






一、数据类型轻量化
def reduce_df_memory(df):
""" iterate through all the columns of a dataframe and modify the data type
to reduce memory usage.
"""
start_mem = df.memory_usage().sum() / 1024 ** 2
print('Memory usage of dataframe is {:.2f} MB'.format(start_mem))
for col in df.columns:
col_type = df[col].dtype
if col_type != object:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
end_mem = df.memory_usage().sum() / 1024**2
print('Memory usage after optimization is: {:.2f} MB'.format(end_mem))
print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem))
return df
分块读取
一次性加载会出现内存溢出,24G内存都不够
chunk_iter = pd.read_csv('train.csv',chunksize=100000)
train_data = pd.DataFrame()
num = 0
for chunk in chunk_iter:
tmp_df = reduce_df_memory(chunk)
train_data = pd.concat([train_data, tmp_df])
如果提前知晓数据类型
data_types_dict = {
'time_id': 'int32',
'investment_id': 'int16',
"target": 'float32',
}
features = [f'f_{i}' for i in range(300)]
for f in features:
data_types_dict[f] = 'float32'
target = 'target'
train_data = pd.read_csv(f'{root_path}/data/train.csv',
# nrows=5 * 10 ** 4,
usecols=data_types_dict.keys(),
dtype=data_types_dict)
二、存储数据类型转换
上述数据转换成CSV,内存从18G缩小到7G左右,仍然较大,且每次加载CSV都会需要5分钟左右;所以将CSV类型转换成parquet可以变得更快,更小;
(parquet存储不支持float16数据类型, int8,所以第一步数据类型轻量化中需要注意数据类型)
train_data.to_parquet(f'{root_path}/data/train.parquet')
pd.read_parquet(f'{root_path}/data/train.parquet')
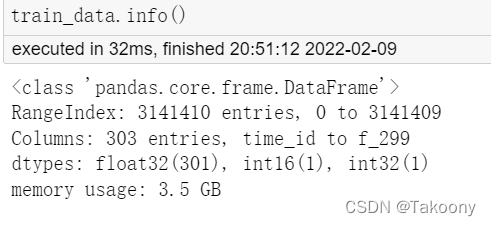
而且加载速度非常快,只需要14.4s

结论:
1、由于pandas加载csv文件默认数据格式是int64,float64等类型,非常吃内存
2、parquet高效的压缩编码,用于降低存储成本
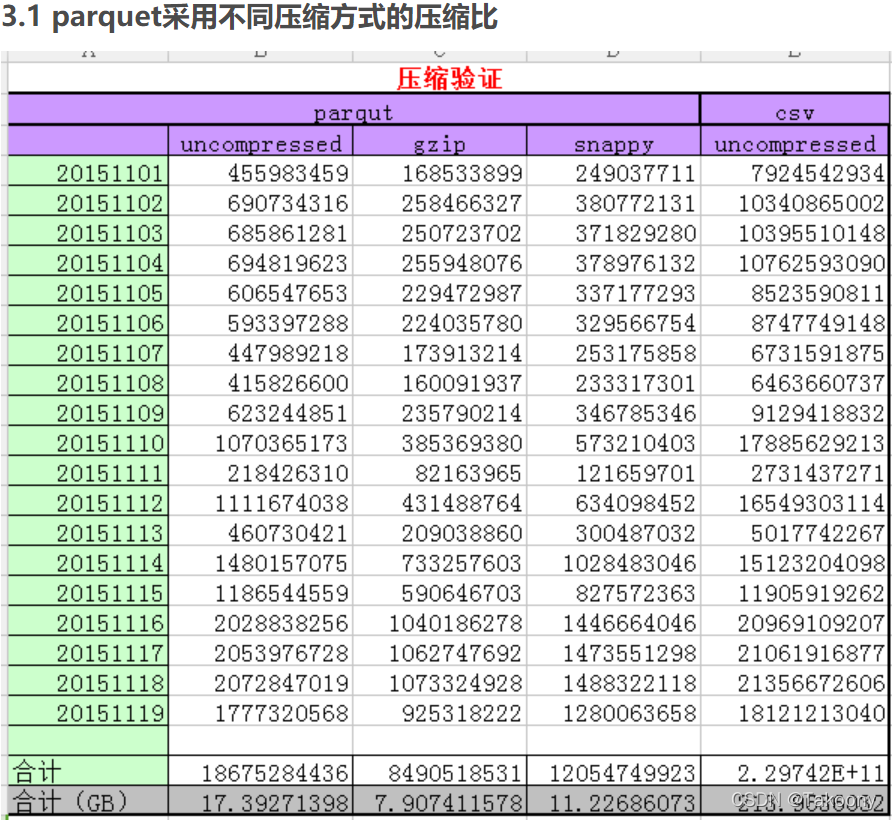
三、parquet高效的读取能力,用于支撑快速查询
问题1:pickle与之相比,速度会怎么样呢?
实验证明:加载速度Pickle(2s)速度是parquet(29s)的10倍;文件大小是一样的;














 114
114











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









