







对于字符串匹配
KMP很好的解决了以一个文本串匹配一个模板串的问题
但如果模板串有多个呢
这是KMP不再适用
于是又有了一个新的数据结构——字典树Trie
字典树可以将多个单词压缩到一棵树上
这样便解决了对于一个文本串要匹配多个模板串时
要重复匹配相同前缀的弊端
假设现在有
h
i
s
,
m
y
,
h
e
y
,
h
e
his,my,hey,he
his,my,hey,he四个模式串
将他们建成字典树后就会长成这样
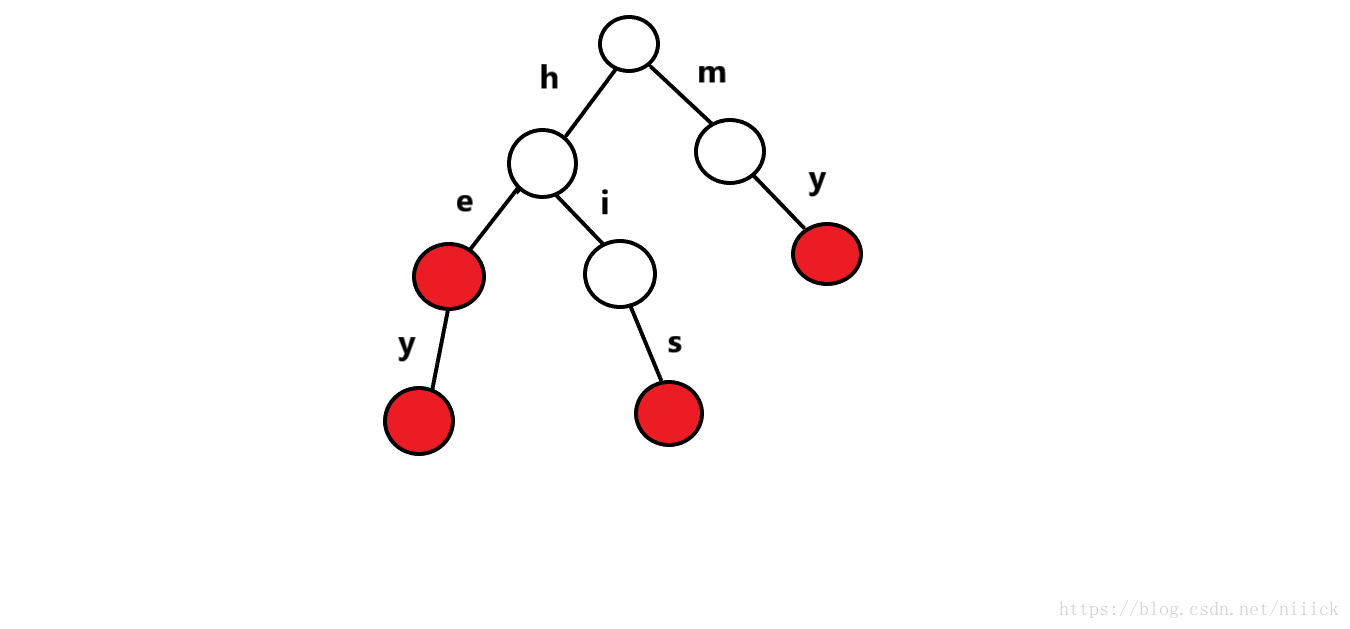
如图所示
字典树的每条边储存了一个字符
这样每条从根到红色节点的路径上的字符就各自组成了一个单词
但特别的,根节点是不表示字符或单词的!!!
虽然在字典树的定义中存字符的是边
但实际操作中为了方便我们还是会以该边下面的节点来表示字符
struct node
{
node* nxt[26];//对应下一层字母的指针
bool judge;//是否是上述的红色节点
node()
{
judge=false;
for(int i=0;i<26;i++)
nxt[i]=NULL;
}
};
node* rt=new node();//初始根结点
Trie–插入
void ins(char ss[])
{
int len=strlen(ss);
node* p=rt;
for(int i=0;i<len;i++)
{
int num=ss[i]-'a';//找到下一层结点
if(p->nxt[num]==NULL)
{
node* k=new node();
p->nxt[num]=k;
}//如果该节点不存在则创建新结点,否则继续迭代插入
p=p->nxt[num];
}
p->judge=true;//单词插入完毕,标记该节点
}
Trie–匹配
查询给定的字符串是否在模式串中出现过
bool find(char ss[])
{
int len=strlen(ss);
node* p=rt;
for(int i=0;i<len;i++)
{
int num=ss[i]-'a';
p=p->nxt[num];
if(p==NULL) return false;
//如查找过程中有结点不存在,则匹配失败
}
if(p->judge)return true;
//遍历完文本串,若该接点被标记,则查着成功
else return false;//否则查找失败
}
来一道果题练练手
洛谷P2580 于是他错误的点名开始了
题目描述
这之后校长任命你为特派探员,每天记录他的点名。校长会提供化学竞赛学生的人数和名单,而你需要告诉校长他有没有点错名。
输入格式:
第一行一个整数 n,表示班上人数。接下来 n 行,每行一个字符串表示其名字(互不相同,且只含小写字母,长度不超过 50)。第 n+2 行一个整数 m,表示教练报的名字。接下来 m 行,每行一个字符串表示教练报的名字(只含小写字母,且长度不超过 50)。
输出格式:
对于每个教练报的名字,输出一行。如果该名字正确且是第一次出现,输出“OK”,如果该名字错误,输出“WRONG”,如果该名字正确但不是第一次出现,输出“REPEAT”。(均不加引号)
说明
对于 40%的数据,n≤1000,m≤2000;
对于 70%的数据,n≤10000,m≤20000;
对于 100%的数据, n≤10000,m≤100000。
#include<iostream>
#include<cstdio>
#include<vector>
#include<algorithm>
#include<cstring>
#include<queue>
using namespace std;
int read()
{
int f=1,x=0;
char ss=getchar();
while(ss<'0'||ss>'9'){if(ss=='-')f=-1;ss=getchar();}
while(ss>='0'&&ss<='9'){x=x*10+ss-'0';ss=getchar();}
return x*f;
}
void print(int x)
{
if(x<0){putchar('-');x=-x;}
if(x>9)print(x/10);
putchar(x%10+'0');
}
struct node
{
node* nxt[26];
bool judge,rem;
node(){judge=rem=false;for(int i=0;i<26;i++)nxt[i]=NULL;}
};
node* rt=new node();
int n,m;
void ins(char ss[])
{
int len=strlen(ss);
node* p=rt;
for(int i=0;i<len;i++)
{
int num=ss[i]-'a';
if(p->nxt[num]==NULL)
{
node* k=new node();
p->nxt[num]=k;
}
p=p->nxt[num];
}
p->judge=true;
}
int find(char ss[])
{
int len=strlen(ss);
node* p=rt;
for(int i=0;i<len;i++)
{
int num=ss[i]-'a';
p=p->nxt[num];
if(p==NULL) return -1;
}
if(p->judge)
{
if(p->rem) return 0;
p->rem=true; return 1;
}
return -1;
}
int main()
{
n=read();
for(int i=1;i<=n;i++)
{
char ss[100];
scanf("%s",&ss);
ins(ss);
}
m=read();
for(int i=1;i<=m;i++)
{
char ss[100];
scanf("%s",&ss);
int ans=find(ss);
if(ans==-1)cout<<"WRONG"<<endl;
else if(ans==1)cout<<"OK"<<endl;
else if(ans==0)cout<<"REPEAT"<<endl;
}
return 0;
}
数组版的
#include<iostream>
#include<cstdio>
#include<vector>
#include<algorithm>
#include<cstring>
#include<queue>
using namespace std;
int read()
{
int f=1,x=0;
char ss=getchar();
while(ss<'0'||ss>'9'){if(ss=='-')f=-1;ss=getchar();}
while(ss>='0'&&ss<='9'){x=x*10+ss-'0';ss=getchar();}
return x*f;
}
const int maxn=1000010;
int n,m;
int ch[maxn][26],rem[maxn],vis[maxn];
int cnt;
void ins(char *ss)
{
int u=0;
int len=strlen(ss);
for(int i=0;i<len;++i)
{
int x=ss[i]-'a';
if(!ch[u][x]) ch[u][x]=++cnt;
u=ch[u][x];
}
rem[u]=1;
}
int find(char *ss)
{
int len=strlen(ss);
int u=0;
for(int i=0;i<len;i++)
{
int x=ss[i]-'a';
u=ch[u][x];
if(!u) return -1;
}
if(rem[u])
{
if(vis[u]) return 0;
vis[u]=1;
return 1;
}
return -1;
}
int main()
{
n=read();
for(int i=1;i<=n;i++)
{
char ss[100];
scanf("%s",&ss);
ins(ss);
}
m=read();
for(int i=1;i<=m;i++)
{
char ss[100];
scanf("%s",&ss);
int ans=find(ss);
if(ans==-1) cout<<"WRONG"<<endl;
else if(ans==1) cout<<"OK"<<endl;
else if(ans==0) cout<<"REPEAT"<<endl;
}
return 0;
}














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









