







Dataset
在NBA的媒体报道,体育记者通常会集中在少数几个球员身边。为什么这个球员与其他球员不一样?使用数据挖掘可以探索这个问题。本文的数据集
nba_2013.csv是2013-2014赛季的NBA球员的表现。下面是数据集的一些属性描述:
- player – name of the player
- pos – the position of the player
- g – number of games the player was in
- pts – total points the player scored
- fg. – field goal percentage(投篮命中率)
- ft. – free throw percentage(罚球命中率)
# 首先打印数据的前三行,观察数据的特性,总共31个属性
import pandas as pd
import numpy as np
nba = pd.read_csv("nba_2013.csv")
nba.head(3)
'''
player pos age bref_team_id g gs mp fg fga fg. \
0 Quincy Acy SF 23 TOT 63 0 847 66 141 0.468
1 Steven Adams C 20 OKC 81 20 1197 93 185 0.503
2 Jeff Adrien PF 27 TOT 53 12 961 143 275 0.520
... drb trb ast stl blk tov pf pts season season_end
0 ... 144 216 28 23 26 30 122 171 2013-2014 2013
1 ... 190 332 43 40 57 71 203 265 2013-2014 2013
2 ... 204 306 38 24 36 39 108 362 2013-2014 2013
[3 rows x 31 columns]
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
Point Guards
控球后卫(Point Guards)往往是全队进攻的组织者,并通过对球的控制来决定在恰当的时间传球给适合的球员,是球场上拿球机会最多的人。他要把球从后场安全地带到前场,再把球传给其他队友,这才有让其他人得分的机会。 一个合格的控球后卫必须要能够在只有一个人防守他的情况下,毫无问题地将球带过半场。然后,他还要有很好的传球能力,能够在大多数的时间里,将球传到球应该要到的地方:有时候是一个可以投篮的空档,有时候是一个更好的导球位置——百度搜的,我也不懂球╰( ̄▽ ̄)╭
- 先提取出所有控卫的球员信息,控卫的属性pos值为PG:
point_guards = nba[nba['pos'] == 'PG']
- 1
- 1
Points Per Game
- 由于我们的数据集给出的是球员的总得分(pts)以及参赛场数(g),没有直接给出每场球赛的平均得分(Points Per Game),但是可以根据前两个值计算:
point_guards['ppg'] = point_guards['pts'] / point_guards['g']
# 查看下数据,确保 ppg = pts/g
point_guards[['pts', 'g', 'ppg']].head(5)
'''
pts g ppg
24 930 71 13.098592
29 150 20 7.500000
30 660 79 8.354430
38 666 72 9.250000
50 378 55 6.872727
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
Assist Turnover Ratio
NBA中专门有一项数据统计叫assist/turnover,是用这个队员助攻数比上他的失误数,这项统计能准确的反映一个控卫是否称职。
- 助攻失误比的计算公式如下,其中Assists表示总助攻(ast),Turnovers表示总失误(tov)。

- 计算之前要将那些失误率为0的球员去掉,因为他可能参赛数很少,分析他没有意义,并且作为除数不能为0.
point_guards = point_guards[point_guards['tov'] != 0]
point_guards['atr'] = point_guards['ast'] / point_guards['tov']
- 1
- 2

- 1
- 2
Visualizing The Point Guards
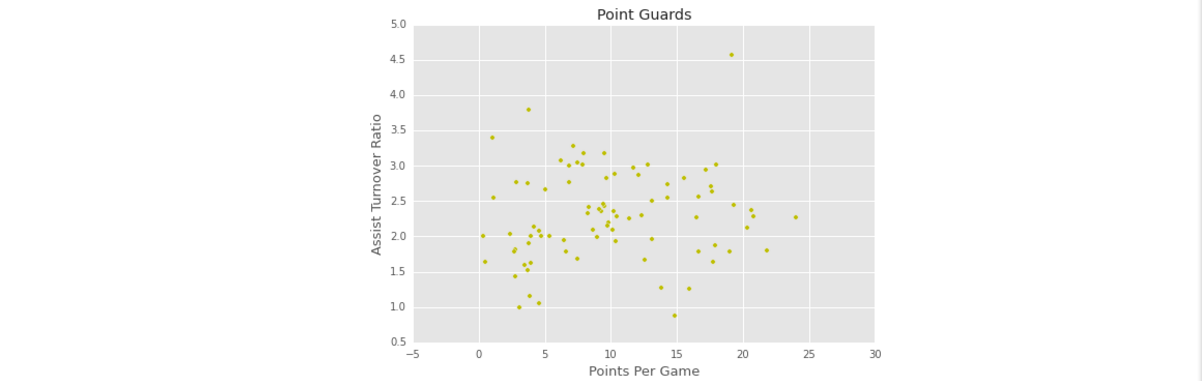
- 可视化控卫的信息,X轴表示的是个平均每场球赛的得分,Y轴是助攻失误比。
plt.scatter(point_guards['ppg'], point_guards['atr'], c='y')
plt.title("Point Guards")
plt.xlabel('Points Per Game', fontsize=13)
plt.ylabel('Assist Turnover Ratio', fontsize=13)
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
Clustering Players
- 粗略看一下上面的图,大约有五簇比较集中。可以利用聚类技术将水平差不多的控卫聚集在一簇。K-Means是比较常用的聚类算法,是基于质心的聚类(簇是一个圆圈,质心是这个簇的平均向量)。在美国议员党派——K均值聚类
这篇文章中我也用到K-Means这个算法,当时我是直接调用sklearn中的包(from sklearn.cluster import KMeans),然后直接计算。但是在本文,我想要研究K-Means的具体步骤,因此一步步迭代。
# 美国议员党派——K均值聚类 中直接调用包来进行聚类
from sklearn.cluster import KMeans
kmeans_model = KMeans(n_clusters=2, random_state=1)
senator_distances = kmeans_model.fit_transform(votes.iloc[:, 3:])
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
Step 1
- 首先随机生成5个中心点:
num_clusters = 5
random_initial_points = np.random.choice(point_guards.index, size=num_clusters)
# centroids 随机初始化的聚类中心点,centroids是point_guards的子集
centroids = point_guards.ix[random_initial_points]
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
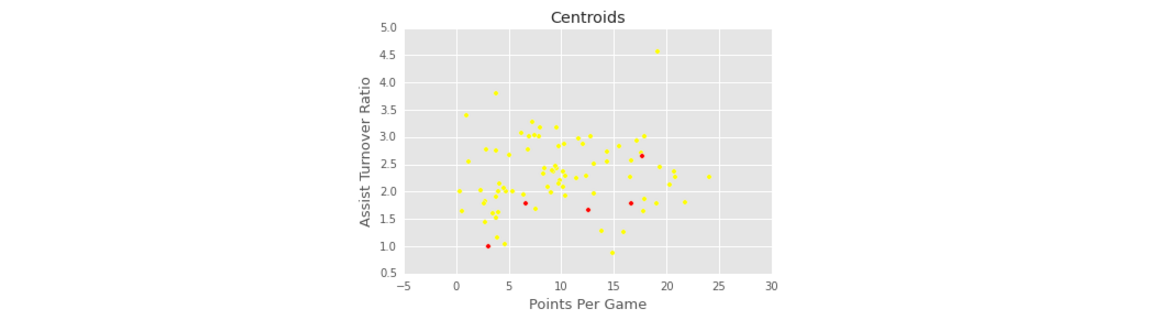
- 可视化初始聚类中心,中心点用红色标识,其他的点用黄色标识:
plt.scatter(point_guards['ppg'], point_guards['atr'], c='yellow')
plt.scatter(centroids['ppg'], centroids['atr'], c='red')
plt.title("Centroids")
plt.xlabel('Points Per Game', fontsize=13)
plt.ylabel('Assist Turnover Ratio', fontsize=13)
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
- 然后将中心点转化为一个字典格式,字典的键是这个簇的名称,字典的值是这个中心点的信息(”ppg”,”atr”)。
def centroids_to_dict(centroids):
dictionary = dict()
# counter作为字典的键值,自增
counter = 0
# iterate a pandas data frame row-wise using .iterrows()
for index, row in centroids.iterrows():
coordinates = [row['ppg'], row['atr']] #list对象
dictionary[counter] = coordinates
counter += 1
return dictionary
centroids_dict = centroids_to_dict(centroids)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 再然后就是计算每个点到聚类中心的距离然后将每个点的聚类中心修改为离其最近的那个簇。
import math
# 计算两个点距离的函数
def calculate_distance(centroid, player_values): # 参数都是list对象
root_distance = 0
for x in range(0, len(centroid)):
difference = centroid[x] - player_values[x]
squared_difference = difference**2
root_distance += squared_difference
euclid_distance = math.sqrt(root_distance)
return euclid_distance
# 返回离每个点最近的簇的键
def assign_to_cluster(row):
lowest_distance = -1
closest_cluster = -1
for cluster_id, centroid in centroids_dict.items():
df_row = [row['ppg'], row['atr']]
euclidean_distance = calculate_distance(centroid, df_row)
if lowest_distance == -1:
lowest_distance = euclidean_distance
closest_cluster = cluster_id
elif euclidean_distance < lowest_distance:
lowest_distance = euclidean_distance
closest_cluster = cluster_id
return closest_cluster
# 生成一个新的属性cluster:存储每个节点所属的簇的键值
point_guards['cluster'] = point_guards.apply(lambda row: assign_to_cluster(row), axis=1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
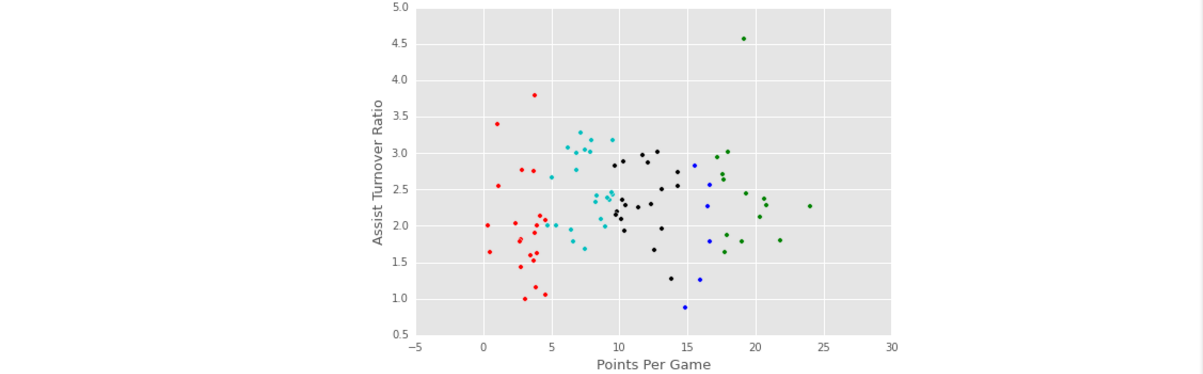
- 上面根据随机初始化的簇及其键值,将其它的点分配给这些簇。可视化第一次随机初始化的聚类图,将不同的簇用不同的颜色表示出来:
def visualize_clusters(df, num_clusters):
colors = ['b', 'g', 'r', 'c', 'm', 'y', 'k']
for n in range(num_clusters):
clustered_df = df[df['cluster'] == n]
plt.scatter(clustered_df['ppg'], clustered_df['atr'], c=colors[n-1])
plt.xlabel('Points Per Game', fontsize=13)
plt.ylabel('Assist Turnover Ratio', fontsize=13)
visualize_clusters(point_guards, 5)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Step 2
- 将所有节点分配给离其最近的簇后,需要调整簇中心,需要重新计算簇的质点:
# 计算簇中心
def recalculate_centroids(df):
new_centroids_dict = dict()
for cluster_id in range(0, num_clusters):
values_in_cluster = df[df['cluster'] == cluster_id]
# Calculate new centroid using mean of values in the cluster
new_centroid = [np.average(values_in_cluster['ppg']), np.average(values_in_cluster['atr'])]
new_centroids_dict[cluster_id] = new_centroid
return new_centroids_dict
centroids_dict = recalculate_centroids(point_guards)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
Repeat Step 1
- 重新计算了簇中心后,又要计算每个点到新簇中心的距离,将所有节点重新分给离其最近的那个簇中(跟1相差不大):
point_guards['cluster'] = point_guards.apply(lambda row: assign_to_cluster(row), axis=1)
visualize_clusters(point_guards, num_clusters)
- 1
- 2
- 1
- 2
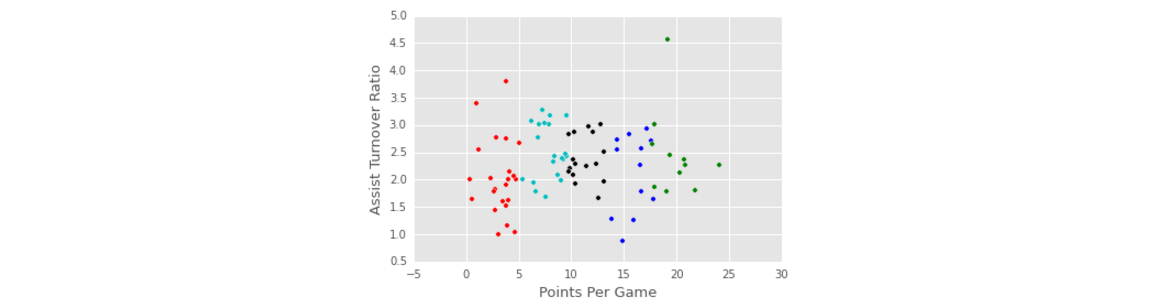
Repeat Step 2 And Step 1
- 然后一只重复步骤2和步骤1,调整簇中心,再调整每个点的所属的簇值
centroids_dict = recalculate_centroids(point_guards)
point_guards['cluster'] = point_guards.apply(lambda row: assign_to_cluster(row), axis=1)
visualize_clusters(point_guards, num_clusters)
- 1
- 2
- 3
- 1
- 2
- 3
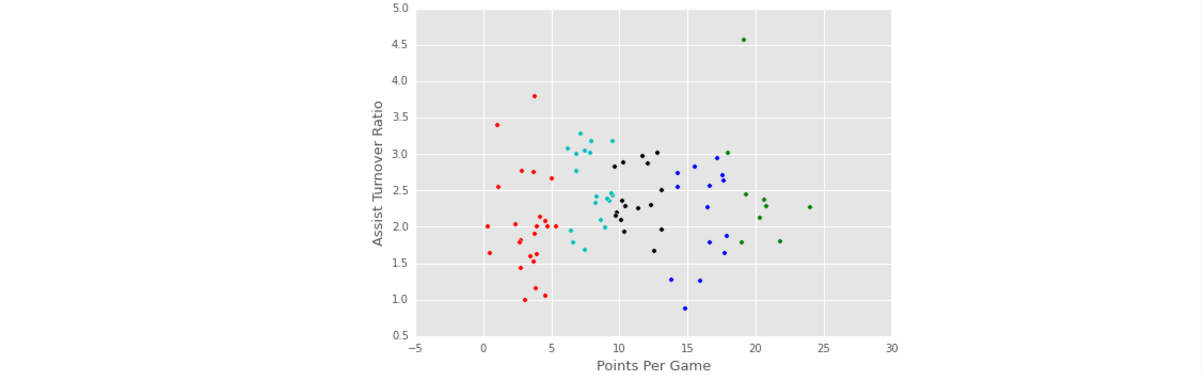
Challenges Of K-Means
观察前几次迭代,每次节点改变都不是很大,主要是因为:
- K-Means算法在迭代的过程中,对于每个簇不会引起很大的变化,因此这个算法总是收敛的并且很稳定。
- 由于K-Means算法迭代得很保守,因此最终结果与选取的初始质点有很大关系。
为了解决这些问题,sklearn包中的K-Means实现中做了一些智能的功能,比如重复聚类,每次随机选取质心,这比只采用一次质心选取所带来的偏差要少很多。
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=num_clusters)
kmeans.fit(point_guards[['ppg', 'atr']])
point_guards['cluster'] = kmeans.labels_
visualize_clusters(point_guards, num_clusters)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
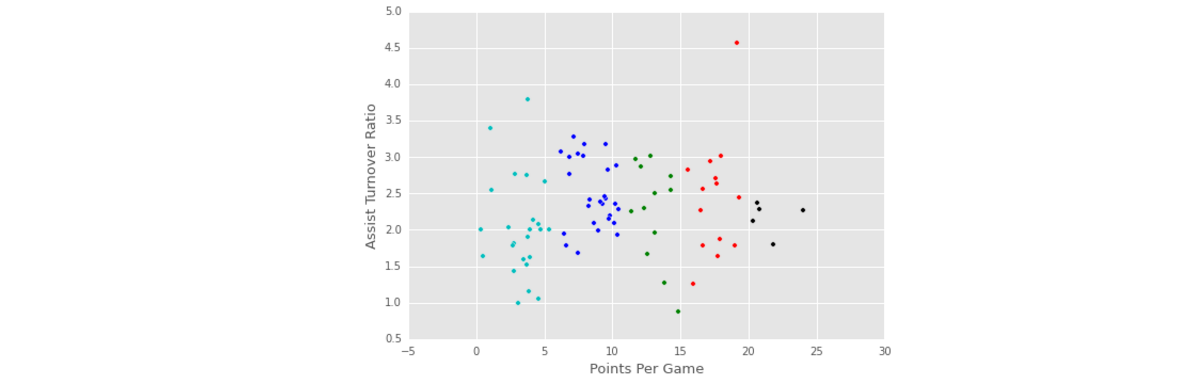
Conclusion
- 本文我们通过控卫的助攻失误率和每场球赛的平均得分将控卫分为5大类型。我们也可以利用球员的更多信息来进行聚类。得到了这些聚类信息,再去获取每簇中的球员的信息,你就会发现,一个簇中的球员的水平相当,如果一个簇中有一个球员得到的关注很大,那么该簇内其它球员同样可能得到很大的关注,因为他们属于一个高水平的球员簇中;
About K-Means
- 上面这个例子主要是用来理解K-Means.下面来总结下这个方法。
优点:容易实现(非常好理解,相似的点尽量待在一块儿);
缺点:可能收敛到局部最小值,在大规模数据集上收敛较慢(因为随机初始化的质心不同,很有可能导致最后形成的簇也不同,因此可能不是最优解,并且要进行多次相似性度量,非常耗时);
适用数据类型:数值型数据(上面给的例子都是数值型数据,因为需要进行相似性度量,当然有的相似性度量方法比如Jaccard系数主要用于计算符号度量或布尔值度量的个体间的相似度,因为个体的特征属性都是由符号度量或者布尔值标识,因此无法衡量差异具体值的大小,只能获得“是否相同”这个结果),有的时候可以将标称型数据映射为二值数据再用于距离计算;
- 伪代码:
创建k个点作为起始质心(随机选择)
当任意一个点的簇分配发生改变时
对数据集中的每个数据点
对每个质心
计算质心与数据点之间的距离
将数据点分配到距其最近的簇
对于每个簇,计算簇中所有的点的均值并将其作为质心
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 衡量指标:SSE(Sum of Squared Error误差平方和)
在聚类过程中,保存了每个点到质心的距离,将其理解为误差,那么SSH值越小表示数据点越接近于它们的质心,聚类效果也越好。因为对误差去了平方,因此更加重视那些远离中心的点。
- 使用后处理来提高聚类性能
对生成的簇进行后处理:
- 将具有最大SSE值的簇划分为两个簇(在这个簇中进行K均值聚类,将k设置为2即可),但为了保持总的簇数不变,因此需要将两个簇合并,合并的方法:
- 合并距离最近的两个质心(需要计算所有质心之间距离);
- 合并两个使得SSE增幅最小的质心(需要计算所有两个簇合并所带来的SSE增长);
二分K-均值
由于K均值算法容易收敛到局部最优,有人就提出了另一个称为二分K均值的算法。该算法首先将所有点作为一个簇,然后将该簇一分为二。之后选择其中一个簇继续进行划分,选择哪一个簇进行划分取决于对其划分是否可以最大程度的降低SSE值,上述划分过程不断重复,直到得到用户指定的簇数目为止;另一种做法是直接选择SSE最大的簇进行划分;
- 伪代码:
将所有点看成一个簇
当簇数目小于k时
对于每一个簇
计算总误差
在给定的簇上面进行K均值聚类(k=2)
计算将该簇一分为二之后的总误差
选择使得误差最小的那个簇进行划分操作















 5269
5269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









