



 本文详细介绍了MySQL数据库系统,包括其结构、组件(如SGA、共享池)、核心处理流程、文件处理模块、B+树索引算法以及技术难点和解决方案。文章还涵盖了词法分析、接口设计和测试等内容。
本文详细介绍了MySQL数据库系统,包括其结构、组件(如SGA、共享池)、核心处理流程、文件处理模块、B+树索引算法以及技术难点和解决方案。文章还涵盖了词法分析、接口设计和测试等内容。
资源下载地址:https://download.csdn.net/download/sheziqiong/88333047
资源下载地址:https://download.csdn.net/download/sheziqiong/88333047
本项目的主要命令都参考mysql完成。MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,目前属于 Oracle 旗下产品。MySQL 最流行的关系型数据库管理系统,在 WEB 应用方面MySQL是最好的 RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件之一。MySQL是一种关联数据库管理系统,关联数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。MySQL所使用的 SQL 语言是用于访问数据库的最常用标准化语言。MySQL 软件采用了双授权政策,它分为社区版和商业版,由于其体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,一般中小型网站的开发都选择 MySQL 作为网站数据库。
1.3 术语
| 序号 | 术语/缩略语 | 说明 |
|---|---|---|
| 1 | B+tree | B+树 |
| 2 | SGA | System Global Area 系统全局区 |
| 3 | shared pool | 共享池 |
| 4 | data buffer area | 数据缓冲区 |
| 5 | redo log buffer | 日志缓冲区 |
| 6 | library cache | 库缓存区 |
| 7 | data directory cache | 数据字典缓存区 |
| 8 | SMON | System Monitor |
| 9 | DBWR | Data Base Writer |
| 10 | LGWR | Log Writer |
| 11 | CKPT | Check point |
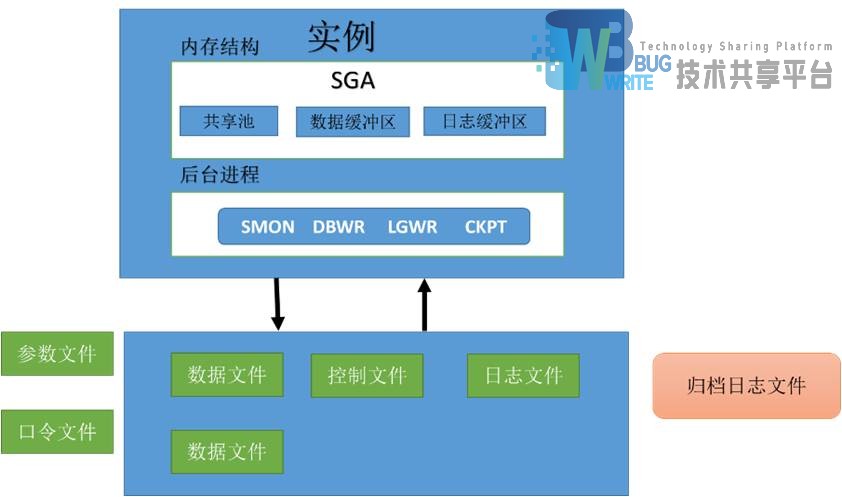
2 软件基本结构
软件由实例和数据库组成:
数据库由数据文件(包含表头文件、纪录文件、索引等数据)、控制文件(包括每个表的操作信息)、日志文件(数据操作sql语句)、参数文件(分配内存区域并定位控制文件的位置)、口令文件、日志归档文件(归档模式下)(服务器崩溃、硬盘损坏情况下,通过日志恢复时用)
实例由内存结构(memory strutct) 和后台进程(background processor)组成。
SGA: System Global Area 系统全局区,主要是给实例使用,包括共享池(shared pool 、数据缓冲区( data buffer area) ,日志缓冲区( redo log buffer)。
2.1 共享池(shared pool)
包括library cache 、data directory cache 组成,其中 library cache 主要保存最近的sql 检查、编译、执行计划, 下次有同样语句过来的时候,可以重用这些,避免重复的检查编译执行计划。 data directory cache 主要保存数据库数据表的字段定义、索引数据等, shared pool 的大小直接影响到数据库的性能。
data buffer area : 主要保存用户对数据的修改,查询操作。该内存区域的大小直接影响数据库的性能
redo log buffer area: 主要保存最近用户对数据库的操作记录,该大小对数据库性能没有多大影响
-
SMON(System Monitor)监控SGA的健康情况,收集SGA碎片内存,监控实例健康情况
-
DBWR(Data Base Writer)维护data buffer area 和物理表数据的一致性
-
LGWR(Log Writer)维护redo log buffer area 内存数据和日志文件的一致性
-
CKPT(Check point)设置检查点,在oracle 实例出现问题的时候,可以恢复到实例失败前的情况
3 系统模块划分与设计
3.1 词法分析模块
主要是处理用户的输入,将用户的输入转换成程序可执行的语句。它拟提供以下功能:程序使用简要说明,对用户输入进行词法分析并提取参数及关键字,对于错误输入报错并提示正确的输入格式,将用户输入的信息备份在日志中。
| Analysis() | 从输入流中取出主要命令,调用各命令对参数的分析 |
|---|---|
| CommandHelp() | 当输入出现错误时对用户提供帮助 |
| Use() | 提供USE命令的句法分析 |
| Back() | 提供BACK命令的句法分析 |
| CreateDataBase() | 提供CREATE DATABASE命令的句法分析 |
| CreateTable() | 提供CREATE TABLE命令的句法分析 |
| Inster() | 提供INSTER命令的句法分析 |
| Update() | 提供UPDATE命令的句法分析 |
| Delete() | 提供DELETE命令的句法分析 |
| Select() | 提供SELECT命令的句法分析 |
| Add() | 提供ADD命令的句法分析 |
| Save() | 提供SAVE命令的句法分析 |
3.2 核心处理模块:
对已从磁盘加载进内存中的数据进行处理,并利用索引实现增删改查等功能,将结果显示在控制台上。
| CoreProcessing() | 创建日志文件并且写入 | |
|---|---|---|
| Analysis () | 判断命令内容调用相关处理函数 | string& cmd传入命令指针 |
| UseDataBase () | 进入文件夹(使用数据库) | string,传入数据库名称 |
| CreateDataBase () | 创建数据库(即创建文件夹) | string,传入文件夹名称 |
| ReadLog () | 读取日志内容 | string文件夹名称 |
3.3 文件处理模块
将内存与磁盘数据同步(日志、表单读取、新建库或表单)。
| ChangePath () | 根据输入参数提取出文件路径 | |
|---|---|---|
| CreateFolder () | 创建文件夹(即库) | string传入文件路径 |
| DeleteFolde() | 删除文件夹 | string传入文件路径 |
| Rename() | 更改名称 | string原名称,string现名称 |
| WriteTxt() | 将记录写入txt文件中 | string表名,vector记录内容 |
| ReadTxt() | 从txt中读出记录 | string表名,vector记录内容 |
3.4 table记录处理相关操作
| Table() | 将记录数和关键词数初始化为0 | |
|---|---|---|
| CreateTable() | 创建表单时将表头的内容写入 | vector表头内容 |
| Insert() | 将记录写入表单 | vector,传入记录内容 |
| Update () | 更新记录内容 | vector,需要更新条目的条件及新内容 |
| Delete () | 删除记录内容 | vector,需要删除条目的条件 |
| Select() | 输出符合条件的条目 | vector,需要输出条目的条件 |
| Add() | 添加一个表头 | vector,添加的表头内容及数据类型 |
| Save() | 将内存数据写入磁盘 |
4 接口设计
4.1 用户接口
用户在控制台输入与SQL命令类似的语句来操作软件,具体的语句格式见需求分析文档。
本项目中Analysis()是从控制台获取用户输入并且进行分析的主要函数,他从输入中提取到关键命令后将调用函数对参数进行进一步提取。而后CreateDataBase(),CreateTable()等函数将在提取完参数后调用核心处理模块。进而完成用户接口的功能。
4.2 外部接口
本软件主要通过文件处理模块与磁盘就行交互。
外部接口
-
CreateFolder (),DeleteFolde(),Rename()等文件及文件夹的创建删除等功能
-
WriteTxt()和ReadTxt()函数主要负责完成内存和磁盘的同步
4.3 内部接口
将上述三个模块封装为三个类,模块之间用类的成员函数进行调用,尽量在设计类时减小它们间的耦合度,实现内部接口功能。
4.4 数据结构
-
表头为结构体数组,结构体包含字段名、数据类型等
-
数据记录结构为一系列数组,每一列数据对应一个数组,将角标相同的各数组元素逻辑上视为一条记录中的成员。
-
索引结构为B+树,每个节点指向一个记录的角标
5 算法设计
5.1 关键字设计
-
CREATE:在文件夹中新建一个表头和一个数据文件,表头内容由词法分析模块提供的参数确认
-
INSTER:将插入的数据保存在每一个对应数组的最后一个,也就是指数据的存盘是追加的形式
-
UPDATE:循环加判断,找到所有符合条件的值进行替换,先在内存中处理再进行数据的存盘
-
DELETE:用循环,找到删除以后直接break,先在内存中处理再进行数据的存盘
-
SELECT: 循环
- 直接按格式将内容输出
- 在取完整条数据内容后加条件输出
- 在循环时取指定内容进行判断,符合条件的输出
- 先按要求排序(如果数据结构支持则不需要这一步),然后按照INSTER算法进行输出
其中的排序和查找由B+树本身的性质就可以高效实现
5.2 B+树索引算法
5.2.1 B+树叶子节点定义
struct LeafNode
{
vector<Key> keys;
vector<Value> values;
PagePointer next_page;
};
5.2.2 B+树内部节点定义
struct InteriorNode
{
vector<Key> keys;
vector<PagePointer> pointers;
};
5.2.3 search操作
/**
* finds the leaf node that _should_ contain the entry with the specified key
*/
LeafNode search(Node root, Key key);
/**
* Inserts a key/val pair into the tree.
* Returns the root of the new tree which _may_ be different
* from the old root node.
*/
InteriorNode insert_into_tree(InteriorNode root, Key newk4.ey, Value val);
5.2.4 insert操作
-
寻找insert的正确的目标leaf node
-
向目标leaf node中尝试insert操作
InteriorNode insert_into_tree(InteriorNode root, Key newkey, Value val) { LeafNode leaf = search(root, newkey); return insert_into_node(leaf, newkey, val); }
其中,insert_into_node中,要做如下的一些事:
-
/** * Tries to inserts the (newkey/val) pair into * the node. * * If `target` is an interior node, then `val` must be a page pointer. */ InteriorNode insert_into_node(Node target, newkey, val) { if( ... CASE 1 ... ) { /* handle CASE 1 */ } else if( ... CASE 2 ... ) { /* handle CASE 2 */ } else if( ... CASE 3 ... ) { /* handle CASE 2 */ } }
其中三个不同的case包括:
-
目标leaf node有足够的空间保存key
-
目标leaf node已满,但是它的parent node(父节点)有足够的空间保存key
-
目标leaf node和它的parent node已满。
5.2.5 delete操作
删除算法是insert算法的逆过程。
6 技术难点及其解决方案
-
词法分析模块对于用户多变的输入,如何正确地判段输入的合法性,再提取出关键字和参数是相当麻烦的,我们暂拟定用正则表达式来实现主体部分
-
对记录的数据结构方面,我们开始打算使用变长的结构体,然后发现并不能在程序运行后来确定结构体大小,所以我们就使用一系列数组来实现,只是要将角标相同的元素逻辑上视为一个记录结构体的成员就行
-
对于索引方面,首先B+树这种结构该如何存盘就是个非常棘手的问题,如果我们不能找到有效的方法的话,我们将采用二叉查找树来代替B+树
-文本文件的读写可能会出现意外情况,而这方面我们了解不多
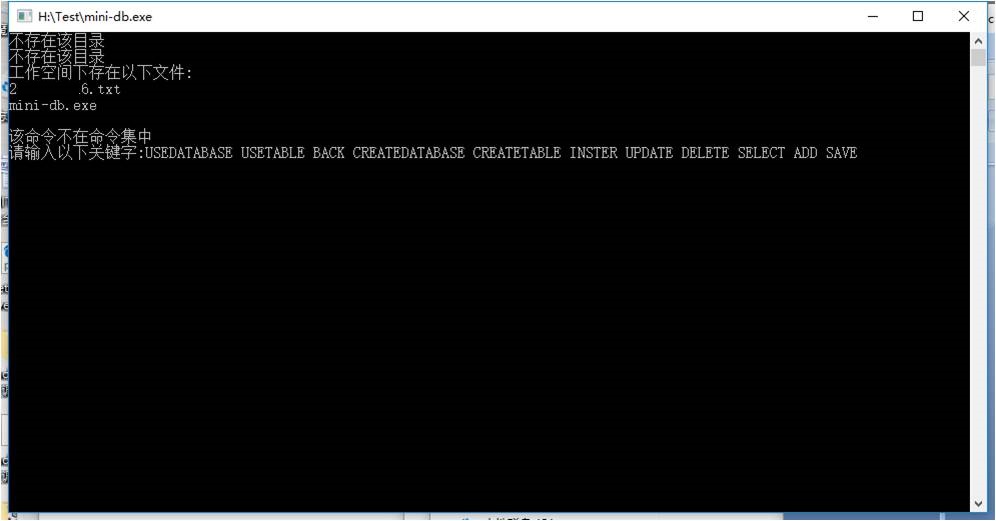
7 测试
程序主界面

命令提示
资源下载地址:https://download.csdn.net/download/sheziqiong/88333047
资源下载地址:https://download.csdn.net/download/sheziqiong/88333047

















 300
300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









