



目录
数据库(DB),是 存储和管理 数据的 仓库。DataBase(DB)
数据库管理系统(DBMS), 操纵和管理 数据库 的大型 软件。DataBase Management System(DBMS) 包括MySQL ,Oracle
SQL,操作 关系型数据库 的 编程语言,定义了 一套操作 关系型数据库 统一标准。Structured Query Language(SQL)
关系型数据库(RDBMS):建立在 关系模型 基础上,由 多张 相互连接 的 二维表 组成的 数据库
DDL : 数据定义语言,用来定义 数据库/表 对象 (数据库,表,字段)
DML: 数据操作语言,用来对数据库中表的 数据 进行增删改
DCL: 数据控制语言,用来创建数据库用户、控制数据库的访问权限
多表设计—— 一对多(多对一)、多对多、一对一项目开发中,在进行数据库表结构设计时,会根据业务需求及业务模块之间的关系,分析并设计表结构,由于业务之间 相互关联,所以各个表结构之间也存在着各种联系
一对多:在数据库表中多的一方,添加字段,来关联 一 的 一方的 主键
一对一:在任意一方加入外键,关联另外一方的主键,并且设置外键为唯一的(UNIQUE)
多对多:建立第三张中间表,中间表至少包含两个外键,分别关联两方主键
外键约束:目前一对多的两张表,在数据库层面,并未建立关联,所以是无法保证数据的一致性和完整性的。
其他查询方法——连接查询+子查询注意:1.子查询会多次访问表中的数据,效率不高 2.可以使用连接查询,尽量使用连接查询
子查询:SQL语句中嵌套select语句,称为嵌套查询,又称子查询。注意点:一般将 其他表的查询语句 称为子查询 并且使用小括号括起来,选中 小括号中的代码 也是可以 直接运行的
事务:要么同时成功,要么同时失败。注意事项:默认MySQL的事务是自动提交的,也就是说,当执行一条DML语句,MySQL会立即隐式的提交事务,
概念:事务 是一组操作的集合,它是一个不可分割的工作单位。事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作 要么同时成功,要么同时失败。
-
一、什么是数据库?
-
数据库(DB),是 存储和管理 数据的 仓库。
DataBase(DB) -
数据库管理系统(DBMS), 操纵和管理 数据库 的大型 软件。
DataBase Management System(DBMS) 包括MySQL ,Oracle -
SQL,操作 关系型数据库 的 编程语言,定义了 一套操作 关系型数据库 统一标准。
Structured Query Language(SQL)-
SQL通用语法
- SQL语句可以单行或多行书写,以分号结尾。
- SQL语句可以使用空格/缩进来增强语句的可读性。
- MySQL数据库的SQL语句不区分大小写。
- 注释:
- 1.单行注释:--注释内容 或 # 注释内容 (MySQL特有)
- 2多行注释:/*注释内容 */
-
-
-
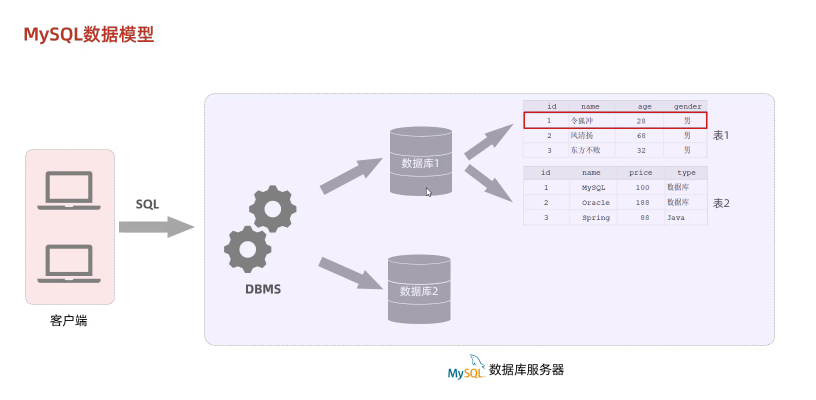
二、MySQL:开源免费的中小型数据库。
mysql -u用户名 -p密码 [-h数据库服务器IP地址 -P端口号]-
关系型数据库(RDBMS):建立在 关系模型 基础上,由 多张 相互连接 的 二维表 组成的 数据库
-
特点
- 使用 表 存储数据,格式统一,便于维护
- 使用 SQL语言 操作,标准统一,使用方便,可用于 复杂查询
-
MySQL客户端工具-图形化工具——>DataGrip——>内嵌于 IDEA
:DataGrip是letBrains旗下的一款数据库管理工具,是管理和开发MyS0L、0racle、PostgreSOl的理想解决方案。 -
MySQL 中的 SQL语句
-
SQL通用语法

- SQL语句可以单行或多行书写,以分号结尾。
- SQL语句可以使用空格/缩进来增强语句的可读性。
- MySQL数据库的SQL语句不区分大小写。
- 注释:
- 1.单行注释:--注释内容 或 # 注释内容 (MySQL特有)
- 2多行注释:/*注释内容 */
-
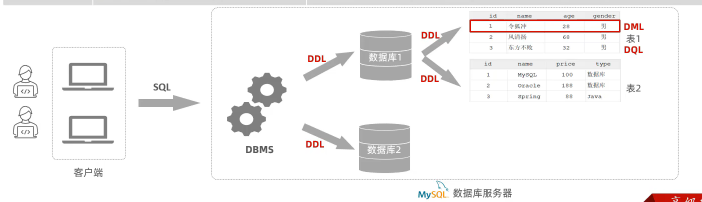
SQL 分类——通常被分为四大类:
-
DDL : 数据定义语言,用来定义 数据库/表 对象 (数据库,表,字段)

- 数据库操作
语法中的 database,也可以替换成 schema。如:create schema db01;- 查询:show / select
- 查询所有数据库:show databases;
- 查询当前数据库:select database();
- 使用:use
- 使用数据库:use 数据库名;
- 创建:create
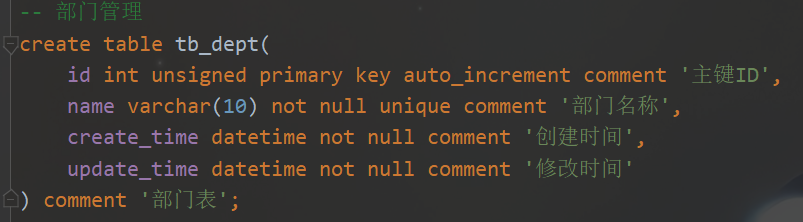
- 创建数据库:create database[if not exists] 数据库名;
- 删除:drop
- 删除数据库: drop database [ if exists] 数据库名;
- 查询:show / select
- 表操作
- 设计表结构的基本流程:
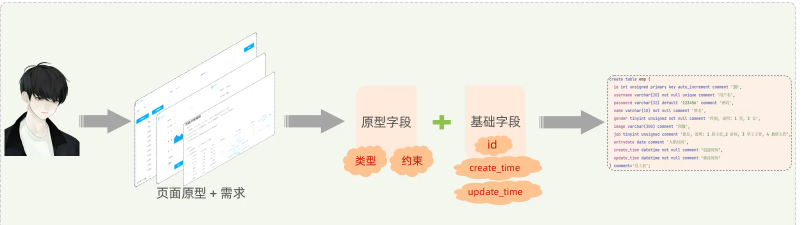
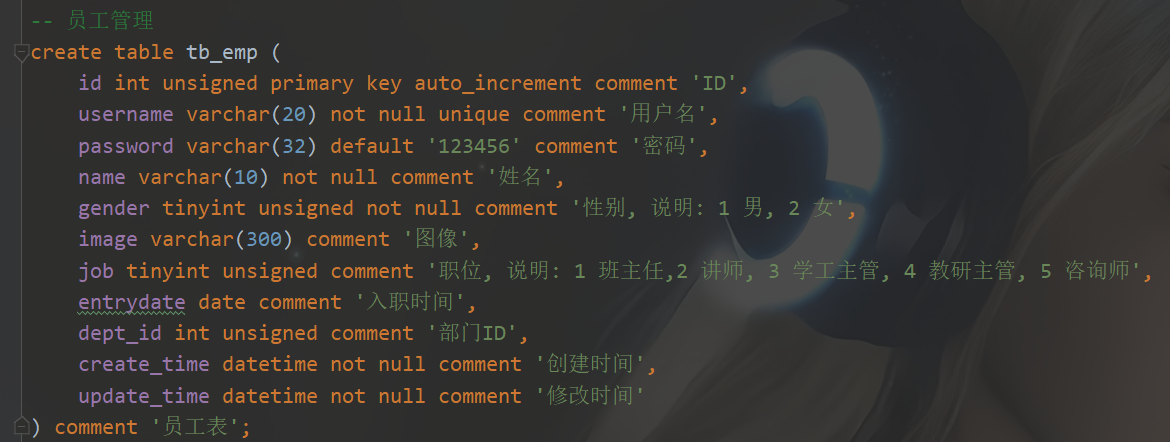
- 创建 : create table 表名();

- 约束 :约束是 作用于表中字段 上的 规则,用于 限制 存储在表中的数据。
目的: 保证数据库中数据的正确性、有效性和完整性。- 常用约束
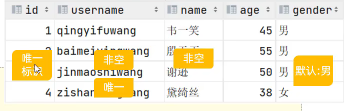
特殊:非空且唯一是主键的特性,但是设置 非空+唯一 的 不一定是主键。- 非空约束:not null
限制该字段值不能为null - 唯一约束:unique
保证字段的所有数据都是唯一、不重复的 - 主键约束:primary key (auto_increment 自增)
主键是一行数据的唯一标识,要求非空且唯一 - 默认约束:default
保存数据时,如果未指定该字段值,则采用默认值 - 外键约束:foreign key
让两张表的数据建立连接,保证数据的一致性和完整性
- 非空约束:not null
- 常用约束
- 数据类型
MySQL中的数据类型有很多,主要分为三类:数值类型、字符串类型、日期时间类型。- 1.数值类型 —— 默认是有符号数;使用无符号数,在数值类型后加上 unsigned ,中间用空格隔开
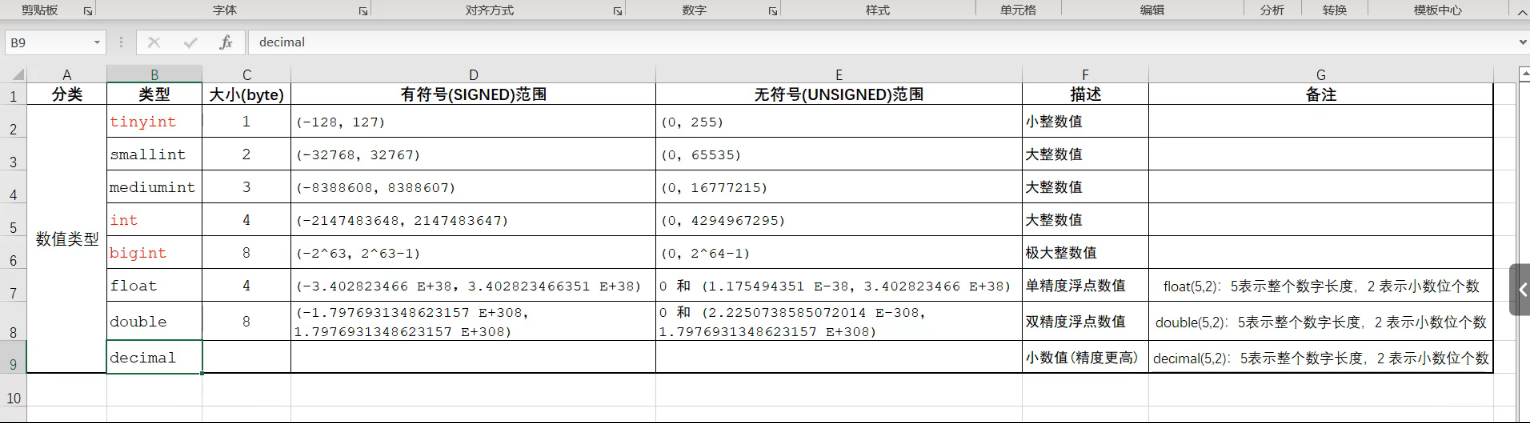
有符号:signed 无符号:unsigned- 整数类型
常用 : tinyint + int- tinyint (小整数值)
大小 :1个字节
范围 :有符号——(-128,127); 无符号——(0,255) - int : (大整数值)
大小 :4个字节
范围 :有符号——(-2147483648,2147483647); 无符号——(0,4294967295) - bigint :(极大整数值)
大小 :8个字节
范围 :有符号——(-2^63,2~63-1); 无符号——(0,2~64-1)
- tinyint (小整数值)
- 小数类型 —— “ (A,B) ” 中,参数A表示整个数字长度,参数表示小数位个数
常用 :double + decimal- double : (双精度浮点数值)(精度低)
大小:8个字节
范围:有符号——(-1.7976931348623157 E+308,1.7976931348623157 E+308) 无符号——0和(2.2250738585072014E-308,1.7976931348623157 +308)- double(5 ,2):5表示整个数字长度,2 表示小数位个数
- decimal : (小数值,精度更高)
- double : (双精度浮点数值)(精度低)
- 整数类型
- 2.字符串类型
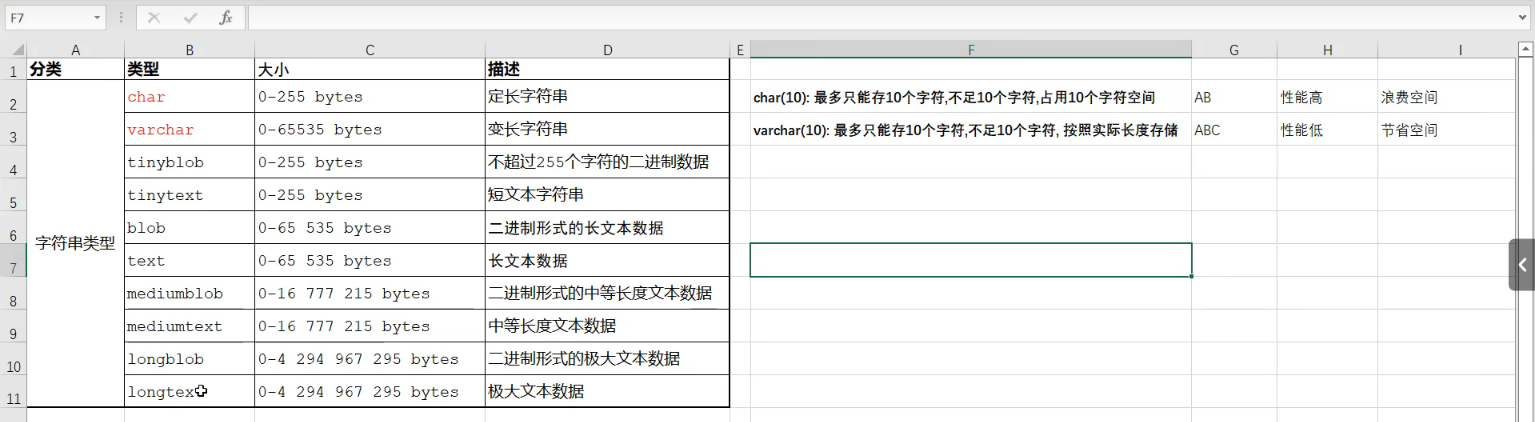
char:定长字符串(相当于数组)(性能高,浪费空间); varchar : 变长字符串(相当于集合)(性能低,节省空间)- char:定长字符串——性能高,浪费空间
当检索(输出)CHAR值时,除非启用了PAD_CHAR_TO_FULL_LENGTH SQL模式(默认没启用),否则会删除尾随空格。
char(10): 最多只能存10个字符,不足10个字符,占用10个字符空间
大小:0-255 bytes - varchar : 变长字符串——性能低,节省空间
varchar(10): 最多只能存10个字符,不足10个字符,按照实际长度存储
大小:0-65535 bytes
- char:定长字符串——性能高,浪费空间
- 3.日期时间类型。

date:日期 ; datetime:日期+时间 ; now():插入当前系统时间(一般用于设置数据的插入时间和修改时间)- date:日期值 ——>格式 :YYYY-MM-DD
一般用于表示 生日
大小:3 字节
范围:1000-01-01至9999-12-31 - datetime:混合日期和时间值 ——>格式 :YYYY-MM-DD HH:MM:SS
一般用于数据的创建时间和修改时间
大小:8字节
范围:1000-01-01 00:00:00至9999-12-31 23:59:59
- date:日期值 ——>格式 :YYYY-MM-DD
- 1.数值类型 —— 默认是有符号数;使用无符号数,在数值类型后加上 unsigned ,中间用空格隔开
- 约束 :约束是 作用于表中字段 上的 规则,用于 限制 存储在表中的数据。
- 查询 —— show + desc
- 查询 当前数据库 所有表 :show tables;
- 查询 表结构:desc 表名;
- 查询 建表语句:show create table 表名;
- 修改 ——alter + rename
- 添加字段:alter table 表名 add 字段名 类型(长度)[comment 注释][约束];
- 修改字段类型:alter table 表名 modify 字段名 新数据类型(长度);
- 修改字段名和字段类型:alter table 表名 change 旧字段名 新字段名 类型(长度)[comment 注释][约束];
- 删除字段:alter table 表名 drop column 字段名;
- 修改表名: rename table 表名 to 新表名;
- 删除:drop table [if exists ]表名;
在删除表时,表中的全部数据也会被删除。 - 注意事项——所有的表都需要加
给表添加数据时 :now():插入当前系统时间(一般用于设置数据的插入时间和修改时间)- create_time:记录的是当前这条数据插入的时间。
- update_time:记录当前这条数据最后更新的时间。
- 创建 : create table 表名();
- 设计表结构的基本流程:
- 补充点:
- 1. 执行语句时,创建时如果存在,就会报错;查询,使用,删除时候如果不存在,就会报错;
- 2. if exists 对象名称 。作用:存在 才执行操作,不存在 就不执行,且不会报错。 创建时 使用 if not exists 对象名称 ,相当于取反,也可以与其他条件组合使用
其中,对象名称可以是表、视图、存储过程或其他数据库对象
- 数据库操作
-
DML: 数据操作语言,用来对数据库中表的 数据 进行增删改

- 添加数据(insert)

- 注意点:
- 1.插入数据时,指定的字段顺序需要与值的顺序是一一对应的。
- 2.字符串和日期型数据应该包含在引号中。
- 3. 插入的数据大小,应该在字段的规定范围内。
- 指定字段添加数据:insert into 表名(字段名1,字段名2) values (值1,值2);
- 全部字段添加数据:insert into 表名 values (值1,值2,..);
- 批量添加数据(指定字段):insert into 表名(字段名1,字段名2) values (值1,值2),(值1,值2);
- 批量添加数据(全部字段):insert into 表名 values(值1,值2,….),(值1,值2,….);
- 注意点:
- 修改数据(update)
- 修改数据: update 表名 set 字段名1=值1,字段名2=值2,…[where 条件];
- 注意事项:修改语句的条件 可以有,也可以没有;如果 没有条件,则会修改 整张表的 所有数据。
- 删除数据(delete)
针对行数据- 制除数据: delete from 表名[where 条件];
删除一整行的数据 - 注意事项
- 1. delect 语句的 条件可以有,也可以没有,如果 没有条件,则会除 整张表 的 所有数据。
- 2. delect 语句 不能删除 某一个字段的 值(如果要操作,可以使用update,将该字段的值 置为NULL)。
update 表名 set 字段=null where 字段=某值 --即将表中字段为某值的替换为null update(更新)
- 制除数据: delete from 表名[where 条件];
- 添加数据(insert)
-
DQL: 数据 查询语言,用来 查询 数据库中表 的 记录

- 补充点:
- 1 . 通配符 * 号 ,代表查询所有字段;在实际开发中尽量少用(不直观、影响效率)
- 2. as :起别名,前面是字段(如果是表达式,用 “(...)” 括起来再写),后面跟 别名, 执行完后在使用字段时用别名代替。
细节:没有特殊符号,引号可以省去,有特殊符号,使用单引号和双引号都可以; as可以省去
- 基本查询
设置别名(as) ; 去除重复记录(distinct )- 查询多个字段: select字段1,字段2,字段3 from 表名;

- 查询所有字段:

- 1. select字段1,字段2,字段3,...全部字段 from 表名;
推荐使用 (小技巧,先写from后面,再写 id,IDEA会自动提示是否要全部字段) - 2. select*from 表名; -- *(通配符)
不推荐,(不直观,性能低)
- 1. select字段1,字段2,字段3,...全部字段 from 表名;
- 设置别名(as): select 字段1 [as 别名1],字段2[as 别名2]from 表名;

- 去除重复记录(distinct ): select distinct 字段列表 from 表名;

- 查询多个字段: select字段1,字段2,字段3 from 表名;
- 条件查询(where)

% :表示任意字符任意长度; and : 作为连接符,并且的意思; = :判断语句,成立就留下,不成立舍去; between...and... :范围表达式;- 条件查询: select 字段列表 from 表名 where 条件列表;

- 条件查询: select 字段列表 from 表名 where 条件列表;
- 分组查询(group by)
group by :分组名 ; where:分组条件 ; having : 分组后的判断
聚合函数 : count统计数量 mаx最大值 min最小值 avg平均值 sum求和- 过程:1. select * from....;先按照一般形式写好代码,然后 根据where后面的条件进行分组,然后 根据 group by 后面的分组字段名修改 *这个通配符——如果没有 特殊命名条件 就改成 “分组字段名,聚合函数”;如果有特殊条件(1是男/2是女....等乱七八糟的),直接将 分组字段名 替换成 判断的表达式(if...;case...)。分组后还有 筛选的条件,再用 having 加上 分组后过滤条件就行了
- 分组查询: select 字段列表 from 表名[where 条件] group by 分组字段名 [having 分组后过滤条件];
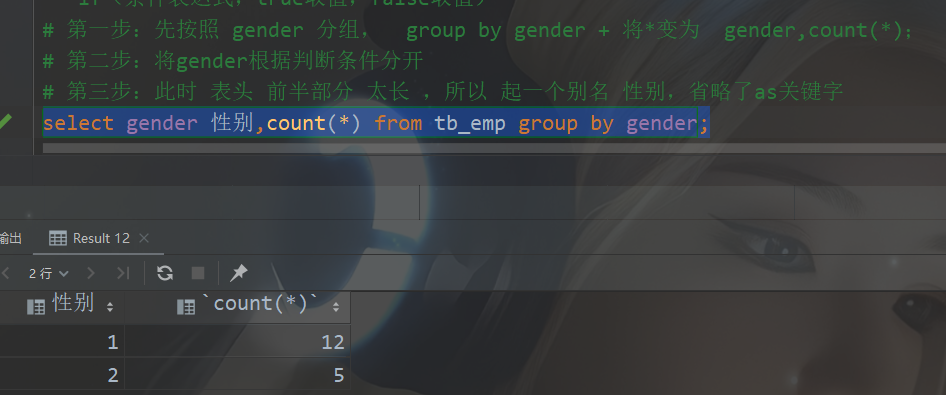
字段列表 一般为 “ 分组字段名 ,聚合函数 ” ;也可以对分组字段名进一步判断进行命名。
执行顺序: where >聚合函数>having。- where与having区别
- 1.执行 时机 不同:
- where是 分组之前 进行过滤,不满足where条件,不参与分组;
- having是 分组之后 对 结果 进行过滤。
- 2.判断 条件 不同:where不能对 聚合函数 进行判断,而having 可以。
- 1.执行 时机 不同:
- 注意事项
- 分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义。
- 执行顺序: where >聚合函数>having。
- where与having区别
- 聚合函数
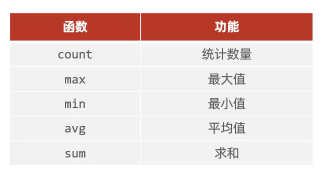
- 介绍:将一列数据作为一个整体,进行纵向(竖着)计算。
- 语法: select 聚合函数 (字段列表) from 表名:
- 注意事项
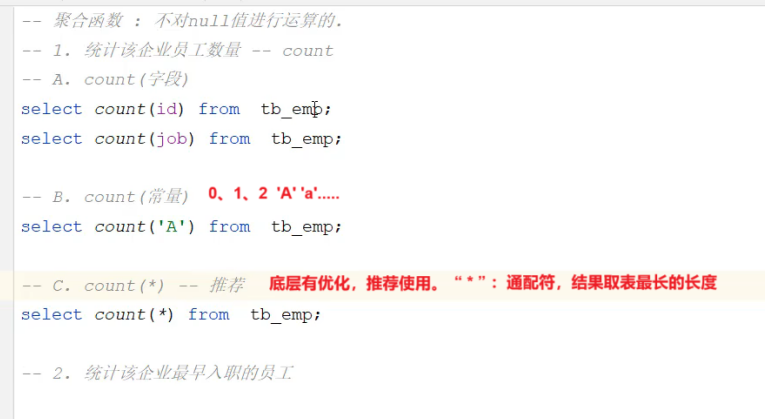
推荐使用count(*) 统计数量- nu11值不参与所有聚合函数运算。
- 统计数量可以使用: count(*) 、count(字段) 、count(常量),推荐使用count(*)。
- 分组后对分组字段进一步命名,使用判断语句


- if(条件表达式,true取值,false取值)
- case 表达式 when 值1 then 结果1 when 值2 then 结果2 ... else ... end
- 排序查询(order by)
order by.... [desc];排序 ; desc : 降序排序 (默认是升序(asc),一般不写升序)- 条件查询: select 字段列表 from 表名[where 条件列表][group by 分组字段]order by 字段1 排序方式1,字段2 排序方式2 ...;
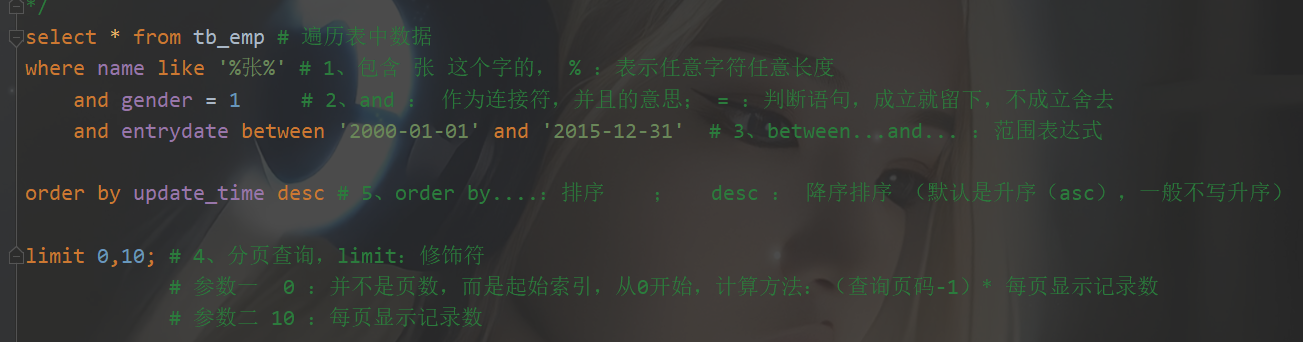
排序方式: ASC—>升序(默认值) DESC—>降序 - 注意事项:如果是多字段排序,当第一个字段值 相同 时,才会根据第二个字段 进行排序。
- 条件查询: select 字段列表 from 表名[where 条件列表][group by 分组字段]order by 字段1 排序方式1,字段2 排序方式2 ...;
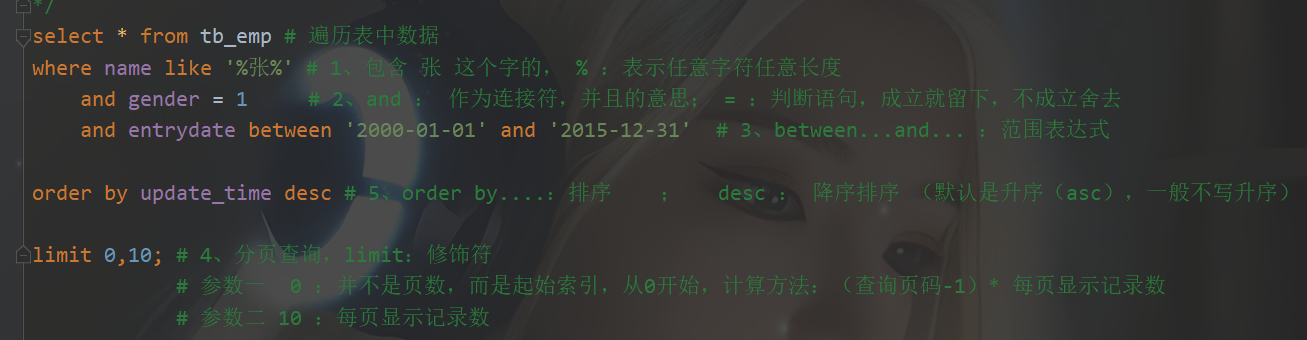
- 分页查询(limit)
起始索引 =(页码- 1) * 每页展示记录数
分页查询 limit 0,10
limit :修饰符
参数一 0 :并不是页数,而是起始索引,从0开始,计算方法:(查询页码-1)* 每页显示记录数
参数二 10 :每页显示记录数- 分页查询: select 字段列表 from 表名 limit 起始索引,查询记录数;
- 注意事项
起始索引 =(页码- 1) * 每页展示记录数- 1. 起始索引从0开始,起始索引 = (查询页码-1)*每页显示记录数。
- 2. 分页查询 是 数据库的方言,不同的数据库有不同的实现,MySQL中是limit。
- 3.如果 查询的是 第一页数据,起始索引 可以省略,直接简写为 limit 10。
- 分页查询: select 字段列表 from 表名 limit 起始索引,查询记录数;
- 补充点:
-
DCL: 数据控制语言,用来创建数据库用户、控制数据库的访问权限
-
-
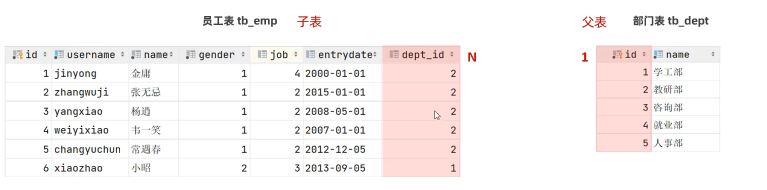
多表设计—— 一对多(多对一)、多对多、一对一
项目开发中,在进行数据库表结构设计时,会根据业务需求及业务模块之间的关系,分析并设计表结构,由于业务之间 相互关联,所以各个表结构之间也存在着各种联系-
一对多:在数据库表中多的一方,添加字段,来关联 一 的 一方的 主键
-
一对一:在任意一方加入外键,关联另外一方的主键,并且设置外键为唯一的(UNIQUE)
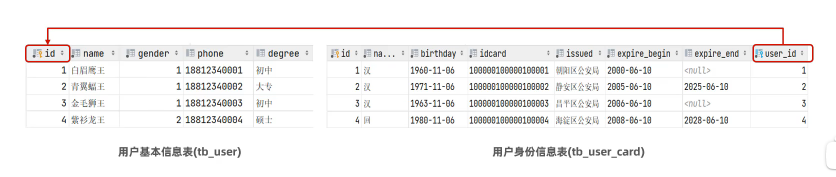
一对一可以看做另类的一对多
用户 与 身份证信息 的关系:多用于单表拆分,将一张表的基础字段放在一张表中,其他字段放在另一张表中,以提升操作效率- 代码实现——物理外键
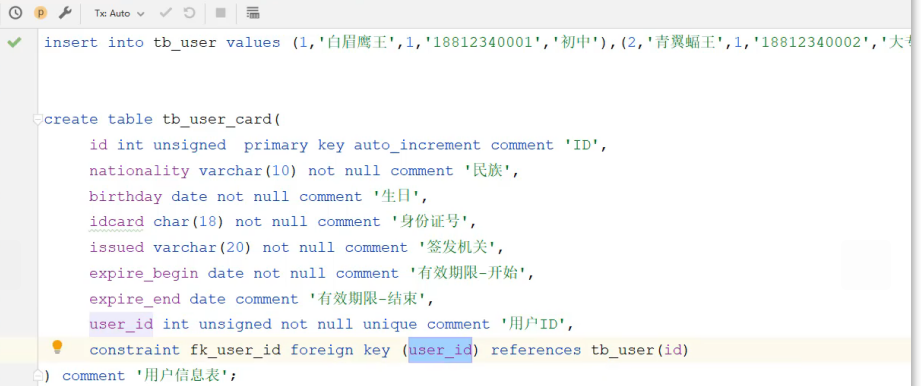
- 代码实现——物理外键
-
多对多:建立第三张中间表,中间表至少包含两个外键,分别关联两方主键
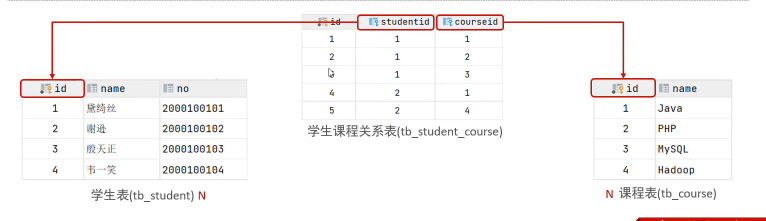
案例:学生 与 课程的关系:一个学生可以选修多门课程,一门课程也可以供多个学生选择- 代码实现——物理外键
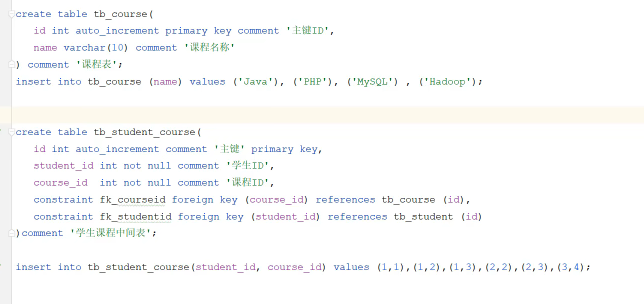
- 代码实现——物理外键
-
外键约束:目前一对多的两张表,在数据库层面,并未建立关联,所以是无法保证数据的一致性和完整性的。
- 物理约束:[constraint] 外键别名 foreign key (多表中外键字段名)references 主表(一表中字段名)

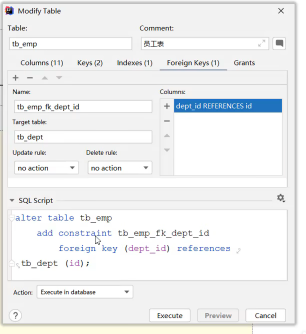
概念:使用 foreign key 定义外键关联另外一张表。
缺点:
1.影响增、删、改的效率(需要检查外键关系)
2.仅用于单节点数据库,不适用与分布式、集群场景。
3.容易引发数据库的死锁问题,消耗性能。 - 逻辑外键:在业务层逻辑中,解决外键关联。(推荐使用)
通过逻辑外键,就可以很方便的解决物理外键问题
简单理解逻辑外键:
我们在定义两张表(user/userInfon)的关系时,学校教我们的是用foreign key 去创建,这种是物理外键。
而逻辑外键就是两者必然的关联但是没有foreign key 来关联,而是在设计两张表的时候创建字段去存储相关联的数据内容。
如,user(用户表)中存在user_id(用户id)字段,userInfon(用户信息表)中也存在user_id(用户id)字段,
这样就可以通过
'select * from user inner join userInfon on user.user_id = userInfon.user_id,
这样的sql语句来实现逻辑查询
- 物理约束:[constraint] 外键别名 foreign key (多表中外键字段名)references 主表(一表中字段名)
-
-
多表查询:指从多张表中查询数据
-
直接查询
- 如果不加where判断语句,就会出现 tb_emp乘以tb_dept 条数据,这种现象也叫做 笛卡尔积
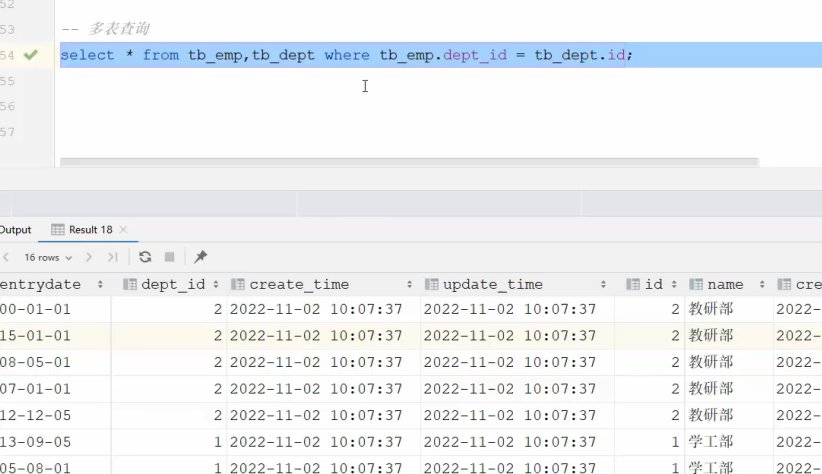
select * from tb emp,tb dept where tb emp.dept id = tb dept.id; - 笛卡尔积:笛卡尔乘积是指在数学中,两个集合(A集合 和 B集合)的所有组合情况,(在多表查询时,需要消除无效的笛卡尔积)
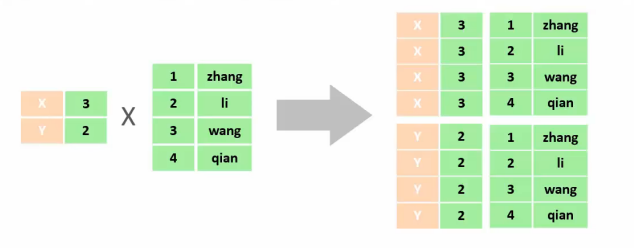
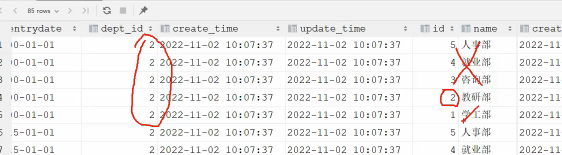
- 如果不加where判断语句,就会出现 tb_emp乘以tb_dept 条数据,这种现象也叫做 笛卡尔积
-
其他查询方法——连接查询+子查询
注意:1.子查询会多次访问表中的数据,效率不高 2.可以使用连接查询,尽量使用连接查询
-
连接查询——内连接+外连接
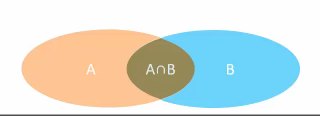
如果需求中没有特别要求查询某表的全部数据,默认使用内连接- 内连接:相当于查询A、B交集部分数据
- 语法:
- 隐式内连接: select 字段列表 from 表1,表2 where 条件…;
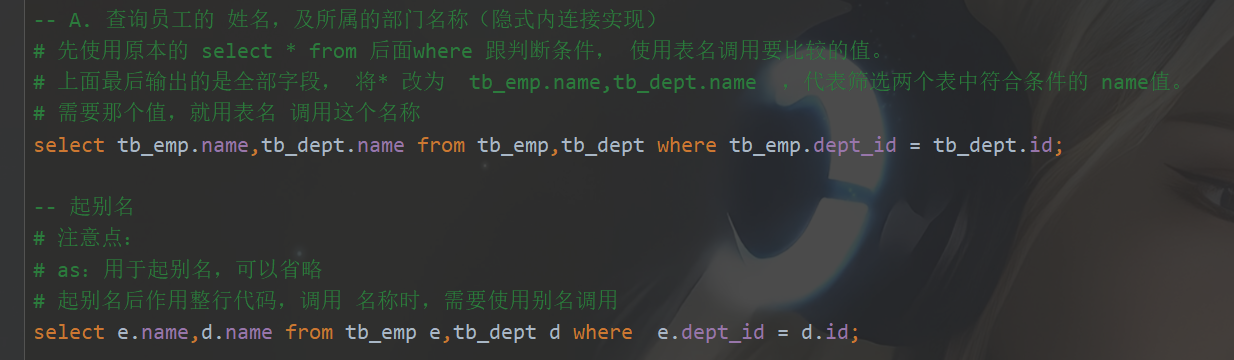
- 显式内连接: select 字段列表 from 表1 [inner] join 表2 on 连接条件…;

- 隐式内连接: select 字段列表 from 表1,表2 where 条件…;
- 语法:
- 外连接——左连接+右连接
注意点:开发经常使用左外连接
原因:右外连接可以使用左外连接代替,只是交换两个表的位置- 左外连接:查询左表所有数据(包括两张表交集部分数据)

select字段列表 from 表1 left [outer] join 表2 on 连接条件...; - 右外连接:查询右表所有数据(包括两张表交集部分数据)
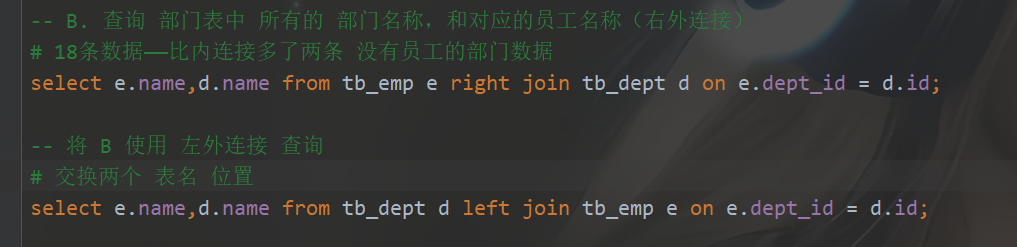
select 字段列表 from 表1 right [outer] join 表2 on 连接条件...;
- 左外连接:查询左表所有数据(包括两张表交集部分数据)
- 内连接:相当于查询A、B交集部分数据
-
子查询:SQL语句中嵌套select语句,称为嵌套查询,又称子查询。
注意点:一般将 其他表的查询语句 称为子查询 并且使用小括号括起来,选中 小括号中的代码 也是可以 直接运行的- 代码实现: select * from tl where column1 = (select column1 from t2 ... );
子查询外部的语句可以是insert/update/delete/select 的任何一个,最常见的是 select。 - 分类
- 标量子查询:子查询返回的结果为 单个值


子查询返回的结果是单个值(数字、字符串、日期等),最简单的形式
常用的操作符: = "不等于"<> > >= < <=- 代码过程:
- 1.将需求分开,先查询A表中东方白的入职信息
- 2.再根据返回值去B表中查询员工信息
- 3.最后将 2中的返回值 替换成1的代码语句,并用()括起来
- 代码过程:
- 列子查询:子查询返回的结果为一列 多行
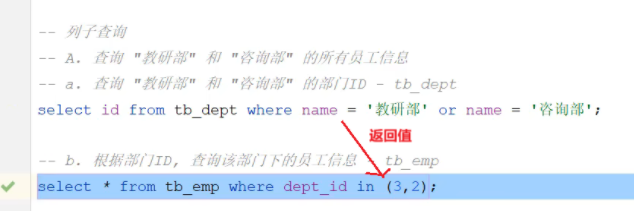
子查询返回的结果是一列(可以是多行)
常用的操作符:in、notin等
注意点:or和in 的使用方法or:或者的意思,放在两者之间in:在....地方, 部门ID为3 或者 部门ID为2的。 - 行子查询:子查询返回的结果为一行 多列
子查询返回的结果是一行(可以是多列)常用的操作符: =、<>、in、not in- 两种写法
- 1、根据判断条件将查询语句分开

- 2、使用第二种写法:将 等于号左边的 判断条件 放在 括号 中;这样 等号右边 括号 写上 对应的值。

- 2.1 这样,使用 行子查询 时,就可以直接将 表达式 替换 对应的值
- 1、根据判断条件将查询语句分开
- 两种写法
- 表子查询:子查询返回的结果为 多行多列
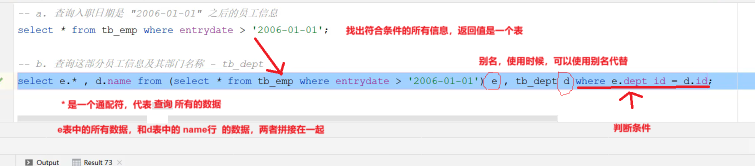
子查询返问的结果是多行多列,常作为临时表
常用的操作符:in
- 标量子查询:子查询返回的结果为 单个值
- 代码实现: select * from tl where column1 = (select column1 from t2 ... );
-
-
-
事务:要么同时成功,要么同时失败。
注意事项:默认MySQL的事务是自动提交的,也就是说,当执行一条DML语句,MySQL会立即隐式的提交事务,-
概念:事务 是一组操作的集合,它是一个不可分割的工作单位。事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作 要么同时成功,要么同时失败。
-
事务操作
- 开启事务:start transaction;/ begin;
- 提交事务:commit;
- 回滚事务:rollback;
-
使用过程:
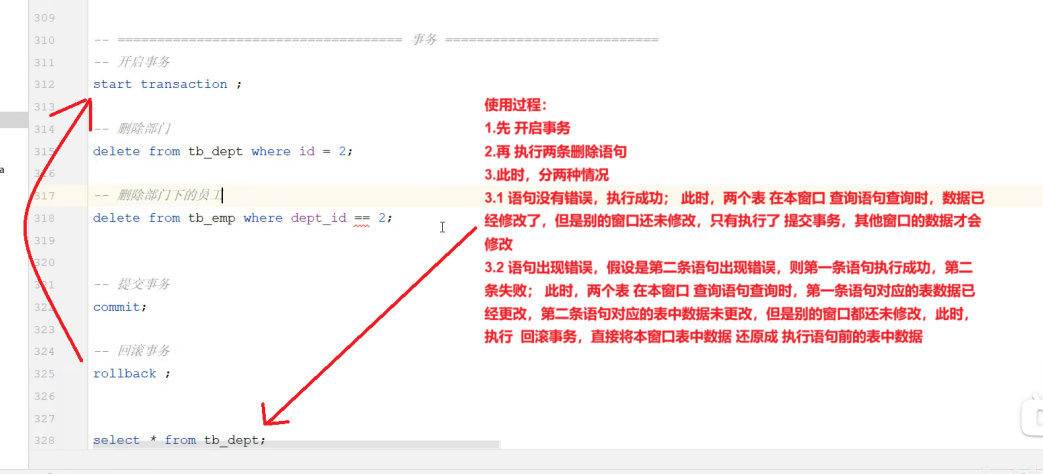
- 1.先 开启事务
- 2.再 执行两条删除语句
- 3.此时,分两种情况
- 3.1 语句没有错误,执行成功;此时,两个表 在本窗口 查询语句查询时,数据已经修改了,但是别的窗口还未修改,只有执行了提交事务,其他窗口的数据才会修改
- 3.2 语句出现错误,假设是第二条语句出现错误,则第一条语句执行成功,第二条失败; 此时,两个表 在本窗口 查询语句查询时,第一条语句对应的表数据已经更改,第二条语句对应的表中数据未更改,但是别的窗口都还未修改,此时执行 回滚事务,直接将本窗口表中数据 还原成 执行语句前的表中数据
-
四大特性—— 原子性、一致性、隔离性、持久性
原子性Atomicity
事务是不可分割的最小单元,要么全部成功,要么全部失败
一致性Consistency
事务完成时,必须使所有的数据都保持一致状态
隔离性lsolation
数据库系统 提供的 隔离机制,保证事务 在不受外部并发操作 影响的 独立环境下 运行
持久性Durability
事务一旦提交或回滚,它对数据库中的数据的改变就是永久的
-
-
-

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









