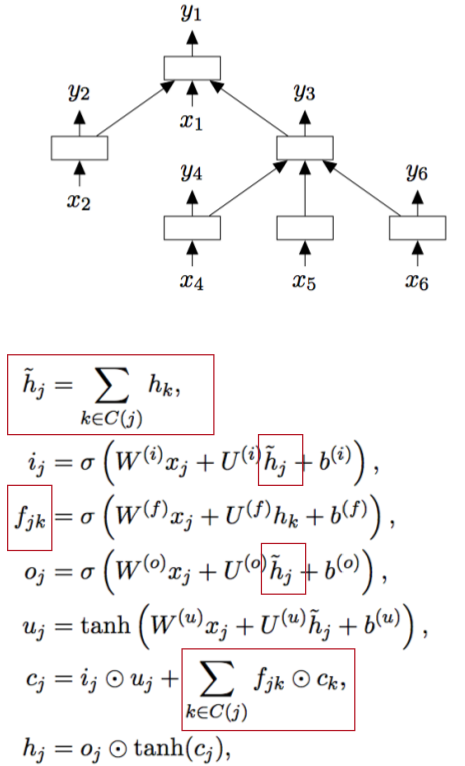
Tree LSTMs和普通的LSTMs的不同之处在于Tree LSTMs是从tree的结构中进行LSTMs的建模。
普通的LSTMs也可以看作是Tree LSTMs的一种特殊情况。
Tree LSTMs里leaf node的hidden计算和之前的普通的hidden计算方法一样,只是其parents的计算略有不同。具体公式见上图。
parent的hidden是其children的hiddens的和,每一个forget unit是根据具体的某个node来计算的,计算最终cell时要把所有forget units和对应的cells相乘并求和,其他都是和普通LSTMs一样的计算方法了。
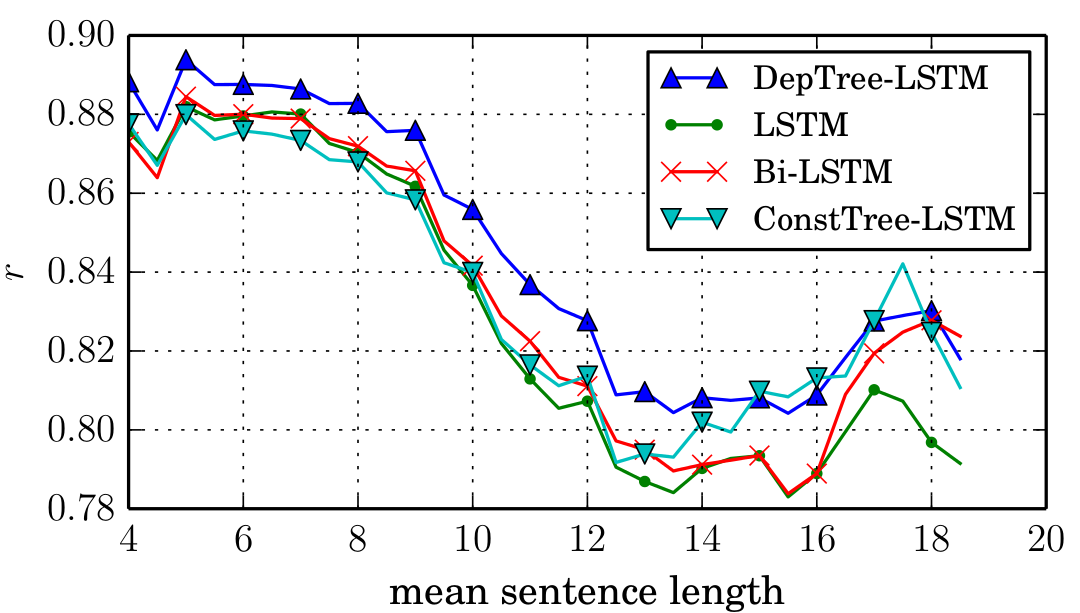
这个模型对于semantic similarity目前还是最适用的。如图:
有用的链接
GRU LSTM
http://www.ubi.com/
https://github.com/jych/librnn.git
recursive NN
nlp.stanford.edu
http://repository.cmu.edu/robotics
www.socher.org
HW
Python generators
http://www.python-course.eu/generators.php
The difference between range and xrange
退火算法:
http://www.cnblogs.com/heaad/archive/2010/12/20/1911614.html














 198
198











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









